Авторитетность издания

Добавить в закладки
Следующий номер на сайте


Структурно-параметрическая идентификация функций занятости и прогнозирование спроса на молодых специалистов
Аннотация:
Abstract:
| Авторы: Семенов Н.А. (dmitrievtstu@mail.ru) - Тверской государственный технический университет (профессор кафедры «Информационные системы»), г. Тверь, Россия, доктор технических наук, Шалунова М.Г. () - | |
| Ключевое слово: |
|
| Ключевое слово: |
|
| Количество просмотров: 18379 |
Версия для печати Выпуск в формате PDF (1.58Мб) |
В Федеральной Программе развития образования подчеркивается необходимость создания служб маркетинга и информационно-рекламного обеспечения в образовательных учреждениях, позволяющих поддерживать эффективную систему мониторинга и обеспечивающих сбор образовательной статистики. Принятие обоснованных решений по объему и структуре подготовки специалистов в регионе требует разработки моделей прогнозирования потребности отраслей экономики в кадрах специалистов, моделей оценки перспективности и качества образовательных услуг (ОУ) [1], реализуемых в информационных системах административного управления профессиональными образовательными учреждениями. Оказание актуальных ОУ повысит конкурентоспособность молодых специалистов, эффективность инвестиций в образование. Динамическая модель планирования потребности экономики в образовании, предложенная Ж. Тинбергеном и Х. Босом, выражает связь между численностью работников со средним и высшим образованием и объемом производства в стране. Применение этого подхода ограничено рамками периода стабильного экономического развития, на котором при достаточной статистической базе выявлены достоверные связи социально-экономических показателей. Большинство современных исследований зарубежных ученых опираются на выборочные исследования структуры спроса на специалистов. В своих работах отечественные исследователи пытаются учесть переходный характер процессов в экономике России, неполную занятость и неформальный сектор. Следует отметить несколько подходов к расчету потребности отраслей экономики в трудовых ресурсах, например, потоковые динамические модели (А.Н. Марюты), модель движения рабочих мест (А.Г. Коровкина, К.В. Парбузина), макроэкономические (А.С. Семенова, С.Г. Кузнецова), нейросетевые, адаптивные, трендовые, экспертные, нечеткие модели [2]. Многие исследователи отмечают оценочный характер таких расчетов. В работе А.Н. Марюты разработана динамическая модель движения трудовых ресурсов в промышленном регионе, включающая семь групп населения. По нашему мнению, социально-трудовая сфера должна рассматриваться в комплексе с макроэкономическими факторами региона (города). В монографии [3] И.Г. Акперов предлагает методику прогнозирования совокупной и дополнительной потребности в специалистах для экономики региона, результатные данные позволяют планировать выпуск, ресурсы и бюджет системы образования на перспективу. Автором предусмотрено два сценария: для стационарной экономики (прогноз объема производства по трендовым моделям) и для переходной экономики (экспертная оценка). Эконометрическая модель прогноза потребности в специалистах И.Г. Акперова учитывает динамику трудовых ресурсов, эластичность производства по труду, темп НТП. Система регрессионных уравнений, предлагаемая А.С. Семеновым и С.Г. Кузнецовым, выражает зависимости индексов численности занятых, потребительских цен, инвестиций в основной капитал, среднего возраста основных производственных фондов, ВВП, реальной заработной платы. Таким образом, современные исследования по прогнозированию спроса на специалистов проводятся в следующих направлениях: построение баланса трудовых ресурсов, анализ и прогноз кадровой ситуации на предприятиях и в организациях, макроэкономические тенденции спроса на рабочую силу, выборочные обследования населения, экспертные опросы. Рассмотренные модели основываются на традиционных методах прогнозирования: экстраполяции, корреляционном, регрессионном анализе, моделях Маркова, которые требуют надежной статистической базы. Наличие коротких временных рядов социально-экономических показателей ставит под вопрос обоснованность применения некоторых моделей. В настоящее время исследуются возможности применения нейронных сетей, методов эволюционного программирования, генетических алгоритмов для моделирования в социально-трудовой сфере. В нашей работе предлагается методика моделирования и прогнозирования спроса на специалистов в регионе (городе).
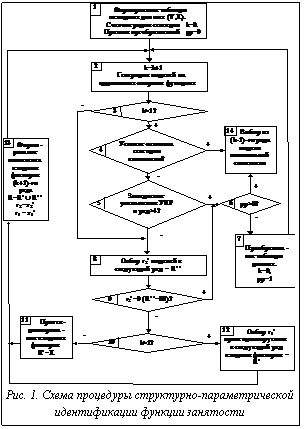
Особенностями МГУА по сравнению с другими алгоритмами структурной идентификации, а также регрессионного анализа являются: использование внешних критериев при отборе моделей, использование коротких зашумленных рядов, постепенное усложнение модели. Использование МГУА при моделировании функций занятости обусловлено достаточной точностью результатов при структурно-параметрической идентификации моделей и прогнозировании экономических объектов при большом числе факторов и малых выборках (фактически имеется статистическая база рядов показателей X за 6-9 лет), когда применение методов регрессионного и факторного анализа не давало положительного результата. Исследователи отмечают [4], что МГУА дает более статистически значимые результаты, чем нейросети и генетические алгоритмы, хотя нейросети являются одним из направлений развития МГУА, а идеи генетических алгоритмов и МГУА схожи. Объем выборки и характер принятых зависимостей позволили нам выбрать для решения задачи идентификации отраслевых функций занятости многорядный алгоритм МГУА. С одной стороны, высокая изначальная взаимозависимость входных факторов X функций занятости (что отмечается для экономических показателей) требует протекции исходных X на каждом ряду селекции. С другой стороны, наличие малых выборок при моделировании требует сокращения рядов селекции, следовательно, степени свободы. Эти противоречивые требования послужили основанием для разработки модификации многорядного алгоритма МГУА, обобщенная схема которого представлена на рисунке 1. Предварительный корреляционный анализ позволяет учесть лаговые взаимодействия факторов, на основании которого строится таблица исходных данных. Множество факторов, учитываемых без лага, – X1,q, с лагом – X2,q. На первом ряду образуются частные аддитивные модели, попарно учитывающие аргументы Xq: 1-й ряд: yjl1=b0+b1· xjq +b2· xlq, j,l=1,…, m; j Среди сгенерированных моделей-претендентов осуществляется отбор r2 моделей, которые становятся входными факторами для следующего ряда; в целях устранения возможности потери важных r1 исходных факторов xj и повышения обусловленности информационной матрицы на каждом ряду селекции в качестве входных факторов предлагается учитывать эти исходные факторы xj, j=1, …, r1. Протекция исходных факторов, как отмечает А.Г. Ивахненко [5], сводит ошибку многорядного алгоритма к нулю. Тогда для k-го ряда выбранные в предыдущем ряду r2 моделей (множество R’’) и r1 исходных факторов (множество R’) снова попарно комбинируются в частных моделях:
где yk-1 – входные факторы k-го ряда селекции.
Принципы отбора моделей формулируются в критериях селекции. Критерий регулярности рекомендуется для краткосрочного прогноза, поэтому он выбран в качестве основного в нашем исследовании. Критерий регулярности определяет среднеквадратичное отклонение модели на проверочной выборке nB:
При очень коротких временных рядах деление таблицы на две части нецелесообразно, в этом случае применяется усредненный критерий регулярности (УКР), который равен среднему значению критериев регулярности, рассчитанных при выделении всех n точек по одной в проверочную последовательность nB=1, остальные точки служат для обучения:
При отборе моделей исследователь задает степень свободы выбора F, определяющую количество селекционируемых наилучших моделей из потока сгенерированных. Нами предлагается от каждого входного фактора ряда отбирать по одной наилучшей модели, имеющей минимальную величину УКР. Обозначим лучшую модель k-го ряда yzk, имеющую наименьшее значение УКР УКРkmin. В качестве дополнительного критерия, оценивающего ошибку модели, используется дисперсионное отношение
где Критерием останова селекции служит увеличение или неизменность УКР либо замедление уменьшения УКР. Если на k-м ряду УКРkmin ≥ УКРk-1min, то на (k-1)-м ряду получена модель оптимальной сложности yzk-1, являющаяся результатом структурно-параметрической идентификации. Второй причиной останова нами выделяется замедление уменьшения УКР УКРk-1min ∙ 0,98 < УКРkmin при большом количестве рядов селекции (k>4). При выводе условия принимаем, что на k-м ряду наблюдается замедление уменьшения УКР, если уменьшение среднего отклонения произошло менее 1%. В этом случае необходим переход к мультипликативному классу опорных функций, для этого таблица исходных данных логарифмируется, и процесс поиска оптимальной модели начинается вновь. То же самое осуществляется, если R’’=Ø. Множество протекционируемых на 2-й ряд входных факторов R’ соответствует множеству факторов X. Из множества протекционированных на k-м (k≠1) ряду факторов R’={y1k-1, …, yr1k-1} исключаются те yjk-1, которые имеют нулевые коэффициенты ajz у лучшей модели yzk и у более чем 50% отобранных на k-м ряду моделей (R’’). Схема структурно-параметрической идентификации функции занятости по разработанному алгоритму представлена на рисунке 2. Практические результаты применения разработанной модификации алгоритма МГУА (РА) при моделировании численности занятых в отраслях экономики и промышленности Тверской области за 1993-1999 гг. показали ее высокую эффективность. Функции занятости были построены с помощью следующих программных продуктов: пакет статистического анализа STATGRAPHICS PLUS 2.1 for Windows (SG), диалоговая программная система МГУА (ДПС МГУА), реализующая комбинаторный (COMBI) и селективный методы (MIA) МГУА [6]. В таблице 1 приведены результаты сравнительного анализа прогностических свойств тридцати моделей, построенных по данным за 1993-1998 гг. с помощью систем SG, ДПС МГУА и программы, разработанной на основе РА. Таким образом, средняя абсолютная ошибка ретроспективного прогноза модифицированного алгоритма (4.19 %) в 2 раза меньше ошибки метода пошаговой регрессии (9.45%). При структурно-параметрической идентификации с помощью РА количество просматриваемых моделей в 2 раза меньше, чем с COMBI, и в 1,4 раза меньше, чем с MIA.
Функция занятости q-й отрасли с постоянными коэффициентами Aq отражает характер связи переменных в среднем за период. В целях повышения точности краткосрочного прогноза применяется метод адаптации коэффициентов множественной регрессии. Корректировка Aq осуществляется по формуле Aнq,t = Aсq,t + 2·kt·et·Xtq, t = 1,…,n, где et = cqt - yq,t – оценка отклонения модельных данных и фактической численности занятых в q-й отрасли;
r – количество факторов в функции занятости; a – коэффициент адаптации, 0 Адаптация коэффициентов многофакторных функций занятости Тверской области, построенных по данным за 1993-1998 гг., позволила в среднем снизить ошибку прогноза на 1999 г. с 4,19% до 3,2%. Для прогнозирования численности занятых в отрасли экономики (промышленности) необходимы прогнозные значения учитываемых без лага экзогенных факторов функций занятости
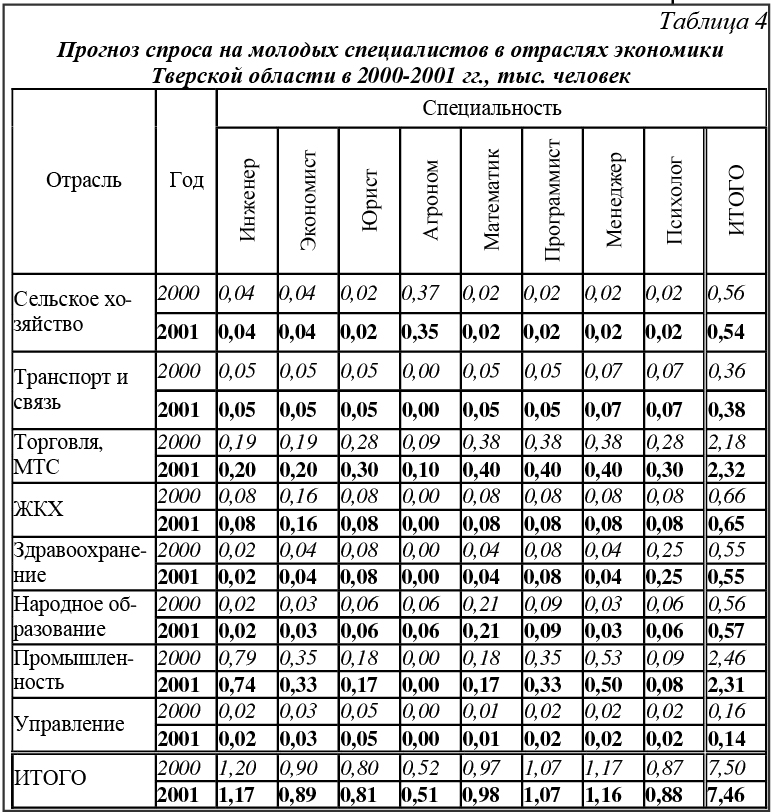
Таким образом, краткосрочный прогноз численности занятых в q-й отрасли рассчитывается по формуле yq=f(Aнq,n, X2,q, Спрос на специалистов необходимо корректировать с учетом значительного в некоторых отраслях неформального сектора, оценивать который возможно методами выборочных обследований и экспертного опроса. Нами предлагается прогнозировать спрос q-й отрасли на молодых специалистов i-го направления по формуле Пqi= yq · Кq ·Дqгс · Дqм · wiq · (1+ Дqнс), где Кq – коэффициент оборота кадров по приему; Дqгс – доля работников оцениваемых специальностей; Дqм – доля молодых специалистов в потоке приема; wiq – вес (приоритет) специальности в отрасли; Дqнс – доля неформального сектора. Отраслевые коэффициенты весомости специальностей рассматриваемой группы оцениваются методом попарных сравнений Саати.
Программное средство, реализующее структурно-параметрическую идентификацию функций занятости и прогнозирование спроса на молодых специалистов, выполнено в инструментальной среде Visual Basic for Applications для Microsoft Excel 2000 под Windows 98 и является компонентом системы поддержки принятия решений по планированию структуры предложения ОУ [1]. Выбор среды обусловлен особенностями информационного обеспечения (табличная организация входных, промежуточных (при селекции моделей) и выходных данных), возможностями использования функций и надстроек Microsoft Excel 2000 (типовых проектных решений), совместимостью с программными средствами Microsoft. Результаты программы могут использоваться при принятии обоснованных решений в профессиональных образовательных учреждениях регионального и городского уровней, в органах муниципального управления образованием, службах занятости региона и города, в городской студенческой бирже труда, комитете по делам молодежи. По мере накопления и структуризации данных в информационных системах мониторинга рынков труда и ОУ для решения поставленной задачи эффективным средством может стать Data Mining – технология интеллектуального анализа данных. Список литературы 1. Семенов Н.А., Шалунова М.Г. Система поддержки принятия решений по планированию профессиональной структуры подготовки специалистов // Программные продукты и системы. - 2000. - №3. - С. 39-43. 2. Шалунова М.Г. Управление подготовкой кадров специалистов на региональном уровне // Сб. науч. тр.: Математика. Компьютер. Образование.- Вып. 6. - Ч. 2. - М.: Прогресс-Традиция, 1999. – С. 550-555. 3. Акперов И.Г. Прогнозирование потребности в специалистах и управление региональной системой образования. – М.: Высш. шк., 1998. – 306 с. 4. Киселев М., Соломатин Е. средства добычи знаний в бизнесе и финансах // Открытые системы. – 1997. - № 4. – С. 41-44. 5. Ивахненко А.Г., Мюллер Й.А. Самоорганизация прогнозирующих моделей. – К.: Технiка, 1985; Берлин: ФЕБ Ферлаг Техник, 1984. – 223 с. 6. Михеев В.Н. Диалоговая программная система структурно-параметрической идентификации с использованием нестандартных методов математического моделирования // Дис. канд. техн. наук: 05.13.16. – Тверь: ТГТУ, 1995. – 144 с. |
 Структурно-параметрическую идентификацию функции занятости q-й отрасли экономики (промышленности) yq=f(Aq, Xq), (где Aq – вектор параметров; Xq – вектор входных факторов) нами предлагается реализовать методом группового учета аргументов (МГУА). Макроэкономические регрессионные модели А.С. Семе-нова и производственные функции послужили теоретической основой наших исследований зависимости численности занятых в q-й отрасли экономики (промышленности) – Сq от следующих факторов: валового выпуска (объема производства, оказания услуг) – x1q (П), реальной среднемесячной заработной платы – x2q (З), рентабельности реализованной продукции (услуг) – x3q (Р), вакантных рабочих мест – x4q (В), инвестиций в основной капитал – x5q (И). Поэтому применяемыми видами зависимости являются аддитивные и мульти- пликативные.
Структурно-параметрическую идентификацию функции занятости q-й отрасли экономики (промышленности) yq=f(Aq, Xq), (где Aq – вектор параметров; Xq – вектор входных факторов) нами предлагается реализовать методом группового учета аргументов (МГУА). Макроэкономические регрессионные модели А.С. Семе-нова и производственные функции послужили теоретической основой наших исследований зависимости численности занятых в q-й отрасли экономики (промышленности) – Сq от следующих факторов: валового выпуска (объема производства, оказания услуг) – x1q (П), реальной среднемесячной заработной платы – x2q (З), рентабельности реализованной продукции (услуг) – x3q (Р), вакантных рабочих мест – x4q (В), инвестиций в основной капитал – x5q (И). Поэтому применяемыми видами зависимости являются аддитивные и мульти- пликативные.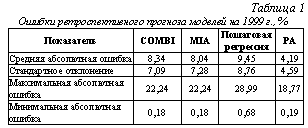 k-й ряд: yjlk=b0+b1· yjk-1 +b2· ylk-1, l=1,…, j-1, j= r1+1, …, r1+r2 ;
k-й ряд: yjlk=b0+b1· yjk-1 +b2· ylk-1, l=1,…, j-1, j= r1+1, …, r1+r2 ;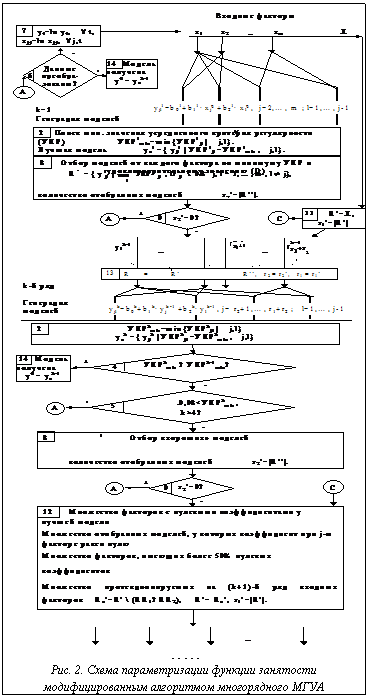

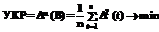 .
.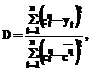
 – средняя численность занятых в q-й отрасли. На 1-м ряду пропускаются модели при D<0,8; на последующих – при D<0,5. Отобранные таким образом модели образуют множество R’’.
– средняя численность занятых в q-й отрасли. На 1-м ряду пропускаются модели при D<0,8; на последующих – при D<0,5. Отобранные таким образом модели образуют множество R’’.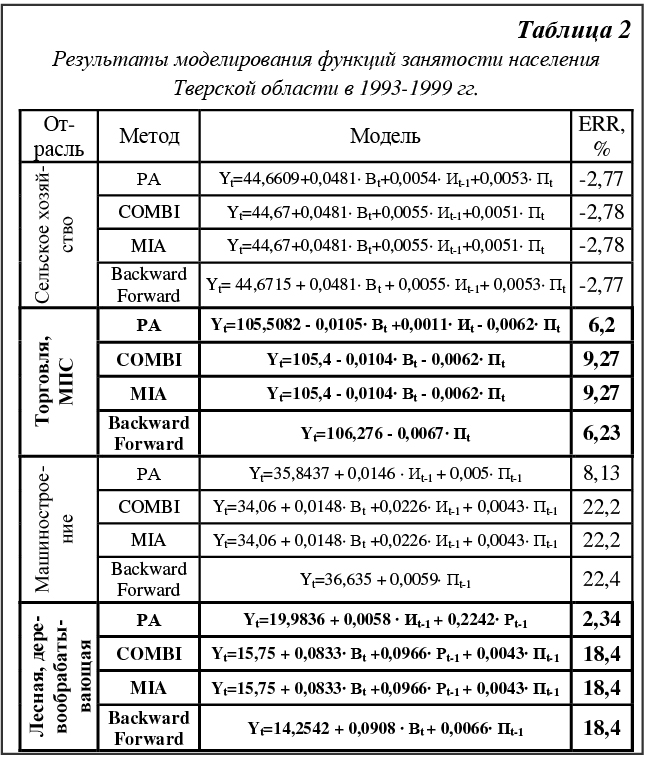
 ,
, , для получения которых нами предлагается применять адаптивные методы, позволяющие строить самокорректирующиеся экономико-математические модели. Годовые уровни макроэкономических показателей, используемые в исследовании, аппроксимируются наилучшим образом зачастую линейно-аддитивными и линейно-мультипликативными трендами. Для прогнозирования входных факторов
, для получения которых нами предлагается применять адаптивные методы, позволяющие строить самокорректирующиеся экономико-математические модели. Годовые уровни макроэкономических показателей, используемые в исследовании, аппроксимируются наилучшим образом зачастую линейно-аддитивными и линейно-мультипликативными трендами. Для прогнозирования входных факторов  нами используются модель Хольта (Х), модель адаптивного сглаживания Брауна (Б) и модель Муира (М), результаты которых являются составляющими комбинированного прогноза показателя
нами используются модель Хольта (Х), модель адаптивного сглаживания Брауна (Б) и модель Муира (М), результаты которых являются составляющими комбинированного прогноза показателя
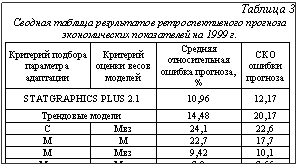 где w – веса моделей. Критерием поиска оптимальных значений параметров адаптации моделей и весов составляющих комбинированного прогноза является минимум средней взвешенной относительной ошибки прогноза. Результаты показывают достаточную эффективность прогноза по комбинированной модели (табл. 3). В таблице 3 приняты следующие обозначения: С – средний квадрат ошибки; М – средняя относительная ошибка прогноза; Мвз – средняя взвешенная относительная ошибка прогноза.
где w – веса моделей. Критерием поиска оптимальных значений параметров адаптации моделей и весов составляющих комбинированного прогноза является минимум средней взвешенной относительной ошибки прогноза. Результаты показывают достаточную эффективность прогноза по комбинированной модели (табл. 3). В таблице 3 приняты следующие обозначения: С – средний квадрат ошибки; М – средняя относительная ошибка прогноза; Мвз – средняя взвешенная относительная ошибка прогноза. ).
).
| Постоянный адрес статьи: http://swsys.ru/index.php?page=article&id=830&lang= |
Версия для печати Выпуск в формате PDF (1.58Мб) |
| Статья опубликована в выпуске журнала № 2 за 2001 год. |
Возможно, Вас заинтересуют следующие статьи схожих тематик:
- Эвристические и точные методы программной конвейеризации циклов
- Алгоритмы и процедуры построения билинейных моделей непрерывных производств
- Подход к выбору оптимального маршрута при перевозке крупногабаритных грузов на основе нейросетевых технологий
- Информационная система оптимизации расписания доставки грузов от производителей сырья
- Системы баз данных и знаний, разработанные в Республике Куба
Назад, к списку статей