Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Author: () - | |
| Ключевое слово: |
|
| Page views: 21742 |
Print version |
Ибо В множестве мудрости много печали, и умНй>кэющий знание умножат горе. Екклезиаст. 1:18 Специалисты в области искусственного интеллекта считают, что это направление исследований стало самостоятельной наукой в тот момент, когда термин "знания" занял в этих работах центральное место. Его появление характеризовало возникновение таких проблем, как приобретение и формализация знаний, представление знаний, база знаний, манипулирование знаниями, языки для представления и манипулирования знаниями и, наконец, возникновение новой профессии - инженер по знаниям. Интеллектуальные системы, которые строятся на основе результатов, полученных в области искусственного интеллекта, асто называют системами, основанными на знаниях, подчеркивая этим их нринци-иальпос отличие от рапее создававшихся систем. Такая ситуация требует анализа самого понятия "знания" для уточнения круга роблем, включаемых в область исследований специалистов по искусственному ин-еллекту, а также наметить перспективы развития этих исследований. Подобный нализ возможен с различных точек зрения: философской, психологической, лингвистической и т.д. Каждая из них по-своему интересна и может дать нетривиальные результаты. Но в этой работе для анализа будет использована "внутренняя точка зрения" на проблему знаний, характерная для специалиста в области искусственного ин-чедлскта и интеллектуальных систем. ЧТО ТАКОЕ ЗНАНИЯ? Как многие фундаментальные понятия в других науках ("множество" в математике, "истина" н логике или "мышление" в психологии), в искусственном интеллекте понятие "знание" не имеет какого-либо исчерпывающего определения. Интуитивное понимание этого термина специалистами, по-видимому, близко к тем толкованиям, которые приводятся в философских словарях. Вот пример такого толкования: "Знание - обладание опытом и пониманием, которые являются правильными и в субъективном, и н объективном отношении и на основании которых можно построить суждения и выводы, кажущиеся достаточно надежными, для того чтобы рассматриваться как знание". Примем пока это толкование, чтобы в дальнейших рассуждениях опираться на интуицию читателя. Наша ближайшая задача - перечислить принципиальные свойства знаний, отличающие их от данных, которыми оперировали ЭВМ. При традиционной организации решения задач на ЭВМ выделяются два момента: про1рамма, реализующая некоторую алгоритмическую процедуру, и совокупность данных, над которыми совершается последовательность операций, заданная программой. В самом начале развития вычислительной техники и программирования среди «сего многообразия информационных единиц, которыми оперирует человек, данные представляли частный случай. Их структура была линейной записью, числом позиций в которой могло быть лишь фиксированное заранее число. Оно определялось не характером решаемой задачи, а конструктивными особенностями вычислительной машины. Машина оперировала лишь со словами определенной длины, поэтому нес данные приходилось укладывать в это "прокрустово ложе". С развитием профаммирования развивалась и структура данных: происходило ее усложнение за счет специальных приемов программирования и появления в языках программирования таких структур данных, которых на физическом уровне вычислительной машины не существует. Так появилась возможность манипулирования с векторами, матрицами и словами неременной длины, позже - со списками и множествами. Правда, традиционная машина по-прежнему работала с машинными словами фиксированной длины, что сильно снижало эффективность работы со сложно opiавизованными данными. В связи с этим стали возникать специализированные процессоры, рассчитанные на аппаратную поддержку векторных или матричных вычислений; в последние годы аппаратную поддержку получили операции над списками. Но даже такие типы данных были недостаточными для выполнения любых символьных преобразований и решения задач, не носящих вычислительного характера. Переход к работе со списками показал, что необходимые структуры данных могли быть такими же нетрадиционными, какими были мно1гх>бразные формы документов, используемых человеком: разного рода таблицы, диаграммы и тд. В связи с тем, что при решении повой задачи может возникнуть необходимость в новой структуре данных, появилась идея абстрактных типов данных, благодаря которой появились и соответствующие механизмы в ряде современных языков lipoipaM-мирования. При работе с абстрактными типами данных программист, пользуясь специальными средствами языка, может описать нужную ему структуру данных и оперировать ею. Казалось бы, это решает все проблемы. Но в задачах, традиционно относящихся к информационным и интеллектуальным, складывалась иная ситуация. При традиционном выполнении программы вычислительная машина "не представляет" семантики решаемой задачи. Закодированные данные и программа всегда являются некоторыми двоичными словами, над которыми стандартным образом выполняются определенные преобразования из конечною списка, называемого списком машинных команд. С этих позиций решение любых задач машина выполняет однотипно: решает ли дифференциальное уравнение или сочиняет музыкальное произведение. Если человеку, не знающему, что именно делает машина, выдать всю распечатку процесса, то вряд ли он сможет найти интерпретацию его на уровне первоначального замысла программиста. Стремление к тому, чтобы машина сама ^югла интерпретировать содержимое во внешних по отношению к своей памяти понятиях, в тех, которые связаны с семантикой задачи, было первым побудительным мотивом перехода от данных к тому, что стало называться знаниями. Ряд других требований, вытекающих из специфики невычислительных (в основном информационных и интеллектуальных) задач, еще более обособил знания от данных. Внутренняя интерпретируем ость Для того, чтобы система могла "знать", что собой представляет та или иная информационная единица, хранящаяся в ее памяти, необходимо снабдить эти единицы поясняющей информацией. Это могут быть имена-метки, фиксирующие отнесение информационной единицы к некоторому классу или типу. Если, например, и памяти системы хранится информация о животных, содержащихся в зоопарках мира, то отдельные информационные единицы могут входить в классы с именами-метками ги-па: страна, город, род, возраст и т.п. Это даст возможность системе понять, что за- ась < (Рол),(Тиф) > относится к перечислению зверей по родам, а запись <(Го-щ),(Берлин) > - элемент, относящийся к классу с именем-меткой "город". В общем виде запись < (имя-метка),(значение) > является тем кирпичиком, из кножества которых образуется содержимое памяти. Тахие кирпичики принято назы-шъ слотами. Более точно слотами называются записи вида: <(имя слога),(значение слота) >. Имя слота - это не обязательно простое имя-метка. В ка-(естве имени слота может выступать любой текст. Примером может служить слот: < (Главный герой романа Ф. Достоевского "Идиот"),(Князь Мыгакин)>. Слот может в качестве своего значения содержать некоторое имя-метку, и в этом случае он будет определять тавтологию двух имен слотов, что можно фиксировать изменением синтаксиса записи. Например: < (Утренняя звезда) = (Венера) >. Наконец, ргот может содержать знак вопроса или знак переменной в любой позиции. Например: <(Имя великого русского поэта Пушкина),(?) >, или < (Город),(Х)>, или <(?),(Тигр)>. I Слот первого типа представляет собой запрос к системе, выраженный в форме вопроса: "Как зовут великого русского поэта Пушкина?" Второй из приведенных слотов характеризует "внутренний запрос" самой системы. Слот такого вида называется протослотом. Это как бы оболочка, которая может быть заполнена любым нужным системе значением. Третий слот также характеризует некоторый вопрос к системе, соответствующий запросу: "Что тебе известно о тиграх?". Ответом в данном случае будет перечисление всех имен слотов, значением которых является "тигр". Разгадывая кроссворды, мы даем ответы на запросы тина: < (А) = (X) >, ще А - некоторое юве стн ое оп исан и е- и мя. Приписывание статусов Когда вычислительные машины манипулируют с данными, то истинность данных определяется самим их существованием. Если имеются данные, то нро!рамма все] -да оперирует с ними как с абсолютно истинными. Такое положение является весьма ограничивающим. В памяти системы могут храниться информационные единицы, для которых статус истинности необязательно должен совпадать с абсолютной истиной. Хранимая информация может отражать результаты экспериментальных наблюдений, опросов населения, Представлять собой чье-то личное мнение и т.д. Такая ситуация заставляет расширить структуру слота. При расширении слот будет выглядеть так: <(имя слота),(значенис слота), (статус слота) >. Тот статус, который приписывается слоту, можно назвать статусом истинности. В качестве заполнителя этой позиции слота могут выступать словесные оценки типа: абсолютная истина, эмпирическая истина, сомнительно, вполне вероятно и т.п. Друшми значениями, используемыми в этой позиции, могут служить условные числовые оценки, например вероятностные , статистические или получаемые в результате экспертного опроса. Статус истинности носит не абсолютный характер. Он отражает истинность, оцениваемую в рамках той модели, которая реализуется в системе. Например, система может оценивать пятый постулат Эвклида как абсолютно истинный, если она оперирует моделью, в которой он верен. Если же она переходит к другой модели геометрии, то хранящаяся в ее памати информация приобретает друшс статусы истинности. Операции композиции и декомпозиции Слоты неудобно хранить в памяти "россыпью". Было бы желательно обьединить в некое целое те слоты, которые связаны с понятиями, объектами, фактами, явлениями отображаемого в системе внешнеш мира, называемого обычно проблемной (или предметной) областью. В проблемной области сложные понятия описываются, конечно, не одним слотом, а характеризуются разными свойствами, параметрами, оценкам и. Для более удобного их описания в памяти системы можно использовать конструкции, называемые в искусственном интеллекте фреймом. <. (имя фрейма); < (имя слота 1),(значение слота 1)> < (имя слота 2), (значение слота 2) > < Фрейм представляет собой композицию слотов, объединенных между собой именем фрейма. Приведем пример фрейма. < (Зоопарк); < (Страна), (СССР) > < (Город), (Ереван) > <(Род),(Тигр)> < (Возраст),(7 лет) > >. Фрейм, в котором заполнены вес значения слотов, называется экзоашеймом. или фреймом-экземпляром. Экзофрейм описывает некоторый конкретный факт и является сложно структурированным образцом данных. Структура его может задаваться с помощью упоминавшихся механизмов формирования абстрактных типов данных. Но экзофреймы не исчерпывают собой все виды фреймов. От них отличается, например, протофрейм. или фрейм-прототип. Он представляет собой оболочку, в которой все позиции значений слотов помечены переменной X (может быть, с указанием на то, какие шраничения на область возможных значений должны в этой позиции выполняться). Протофреймы могут рассматриваться как внутренние определения понятий проблемной области, с которыми имеет дело система. Например фрейм: < (Демонстрация); < (Место), (Х1) > <(Дата),(Х2)> <(Цель],(ХЗ)>> определяет само понятие "демонстрация". Каждая конкретная демонстрация будет определяться при заполнении значений слотов этого протофрейма. Вывод: слот может рассматриваться как фрейм наиболее простого вида, что позволяет определять фреймы рекурсивно. В качестве слотов некоторого фрейма К-го порядка могут выступать фреймы (K-l)-ro порядка, а слоты можно считать фреймами нулевого порядка - это позволяет проводить в системе процедуры композиции и декомпозиции информационных единиц. Такие операции имеют прямые аналоги в организации человеческих (особенно научных) знаний и оказываются очень полезными в информационных и интеллектуальных системах. Операции и отношения для слотов Часто бывает удобно связывать между собой значения слогов определенными операциями. Например, при наличии фрейма: < (Парк автомобилей); < (Легко8ые),(Х1)> <(ГР"узо6ые),(Х2)> <(А6тобусы),(ХЗ)> < (Всего), jX4)>> удобно значение последнего слота получать суммированием значений первых грех слотов. Информацию о такой возможности в виде Х4 = Х1+Х2 + ХЗ можно включить в запись фрейма, введя для этого специальный слот с именем "внутренние операции". В этом случае при заполнении протофрейма "Парк автомобилей" по конк- •> сгаым данным, касающимся значений первых трех слотов, автоматически вычис-'> яется значение слота с именем "Всего". Необходимость введения отношений между значениями слотов можно показать ■ да примере уже упоминавшегося фрейма "Зоопарк". Пусть некоторый экзофрейм та-гаго вила записан как: < (Зоопарк); < (Страна) .(СССР) > < (Город),(Ереван) > <(Род),(Тигр, Ле8, Олень, Зебра) > < (Возраст),(7 лет, 10 лет, 3 года, 6лет)> > В этом фрейме два последних слота но своим значениям не являются независи-шми. Ясно, что значение "7 лет" относится к значению "Тигр", а значение "3 года" - к шачению "Олень". Но для того, чтобы эту информацию сделать доступной для вычислительной машины, необходимо связать слоты с именами "Род" и "Возраст" специальным отношением покомпонентного соответствия. Информация об этом отношении может быть записана в специальном разделе слота, структура которого при зтом будет выглядеть так; < (имя слот а), (значение слота),((отношение), (имя слога)) >. Для нашего примера запись слота "Род" будет иметь следующий вид: < (Род),(Ти1р, Лев, Олень, Зебра),((Покомпонентное соответствие),(Возраст))>. В слоте с именем "Возраст" удобно также указать на его отношение к значениям слота "Род". Отношения для фреймов Информационные единицы в проблемных областях существуют не сами ио себе. Оци связаны друг с другом разнообразными отношениями. Например, всякая научная система понятий в идеале образует классификации родовидового типа. В рамках этой классификации понятия делятся на более общие и менее общие. При описании различных процессов ситуации, которые можно рассматривать как информацион-аые единицы, оказываются связанными друг с другом временными, пространствен -еыми и каузальными отношениями. Иначе говоря, описание проблемной области должно отражать не только структуру понятий этой области и совокупность имеющихся в ней объектов и фактов, а саму структуру взаимосвязей. Поскольку в памяти вычислительной машины все понятия, объекты, факты, явления, процессы и тд,, входящие в описание проблемной облас-тн, задаются фреймами, то между фреймами необходимо устанавливать нужные связи. Для этого в структуру фрейма вносится специальный слот, имеющий следующую структуру: < (Слот свяэи);((имя первой связи).(имена фреймов)) ((имя Второй связи),(имена фреймов))
< (Демонстрация); < (Место), (Брянск) > <(Датз),(2.02.90)> <(Цель),(сеяэь 1)> < (Слот связи);((Средетбо-Цель), (Экология)) > > называется связапным с фреймом "Экология" отношением "средство - цель". Это тачает, что для расшифровки цели демонстрации, которая состоялась в Брянске \ февраля 1990 гола, надо обратиться к слотам фрейма "Экология" с тем же именем Цель". Если этот слот во фрейме "Экология" имеет вид: < (Цель),(Удовлетворение нормативных требований но загрязненности воздуха) >, то цель демонстрации про-меняется. С помощью специального вида связей между фреймами, которые называют связями наследования, клн отношениями наследования (к ним относятся, например, родовидовые и декомпозиционные связи, а также связи типа элемент-класс ил часть-целое), в памяти можно передавать нужную информацию из одной сдиницыв другую. При этом информация, касающаяся более крупной единицы, хранится лишь в ней. При необходимости менее крупные единицы обращаются "наверх" за нужной информацией с помощью слотов связи. Эта же информация может использоваться при обозначении слотов тех фреймов, которые оказываются подчиненными какому-либо "родовому" фрейму, - такая организация памяти избавляет от ненужного дублирования информации. При описании динамики изменений в проблемной области можно использовать нременные отношения между фреймами, касающиеся событий или ситуаций в этой области. В качестве имен связей в этом случае Moiyr выступать такие отношения, как "одновременно", "позже", "пересекаясь во времени" и т.п. В результате отношений между фреймами в памяти вычислительной машины об-разуется семантическая сеть. В общем виде семантическая сеть - ъто множество именованных вершин, имеющих некоторую внутреннюю организацию, и множеств именованных отношений между ними. Если структура вершин сети такова, что она отвечает фреймам, то говорят о фреймовой сети. Операции над фреймами Над фреймами удобно совершить по крайней мере две теоретико-множественные операции: объединение и пересечение. При объединении двух и более фреймов £ результирующем фрейме возникают вес слоты, которые присутствовали в исходны; фреймах, вместе со своими значениями для тех слотов, которые для объединяемы) фреймов не являются общими по имени. Для одноименных слогов в результирую щем фрейме имеется один слот с таким именем. Значение этого слота и есть объе динение значений соответствующих слотов в исходных фреймах. Имя объединенного фрейма присваивается системой цо некоторому имеющемус у нее правилу либо составляется из имен исходных фреймов, соединенных союзо» "или" (союз в этом случае имеет не разделительное значение). При пересечении в результирующем фрейме остаются лишь те слоты, которы присутствовали в каждом из исходных фреймов. Что касается значений этих слота то в алгебре фреймов можно выделить два вида пересечения. При первом виде операции пересечения слоты в результирующем фрейме соде[ жат только те значения, которые были одинаковыми в исходпых фреймах. Earn т; ким резу)цитирующим фреймам имя не присваивается специальной процедурой, т присваивается имя, состоящее из имен исходных фреймов, соединенных союзом У Пересечение второго вида даст в качестве значений слотов результирующет фрейма объединение значений исходных фреймов. Если имя такого результирующ го фрейма не определяется специальной процедурой, то оно образуется из имен hi ходных фреймов с помощью лексемы "сходен с". Умолчания При передаче сообщений между людьми есть одна особенность: сообщение ш когда не бывает абсолютно полным. Часть информации, содержащейся в сообш пии, считается сама собой разумеющейся, поэтому она отсутствует. Но пропуски информации могут свидетельствовать и о забывчивости, и о том, что эта дополи гельная информация вытекает из сообщения или вообще не нужна. У При создании интеллектуальных и информационных систем приходится принимать специальные меры для того, чтобы обработать подобные умолчания. Для это-[iro существуют специальные слоты, чаще всего называемые дефолт. >, Если в каком-нибудь слоте нет значения, а фрейм должен быть превращен в экзо-н фрейм, то происходит обращение к слоту с именем "дефолт": < (Дефолт);((имя сло-вта 1),(значение слота 1)),((имя слота 2),(значение слота 2)),...,((имя слота * К),(значение слота К)) >. Из слота "Дефолт" берутся хранящиеся в нем значения, ко-' торыми заполняются пустые позиции в основных слотах фрейма. 1 Активность Последнее отличие знаний от данных, которое надо отметить, весьма существен-' но. В классических программах, как уже говорилось, процедура решения задачи отделена от данных. Обычно в таких случаях говорят об отделении процедурных знаний (что и как делать) от декларативных (что дано вначале и какие промежуточные результаты надо далее обрабатывать для получения результата, который также является декларативным знанием). Такая ситуация предполагает, что декларативные знания пассивны (как пассивны данные при обычных программах), а процедурные - активны. Инициализация процедур приводит к активизации данных, по не наоборот. Однако у человека ситуация иная: именно декларативные знания являются у него активными. Например, знание о том, что в книжный магазин поступила интересующая нас книга, может активизировать начало процедуры, которая обеспечит покупку книги. Даже некоторое незнание (знание о незнании) может стать той активной силой, которая инициирует начало выполнения нужных процедур по ликвидации этого незнания. Для того, чтобы иметь возможность реализовать аналогичную ситуацию в системе информационных представлений о проблемной области, необходимо ввести в качестве значений слотов возможность ссылки на необходимость инициации определенных процедур. Такая ситуация уже возникала, когда использовался механизм умолчания: отсылка к слоту "Дефолт" и была такой процедурой, выполняемой каждый раз, когда обнаруживался слот с незаполненным значением. Итак, знания, как они понимаются в информационных и интеллектуальных системах, отличаются от данных активностью, способностью к образованию сложных структур, внутренней интерпретируемостью и необязательно абсолютной истинностью. Специалисты, занятые разработкой интеллектуальных систем, глубоко убеждены а том, что данные и знания - две большие разницы. ПРЕДСТАВЛЕНИЕ ЗНАНИЙ. Описанные фреймовые представления весьма популярны среди специалистов по искусственному интеллекту: многие экспертные системы, например, имеют в качестве своей основы именно такие представления. Говоря о том, что фреймовые сети можно рассматривать как частный случай семантических сетей, надо отметить, что па основе той же концептуальной модели, которая задается семантическими сетями, можно описывать и другие способы представления знаний. Примером их могут служить вычислительные модели, или вычислительные (функциональные) сети. Они активно используются при создании планировщиков, позволяющих автоматически синтезировать программы вычислений. В сетях такого рода вершины соответствуют некоторым модулям, определенным образом преобразующим информацию, а дуги указывают на то, какие входные значения должны быть найдены и переданы в данную вершину для возможности реализации модуля. Другим примером представления знаний, связанным с концепцией семантических сетей, могут служить сценарии. В сценариях часть вершин описывает конечные цели, а остальные вершины - подцели, на которые эти цели могут быть разбиты. Дуги соответствуют средствам, с помощью которых Moiyr быть достигнуты тс или иные полцели. Движение по сценарию от специальной начальной вершины к нужным целям с учетом тех ресурсов, которые имеются у системы на реализацию тех или иных средств - это процесс планирования целенаправленного (оптимального, если это необходимо) поведения. Совершенно иным классом моделей представления знаний являются системы продукций: в этих моделях каждая информационная единица представлена в виде продукции, которая может иметь следующую структуру: Имя продукции; Сфера; Предусловие; Условие; Ядро продукции; Постусловие Основной частью продукции является се ядро. Оно имеет вид: ЕСЛИ А, ТО В, где природа А и В может быть различной. Наиболее распространенным случаем интерпретации ядра продукции является замена его секвенцией, т.е. записью вида: А ^- В. Работа секвенции осуществляется следующим образом: если А истинно, то и В истинно; если А ложно, то о В ничего сказать нельзя. При такой интерпретации ядра продукции его можно трактовать как правило лошческоге вывода. Дру1-ая интерпретация ядра связана с идеей подстановки. В этом случае наличие в памяти системы или в некотором рабочем ноле, специально выделенном для этой цели А, приводит к замене его на В, Правила замены фиксируются вне самой продукции и могут &ыть различными. Имеется еще несколько интерпретаций, часто встречающихся в интеллеетуаль-ных системах: например, в роботах автономною типа ядро продукции интерпретируется как отношение "средство-цель", и в этом случае А есть некоторое средство для достижения В. Другая интерпретация заключается в замене ядра отношением типа "условие-действие". В такой ситуации выполнение условий А делает необходимым совершение действия В. Существует много других способов интерпретации ядра, в зависимости от которых в реализацию ядра будет вкладываться различный смысл, Имя продукции в ее структуре шрает такую же роль, как имя фрейма, и возникает из-за требований к возможности внутренней интерпретации информационных единиц, заданных в виде продукций. Сфера определяет, к какой подобласти проблемной области относится знание, фиксируемое в данной продукции. Если, например, с помощью продукций описаны правила поведения тииа: "Если п транспорте рядом с тобой стоит инвалид, а ты, не являясь инвалидом или старым человеком, сидишь, то уступи ему свое место", то с помощью информации, относящейся к позиции "Сфера", можно выделить правила поведения в транспорте, дома, в театре и кицо и тд. Наличие информации о сфере применения продукций облегчает поиск нужных продукций, сокращает перебор за счет обращения только к тем продукциям, которые входят в данную сферу. Смысл, связанный с позицией "Предусловие", выяснится позже, а что касается позиции "Условие", то в ней фиксируется информация, необходимая для проверки возможности применения ядра продукции в данной ситуации. Например, хорошо известная всем военнослужащим продукция: "ЕСЛИ навстречу идет старший по званию, ТО отдайте ему честь" не должна срабатывать в тех случаях, когда подобная встреча происходит в транспорте, кино и других местах, подходящих под действие соответствующего пункта воинского устава. Отсутствие необходимости приветствия в таких ситуациях должно следовать из тех процедур, которые реализуются в позиции продукции, названной "Условие". Когда ядро продукции сработает, Moiyr возникнуть условия для изменения какой-то информации, содержащейся в позициях "Предусловие" и "Условие" или в самом ядре продукции. Кроме того, существует возможность возникновения необходимос-ти обращения к какой-либо другой продукции. Информация об этих действиях и ус-ловиях их возникновения сосредоточена в позиции "Постусловие". Пусть в памяти системы хранится некоторое множество продукций, условно обоз-наченное Р. Оно образует систему продукций, разбитую на части в соответствии со сферами, к которым продукции относится. В какой-то момент времени часть про-дукций, у которых выполнены все условия срабатывания, из Р образует так называемое конфликтное множество продукций, или активный фронт продукций. На последовательных машинах при этом возникает проблема выбора продукции для исполнения. Этот выбор может быть либо случайным с равной вероятностью для всех продукций, вошедших н конфликтное множество, либо определяться некоторыми дополнительными условиями. Продукции могут, например, иметь абсолютные, относительные, динамические приоритеты или какие-то другие способы ран-«нрования. Необходимая для такого ранжирования информация хранится в позициях "Предусловие". Анализируя содержимое этой позиции для всех продукций, образующих конфликтное множество, система управления выполнением продукций делает соответствующий выбор. Теперь понятно, например, почему в позиции "Постусловие" может содержаться требование к изменению информации в позиции "Предусловие". Такое изменение может потребоваться, если используется система динамических приоритетов, в которой приоритет продукции возрастает по мере накопления времени ее пребывания в конфликтном множестве. Представление знаний с помощью продукций популярно среди специалистов по интеллектуальным системам не менее, чем фреймовые представления, по крайней мере по двум причинам. Первая - это возможность распараллеливания выполнения всех продукций из теку-щего конфликтного множества. При сегодняшних тенденциях к параллелизму в архитектуре вычислительных машин новых поколений подобная возможность ускорения преобразований становится весьма важной. Второй аргумент сторонников продукционных представлений состоит в том, что благодаря модульности они считаются более удобными. При необходимости «несения изменении в систему продукций, при замене одних продукций другими или их удалении из системы практически не надо изменять ничего в других продукциях (исключение составляет наличие ссылок из одних продукций в другие). При поиске противоречий в хранящихся знаниях, при корректировке знаний и выполнении других процедур модульность сугцественно повышает их эффективность. . Что же противопоставляют этим аргументам сторонники фреймовых представлений? Прежде всего сомнение в том, что любые знания можно представить в процедурной форме. Кроме того, в продукционных системах практически невозможно иметь достаточно богатые внутренпие интерпретации, за исключением имен-меток. Не совсем четко представляется выполнение операций над продукциями, композиции и декомпозиции продукций, установление разнообразных по семантике связей. Поэтому в последнее время наблюдается тенденция к сближению этих двух способов представления знаний; в этих смешанных системах представления знаний декларативная составляющая описывается фреймовыми представлениями, а продукционные системы описывают процедурную составляющую знаний. В подобных системах продукции работают над фреймовыми сетями или над более общими моделями декларативных знаний, приближающимися по своему уровню к семантическим сетям. Следует упомянуть еще об одной модели представления знаний, которая пользовалась популярностью на первом этапе развития работ в области интеллектуальных систем (в начале 70-х гг.), а сейчас имеет небольшое число сторонников. Речь идет о логических моделях представления знаний. В них знания представляются в виде формул в некотором логическом исчислении - как правило, в исчислении предикатов первого порядка или его расширениях. Возможность потузить описание проблемной области в некоторую логическую формальную модель на начальном этапе исследований по искусственному интеллекту не отвергалась. Это было связано с тем, что процедуры работы со знаниями отрабатывались на примере простых модельных проблемных областей: то "мира кубиков", то известной проблемы "обезьяна и банан". Подобные проблемные области настолько просты, что ничего не стоит описать их полностью, задать все необходимые аксиомы и правила вывода, с помощью которых можно путем логического вывода решить любую возникающую здесь задачу. Но для практически интересных областей почти невозможно дать полное и непротиворечивое описание всего, что в них есть, и свести решение всего множества характерных для них задач к процедуре лошческого вывода. Поэтому лошческие модели представления знаний остаются лишь там, где проблемные области просты и доступны для описания такого типа. Другие существенные изменения в области представления знаний определяются появлением и распространением оптических и голограф и ческих компьютеров с "картинной логакой", используемой при обработке образов. Такая техника заставит пересмотреть основные принципы, которые положены в основу систем представления знаний. ПРИОБРЕТЕНИЕ ЗНАНИЙ. Проблема приобретения знаний возникла с появлением интеллектуальных, прежде всего экспертных, систем. Именно в них нужно было представлять знания профессионалов о проблемных областях и способах принятия решений при тех или иных начальных условиях. С самого начала развитии прикладной математики идея формализации некоторой содержательной задачи считалась самым трудным этапом на пути поиска ее строгого решения. При массовом развитии и внедрении интеллектуальных систем эта проблема также стала массовой. И если раньше для перехода к математической постановке, адекватной содержательной задаче, достаточно было интуиции математика, то теперь стало необходимым создавать специальные средства для автоматизации этот этапа. Эксперт-профессионал обладает знаниями двух типов. Один из них составляет вербализуемый пласт, т.е. знания могут быть выражены словесно или с помощью различных схем, диаграмм, графиков и т.п. Эти знания легко "оторвать" от их владельца. Подобный процесс происходит, например, тогда, когда профессионал обобщает свой опыт в статье или монографии. Таким путем вербализуемые знания становятся доступными и для тех специалистов, которые не входят в непосредственный контакт с носителем знаний. Вербализуемые знания не так сложно вводить в память интеллектуальной системы; некоторые сложности связаны с формализацией качественной информации. Но за последние годы в этой области накоплен большой опыт. Быстрое развитие теории нечетких множеств породило немало приемов достаточно уцобного представления качественной информации в вычислительной машине, и практически с любыми НЕ-факторами (неточностью, недетерминированностью, неполнотой и т.п.) специалисты научились справляться. > Но эксперты-профессионалы являются носителями знаний и иного типа, отра-кжающих тот профессиональный оиыт специалиста, который он накопил в процессе о своей деятельности. Эти знания и выделяют специалиста и делают еш экспертом, е Сложность, однако, состоит в том, что эти наиболее интересные для воспроизве- - дения в интеллектуальной системе знания существуют как бы вне сознания, являют ся трудновыразимыми, невербализуемыми. ' Есть ли надежда "добыть" требуемые знания у специалиста?-Именно эта задача " находится сейчас в центре внимания специалистов по искусственному интеллекту, и ' первые результаты се решения обнадеживают. Появились специальные психологические методы косвенного выявления предпочтений специалистов при принятии решений, приемы, которыми пользуются эксперты при структуризации проблемной области, а также при формировании обобщений, используемых для сокращения описаний. Появляются первые инструментальные системы, с помощью которых можно создавать разнообразные средства для общения с экспертами, чтобы получить от них вербализованные и невербализованные знании. МАНИПУЛИРОВАНИЕ ЗНАНИЯМИ. Знания сами по себе еще не представляют большого интереса, с ними необходимо научиться обращаться. И поскольку структура знаний достаточно сложна, то и манипулировали с ими - процесс непростой. Для знаний, как и для данных, есть три основные задачи: запись новых знаний, поиск необходимых знаний и удаление ставших ненужными знаний. Но решение этих задач происходит не так, как в случае сданными. Данные не связаны между собой: добавляя новые или убирая ставите ненужными, нет необходимости учитывать другие данные. Поэтому основные задачи, связанные с изменением множества данных, происходят на физическом, машинном уровне: надо записать нужный код в свободной ячейке памяти или по адресу ячейки найти ее и стереть содержимое. Тесная связь данных с адресацией в памяти вычислительной машины, от которой не избавляют любые системы символьной адресации, используемые на уровне автокодов, существенно затрудняет решение многих задач, но снимает проблемы, связанные с поиском не по адресу ячейки, а по ее содержимому. То, что в программировании прошлых десятилетий называли ассоциативным поиском, и есть переход к поиску информации по ее записи в памяти. В обычных вычислительных машинах, в которых память не приспособлена к ассоциативному поиску, процедуры такого поиска данных неэффективны. Разработка специальной аппаратно организованной ассоциативной памяти большого объема все еще остаст- - ся попыткой. При переходе к знаниям ситуация резко меняется: знания оказываются связанпы-ми друг с другом с помощью богатого набора связей в силу своих свойств, поэтому при удалении знаний или вводе их в память возникает немало трудностей. Это требующие определенных затрат времени процедуры просмотра хранилища, выявление всех связей, которые должны исчезнуть или установиться, и изменение этих связей при выполнении процедур пополнения хранилища знаний и удаления из него. Кроме того, сами единицы знаний обладают такой сложной структурой, что прямая адресация их в памяти вычислительной машины становится невозможной. В итоге оказывается, что поиск нужных знаний возможен лишь по их структуре и содержанию. Такой поиск в теории искусственного интеллекта и в программировании решения интеллектуальных задач называется поиском по образцу. Для пояснения этой важнейшей для задач манипулирования знаниями процедуры предположим, что знания хранятся в памяти в виде семантической сети (см. рисунок). Ниже показан образец, по которому осуществляется поиск. Переменные X в образце свидетельствуют о том, что соответствующие вершины и дуги в этих местах . могут быть любыми. Результатом поиска должны быть все фрагменты в семантической сети, удовлетворяющие образцу. При отсутствии таких фрагментов будет выдан ответ: поиск оказался безуспешным. Два фрагмента сети, соответствующие образцу, показаны в нижней части рисунка.
Если в качестве модели используются не семантическая сеть и опирающиеся на нее представления (например в виде фреймов), то вместо поиска по образцу могут использоваться иные процедуры. Например, в логических моделях поиск часто осуществляется в виде вывода нужного утверждения. Это происходит потому, что в ло-шческих моделях, как правило, стараются минимизировать число формульных описаний знаний, а при необходимости получить их используют формулу запроса (образец) в качестве записи теоремы, которую надо доказать или опровергать в формальной системе, описывающей проблемную область. В смешанных системах представления образец может иметь форму продукции А => В, ще А - некоторый фрагмент сети, а В - либо фрагмент сети, либо какое-то указание на выполнение действий, процеЛур и т.н. В первом случае такой образец интерпретируется как замена всех фршментов в сети, соответствующих А, на фрагменты В (правила замены формулируются отдельно и реализуются при помощи специальных механизмов). Во втором случае обнаружение в сети фрагментов, соответствующих А, приводит к тому, что задается с помощью В. ■ Другой типовой прдедурой в системах представления знаний является обобщение. Возможны обобщения по именам, признакам и структурам. При первом типе обобщаются информационные единицы, снабженные одинаковыми именами. Реализация такой процедуры зависит от модели представления (например, при фреймовых представлениях соответствующие фреймы объединяются в теоретико-множественном смысле так, как об этом говорилось выше). Обобщение по признакам пребуст прежде всего уточнения того, что используется в качестве признака. Роль признаков могут играть разные составляющие структуры информационных единиц. При фреймовых представлениях это могут быть, например, значения слотов с определенными именами, сами имена слотов, содержание слота "Дефолт" и т.д. В зависимости от того, что выбрано в качестве признака обобщения, реализуются различные процедуры обобщения. Обобщение по структурам позволяет целые фрапиенты из информационных единиц, связанных между собой по одному типу, заменять новой информационной единицей. Образец, показанный на рисунке, является обобщением по структуре для фрагментов нижней части рисунка. Обобщение вместе со связями по наследованию информации способствует переходу от одноуровневых систем представления знаний к иерархическим. Манипулирование знаниями в интеллектуальных системах лежит в основе моделирования рассуждений специалистов при решении задач в проблемной области. Большое внимание к схемам профессиональных рассуждений, проявленное специалистами по искусственному интеллекту, позволило развеять логическую парадигму принятия решений, которая являлась бесспорной в течение мношх лет. По этой парадигме человек принимает решения в результате последовательного процесса, в котором каждый последующий шаг зависит от предыдущих Этот последовательный процесс в идеале совпадает с процессом логаческого вывода и поиска нуги к заранее намеченной цели. Эта парадигма питала иллюзии сторонников логических моделей представления знаний и легла в основу многочисленных работ в области поиска эффективных методов вывода, опирающихся на исчисление предикатов первого порядка (достаточно указать на такие методы вывода, как метод резолюций или обратный метод Маслова). Анализ схем рассуждений в реальных проблемных областях показал, что человек вместо логического вывода осуществляет аргум ен таиию. обосновывая Свое решение в системе имеющихся у него знаний. Чем отличается аргументация от логического вывода? Если все знания имеют статус абсолютной истинности, а операторы не могут изменить этот статус, то разницы между ар1ументацией и логическим выводом нет. Она обнаруживается тогда, когда статусы истинности знаний начинают отличаться от абсолютной истины, когда нельзя быть уверенным, что отсутствие некоторых знаний в памяти эквивалентно их абсолютной ложности, когда операторы преобразования знаний могут менять статусы истинности. Рассмотрим случай, когда все знания в памяти имеют статус абсолютной истинности, и операторы этого статуса не меняют. Тогда возможны два предположения о знаниях, которых нет в памяти. Первое предположение - это утверждение о замкнутости мира, или утверждение о том, что проблемная область описана полностью. Все, что в данный момент не записано в памяти, либо логически выводится из имеющегося, либо имеет статус абсолютной лжи. В замкнутом мире действуют обычные законы лотки, из которых главным является принцип монотонности. Если из множества утверждений, выведенных ранее {F.}, следует утверждение Ч*, то верно и то, что из {1P.}U1I' , где Ч/ есть любое утверждение, также следует Ч'. Другими словами, если что-то логически вытекает из некоторой информации, то добавление к ней новой информации ничего не меняет. На основании этого последователи Аристотеля в свое время были твердо убеждены в том, что утверждение "все лебеди белые" истинно. Они просто не знали, что в Австралии (еще не открытой европейцами) живут черные лебеди. Развитие любой пауки есть пень немонотонных построений. С появлением новых фактов исчезают старые теории и отвергается истинность утверждений, порожденных этими теориями; возникают вовые теории, и статусы истинности отдельных утверждений начинают изменяться. Поэтому куда более разумным представляется предположение об открытости ми-ца, о том, что немонотонные рассуждения являются не свидетельством "плохой науки", а сутью самого научного и любого другого познавательного процесса. В таких предположениях на CMeiry логическому выводу приходит аргументация. В процессе аргументирования некоторого утверждевия Sf происходит как бы "параллельный" процесс выдвижения аргументов, каждый из которых имеет свой статус ИСТИННОСТИ. Опенки истинности аргументов как бы суммируются, и когда эта "сумма" превышает некоторый порог, зависящий от важности Ч' дня того, кто оценивает аргументы, то У принимается, и ему присваивается некоторый статус истинности. При наличии контраргументов достаточной силы Ч* может быть отвергнуто, т.к. ему будет приписан статус ложности. Если при логическом выводе, когда каждый совершаемый переход не является абсолютно истинным, появление в цепи вывода перехода с малой оцевкой истинности может сделать ненадежным весь вывод, то при аргументации аргументы даже с очень маленькими оценками истинности работают только на пользу, внося свой позитивный вклад. В настоящее время в области искусственного интеллекта проводятся исследования по теории аргументации как теории обоснования новых знаний в уже имеющемся множестве знаний. Обращает на себя внимание еще одна парадигма, связанная с приобретением и обработкой знаний. Когда эксперт передает инженеру по знаниям информацию о закономерностях и фактах проблемной области и о том, как он решает свои задачи, то эксперт находится в рамках некоторых представлений о своей области и о своей работе в ней. Эти представления носят для него ценностный характер. Например, врач-онколог твердо уверен в том, что раковые заболевания носят вирусный характер, или геолог, занимающийся генезисом нефтяных месторождений, верит в то, что происхождение нефти является результатом трансформации органического вещества. В этих условиях специалисты будут сообщать инженеру по знаниям лишь ту информацию, которая не вступает в противоречие с их моделями. Об этой особенности экспертных знаний инженер по знаниям должен помнить всегда, иначе в вычислительную машину будет заложена информация с субъектив- ыми ценностными представлениями эксперта. В своих рассуждениях эксперт часто е аргументирует утверждения во всей совокупности известных знаний, а оправды-ает их в тех ценностных моделях, которые он принимает. Оправдание в системе 1енностей - это специальный метод введения новых знаний в общую их совокупность. Если при аргументации вновь принимаемое знание не должно противоречить ^анее имевшимся, то при оправдании это требование необязательно. Более того, финимая оправдываемое знание и обнаружив его противоречие с ранее накоплен-1ым, эксперт может уменьшить статус истинности того, что он знал раньше, а то и отвергнуть это знание. Процедуры оправдания еще только начинают изучаться специалистами по искусственному интеллекту. БАЗЫ ЗНАНИЙ. В интеллектуальных системах знания хранятся в специальном программном или программно-аппаратном блоке, называемом обычно базой знаний, В программировании существовал термин "базы данных"; появление нового термина свидетельствовало об отделении данных от использующих их программ. В базах дапных различают собственно базу и схему базы данных. Схема базы данных - это описание той информации, которая обеспечивает расшифровку запросов к базе данных. Таким образом, схема базы данных обеспечивает внутреннюю интерпретацию единиц, хранящихся в базе. Все процедуры, связанные с обращением к базе данных, поиском нужной информации в ней и выдачей ответов, обеспечиваются СУБД - системой управления базой данных. Аналогичным образом устроена и база знаний. В ней имеется схема базы знаний и СУБЗ - система управления базой знаний. В базе знаний обычно различают две составляющих: интенсиональную (схему базы знаний) и экстенсиональную (базу фактов). Разницу между этими составляющими легко уловить из фреймовых представлений. Множество протофреймов со всеми связями, описывающее как бы общее знание о проблемной области, и образует интенсиональную составляющую. Множество ■жзофреймов, т.е. утверждений о некоторых конкретных фактах, образует экстенсиональную составляющую. В базах знаний, кроме задач, относящихся к поиску информации по запросам, решаются еще и задачи постоянного слежения за состоянием базы. При вводе в базу новых знаний, исключении старых, установлении или уничтожении связей, изменении статусов истинности и т.п. происходят трансформации содержимого базы. Базы данных и знаний привлекают внимание инженеров по вычислительной технике спецификой набора базовых операций. Они отличаются от базовых операций, реализуемых на аппаратном уровне в классических вычислительных машинах. Предполагается, что для обеспечения эффективной работы с базами данных и знаний необходимо создать специализированные устройства - спецпроцессоры баз данных и знаний, разработка которых сейчас ведется довольно активно. Исследования в теории знаний - это не только исследования в области искусственного интеллекта, а исследования, относящиеся ко всем наукам, к той методологии науки, которая едина для всех сфер научной деятельности. СПИСОК ЛИТЕРАТУРЫ 1. Йагин ЗгН. Дедукции и оОобшвние В системах принятия решений. M.:Hayka, 198в. 2. Нильсон Н. Принципы искусственного интеллекта. ЬЛ.: CoGottcfcoe радио, 1985. 3. Поспелов Д.А. Сиггуационнов управление: Теория и практика. М.:Нву*а, 1986. J. Представление знании S человеКс-ыашинник и робототеинических система*. Том А. Фундаментальные исслеяойвмир в области представ'*™» знании/ Под ред. Д.А. Поспелове. - М.: ВЦ ftH СССР, ВИНИТИ. 1964. 5. Уинстйн П Искусственный интеллект. М.: Мир. 1980 6. ШенЬ Р. Обрабсет*а концептуальной информации м.; Энврния, I960. |

 (имя слота К),(значение слота К) > >
(имя слота К),(значение слота К) > > < (имя к-ой связи),(имена фреймоВ))> Например, фрейм
< (имя к-ой связи),(имена фреймоВ))> Например, фрейм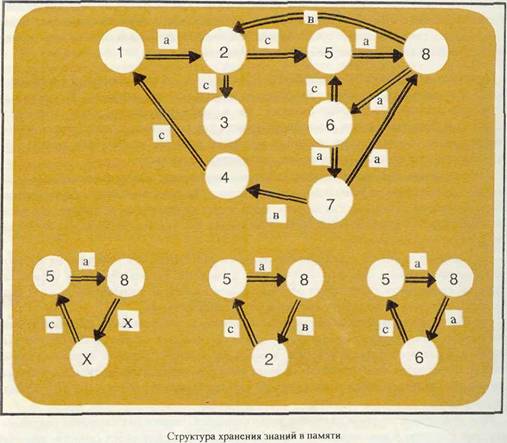
| Permanent link: http://swsys.ru/index.php?id=1422&lang=en&page=article |
Print version |
| The article was published in issue no. № 3, 1990 |
Perhaps, you might be interested in the following articles of similar topics:
- Разработка загрузчика программного обеспечения встроенной системы управления
- Электронный глоссарий
- Интерактивная процедура построения модели тренда для экономических показателей
- Исследовательское проектирование в кораблестроении на основе гибридных экспертных систем
- Оптимизация структуры базы данных информационной системы ПАТЕНТ
Back to the list of articles