Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: () - , () - | |
| Keywords: , semantics, attributes, network |
|
| Page views: 14469 |
Print version Full issue in PDF (1.92Mb) |
Современные задачи управления требуют консолидации информации. Необходимы средства интегрирования, которые обеспечивали бы не только унифицированный доступ к продолжающим функционировать базам данных, но и позволяли бы создать инфраструктуру для доступа к данным, опирающуюся на единые стандарты и единые принципы сетевого взаимодействия. Решение задачи интегрирования баз данных включает в себя интегрирование данных и интегрирование схем данных.
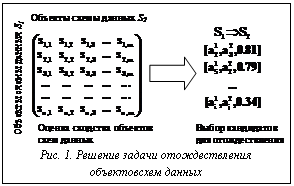
Рассмотрим задачу интегрирования схем данных. Пусть заданы две схемы данных В работе Ronkainen Pirjo “Attribute Similarity and Event Sequence Similarity in Data Mining” (University of Helsinki Report, 1998) показано, что для построения такого рода бинарного отношения необходимо выполнить два основных шага (рис. 1). Первым шагом является построение матрицы оценок семантического сходства объектов. Элементами этой матрицы являются значения оценок семантического сходства пар объектов, построенные с помощью некоторого метода оценки сходства. Определение семантического сходства объектов является нетривиальной задачей, которая в настоящее время окончательно не решена. На основе построенных оценок семантического сходства необходимо выбрать пары объектов для отождествления, которые в совокупности и образуют бинарное отношение соответствия, необходимое для решения задачи интегрирования схем данных. Оценка семантического сходства объектовсхем данных Пусть Определим функцию:
где Определим функцию:
Определим функцию:
где Примем значение функции Для множества шаблонов
Таким образом, задача семантической характеристики некоторого атрибута множеством шаблонов может быть сведена к решению задачи максимизации функции семантической значимости. Для решения задачи максимизации функции семантической значимости используем генетический алгоритм (рис. 2).
Рассмотренный генетический алгоритм поиска шаблонов позволяет для каждого атрибута Исходя из указанного предположения, рассмотрим следующую функцию:
данная функция принимает значения на отрезке [0, 1]. Максимальное значение функция принимает тогда, когда для всех шаблонов из множества Предложенная оценка семантического сходства атрибутов может быть использована как база для оценки сходства отношений реляционных баз данных. Рассмотрим два отношения Рассмотрим следующую функцию:
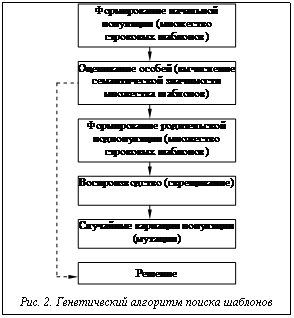
значение функции тем ближе к единице, чем больше сходства между парами атрибутов рассматриваемых отношений. Алгоритм отождествления объектовсхем данных Для построения бинарного отношения недостаточно нечеткой оценки сходства объектов. Необходимо из множества пар объектов выбрать наиболее подходящих кандидатов для отождествления. Рассмотрим алгоритм выбора такого рода пар объектов (рис. 3). Будем считать, что количество объектов в схеме данных Пример решения задачи интегрированиясхем данных Для примера рассмотрим две схемы данных Анализируя представленные схемы данных, можно увидеть семантическую близость следующих пар объектов: student и student, faculty и faculty, student.name и student.first_last_name, student.dob и student.data_rog, student.course и student.kurs, student.phone и student.telefon, faculty.title и faculty.nazvanie, faculty.phone и faculty.phone. Результаты оценки сходства объектов схем данных предложенным методом представлены в таблицах 1 и 2.
Рис. 4. Схема данных S1
Рис. 5. Схема данных S2 Таблица 1 Оценка семантического сходства атрибутовсхем данных
Таблица 2 Оценка семантического сходства отношенийсхем данных
Результатом применения алгоритма отождествления объектов являются следующие пары объектов: student@student, faculty aculty, student.name@ student.first_last_name, student.dob@student.data_rog, student.course@student.kurs, student.phone@student.telefon, faculty.title@faculty.nazvanie, faculty.phone@faculty.phone. В данной работе предложен метод интегрирования схем данных. Метод базируется на семантическом описании атрибутов в виде множества строковых шаблонов, на базе которых производится оценка семантического сходства атрибутов, а уже на основе данной оценки вычисляется мера сходства отношений базы данных. Также предложен алгоритм выбора наиболее предпочтительных пар объектов для отождествления. Описанный метод интегрирования был опробован на тестовой задаче и показал хорошие результаты, которые свидетельствуют о возможности применения данного подхода на практике, а также о необходимости его дальнейшего исследования и анализа. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 где
где 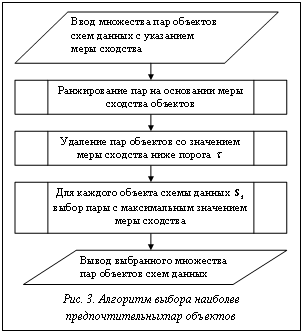
 (5)
(5) , (6)
, (6)| Permanent link: http://swsys.ru/index.php?id=100&lang=en&page=article |
Print version Full issue in PDF (1.92Mb) |
| The article was published in issue no. № 1, 2008 |
Perhaps, you might be interested in the following articles of similar topics:
- Программный комплекс оценки химической обстановки при возникновении чрезвычайных ситуаций
- Программная система для исследования характеристик сетей обработки информации
- Методы повышения быстродействия и надежности многопортовых коммутаторов Ethernet для ЭВМ кластерного типа
- Преобразование данных от разнородных систем мониторинга
- Мультиагентное моделирование процессов распространения и взаимодействия инфицирующих сущностей
Back to the list of articles