Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: Gordeev L.S. (l.s.gordeev@yandex.ru) - D. Mendeleev University of Chemical Technology of Russian Federation, Moscow, Russia, Ph.D, () - | |
| Ключевое слово: |
|
| Page views: 13950 |
Print version |
В последнее время получили широкое распространение искусственные нейронные сети как эффективный моделирующий аппарат. Это объясняется свойством нейронных сетей аппроксимировать и экстраполировать как непрерывные, так и разрывные вектор-функции, а также уникальным их свойством обобщения данных. Последнее особенно важно при решении динамических задач и задач управления. Создание искусственных нейронных сетей и их использование при моделировании объектов исследования предусматривает ряд взаимосвязанных этапов: 1) анализ проблемы; 2) определение топологии нейронной сети; 3) обучение нейронной сети; 4) проверка нейронной сети на воспроизведение и обобщение информации. Все из перечисленных этапов являются взаимосвязанными, поэтому их алгоритмическая и программная реализация проводилась нами с учетом этого обстоятельства. Среди множества предложенных к настоящему времени типов нейронных сетей мы выбрали наиболее распространенные и исследованные нейронные сети обратного распространения. Широкое применение обратнораспространяющихся нейронных сетей обязано их способности узнавать сложные многомерные отображения (так называемая аппроксимация вне регрессии). Одним из принципиальных решений в создании обратнораспространяющейся архитектуры является выбор сигмоидальной функции активации, выполненный Вильямсом в 1983 году в ходе изучения различных функций активации. Рассмотрим топологию обратнораспространяющихся нейронных сетей. Нейронная сеть есть параллельная структура с распределенной информацией, состоящая из перерабатывающих элементов (которые могут обладать локальной памятью и выполнять локальные операции с информацией), взаимосвязанных друг с другом однонаправленными информационными связями. Каждый перерабатывающий элемент имеет один выход, который разветвляется на необходимое число связей, по которым передается один и тот же выходной сигнал. Функционирование каждого перерабатывающего элемента должно быть полностью локальным, то есть перерабатывающий элемент зависит только от текущих значений входных сигналов, поступающих в перерабатывающий элемент по входящим в элемент связям, от величин, хранимых в локальной памяти перерабатывающего элемента. Топология обратнораспространяющихся нейронных сетей является иерархической структурой, состоящей из полностью взаимосвязанных слоев или уровней функционирующих единиц (причем каждая единица сама состоит из нескольких перерабатывающих элементов, как будет объяснено ниже). Обратное распространение принадлежит к классу топологий отображающих нейронных сетей, и поэтому перерабатывающая информацию функция, которая выполняет отображение, является аппроксимацией ограниченного отображения или функцией f:AÌ Rn®Rm из компактного подмножества А n-мерного евклидова пространства в ограниченное подмножество f[A] m-мерного евклидова пространства с помощью обучающих примеров (x1, y1), (x2, y2), . . . , (xk, yk), . . . (где yk=f(xk)). В целом топология включает К строк перерабатывающих элементов, занумерованных снизу вверх, начиная с 1. В действительности каждая строка, в свою очередь, состоит из двух разных слоев (где термин слой используется для обозначения множества перерабатывающих элементов с одной и той же передаточной функцией). Первый слой состоит из n элементов, которые просто принимают индивидуальные компоненты xi входного вектора X и распределяют их без изменения ко всем элементам второй строки. Каждый элемент каждой строки принимает выходной сигнал от каждого элемента нижерасположенной строки. Это продолжается по всем строкам сети вплоть до выходной. Последняя К-тая строка сети состоит из m элементов и дает оценку y' выходного сигнала y. В дальнейшем будет предполагаться, что К ³ 3. Строки 2 ¸ (К-1) называются скрытыми (так как они не связаны напрямую с окружением сети). Наряду с прямонаправленными связями каждый элемент скрытой строки принимает обратную связь ошибки от каждого элемента вышерасположенной строки. Однако в сети присутствуют не только распространяемые копии выхода, но и независимые связи, каждая из которых передает свой разностный сигнал. При этом каждый элемент составлен из одного главного элемента (нейрона) и нескольких входных элементов нейрона. Каждый входной элемент вырабатывает выходной сигнал, который посылается собственному нейрону и нейрону предыдущего слоя, с которого поступает входной сигнал. Каждый входной элемент нейрона принимает входной сигнал от одного нейрона предыдущего слоя, а также от собственного нейрона. Как уже упоминалось, нейроны скрытого слоя принимают входные сигналы от входных элементов каждого из нейронов следующего вышерасположенного слоя. Нейроны выходного слоя принимают "желаемый" выходной сигнал yi для компонент выходного вектора на каждом обучающем примере. Функционирование нейронной сети включает две стадии: прямой проход и обратный. Первый проход (прямой) начинается с введения вектора xk в первую (входную) строку сети. Элементы первой строки передают все компоненты вектора xk всем элементам второй строки сети. Выходные сигналы второй строки затем передаются всем элементам третьей строки и так далее до тех пор, пока не будут достигнуты выходные элементы последней k-той строки (их количество равняется m), которые вырабатывают компоненты yk' выходного вектора (то есть сеть оценивает желаемый выходной вектор yk). После того, как сделана оценка yk' выходного вектора, каждому выходному элементу предоставляется соответствующая компонента "желаемого" выходного вектора yk. Нейроны вычисляют соответствующие величины dki и передают их своим входным элементам. Они затем вычисляют величины Dkij (или новые значения весов, если выполнена требуемая серия уточнений) и передают величины wkijolddki нейронам предыдущего слоя. В таблице приведены точные выражения для передаточных функций элементов. Верхний индекс "old" указывает, что используется некорректированное значение веса, соответствующее прямому проходу. Данный процесс продолжается, пока не будут достигнуты входные элементы второй строки. После этого цикл может быть вновь повторен. Процесс продолжается до тех пор, пока сеть не достигнет удовлетворительного уровня представления информации (который обычно проверяется на основании данных, отсутствующих в обучении сети) или пока пользователь не решит начать обучение при новых начальных значениях весов или с новой топологией сети. После того, как обучение нейронной сети успешно завершено и достигнут приемлемый уровень ошибки воспроизведения информации сетью, возможна ее проверка предсказания информации. В основе обучения обратнораспространяющихся нейронных сетей лежат градиентные методы, позволяющие наиболее быстро провести обучение сети. Однако данному классу методов обучения присущи серьезные недостатки, главными из которых являются возможность попадания в локальные минимумы и прекращение процесса обучения. Другим возможным классом методов обучения нейронных сетей являются стохастические методы. В данном классе методов обучения нейронных сетей производятся псевдослучайные изменения величин весов, с сохранением тех изменений, которые ведут к улучшениям. Процедура обучения состоит в следующем.
1. Для множества входов вычисляются выходные переменные. 2. Сравниваются полученные выходные переменные с желаемыми выходными значениями и вычисляется значение оценочной функции Е. 3. Случайно выбранный вес корректируется на небольшое случайное значение. Если коррекция помогает (уменьшает оценочную функцию Е), то она сохраняется. В противном случае следует вернуться к первоначальному значению веса. 4. Шаги 1-3 повторяются до тех пор, пока сеть не будет обучена в достаточной степени. Этот процесс стремится минимизировать оценочную функцию, но может попасть в локальные минимумы. Полезная стратегия для избежания подобных проблем состоит в больших начальных шагах и постепенном уменьшении размера среднего случайного шага. Это позволяет сети вырываться из локальных минимумов и в то же время гарантирует окончательную стабилизацию сети. Ловушки локальных минимумов представляют серьезную и широко распространенную трудность, особенно в методах обратного распространения. Стохастические методы позволяют решить эту проблему. Стратегия коррекции весов, вынуждающая их принимать значения, соответствующие глобальному минимуму оценочной функции, возможна. Если первоначально давать большие значения коррекции весов, то вектор значений параметров (весов) нейронной сети будет перескакивать из одной области локального минимума и нигде не будет задерживаться. Если теперь постепенно уменьшать среднюю величину коррекций весов, то достигается условие, при котором вектор весов будет на короткое время застревать в точке глобального минимума. При еще меньшей средней коррекции весов будет достигнута критическая точка, когда средняя величина коррекции достаточна для перемещения вектора весов из точки локального минимума в точку глобального минимума, но недостаточна для того, чтобы вектор весов покинул область глобального минимума. Таким образом, окончательно вектор весов остановится в точке глобального минимума, когда средняя величина коррекций весов уменьшится до нуля. Данная процедура напоминает отжиг металла, поэтому для ее описания часто используют термин "имитация отжига". Этот стохастический метод, называемый Больцмановским обучением, непосредственно применим к обучению искусственных нейронных сетей. Рассмотрим его алгоритм. 1. Задать искусственной температуре Т большое начальное значение. 2. Для множества обучающих примеров вычислить значение оценочной функции. 3. Дать случайное изменение весам и вновь рассчитать оценочную функцию. 4. Если оценочная функция Е уменьшилась, то изменение весов сохранить. Если изменение весов привело к увеличению оценочной функции, то вероятность сохранения этого изменения вычисляется с помощью распределения Больцмана P(c) = e-c/kT, где P(c) – вероятность изменения с в оценочной функции; k – константа, аналогичная константе Больцмана; Т – искусственная температура. С этой целью выбирается случайное число r из равномерного распределения от нуля до единицы. Если P(c) больше, чем r, то изменение весов сохраняется. В противном случае величины весов возвращаются к прежним значениям. Шаги 3 и 4 повторяются для всех весов сети с уменьшением температуры, пока не будет достигнуто допустимо низкое значение целевой функции. Величина случайного изменения веса на шаге 3 определяется с помощью распределения Коши. Это симметричное распределение с плотностью распределения р(x) равной p(x)= Комбинированное обучение на основе обратного распространения обладает тем преимуществом, что веса всегда корректируются в направлении вдоль градиента минимизируемой функции. При этом время обучения существенно меньше, чем при случайном поиске, выполняемом машиной Коши, когда находится глобальный минимум, но многие шаги выполняются в неверном направлении, что отнимает много времени. Соединение этих двух подходов дало хорошие результаты. Коррекция весов, равная сумме, вычисленной алгоритмом обратного распространения, и случайный шаг, определяемый алгоритмом Коши, приводят к последовательности коррекций весов нейронной сети, которая сходится и находит глобальный минимум быстрее, нежели каждый из методов в отдельности. Коррекция весов в комбинированном алгоритме, использующем обратное распространение и обучение Коши, состоит из двух компонент: направленной компоненты, вычисляемой на основе алгоритма обратного распространения, и случайной, определяемой распределением Коши. Эти компоненты вычисляются для каждого веса, и их сумма является величиной, на которую изменяется вес. Как и в алгоритме на основе распределения Коши, после вычисления изменения веса находится новое значение оценочной функции. Если оценочная функция уменьшается, то изменение сохраняется. В противном случае оно сохраняется с вероятностью, определяемой распределением Больцмана. Коррекция веса определяется в виде: wm,n,k(n+1)=wm,n,k(n)+h[aDwm,n,k(n)+(1-a)dn, kzm, j]+(1-h)xc, где h – коэффициент, определяющий соотношение между изменением веса по алгоритму Коши и алгоритму обратного распространения. Если h=0, то комбинированный метод обучения нейронных сетей вырождается в стохастический метод обучения на основе распределения Коши. Если h=1, то комбинированный метод совпадает с алгоритмом обратного распространения ошибок. Следует отметить, что изменение лишь одного весового коэффициента нейронных сетей между вычислениями оценочной функции неэффективно. В зависимости от конкретной задачи целесообразнее изменять сразу веса целого слоя либо использовать иную стратегию изменения весов. Так как в комбинированном методе с вероятностью, определяемой распределением Больцмана, могут сохраняться шаги, увеличивающие оценочную функцию, а распределение Коши, определяющее величину случайного шага, имеет бесконечную дисперсию, то весьма вероятно возникновение больших приращений весов, приводящих нейронную сеть к так называемому сетевому “параличу". Такой "паралич” сети является серьезной проблемой: раз возникнув, он может увеличить время обучения на несколько порядков. “Паралич” возникает, когда значительная часть нейронов сети получает достаточно большие веса, чтобы дать большие значения взвешенной суммы входов к рассматриваемому искусственному нейрону. Это приводит к тому, что величина выхода нейрона приближается к своему предельному значению, а производная от функции активности приближается к нулю. Так как алгоритм обратного распространения ошибок при вычислении величины изменения веса использует эту производную в качестве сомножителя, то величины изменения веса также будут стремиться к нулю. Если такая ситуация возникает во многих нейронах сети, то обучение может замедлиться вплоть до полной остановки. К настоящему времени теоретически предсказать будет ли нейронная сеть парализована во время обучения не представляется возможным. Однако экспериментально установлено, что малые размеры шага в ходе обучения реже приводят к “параличу” сети. Для решения проблемы паралича нейронной сети в ходе обучения выявляются нейроны, находящиеся в состоянии насыщения. С этой целью определяется взвешенная сумма сигналов, поступающих к нейрону. Если она приближается к своему предельному значению (положительному или отрицательному), то на веса, относящиеся к данному нейрону воздействует сжимающая функция, аналогичная функции активности, за исключением того, что диапазоном ее изменения является интервал (+10, -10) или (в зависимости от задачи) другое подходящее множество. Тогда модифицированные значения весов будут определяться по формуле: wmn = -10 + 20/[1 + exp(-wmn/10)] . Данная функция сильно уменьшает большие по абсолютной величине веса, в то же время мало изменяя малые веса. Кроме того, она поддерживает симметрию, сохраняя небольшие различия между большими весами. Программная реализация изложенного комбинированного алгоритма обучения нейронной сети была выполнена нами в виде программного модуля TRAIN на языке турбо-Паскаль. Особенностью программного модуля является его двоякое использование: при обучении нейронной сети он осуществляет переработку информации в прямом и обратном направлении по сети, а при использовании уже обученной сети обратный проход информации исключается. Для генерирования случайных чисел использовался программный датчик RAND. Расчеты задач с использованием нейронных сетей велись на IBM PC c процессором 486 и Pentium. Время обучения нейронной сети зависело от решаемой задачи и составляло от нескольких часов до нескольких суток. В качестве примера рассмотрим применение нейронных сетей для исследования процессов разделения неидеальных смесей с химическими превращениями. Наличие химических превращений в многофазных системах при ректификационном разделении подобных смесей приводит к необходимости совместного учета условий фазового и химического равновесий, что значительно усложняет задачу расчета. При этом основная схема решения подзадачи расчета фазового и химического равновесий предусматривает представление химического равновесия в одной фазе и соотнесение химически равновесных составов в одной фазе с составами других фаз с помощью условий фазового равновесия. Для химически взаимодействующих систем с двумя жидкими и одной паровой фазой выражают химическое равновесие в одной из жидких фаз и дополняют его условиями фазовых равновесий и материального баланса. Если известны константы фазовых и химического равновесий, общий состав смеси, а также общее давление, то решение образующейся нелинейной системы позволяет определить составы и относительные количества фаз в химически реагирующей системе. Сложность описания нелинейных зависимостей констант фазового и химического равновесий, а также коэффициентов активности в многокомпонентных смесях от состава и температуры приводит часто к существенным ошибкам в расчете равновесий либо к получению физически неверных решений в случае их множественности. В связи с этим в работе рассматривается новый подход к моделированию и расчету фазовых и химических равновесий на основе использования гибридных нейронных сетей. Под гибридной нейронной сетью в данном случае понимается сеть, выходы которой соответствуют промежуточным (неизмеряемым) переменным. Кроме того, сеть дополняется известными соотношениями (уравнениями баланса, основными термодинамическими соотношениями), связывающими промежуточные переменные с интересующими выходными величинами. Подобные гибридные нейронные сети работают уже не по принципу "черного ящика", а в силу заложенных в них фундаментальных соотношений обладают значительной прогнозирующей способностью. Для представления промежуточных переменных в подзадаче расчета фазовых и химического равновесий нами используются нейронные сети типа многослойного персептрона. В частности, для решения задачи расчета разделения гетероазеотропных смесей методом ректификации предлагается гибридная нейронная сеть для предсказания многокомпонентных равновесий жидкость-жидкость-пар. Обучение гибридной сети проводилось на основе принципа обратного распространения ошибок. Существенным достоинством представления равновесий жидкость-пар на основе гибридной нейронной сети является исключение итерационных расчетов и множественности решений в ходе определения составов равновесных жидких фаз. Последнее обстоятельство значительно упрощает и решение задачи расчета и моделирования процесса гетероазеотропной ректификации смесей. На примере водных растворов этилового, пропиловых, бутиловых и пентиловых спиртов в работе выполнено сравнение предсказания равновесий на основе известных методов с предлагаемым. Показано, что в случае многофазных многокомпонентных равновесий использование гибридных нейронных сетей позволяет упростить решение задачи и повысить точность предсказания. | ||||||||||||||||||
 Dlijnew=dliz(l-1)j count =1} ELSE{wlijnew=wlijold Dlijnew=Dlijold+dliz(l-1)j count = count +1}
Dlijnew=dliz(l-1)j count =1} ELSE{wlijnew=wlijold Dlijnew=Dlijold+dliz(l-1)j count = count +1}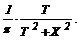
| Permanent link: http://swsys.ru/index.php?id=1021&lang=en&page=article |
Print version |
| The article was published in issue no. № 1, 1997 |
Perhaps, you might be interested in the following articles of similar topics:
- Формирование программ развития больших систем административно-организационного управления
- Сравнительный анализ некоторых алгоритмов распознавания
- Кросс-система автоматизации разработки программного обеспечения на базе языка высокого уровня Рада
- Комплекс автоматизированного проектирования геотехнических сооружений "КАППА"
- Основные характеристики методики АДЕСА-2 для разработки информационных систем и возможности ее практического применения
Back to the list of articles