Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Обобщенный метод иерархического подкрепленного обучения для интеллектуальных систем поддержки принятия решений
Аннотация:
Abstract:
| Авторы: Еремеев А.П. (eremeev@appmat.ru) - Национальный исследовательский университет «Московский энергетический институт» (профессор), г. Москва, Россия, доктор технических наук, Подогов И.Ю. () - | |
| Ключевые слова: интеллектуальные системы поддержки принятия решений, исппр, иерархическое обучение, метод |
|
| Keywords: , , , the method |
|
| Количество просмотров: 14289 |
Версия для печати Выпуск в формате PDF (1.83Мб) |
Интеллектуальные системы поддержки принятия решений (ИСППР) предназначены для помощи ЛПР при мониторинге и управлении сложными объектами и процессами в условиях достаточно жестких временных ограничений [1]. Это, как правило, – системы реального времени, одной из главных задач которых является помощь ЛПР для удержания объекта в штатном режиме функционирования и возвращения его в этот режим при возникновении отклонений. В [2] предложено конструировать ИСППР как интегрированные интеллектуальные системы семиотического типа, сочетающие строгие, формальные методы и модели поиска решений с нестрогими, эвристическими методами и моделями, базирующимися на знаниях специалистов-экспертов, моделях человеческих рассуждений, имитационных моделях, неклассических логиках и накопленном опыте [3]. Обобщенная архитектура ИСППР представлена на рисунке. ИСППР является по сути системой распределенного интеллекта, включающей ряд взаимодействующих между собой интеллектуальных блоков-модулей. К числу таких модулей относятся модули моделирования проблемной ситуации, прогнозирования, связи с внешними объектами, средства организации различного типа интерфейса с ЛПР. К интеллектуальным относятся также функции поиска (вывода) решения на базе моделей и методов представления и оперирования динамическими знаниями, характеризующимися недостоверностью, нечеткостью, неполнотой и противоречивостью. Поиск решения осуществляется с использованием механизмов неклассических (нечетких, псевдофизических – пространственно-временных и причинно-следственных, немонотонных логик), а также механизмов обучения и пополнения динамических знаний. ИСППР семиотического типа может быть задана набором [2] SS=<M, R(M), F(M), F(SS)>, где M={M1,…,Mn} – множество формальных или логико-лингвистических моделей, реализующих определенные интеллектуальные функции; R(M) – множество правил выбора необходимой модели или совокупности моделей в текущей ситуации, то есть правил, реализующих отображение R(M): S®M, где S – множество возможных ситуаций (состояний), которое может быть и открытым, или S'®M, где S' – некоторое множество обобщенных ситуаций, например, нормальных, аномальных или аварийных, при попадании в которые происходит смена модели; F(M)={F(M1),…,F(Mn)} – множество правил модификации моделей Mi, i=1,…,n. Каждое правило F(Mi) реализует отображение F(Mi): S''´Mi®M'i, где S''ÍS, M'i – некоторая модификация модели Mi;
Если процессы принятия решений строго формализованы, то для их описания может быть применена марковская модель, которая в общем виде может быть задана набором (S,A,T,R), где S – множество возможных состояний; A – множество допустимых воздействий на элементы из S; T: S×A→S – функция переходов (преобразования состояний); R: S×A→V – функция оценки, позволяющая оценивать итоги преобразований (V – некоторое упорядоченное множество). В общем случае функция переходов T является вероятностной и может быть определена посредством множества вероятностей переходов {Pi,j(a)}, где Pi,j(a) – вероятность события T(si,a)=sj. Функция R также может быть вероятностной. Известно, что для марковской модели процесса принятия решений эффект от воздействий зависит только от текущего состояния и не зависит от предыстории процесса, то есть справедливо соотношение s(t+Δt) = T(s(t),u(t),v(t)), где sÎS – текущее состояние; u(t)ÎA, v(t)ÎA – управляемые и неуправляемые (внешние) воздействия; Δt – дискрет времени. Таким образом, марковская модель не имеет памяти, так как предполагается, что знаний о текущем состоянии и о воздействиях достаточно для нахождения оптимального (стохастического оптимального – в случае вероятностной модели) решения (управления) для достижения целевого состояния. Однако марковская модель имеет ограниченное применение и ориентирована на ИСППР, предназначенные для статических проблемных областей, характеризующихся полнотой и достоверностью заложенных в систему знаний и поступающей для анализа информации от внешней среды или ЛПР. Для динамических проблемных областей условие полноты и достоверности поступающей информации может не выполняться. Это обусловлено различными факторами, например, сбоями или выходом из строя датчиков, неполным учетом внешних воздействий и т.д. В этих условиях марковская модель не дает адекватного описания проблемной области и необходимо использовать немарковскую модель, обладающую памятью и позволяющую учитывать предысторию изменения состояний. При этом справедливо соотношение s(t+Δt)=F(s(t), s(t-Δt), …, s(t-nΔt), u(t), u(t-Δt), …, u(t-mΔt), v(t),v(t-Δt)),…,v(t-kΔt)), где n, m, k – целые числа, удовлетворяющие ограничениям nΔt≤t, mΔt≤t, kΔt≤t. Заметим, что качество принимаемых решений можно улучшить, если учитывать информацию о последствиях принимаемых решений (о состояниях s(t+2Δt), s(t+3Δt) …), получаемую из базы знаний (если там накапливается информация о прошлом опыте) или от модуля прогнозирования ИСППР. Модель процесса принятия решений на основе подкрепленного обучения Рассмотрим немарковскую модель процесса принятия решений, способную посредством анализа предыстории процесса обучаться и настраиваться на специфику проблемной области и таким образом повышать качество принимаемых решений. Будем предполагать, что неполнота и недостоверность информации о текущем состоянии проблемной области, поступающей в ИСППР, в основном вызвана отсутствием или ошибочной работой датчиков (сенсоров). Для обучения будем использовать так называемое подкрепленное обучение (RL – Reinforcement Learning), активно используемое для обучения систем принятия решений с марковскими моделями посредством выявления имеющихся закономерностей на основе анализа предыстории процесса [2,5,6]. Подкрепленное обучение представляет класс задач, в которых автономный агент, действуя в определенной среде, должен найти оптимальную стратегию взаимодействия с ней. Информация для обучения автономного агента предоставляется в форме простого скалярного платежа, имеющего определенное количественное значение для каждого перехода среды из одного состояния в другое. При этом вполне возможна ситуация, в которой восприятие агента не позволяет точно определить текущее состояние среды, что приводит к более сложной задаче принятия решений в условиях неопределенности (так называемые задачи со скрытым состоянием). Задачи такого рода являются центральными в искусственном интеллекте, теории управления и исследовании операций. Формально задачу со скрытым состоянием можно описать как кортеж <S,A,T,R,Ω,O>, где S – конечный набор состояний среды; A – конечный набор действий; T: S´A®Δ(S) – функция перехода состояний, дающая распределение состояний среды по начальному состоянию и выполненному агентом действию; R: S´A®Â – функция вознаграждений, дающая действительное число (ожидаемую немедленную выплату) по начальному состоянию и выполненному агентом действию; Ω – конечный набор наблюдений, которые может сделать агент; O: S´A®Δ(Ω) – функция наблюдений, дающая распределение возможных наблюдений по начальному состоянию и выполненному агентом действию [6]. Заметим, что подкортеж <S,A,T,R> представляет лежащий в основе задачи марковский процесс принятия решений. Если бы функция наблюдений давала истинное (скрытое) состояние среды с абсолютной уверенностью, проблема свелась бы к полностью обозримому марковскому процессу, и для решения задачи можно было бы эффективно применить, например, методы динамического программирования. Однако в общем случае это не так: одно и то же наблюдение может иметь место в более чем одном состоянии среды и эти состояния могут требовать выполнения разных действий. В такой ситуации целесообразно применить один из методов подкрепленного обучения. Хотя подкрепленное обучение, по сути, базируется на методе проб и ошибок, оно имеет ряд достоинств для применения в ИСППР реального времени, ориентированных на динамические и открытые проблемные области. Один из наиболее простых и популярных подходов к решению задач подкрепленного обучения заключается в нахождении и поддержании оценочной функции состояний и действий Q(s,a), которая приближает ожидаемый возврат для текущего состояния после выполнения каждого из действий, так что
Из этого равенства и определения возврата следует:
где α – скорость обучения, соответствующая тому, насколько агрессивно новые наблюдения включаются в приближение. Как только оценочная функция получена, определяемая ей стратегия (известная как жадная стратегия) получается простым выбором действия с максимальной оценкой для данного состояния: На основе этого базового метода строится большинство алгоритмов, использующих оценочную функцию. Шаг, связанный с вычислением зависимости (1) (уравнения Беллмана), в том или ином виде входит практически во все методы итеративного подкрепленного обучения. Сама функция Q(s,a) может задаваться различными способами в зависимости от задачи: как простая таблица значений, как множество накопленных ощущений с аппроксимацией для непосещенных областей пространства состояний-действий, а также как искусственная нейронная сеть (или множество сетей, см. [4]), дающая для заданного состояния приближение функции Q. Использование нейронной сети позволяет учитывать наблюдения большого объема (в том числе для случая, когда множество состояний является непрерывным), достаточно быстро формировать оценочную функцию и оперативно обновлять ее значения. Кроме того, нейронные сети по своей природе обладают возможностью поиска решений на основе аналогии. Одна из проблем Q-обучения заключается в том, что оценка возврата среды осуществляется только для текущего состояния, независимо от того, какая последовательность событий предшествовала ему. Точнее, агент должен делать свой выбор на основе наблюдения, которое среда дает ему в качестве информации о своем состоянии. Многие исследователи отметили, что фундаментальной проблемой является наложение восприятия, то есть ситуация, в которой несколько состояний системы наложены на одно наблюдение. Эту проблему называют также проблемой скрытого состояния, или неполного восприятия. В этих условиях стратегии без памяти, очевидно, неэффективны в общем случае, поскольку они могут ассоциировать максимум одно действие с каждым наблюдением. Одно из решений этой проблемы – организовать некоторую память, чтобы агент мог пытаться использовать свои прошлые ощущения для устранения двусмысленностей наложенных состояний и действовать соответственно. Вид этой памяти может быть различным: от простого окна, хранящего несколько предшествующих наблюдений, рассматриваемых как единое описание состояния, до полной предыстории событий, возможно, организованной в некоторую древовидную или иную структуру для удобства поиска [2,5,10]. Иерархическое подкрепленное обучение Методы иерархического подкрепленного обучения обладают необходимым потенциалом для поиска решения в случае задач большого масштаба. В различных приложениях возможно применить несколько уровней представления задачи, так что естественно декомпозировать пространство состояний с целью абстрагирования от ненужных деталей. Например, независимо от того, надо ли в задаче навигации агенту добраться до точки на другой стороне улицы или на окраине города, стратегия выхода из текущего помещения должна быть одной и той же. Иерархическая организация обучения также позволяет осуществлять координацию обучения множества агентов (возможно, с различными методами обучения) на разных уровнях. Еще одно достоинство такого подхода – повторное использование накопленного опыта: агент, обученный некоторому полезному поведению, может быть применен к совершенно другой задаче без необходимости повторного обучения. Наконец, использование иерархического подкрепленного обучения позволяет перейти к так называемым полумарковским процессам, в которых длительность выполнения отдельного действия может занимать больше одного шага времени. Существует множество методов иерархического подкрепленного обучения, но из них мы рассмотрим только два, наиболее подходящих для использования в ИСППР реального времени. В работе [8] в рамках так называемой иерархической абстракции машин (HAM – hierarchical abstraction of machines) используется стратегия на основе построения иерархий контроллеров с конечными состояниями, каждый из которых может вызывать другой как процедуру. Можно показать, что в случае полностью обозримого марковского процесса данная стратегия оптимальна по отношению к ограничениям, накладываемым контроллерами в иерархии. HAM является, по сути, программой, которая при выполнении агентом в среде ограничивает действия, которые агент может выполнить в каждом состоянии. Например, для задачи-лабиринта очень простая машина может предложить агенту стратегию «периодически двигайся вправо или вниз», что исключит из рассмотрения все стратегии, которые предусматривают движение вверх или влево. HAM расширяют эту простую идею ограничивающих стратегий, предоставляя иерархические средства представления ограничений на разных уровнях детализации и специфики. Машины для HAM определяются набором состояний, функцией переходов и исходным состоянием машины, которое может быть одним из следующих: · состояния действия – исполняют действия в среде; · состояния вызова – исполняют другие машины как подпрограммы; · состояния выбора – недетерминистически выбирают следующее состояние машины; · состояния остановки – прекращают выполнение машины и возвращают управление предыдущему состоянию вызова. Функция переходов определяет следующее состояние машины после состояния действия или вызова как стохастическую функцию текущего состояния машины и некоторые особенности результирующего состояния среды. Машины обычно будут использовать частичное описание среды для определения следующего состояния. Хотя машины могут функционировать в частично обозримых областях, можно для простоты сделать стандартное предположение, что агент обладает также доступом к полному описанию состояния. Метод HAM может дать большее преимущество в контексте подкрепленного обучения, где затраты, требуемые для получения решения, плохо масштабируются с размером задачи. Ограничения HAM могут сфокусировать исследование пространства состояний, уменьшив фазу слепого поиска, через которую должны пройти агенты подкрепленного обучения во время изучения новой среды. Обучение также будет проходить быстрее, так как агент эффективно оперирует в редуцированном пространстве состояний. Однако данный метод несколько отходит от приведенного ранее формального описания задачи подкрепленного обучения, так как вводит состояния разного типа. Другой подход к иерархическому подкрепленному обучению − HSM (Hierarchical Short-term Memory) [9] основывается на использовании только одного агента, но при наличии нескольких уровней памяти. Применяя кратковременную память на абстрактных решениях, каждое из которых использует иерархию поведений, можно применить память на более информативном уровне абстракции. Особенность такого подхода состоит в том, что агент может получать информацию о точке принятия решения, имевшей место много шагов времени назад, игнорируя точную последовательность низкоуровневых наблюдений и выполненных действий. Приведем алгоритм иерархического подкрепленного обучения на основе HSM-метода. 1. Для данного уровня абстракции l и точки выбора s: для каждого потенциального будущего решения d исследовать историю на уровне l для поиска множества прошлых точек выбора, выполнивших d и тех, чьи входящие (суффиксные) предыстории ближе всего совпадают с предысторией текущей точки. Это множество примеров называется конфликтным множеством для решения d. 2. Выбрать dt как решение с наибольшей дисконтированной суммой выплат из конфликтного множества, время от времени выбирать dt, используя стратегию исследования, где t – счетчик текущей точки принятия решения на уровне l. 3. Выполнить решение dt и записать: ot –результирующее наблюдение; rt, – полученную выплату; nt – длительность абстрактного действия (измеряется числом примитивных переходов среды, выполненных абстрактным действием). Отметим, что для каждого перехода из состояния si-1 в состояние si с выплатой ri и скидкой γ накапливается всякая выплата и обновляется множитель скидки: rt+1←rt+γtri, γt+1←γ γt. 4. Используя следующее правило (2) полумарковского Q-обучения, обновить Q-величину текущей точки принятия решения. Также обновить Q-величину аналогично для каждого примера в конфликтном множестве, используя величины решения, выплаты и длительности, записанные вместе с экземпляром:
Таким образом, метод HSM сочетает в себе две особенности – иерархический подход к обучению и использование памяти для различения наложения восприятия, что делает его особо привлекательным для применения в СППР реального времени. Рассмотренные два подхода к иерархическому обучению – HAM и HSM – можно представить в обобщенном виде. Допустим, имеется обычный процесс принятия решений, в котором жестко разделяются состояния (представляемые кортежем параметров среды) и действия (неделимые произвольные воздействия из заранее определенного множества воздействий над средой). Не расширяя формализм, добавим возможность использования методов иерархической абстракции машин, объединив подмножества состояний, в которых выполняются действия, и состояния вызова других машин, в единое множество действий. Состояние выбора естественным образом войдет в функцию переходов (функция T в исходном формализме). По сути, исходная задача разбивается на подзадачи, для каждой из которых создается отдельный агент: AG={agi}, i = 1..k. Каждый из агентов работает со своим подмножеством состояний среды и набором действий над средой (результатом действия может стать передача управления другому агенту): S=S1×S2×…×Sv; agi=<(Si 1×…×Si m), {ai 1,…,ai l }, π>. Приведем обобщенный алгоритм иерархического подкрепленного обучения. 1. Для текущего агента ag выбрать текущее действие at на основе предыстории текущего состояния st, например, методом вспомогательных суффиксов (Utile Suffix Memory, USM [9]): 2. Выполнить действие at. Если в результате действия произошла передача управления другому агенту, обозначить предыдущего агента как пассивно получающего выплаты. 3. Для текущего агента записать: результирующее наблюдение ot; полученную выплату rt. Если до предыдущего шага текущий агент получал выплаты пассивно, прибавить текущую выплату к накопленной сумме с учетом накопленного множителя скидки: rsum←rsum+γt ∙ rt. Для всех агентов, обозначенных как пассивно получающие выплаты, при каждом переходе из состояния st-1 в состояние st с выплатой rt и скидкой γ накапливается всякая выплата и обновляется множитель скидки: rsum←rsum+γt ∙ rt, γt+1←γ ∙ γt. 4. Выполнить шаг обновления оценочной функции для текущего агента согласно методу USM. Перейти на шаг 1. Таким образом, используется прежний формализм описания задач подкрепленного обучения с той лишь разницей, что в описании действий агентов возможно появление операторов переключения текущего агента. Такой механизм является более общим, чем в методе HAM, так как позволяет определять задачи высокого уровня как произвольную последовательность состояний, являющихся задачами более низкого уровня. В то же время, накопление выплат, которые даются агенту как вознаграждение за передачу управления другому агенту, производится аналогично тому, как это делается в методе HSM. Фактически описанный метод позволяет реализовать оба механизма иерархического подкрепленного обучения, обобщая их и делая более универсальным для применения в ИСППР. Список литературы 1. Вагин В.Н., Еремеев А.П. Некоторые базовые принципы построения интеллектуальных систем поддержки принятия решений реального времени // Изв. РАН: Теория и система управления, 2001. - № 6. – С. 114-123. 2. Еремеев А.П., Тихонов Д.А., Шутова П.В. Поддержка принятия решений в условиях неопределенности на основе немарковской модели // Там же. 2003. - № 5. - С. 75-88. 3. Поспелов Д.А. Логико-лингвистические модели в системах управления. - М.: Энергоиздат, 1981. 4. Lin L-J. and Mitchell T. Memory approaches to reinforcement learning in non-Markovian domains. Technical Report CMU-CS-92-138, Carnegie Mellon University, 1992. 5. Hasinoff S. Reinforcement Learning for Problems with Hidden State, Technical Report, University of Toronto, Department of Computer Science, 2003. 6. Kaelbling L., Littman M. and A. Cassandra. Planning and acting in partially observable stochastic domains. Artificial Intelligence, 101, 1998. 7. Еремеев А.П., Подогов И.Ю. Методы подкрепленного обучения для систем поддержки принятия решений реального времени // Тр. междунар. науч.-технич. конф.– М.: Янус-К, 2006. – Т.3. 8. Parr R. and Russell S. Reinforcement learning with hierarchies of machines. In Advances in Neural Information Processing Systems 10, 1998. – р. 1043-1049. 9. Hernandez-Gardiol N. and Mahadevan S. Hierarchical memory-based reinforcement learning. In Advances in Neural Information Processing Systems 13, 2000. 10.McCallum R.A. (1995b). Instance-based utile distinctions for reinforcement learning with hidden state. In Proceedings of the Twelfth International Conference on Machine Learning, p. 387-395. |
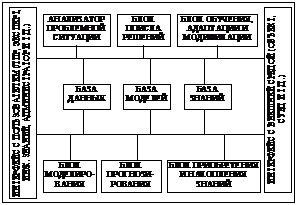 F(SS) – правило модификации собственно системы SS – ее базовых конструкций M, R(M), F(M) и, возможно, самого правила F(SS), то есть F(SS) реализует ряд отображений (или комплексное отображение) F(SS): S'''´M®M', S'''´R(M)® ®R'(M), S'''´F(M)®F'(M), S'''´F(SS)®F'(SS), где S'''ÍS, S'''ÇS'=Æ, S'''ÇS''=Æ, то есть правила модификации данного типа используются в ситуациях, когда имеющихся множеств моделей, правил выбора и правил модификации недостаточно для поиска решения (решений) в сложившейся проблемной ситуации. Причем для модификации F(SS) могут быть использованы как внутренние средства порождения моделей и правил (гипотез), так и внешние метазнания, отражающие прагматический аспект проблемной ситуации.
F(SS) – правило модификации собственно системы SS – ее базовых конструкций M, R(M), F(M) и, возможно, самого правила F(SS), то есть F(SS) реализует ряд отображений (или комплексное отображение) F(SS): S'''´M®M', S'''´R(M)® ®R'(M), S'''´F(M)®F'(M), S'''´F(SS)®F'(SS), где S'''ÍS, S'''ÇS'=Æ, S'''ÇS''=Æ, то есть правила модификации данного типа используются в ситуациях, когда имеющихся множеств моделей, правил выбора и правил модификации недостаточно для поиска решения (решений) в сложившейся проблемной ситуации. Причем для модификации F(SS) могут быть использованы как внутренние средства порождения моделей и правил (гипотез), так и внешние метазнания, отражающие прагматический аспект проблемной ситуации.| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=737 |
Версия для печати Выпуск в формате PDF (1.83Мб) |
| Статья опубликована в выпуске журнала № 2 за 2008 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Метод автоматической кластеризации текстов и его применение
- Основы моделирования системы поддержки принятия решений по комплексному применению сил и средств ПВО надводных кораблей
- Оценка эффективности тренажерной подготовки методом целевого управления
- Способы повышения эффективности отладки и тестирования многопроцессорных систем
- Программная система реструктуризации группы предприятий электроэнергетики
Назад, к списку статей