Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: () - , () - , () - , () - , () - , () - | |
| Ключевое слово: |
|
| Page views: 11052 |
Print version |
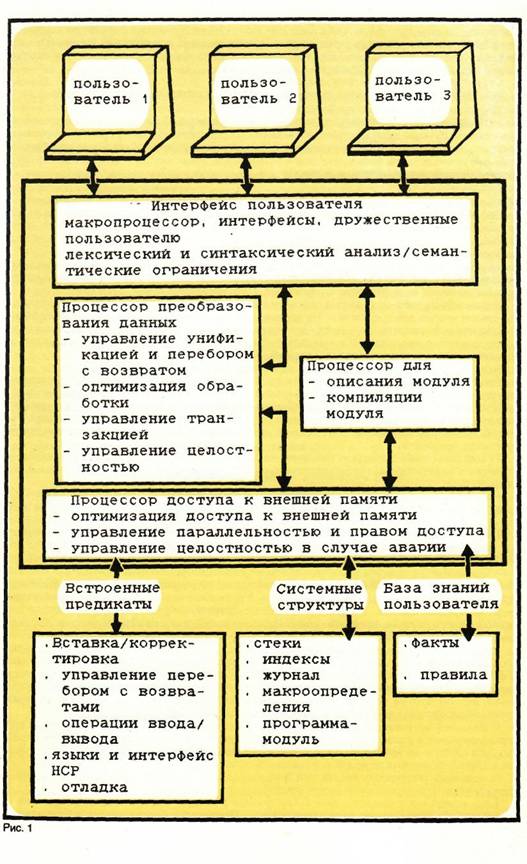
Взаимосвязь искусственного интеллекта и теории баз данных является предметом многих исследований (J. H. Gallaire, J. M. Nicolas и J. Minker «Логика и базы данных», «К системам управления базой знаний» и т. д.). Это связано с возможностью объединения характеристик СУБД как средства обработки и управления данными со специфическими характеристиками систем баз знаний (СБЗ), как, например, получение логических выводов, решение проблемы, проблема запрос — ответ и т. д. * Из наиболее часто используемых схем знаний (семантическая сеть, логический формализм, процедурные схемы и схемы фреймов) выберем логический формализм, учитывая следующие его преимущества: • наличие правил логического вывода; • наличие простой и доступной формальной семантики; • простота используемых представлений, с помощью которых осуществляется легкий доступ к описаниям базы знаний. С помощью логического формализма можно использовать такие понятия, как константа, переменная, функция, предикат, логические связи и квантификаторы для представления фактов при помощи логических формул; • концептуальная экономия, обозначающая, что любой факт представляется однажды независимо от его различных использований. Согласно логическому формализму база знаний представляет собой набор логических формул, которые обеспечивают частичное описание состояния реального мира. Если производится добавление или удаление логических формул, то в базе знаний происходят изменения. Таким образом, логические формулы выступают как структурные блоки, обрабатываемые базой знаний. Языком программирования, который объединяет преимущества логических формализмов с преимуществами схем процедурных представлений, является Пролог; он обеспечивает следующую процедурную семантику: «Если вы хотите решить проблему А, постарайтесь соответственно решить проблемы В1, и В2, и. Вп». Тенденции в подходах взаимосвязи СБЗ и СУБД Системы, основанные на использовании знаний (СБЗ), используют два принципа: • правильное представление домена прикладных знаний (так называемый «слой действительности»); • управление этими знаниями. Эти принципы заложены в два компонента СБЗ: • базу знаний; • механизм логических выводов [VAS85]. Несмотря на то, что модели данных, описываемые в теории баз данных, отличаются от схем представлений данных, применяемых в СБЗ, они имеют аналогичные цели и архитектурные характеристики. При этом СБЗ обеспечивает систему выводов и богатые возможности представления данных, СУБД — эффективный доступ к данным и средства их обработки. Получение подсистем полного представления знаний невозможно (по крайней мере на современных ЭВМ) независимо от используемых формализмов представления знаний [BRA84]. На практике решение состоит в том, чтобы избежать тупиковых ситуаций путем сокращения числа запросов. Поэтому в СБЗ стремятся использовать методы доказательства теорем, которые включают в себя значительные избыточности (например Пролог) или уменьшение правильности представления (например, путем выдачи недостаточно обоснованного ответа после определенного лимита времени). Аналогичным образом в СУБД принимаются незавершенные представления (например, путем избежания дизъюнкции, отрицания и экзистенциальных квалификаторов путем использования структур языка), что означает ограничение возможностей вывода. Такие подходы к домену, которые должны быть минимизированы, отражают, с одной стороны, цели этих двух систем, а с другой — различия между самими этими подходами, подчеркивая трудности, возникающие при попытке объединения методов и технологий, используемых в СБЗ и СУБД. Каковы же пути преодоления этих трудностей и возможно ли их преодоление? Предлагается три стратегии, обеспечивающие решение этих проблем. Усовершенствование существующих систем Эта стратегия появилась первой и, по мнению многих исследователей, коммерческий успех ей обеспечен. В качестве основного пункта данная стратегия имеет дело с двумя направлениями: усовершенствование СУБД за счет возможностей вывода и усовершенствование СБЗ за счет возможностей управления и эффективной обработки больших баз знаний. Усовершенствование СУБД за счет характеристик вывода основывается на наличии действующих СУБД и богатого опыта в проектировании таких систем. В этом подходе предпочтение отдается элементарной информации (отношениям в базе данных), логике, используемой в качестве языка запросов. Иначе говоря, реляционная база данных представляет собой модель теории первого порядка, а запросы трактуются как истина или ложь в соответствии с реляционной алгеброй. Данная модель практически представляет собой точку зрения Кодда (Е. F. Codd [Cod72]), в которой реляционные вычисления рассматриваются как операции реляционной алгебры. Реляционное представление языка запросов показывает, что, используя объединение, разность, проекции, ограничения и графики в декартовых координатах, можно определить истинное значение любого предикативного выражения. Язык запросов, используемый в этих операциях, является полностью реляционным, а база данных рассматривается как интерпретирующая модель теории первого порядка [KON81). Из систем, основанных на данном подходе, кратко рассмотрим версию СУБД «INGRES» вследствие широкого распространения этой системы и элегантности ее проектных решений. М. Стоунбрейкер предлагает несколько расширений языка QUEL, которые дают возможность сохранять порождающие правила, имеющие форму IF condition THEN action и их реализацию, управляющую обработкой, как нисходящую, так и восходящую [ST085]. Делаются предложения, позволяющие этим двум типам управления обработкой правил производить перебор с возвратом. Большим преимуществом предлагаемого решения является то, что оно может быть легко адаптировано на любой реляционной СУБД. Еще одним примером этого класса является система PROBE [DAY85], предназначенная для «расширения» реляционной СУБД с помощью: • абстрактных типов объектов и возможностью описания новых объектов и выполнения операций над ними; • понятий размерности (во времени и пространстве), необходимых для управления данными нового типа; • возможности включения предложений Хорна (Horn), аналогичных тем, которые используются в Прологе при описании представлений. В основу второго подхода усовершенствования систем положена СБЗ, которая расширяется за счет характеристик управления больших баз данных. Среди известных СБЗ с такими свойствами наиболее типичной является система CALLI-STO (SAT86), предназначенная для контроля и управления производством. Такой вид деятельности предполагает управление большим числом сложных объектов, гибкое взаимодействие между ними постоянной корректировкой базы знаний. Система CALLISTO предназначена для решения следующих проблем: • интерактивная генерация производственных планов; • интерактивное изменение приоритета выпуска продуктов; • планирование на многих уровнях. Для реализации этих задач система имеет процессоры, в которых используются следующие концепции: • Основные объекты, которые являются концепциями проекта, описываемые в документации, обеспечиваются различными процедурами (создание, уничтожение, отображение), управление которыми осуществляется путем посылки конкретных сообщений. • Р-базисные объекты, или ответственные объекты, которые являются программными модулями, способными осуществлять связь с другими процедурами для решения задач. • План события: R-объекты интерпретируют пользовательский процесс, представленный состоянием и сетью операций, управляя планом объекта и регулируя события. План ускоряет или замедляет выполнение определенных операций в зависимости от целей. • Правила вывода: SRL-OPS — язык программирования, основанный на правилах, используется для оценки структуры операций и спецификации отчетов состояния. • Логическое программирование: HSRL представляет собой устройство доказательства теорем, основанное на предложении Хорна, и используется как механизм вопрос-ответ. CALLISTO была задумана как распределенная система, каждый член сети которой в состоянии осуществлять связь с другим членом сети при общем управлении всем производством. Что касается Пролога, то можно усовершенствовать его функциями, что позволит более эффективно обрабатывать данные [SCI/86] Из этих усовершенствований можно выделить следующие: • Введение встроенного предиката «deref», который позволяет осуществить поиск кортежа на диске, когда известен ассоциативный указатель. Предлагается применять различные структуры (В-деревья, хеширование) путем описания специальных встроенных предикатов и даже путем изменений в синтаксисе языка с тем, чтобы была возможной индексация конкретного аргумента предиката. Предлагается, чтобы структура, имеющая форму Р(Х), Х>5, могла быть записана как Р(Х : X = 5), что позволяло бы осуществлять доступ согласно дереву, присоединенному к атрибуту X, и индексацию фактов, расширенных для правил. • Введение форматов кортежа при помощи встроенных предикатов. Так, предикат «convert (Fm, T, S)» берет дисковый кортеж Т и преобразует его в структуру Пролога S. • Управление буфером, позволяющее перемещать блоки кортежей с диска в память, что сокращает число обращений к диску. • Недетерминированную оптимизацию запросов на языке Пролог для сокращения области поиска, подобно теории оптимизации баз данных. В Прологе это сложнее, чем в базе данных, где при компиляции известна размерность переменных. • Выполнение параллельного доступа к базе знаний с использованием «и-параллелизма», обеспечиваемого CONCURRENT PROLOG. Усовершенствование СУБД за счет функций вывода имеет преимущество в эффективной реализации алгоритмов и большого опыта проектирования СУБД. В то же время это не совсем совершенный метод, т. к. он вызывает трудности при реализации (например, очень трудно представить в СУБД неопределенную или отрицательную информацию). Объединение СБЗ и СУБД Чтобы пользователи могли применять в своих прикладных программах возможности СБЗ и СУБД и в то же время сохранить их особенности, многие исследователи попытались объединить эти две системы. Проекты охватывают практически все возможные типы связи, начиная со слабой связи с ее двумя вариантами до сильной. Слабая имеет несколько успешных применений, и некоторые из проектов поступили на рынок. Слабая связь реализуется двумя способами. Один из них заключается в компиляции некоторых правил вывода и в сохранении этих правил в метабазе в реляционной форме [МАШ]. При проектировании SABRE правила вывода, написанные на языке L1, группируются в модули. Семантика языка L1 является покортежной семантикой. Правило запускается для каждого момента существования переменных с левой стороны и ответ обеспечивается по условиям этого правила до тех пор, пока вся база не будет выбрана. Эти правила компилируются помодульно после протокола обработки данных, основанного на использовании протокола языка FABRE (особенно SABRE). Такое решение позволяет реализовать дедуктивные характеристики базы данных. По мнению проектировщиков, время выполнения относительно велико (20—50% времени, необходимого на ответ, затрачивается на операции поиска соответствующих запросов). Японскими проектировщиками ЭВМ пятого поколения был принят компилируемый вариант, который обеспечивает компиляцию модулей предложений типа используемых в Прологе и генерацию на их основе запросов реляционной СУБД, которые затем автономно оцениваются. Другой метод слабой связи состоит в том, что СБЗ выбирает факты из базы данных, которые затем обрабатываются механизмом логических выводов. Для данной концепции имеет значение положение, выдвинутое Чангом и Волкером (Chang и Walker), описывающее гибкую слабую связь между системой Пролог и реляционной СУБД SQL/DS фирмы IBM с расширением сильной связи, так чтобы обе системы могли динамически взаимодействовать во время доступа. Для получения недостающих звеньев проектировщики предлагают ввести встроенный предикат, называемый SQL, при помощи которого необходимые запросы передаются в СУБД для передачи фактов из базы данных в систему Пролог для хранения в ее базе знаний и передачи в механизм логических выводов. Такой метод представляет собой сильную связь между СБЗ и СУБД. В действительности проектировщики не добились реализации сильной связи, хотя и считали, что способ ее реализации дает достаточно надежд на достижение такой связи. Система управления базой знаний Джон Милопулос (John Mylopoulos) был первым, кто заговорил о необходимости СУБЗ — системе нового класса, объединяющей функции СБЗ и СУБД. Он утверждает, что СУБЗ определяет новую технологию разработки ПО, включая программы и базы данных с характеристиками интерпретации, специфичными для экспертных систем [MYL80]. По аналогии с СУБД СУБЗ должна иметь средства управления несколькими распределенными базами знаний. В. литературе описывается масса мнений о необходимости СУБЗ и их возможностях, начиная от сокращения и даже отрицания необходимости проектирования СУБД до преувеличения ее роли, что видно из двух других стратегий [MAN85]. Ф. Манола (F. Manola) и X. Броди (Н. L. Brodie) [MAN85] полагают, что большое число специалистов поддерживает работы по искусственному интеллекту. Предложенная ими архитектура основана на следующих принципах: • спрос на возможности БЗ в СУБД и последующая необходимость обработки знаний могут привести к появлению таких компонентов СУБД, которые сами будут представлять системы баз знаний; • вся архитектура в этом случае становится распределенным неоднородным набором систем БЗ, в которых компоненты «управления знаниями» активно соединяются с компонентами, ориентированными на применение. Рассмотрение СУБД как распределенных систем СБЗ представляет возможность связи между ними и возможность интеграции компонентов, выполняющих одинаковые функции. МЕТОД ОРГАНИЗАЦИИ СВЯЗИ МЕЖДУ СБЗ ТИПА ПРОЛОГ И СУБД Целью разработки было создание переносимой системы для баз знаний, используемой первоначально на румынских мини-ЭВМ, совместимых с PDP 11/34, а затем и на ЭВМ семейства VAX. Язык программирования Пролог 1,2 был выбран в качестве схемы для представления званий по следующим причинам: ■ преимущества логических формализмов; ■ возможность компромисса между выбором наиболее выразительных логических форы ж форм, которые могли бы быть эффективно реализованы на имеющихся ЭВМ: ■ Пролог использовался как объектный язык для ЭВМ 5-го поколения. Разработку системы типа Пролог (PKBS), основанной на использовании знаний, предполается вести в два этапа. Первый этап: разработка эффективной непосредственно используемой РКЖ для реализации базы знаний. Второй этап: создание интерфейса между PKBS и реляционной СУБД. Из возможных типов архитектур был выбран следующий вариант: система Пролог, расширенная средствами базы данных. Пролог как средство доказательства теорем продемонстрировал свои возможности и на последние годы стал одним из основных языков программирования. В то же время применение во многих областях выявило некоторые его недостатки. Выделим следующие из них: • слабая структуризация программы; • наличие одной управляющей структуры; • отсутствие типа данных; • отсутствие интерфейса с процедурным языком, с помощью которого могли бы быть описаны встроенные предикаты пользователя; • недостаточная эффективность доступа в случае большой базы знаний; • невозможность коллективного использования базы знаний; • отсутствие механизма восстановления в случае отказов. Ниже предлагается ряд мер, устраняющих некоторые из этих недостатков или уменьшающих отрицательные эффекты. Архитектура системы базы знаний типа Пролог представлена на рис. 1. Интерфейс пользователя является компонентом, который гарантирует связь пользователя с PKBS. Этот интерфейс обеспечивает интерфейсы, предназначенные для запросов непрофессиональными пользователями, которым трудно работать с непосредственными выражениями Пролога. Он также обеспечивает анализ и генерацию промежуточного кода для предложений Пролога. Интерфейс включает макропроцессор для создания макроописании путем указания образца вывода и образца расширения. Процессор преобразования данных представляет собой механизм логического вывода PKBS. В нем используется механизм унификации Пролога и механизм управления перебором с возвратом. Предлагаются следующие расширения: ■ оптимизация обработки для выбора наилучших индексов, порядка оценки, методов «join» и т. д.; ■ индексация предложений в соответствии с главным предложением путем ввода ограничения так, чтобы два различных предиката имели различные имена; я введение встроенных предикатов BTREE и HASH для того, чтобы избежать индексации аргументами некоторых «основных» фактов из базы знаний; ■ параллельньш доступ пользователей к базе знаний за счет блокировки предиката из базы, если к нему обращаются другие пользователи; ■ ввод обозначения транзакции при помощи ряда встроенных предикатов в целях управления данной транзакцией. Транзакция представляет собой также средство сохранения целостности базы знаний в случае аварии и восстановления после аварии; ■ расширение управляющих структур Пролога. Стандартные управляющие структуры представляют собой поиск в глубину из И/ИЛИ дерева поиска. Необходимо ввести механизм отсрочки выполнения предиката до появления экземпляра переменной (такого как встроенный предикат FREEZE из Пролога II). Целесообразен ввод управляющих структур, таких как встроенные предикаты BLOCK/BLOCK-EXIT и ERROR из Пролога II, которые в случае ошибки вызывают прерывание процесса получения логических выводов, вызванных определенным предикатом; • расширение механизма «удаления» с так называемым «дистанционным удалением»; • введение контроля целостности (особенно трудно реализовать) обеспечивает обнаружение неправильных транзакций и автоматически их удаляет. Этот механизм очень полезен, т. к. мог бы компенсировать недостаточный контроль за обновлением базы данных в системе Пролог. Применение процессора преобразования данных будет происходить, по крайней мере в первой версии, на уровне интерпретации. Программный модуль представляет собой набор определений, близких по значению.
Описание модуля состоит из множества объявлений, описывающих отношения с другим модулями, а также описания типов данных, макроописания, переменные, предикаты, операторы, предложения и цель. Из этих определений за пределами могут использоваться только те, которые явно объявлены как глобальные. Структура программного модуля приводится ниже. В разделе домена определяются типы переменных, с которыми работает модуль. Следующие типы данных являются неявными: • целочисленные, с плавающей запятой одинарной и двойной точности, с фиксированной* десятичной точкой, литеры, цепочки, символьные. Разрешаются два формата символьных данных: последовательность букв, цифр или подчеркиваний (первый символ может быть на нижнем регистре), или последовательность символов, заключенная в двойные кавычки; • логические данные (истина или ложь); • файлы. Кроме неявных типов данных, пользователь может указать составной объектный тип: ■ скалярный тип (упорядоченный набор символьных величин); ■ запись (структура с фиксированным числом полей); ■ список; ■ составной терм; ■ «n-uple» тип из Пролога II, представляющий структуру с фиксированным числом компонентов, используемую для динамического описания составных объектов (первым компонентом является знак функции, а остальные — аргументами). Раздел объявления переменных описывает переменные, которые являются глобальными на уровне модуля или программы. На переменные, определяемые здесь, механизм перебора с возвратами влияния не оказывает. Эти переменные могут использоваться в качестве параметров любым предикатом из модуля и, если они определяются как глобальные, то доступны для предикатов и других модулей. Раздел макроопределений содержит определения локальных макросов модуля. Раздел предикатов содержит спецификацию типов данных, используемых для аргумента предикатов в пределах модуля. Можно описать глобальные предикаты, которые могли бы использоваться в других модулях программы так же, как внешние предикаты, определяемые в других модулях. Если для одного и того же аргумента используется предикат с различными типами данных, то для каждого используемого типа данных потребовалось бы описание предиката. Раздел базы знаний содержит описания, аналогичные описаниям в разделе предикатов, не относится к предикатам, уже определенным в базе знаний или к тем, которые должны вводиться. Если предикат программы или базы знаний не был определен в разделе предикатов или разделе базы знаний, то он не будет поддерживать какие-либо типы ограничения для аргументов, а тип будет динамически устанавливаться унификацией. Целевой раздел определяет целевую функцию, которая должна быть реализована в модуле, построенном из последовательности предикатов, соединенных конъюнкцией. Программа может рассматриваться как набор модулей. Управление физической областью путем страничной организации аналогично управлению, используемому в СУБД. Управление состоит из встроенных предикатов управляющих системных структур и структур пользователя. Управление включает в себя два уровня: уровень внутренней памяти, содержащий наиболее активные структуры пользователя, и внешнюю память на диске, предназначенную для хранения большого объема данных. Управление этими двумя уровнями обеспечивается оптимизатором доступа к внешней памяти. Встроенные предикаты обеспечивают средства, которые не могут быть обеспечены определениями пользователей Пролога. Встроенные предикаты могут давать побочные эффекты, означающие, что кроме реализации цели и использования аргументов, они могут приводить к изменениям в системе, которые не могут быть произведены при помощи предиката, написанного на чистом Прологе. Видимо, возможно расширение набора встроенных предикатов системы предикатами, определяемыми пользователем. С помощью встроенных предикатов можно обеспечить интерфейс с другим языком программирования и с командным языком системы. Можно вызвать стандартную подпрограмму, написанную на другом языке программирования, прокомпилированном и соединенном как задача. Возможна передача параметров в обоих направлениях. С помощью встроенных предикатов пользователь распределяет средства отладки, обеспечивающие трассировку и создание контрольных точек и т. д. База знаний представляет собой набор фактов и правил, определяемых программой со встроенными предикатами типа «утверждено». Предикаты, определяемые в базе знаний, являются глобальными для программ пользователя. Они могут определять предикаты дополнительно к системным предикатам, типы данных и управлющие типы данных для параметров предикатов. На уровне базы знаний была расширена концепция модульности, которая представляет собой множество сегментов, содержащих правила и факты из базы знаний. Выполнение программы, работающей с базой знаний, требует запуска только эффективно используемых сегментов. К сегментам базы знаний приписана исходная область диска, которая затем динамически расширяется. Планируется ввести ряд встроенных предикатов для поиска, вставки, удаления и изменения фактов и правил базы знаний. Дальнейшее расширение СБЗ типа Пролог — компилируемый вариант программы Пролог. Этот вариант может значительно повысить эффективность работы системы относительно затрат времени и памяти. Имеются, конечно, некоторые ограничения, которые должны учитываться в компилируемых предложениях. В то же время система должна получить несколько объявлений для того, чтобы она могла правильно работать при использовании смеси предложений, одни из которых компилируются, другие — интерпретируются. Хеширование (поддержка правила). Во время процесса доказательства создается важная дополнительная информация, которая затем последовательно удаляется, и если снова появляется та же задача, то уже нет возможности извлечь пользу за счет предыдущего решения. Идея состоит в том, чтобы сохранить как можно больше информации в соответствующих структурах, чтобы сэкономить время при запросе или использовании одинаковой информации, т. е. чтобы иметь базовые и производные факты. Оптимизация запросов является важной частью систем реляционных баз данных. В дальнейшем усовершенствованный компилятор Пролога будет иметь компонент оптимизации. Этот компонент будет выполнять детерминированную и недетерминированную оптимизацию. Детерминированная оптимизация предполагает выполнение анализа потока данных, распространение констант, обращений к процедуре и т. д., недетерминированная оптимизация сокращает область поиска, что означает переупорядочение предикатов. Недетерминированная оптимизация аналогична оптимизации, используемой в реляционных системах. В целях сокращения времени бесполезного поиска в качестве стратегии используется «интеллектуальный» перебор с возвратами. Для сокращения времени выполнения важно сгенерировать код перебора с возвратом еще на этапе анализа. Языки программирования — интерфейс PKBS С помощью данного интерфейса возможно обращение к прокомпилированному модулю Пролога из программы, написанной на другом языке программирования. Предполагается возможность передачи данных между двумя модулями. Распределенные базы знаний типа Пролог позволяют осуществлять распределенную обработку программ на языке Пролог в сети. На первом этапе осуществлялась связь PKBS с СУБД SOCRATE-MINI. Это сетевая СУБД со средствами иерархического представления, относящаяся к средним базам данных (250МО), с хорошими характеристиками времени ответа (время доступа к основной информации не более 1,5 м/сек). Эта система управляет сетью баз данных типа федерации. Объединение СБЗ типа Пролог с СУБД SOCRATE-MINI представляет собой слабую связь пояснительного типа.
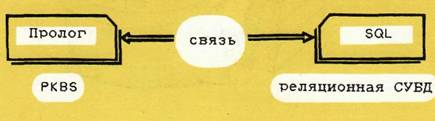
Рис.2 Следовательно, модуль Пролога может обращаться к предварительно прокомпилированой программе с помощью встроенного предиката, позволяющего выполнять передачу параметров. На втором этапе организуется связь с реляционной СУБД. Это слабая связь пояснительного типа (рис. 2). В такой архитектуре система Пролог и SQL выполняются на одной ЭВМ. Реляционная СУБД работает под управлением системы Пролог, имеет средства обслуживания базы данных. Языком для этого интерфейса служит PROSQL, и данная система преобразует программы на PROSQL в программы на Прологе. Переменные Пролога, создаваемые во время обращения, могут использоваться для передачи параметров в SQL (в предложение WHERE...). Результаты выполнения SQL будут храниться в рабочей области Пролога, и если запрос SQL содержит предложение INTO , то переменные Пролога могут быть созданы со значениями возврата SQL. Реляционная СУБД должна иметь гибкий интерфейс с языками программирования. Такой тип архитектуры был реализован на ЭВМ фирмы IBM. |
| Permanent link: http://swsys.ru/index.php?id=1389&lang=en&page=article |
Print version |
| The article was published in issue no. № 4, 1989 |
Perhaps, you might be interested in the following articles of similar topics:
- Компьютерный тренажер для операторов технологических процессов доменного производства
- Разработка загрузчика программного обеспечения встроенной системы управления
- О моделировании данных
- Средства сетевого менеджмента в мультисетевых структурах
- Программная система поддержки принятия проектных решений
Back to the list of articles