Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Метод адаптивной классификации изображений с использованием обучения с подкреплением
Аннотация:В статье представлен метод классификации изображений с использованием, помимо базовой нейронной сети, дополнительной, способной адаптивно концентрироваться на классифицируемом объекте изображения. Задача дополнительной сети является задачей о контекстном многоруком бандите и сводится к предсказанию такой области на исходном изображении, при вырезании которой в процессе классификации возрастет уверенность базовой нейронной сети в принадлежности объекта на изображении правильному классу. Обучение дополнительной сети происходит с помощью методов обучения с подкреплением и стратегий достижения компромисса между эксплуатацией и исследованием при выборе действий для решения задачи о контекстном многоруком бандите. На подмножестве набора данных ImageNet-1K проведены различные эксперименты по выбору архитектуры нейронной сети, алгоритма обучения с подкреплением и стратегии исследования при обучении. Рассмотрены такие алгоритмы обучения с подкреплением, как DQN, REINFORCE и A2C, и такие стратегии исследования, как -жадная, -softmax, -decay-softmax и метод UCB1. Большое внимание уделено описанию проведенных экспериментов и обоснованию полученных результатов. Предложены варианты применения разработанного метода, демонстрирующие увеличение точности классификации изображений по сравнению с базовой моделью ResNet. Дополнительно рассмотрен вопрос о вычислительной сложности данного метода. Дальнейшие исследования могут быть направлены на обучение агента на изображениях, не задействованных при обучении сети ResNet.
Abstract:The paper proposes a method for image classification that uses in addition to a basic neural network for image classification an additional neural network able to adaptively concentrate on the classified im-age object. The task of the additional network is the contextual multi-armed bandit problem, which re-duces to predicting such area on the original image, which is, when cut out of the classification process, will increase the confidence of the basic neural network that the object on the image belongs to the cor-rect class. The additional network is trained using reinforcement learning techniques and strategies for compromising between exploration and research when choosing actions to solve the contextual multi-armed bandit problem. Various experiments were carried out on a subset of the ImageNet-1K dataset to choose a neural network architecture, a reinforcement learning algorithm and a learning exploration strategy. We con-sidered reinforcement learning algorithms such as DQN, REINFORCE and A2C and learning explora-tion strategies such as -greedy, -softmax, -decay-softmax and UCB1 method. Much attention was paid to the description of the experiments performed and the substantiation of the results obtained. The paper proposes application variants of the developed method, which demonstrate an increase in the accuracy of image classification in comparison with the basic ResNet model. It additionally consid-ers the issue of the computational complexity of the developed method.
| Авторы: Елизаров А.А. (artelizar@gmail.com) - Казанский (Приволжский) федеральный университет (магистрант), Казань, Россия | |
| Ключевые слова: задача о контекстном многоруком бандите, обучение с подкреплением, классификация изображений, компьютерное зрение, нейронные сети, машинное обучение, искусственный интеллект |
|
| Keywords: contextual multi-armed bandit problem, time, reinforcem ent learnin, image classification, computer vision, neural network, machine learning, artificial intelligence |
|
| Количество просмотров: 3296 |
Статья в формате PDF |
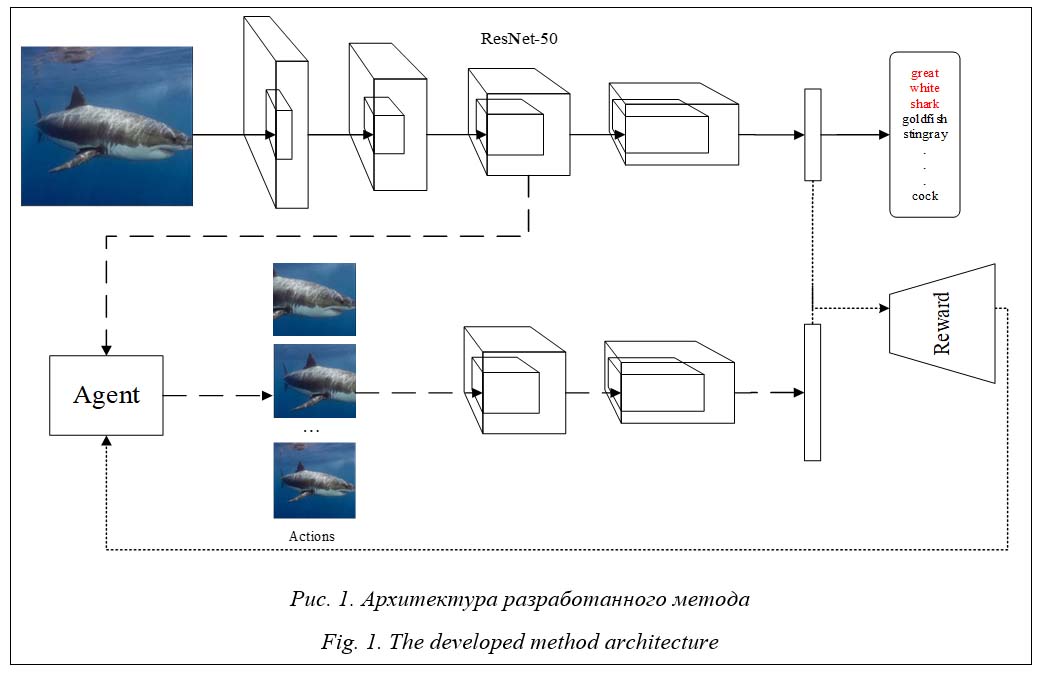
Многие современные интеллектуальные системы управления так или иначе оснащены модулями, которые получают информацию об окружающем мире посредством анализа изображений. В этом аспекте на первый план выходят задачи компьютерного зрения (прежде всего – классификации изображений) и методы их решения. Задача классификации изображений заключается в разделении объектов на изображениях на группы, называемые классами [1]. Со времени проведения соревнования ILSVRC 2012 (ImageNet Large Scale Visual Recognition Challenge) [2] и по сегодня лучшие результаты в решении этой задачи показывают сверточные нейронные сети, превзошедшие в 2015 году уровень классификации изображений человеком на наборе данных ImageNet [3]. В последнее время для решения самых различных задач успешно применяется такое направление машинного обучения, как обучение с подкреплением. В обучении с подкреплением некоторая система (агент) обучается, взаимодействуя с окружающей средой и получая от нее отклик [4], то есть обучение агента осу- ществляется методом проб и ошибок. Хотя основная теория современного обучения с подкреплением была разработана еще в прошлом веке, значительных успехов в этом направ- лении удалось добиться относительно недав- но [5, 6]. В первую очередь это произошло благодаря развитию вычислительной техники и методов глубокого обучения. В силу того, что агент, как правило, не обладает полной информацией об окружающей среде, методы обучения с подкреплением активно применяются при разработке различных интеллектуальных информационных систем. Одними из первых основных методов, использующих обучение с подкреплением при решении задачи классификации изображений и показывающих в настоящее время результаты на уровне state-of-the-art, являются FCAN [7] и DT-RAM [8]. В методе FCAN нейронная сеть имитирует зрительную систему человека, которая распознает объект через серию проблесков на наиболее важных частях этого объекта, отличающих его от других. На каждом времен- ном шаге нейронная сеть выбирает определенную область на входном изображении и с учетом областей, выбранных на предыдущих шагах, пытается классифицировать объект на изображении. Для обучения такой сети используются метод обучения с подкреплением REINFORCE [4] и модифицированная жадная стратегия выбора действий. Идея метода DT-RAM основана на способности человека к избирательному зрительному вниманию, когда зрительные сигналы подавляют ненужные области, присутствующие в поле зрения человека, тем самым помогая ему в поиске цели. В DT-RAM используется глубокая рекуррентная нейронная сеть с итеративным механизмом визуального внимания, для обучения которой применяется модифицированный алгоритм REINFORCE. К преимуществам методов FCAN и DT-RAM можно отнести использование при обучении только меток правильных классов без более подробной аннотации изображений. К недавним работам по данной теме относится, например, [9], в которой нейронная сеть обучается динамически определять необходимые для правильной классификации участки изображений с высоким разрешением на основе парных изображений с низким разрешением. Такой подход позволяет снизить вычислительную сложность метода и повысить точность классификации изображений. В [10] исследуется проблема классификации изображений с использованием нескольких агентов, способных самостоятельно собирать информацию с ограниченного участка изображения и обмениваться ею друг с другом. Экспериментальные результаты демонстрируют эффективность структуры мультиагентного обучения. Целью данной работы является разработка метода классификации изображений с использованием, помимо базовой нейронной сети ResNet, дополнительной (агента), которая обучается с помощью методов обучения с подкреплением [11] и способна адаптивно концентрироваться на классифицируемом объекте изображения. Описание метода адаптивной классификации изображений Идея разработанного метода заключается в использовании, помимо нейронной сети для классификации изображений, дополнительной нейронной сети – агента. В качестве базовой модели для классификации изображений применяется нейронная сеть ResNet-50 [12], пред- обученная на выбранном наборе данных. Агент получает на вход выход 3-й группы остаточных блоков ResNet и предсказывает, какую область из полученных карт признаков изображения нужно вырезать, чтобы в процессе классификации возросла уверенность сети ResNet в принадлежности объекта на исходном изображении правильному классу. После этого карты признаков изображения обрезаются согласно предсказанию агента и подаются на вход следующей группе остаточных блоков ResNet для последующего извлечения признаков и классификации. Для вырезания карт признаков изображения и приведения их к одному размеру используется слой ROI Pool [13], часто применяемый на практике при решении задач локализации объектов на изображениях. Такая задача для агента ставится исходя из предположения, что при правильном вырезании сеть ResNet сможет лучше классифицировать объект на изображении, и является задачей о контекстном многоруком бандите [4], так как эпизод состоит только из одного шага и во время обучения агент получает m различных контекстов (m – количество изображений в обучающей выборке). Состояниями окружающей среды являются карты признаков изображений – выходы 3-й группы остаточных блоков нейронной сети ResNet. Действия агента – варианты вырезания части карт признаков изображения. Они формируются следующим образом: входные карты признаков изображения замощаются с дискретным шагом l слева направо и сверху вниз каждым из ограничивающих прямоугольников с размерами сторон, равными соответственно 0.5, 0.75 и 1.0 от размера сторон входных карт признаков изображения. Замощение ограничивающим прямоугольником с размером сторон 1.0 от размера сторон карт признаков изображения является действием агента «ничего не вырезать». Вознаграждение агента на временном шаге t для i-го изображения из набора данных можно записать как rit = outputsit(ci) – baseline_outputsit(ci), где outputsit, baseline_outputsit – векторы уверенности нейронной сети ResNet в принадлежности объекта на i-м изображении различным классам, полученные соответственно с учетом вырезания агентом карт признаков изображения и без учета вырезания (базовая модель ResNet, эквивалентно действию «ничего не вы- резать»), а ci – индекс правильного класса. Таким образом, вознаграждение агента rit – вещественное число на отрезке от -1 до 1.
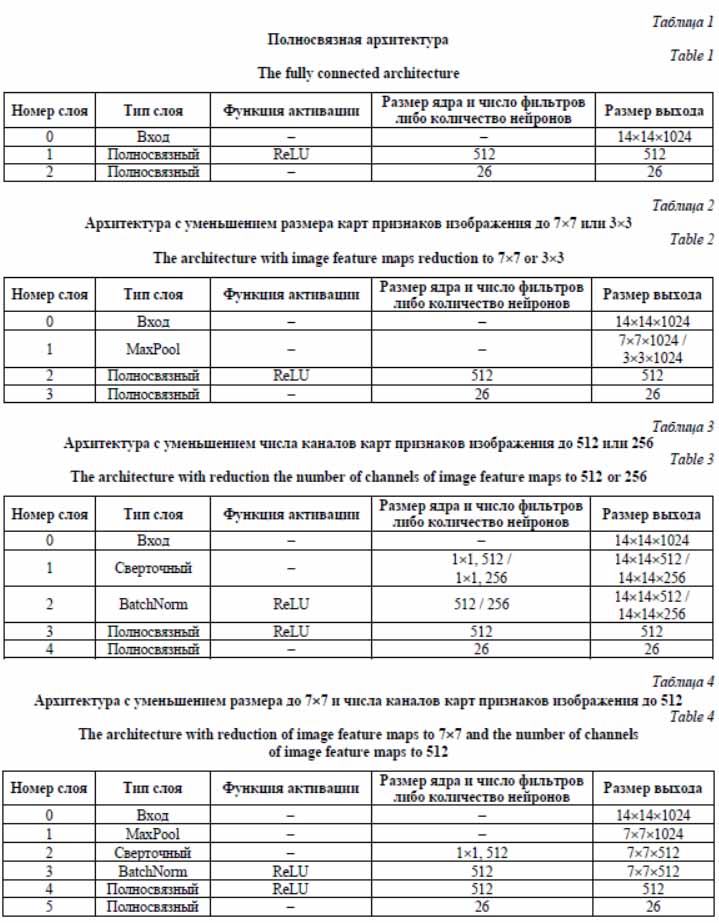
Методика проведения экспериментов При проведении экспериментов для обучения нейронной сети ResNet использовались изображения как из валидационной выборки агента, так и из обучающей. Этот выбор основан на предположении, что для эффективной работы агента нужно обучать и тестировать его на выходах группы блоков ResNet из одного распределения. Другими словами, и обучать, и тестировать агента необходимо на изображе- ниях, которые либо применялись при обучении сети ResNet, либо нет. Для упрощения исследо- вания влияния параметров на эффективность работы агента сначала были проведены эксперименты с агентом, который обучался и тестировался на изображениях, использованных при обучении ResNet. Описание набора данных В настоящей работе для проведения экспериментов использовалось подмножество набора данных ImageNet-1K [14], содержащего почти 1.4 млн изображений с высоким разрешением 1 000 различных классов. В подмножество были включены только классы животных, чтобы приблизить исходную задачу классификации изображений к задаче детального распознавания (fine-grained recognition) [15]. Таким образом, может потенциально увеличиться влияние вырезания карт признаков изображений на эффективность классификации. Основные характеристики использованного подмножества: 60 классов различных животных, 14 тыс. изображений для обучения нейронной сети ResNet, 55 тыс. изображений для обучения агента, 8 тыс. изображений в валидационной выборке. Архитектура нейронной сети В качестве архитектуры нейронной сети агента рассматривались варианты, представ- ленные в таблицах 1–4. Архитектура из таб- лицы 1 является базовым прототипом, а в ар- хитектурах из таблиц 2–4 для уменьшения размерности входа используются слой субдискретизации MaxPool и сверточный слой с размером ядра свертки 1´1 и слоем нормализации BatchNorm. По умолчанию размер скрытого полносвязного слоя в этих архитектурах – 512 нейронов, а шаг замощения l равен 2, что приводит к 26 возможным действиям агента.
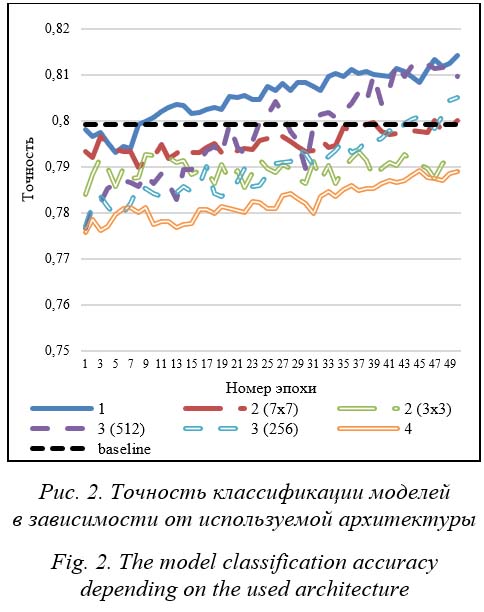
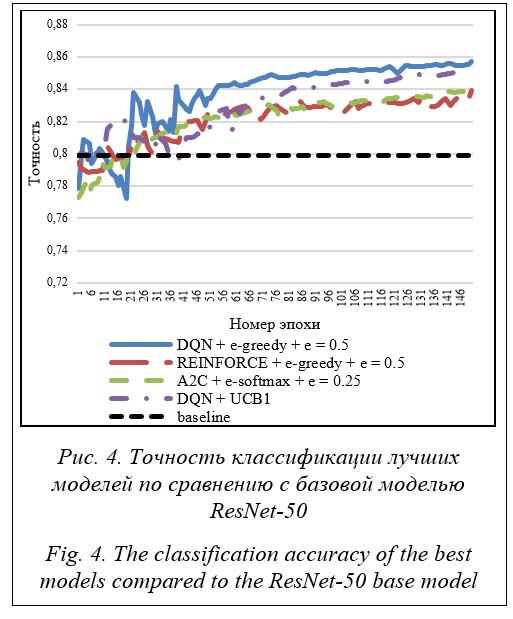
Среди разработанных архитектур лучшие результаты показали полносвязная архитектура из таблицы 1 и архитектура с уменьшением числа каналов карт признаков изображения до 512 из таблицы 3. Среди этих моделей наилучший результат продемонстрировала архитектура из таблицы 3 с уменьшением числа каналов карт признаков изображения до 512 с 1 024 нейронами в скрытом полносвязном слое. Она и была выбрана в качестве основной архитектуры для нейронной сети агента. Следует отметить, что выбранная архитектура является неглубокой и содержит примерно 100 млн обучаемых параметров, что составляет около 80 % от количества обучаемых параметров основной нейронной сети ResNet-50. Поэтому применение агента незначительно увеличивает вычислительную сложность разработанной модели даже несмотря на то, что основная сеть ResNet сама по себе имеет невысокую вычислительную сложность. Более того, для увеличения итоговой точности классификации в качестве основной нейронной сети вместо ResNet-50 могут использоваться самые современные сверточные нейронные сети, являющиеся модификациями сетей ResNet, например, EfficientNet [16], которая на сегодняшний день показывает лучшие результаты в задаче классификации изображений на различных наборах данных. Алгоритм обучения и стратегия выбора действий В качестве алгоритмов для обучения агента рассматривались алгоритмы обучения с подкреплением DQN [6], REINFORCE и A2C [4]. Алгоритм DQN использовался с модификацией воспроизведения опыта [6] с максимально возможным размером буфера. В функциях потерь алгоритмов REINFORCE и A2C также применялся энтропийный бонус [17]. В качестве стратегий выбора действий (стратегий исследования) при обучении агента рассматривались следующие стратегии достижения компромисса между эксплуатацией и исследованием: e-жадная (e-greedy) [4], e-softmax (модификация softmax [4] по аналогии с e-жадной стратегией), e-decay-softmax (по аналогии с e-decay-жадной стратегией [4]) и метод UCB1 [18]. Параметр e в стратегии e-decay-softmax уменьшался в процессе обучения от 1.0 до 0.5. Для каждого из алгоритмов была выбрана наиболее оптимальная стратегия исследования. В результате этого эксперимента построены графики для алгоритмов DQN (см. http:// www.swsys.ru/uploaded/image/2022-1/2022-1- dop/2.jpg, http://www.swsys.ru/uploaded/image/ 2022-1/2022-1-dop/3.jpg), REINFORCE (см. http://www.swsys.ru/uploaded/image/2022-1/ 2022-1-dop/4.jpg, http://www.swsys.ru/uploaded/ image/2022-1/2022-1-dop/5.jpg), A2C (см. http:// www.swsys.ru/uploaded/image/2022-1/2022-1- dop/6.jpg, http://www.swsys.ru/uploaded/image/ 2022-1/2022-1-dop/7.jpg). Проведенные эксперименты показали следующее. · Результаты применения стратегии e-decay-softmax выглядят немного лучше по сравнению с e-softmax. Однако в целом эффективность этих стратегий в данной задаче практически не отличается. Это говорит о том, что большая вероятность исследования в начале обучения не повышает точность классификации. · Результаты работы метода UCB1 (см. http://www.swsys.ru/uploaded/image/2022-1/ 2022-1-dop/2.jpg, http://www.swsys.ru/uploaded/ image/2022-1/2022-1-dop/4.jpg, http://www. swsys.ru/uploaded/image/2022-1/2022-1-dop/6. jpg), несмотря на отсутствие случайности, выглядят несколько шумно по сравнению с результатами других стратегий. Это следует из того, что метод UCB1 довольно часто выбирает недоисследованные действия. · В общем, использование в этой задаче алгоритмов обучения с подкреплением, основанных на функциях ценности, более эффективно, чем алгоритмов, основанных на функции политики. Среди лучших моделей для всех алгоритмов обучения с подкреплением самый хороший результат показала модель, обученная в течение 150 эпох с помощью алгоритма DQN и e-жадной стратегии выбора действий при e = 0.5. Она превысила точность классификации базовой модели ResNet-50 почти на 0.06, достигнув точности классификации изображений на валидационной выборке, равной 0.857. Итоговые результаты отражены на рисунке 4 и в таблице 5. Таблица 5 Результаты классификации лучших моделей по сравнению с базовой моделью ResNet-50 Table 5 The results of classifying the best models compared to the ResNet-50 base model
Способ обучения агента на данных, не использованных при обучении базовой сети ResNet Эксперименты по выбору архитектуры агента, алгоритма обучения с подкреплением и стратегии исследования при обучении проводились при условии, что изображения из валидационной выборки агента использовались при обучении нейронной сети ResNet. На практике такой подход неприменим, но можно предложить другой, в котором валидационная выборка используемого набора данных делится на две части: на одной проходит обучение агента, а на другой его тестирование. Таким образом, нейронная сеть ResNet не будет обучаться на изображениях из обучающей и валидационной выборок агента. Также был проведен эксперимент, где в качестве валидационной выборки использовалась валидационная выборка всего набора данных ImageNet-1K, которая содержит 50 тыс. изображений 1 000 различных классов. Она была поделена на две части: 45 тыс. изображений для обучения и 5 тыс. изображений для тестирования агента. В качестве параметров агента применялись полученные по результатам предыдущих экспериментов. По итогам этого эксперимента точность классификации на тестовой части валидационной выборки с учетом вырезания агентом карт признаков изображений составила 0.6942, что превышает точность базовой модели ResNet, равную 0.6934. Отметим, что обучение агента на изображениях, которые не использовались при обучении сети ResNet, может потребовать большего объема тренировочных данных, а также более детального подбора гиперпараметров. Заключение В статье описан метод классификации изображений с использованием дополнительной нейронной сети (агента), которая обучается с помощью методов обучения с подкреплением и способна адаптивно концентрироваться на классифицируемом объекте изображения. Для обучения разработанного метода необходимы только метки правильных классов изображений, что не усложняет применение его на практике по сравнению с базовой моделью ResNet. Основная идея метода базируется на предположении, что вырезание агентом правильной области на картах признаков изображения в процессе классификации сетью ResNet может потенциально увеличить точность классификации. Такая идея приводит к задаче о контекстном многоруком бандите, где состояниями окружающей среды являются входные карты признаков изображений, действиями – возможные области для вырезания на входных картах признаков, а вознаграждением – разность уверенностей сети ResNet в принадлежности объекта на изображении правильному классу с учетом вырезания агентом карт признаков изображения и если ничего не вырезать (базовая модель ResNet), соответственно. Проведены эксперименты по выбору архитектуры агента, алгоритма обучения с подкреплением и стратегии исследования при обучении агента. Особое внимание уделено описанию проведенных экспериментов и обоснованию полученных результатов. Эксперименты проводились при условии, что изображения из валидационной выборки агента используются при обучении сети ResNet, чтобы оценить эффективность работы агента для входа из выходов группы блоков ResNet из одного распределения. При таком подходе разработанная модель показала точность классификации, значительно превосходящую точность классификации базовой модели, что создает задел для будущих исследований. Однако этот подход неприменим на практике, поэтому был предложен другой, при котором изображения из обучающей и валидационной выборок агента не используются при обучении сети ResNet. Модифицированный подход также показал увеличение точности классификации изображений по сравнению с базовой моделью ResNet-50. Дальнейшие исследования могут быть связаны с обучением агента на изображениях, которые не были задействованы при обучении сети ResNet, так как это может потребовать большего объема тренировочных данных и более детального подбора гиперпараметров. Автор выражает благодарность научному руководителю, к.ф.-м.н. Разинкову Е.В. Литература 1. Goodfellow I., Bengio Y., Courville A. Deep learning. Genet Program Evolvable Mach, 2018, vol. 19, pp. 305–307. DOI: 10.1007/s10710-017-9314-z. 2. Krizhevsky A., Sutskever I., Hinton G.E. ImageNet classification with deep convolutional neural networks. Communications of the ACM, 2017, vol. 60, no. 6, pp. 84–90. DOI: 10.1145/3065386. 3. Russakovsky O., Deng J., Su H. et al. ImageNet large scale visual recognition challenge. Int. J. of Computer Vision, 2015, vol. 115, no. 3, pp. 211–252. DOI: 10.1007/s11263-015-0816-y. 4. Sutton R.S., Barto A.G. Reinforcement Learning: An Introduction. Cambridge, The MIT Press, 2014, 338 p. 5. Silver D., Huang A., Maddison C.J. et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, vol. 529, no. 7587, pp. 484–489. DOI: 10.1038/nature16961. 6. Mnih V., Kavukcuoglu K., Silver D. et al. Playing Atari with deep reinforcement learning. ArXiv, 2013, art. 1312.5602. URL: https://arxiv.org/abs/1312.5602 (дата обращения: 15.06.2021). 7. Liu X., Xia T., Wang J. et al. Fully convolutional attention networks for fine-grained recognition. ArXiv, 2017, art. 1603.06765. URL: https://arxiv.org/abs/1603.06765 (дата обращения: 15.06.2021). 8. Li Z., Yang Y., Liu X. et al. Dynamic computational time for visual attention. Proc. IEEE ICCVW, 2017, pp. 1199–1209. DOI: 10.1109/ICCVW.2017.145. 9. Uzkent B., Ermon S. Learning when and where to zoom with deep reinforcement learning. Proc. IEEE/CVF CVPR, 2020, pp. 12342–12351. DOI: 10.1109/CVPR42600.2020.01236. 10. Mousavi H.K., Nazari M., Takáč M. et al. Multi-Agent image classification via reinforcement learning. Proc. EEE/RSJ IROS, 2019, pp. 5020–5027. DOI: 10.1109/IROS40897.2019.8968129. 11. Елизаров А.А., Разинков Е.В. Классификация изображений с использованием обучения с подкреплением // Электронные библиотеки. 2020. T. 23. № 6. C. 1172–1191. DOI: 10.26907/1562-5419-2020-23-6-1172-1191. 12. He K., Zhang X., Ren S., Sun J. Deep residual learning for image recognition. Proc. IEEE/CVF CVPR, 2016, pp. 770–778. DOI: 10.1109/CVPR.2016.90. 13. Girshick R. Fast R-CNN. Proc. IEEE ICCV, 2015, pp. 1440–1448. DOI: 10.1109/ICCV.2015.169. 14. ImageNet Dataset. URL: http://image-net.org (дата обращения: 15.06.2021). 15. Papers with Code: Fine-Grained Image Classification. URL: https://paperswithcode.com/task/fine-grained-image-classification (дата обращения: 20.06.2021). 16. Mingxing T., Quoc V.L. EfficientNet: Rethinking model scaling for convolutional neural networks. ArXiv, 2019, art. 1905.11946v5. URL: https://arxiv.org/pdf/1905.11946.pdf (дата обращения: 15.06.2021). 17. Abdolmaleki A., Springenberg J.T., Degrave J. et al. Relative entropy regularized policy iteration. ArXiv, 2018, art. 1812.02256. URL: https://arxiv.org/abs/1812.02256 (дата обращения: 15.06.2021). 18. Auer P., Cesa-Bianchi N., Fischer P. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 2002, vol. 47, pp. 235–256. DOI: 10.1023/A:1013689704352. References
|

| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=4873&lang=&lang=&like=1 |
Версия для печати |
| Статья опубликована в выпуске журнала № 1 за 2022 год. [ на стр. 028-036 ] |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- О реализации средств машинного обучения в интеллектуальных системах реального времени
- Применение модели нейронных сетей для поддержки принятия решения абитуриента по выбору специальности
- Настройка и обучение многослойного персептрона для задачи выделения дорожного покрытия на космических снимках города
- Автоматизированное детектирование и классификация объектов в транспортном потоке на спутниковых снимках города
- Нейросетевой метод обнаружения вредоносных программ на платформе Android
Назад, к списку статей