Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: () - , (kvn@keldysh.ru) - , Ph.D | |
| Keywords: , , , |
|
| Page views: 7699 |
Print version Full issue in PDF (3.60Mb) |
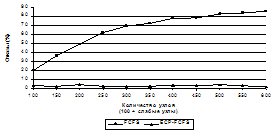
Одним из наиболее развитых направлений применения технологий Грида является создание мощных вычислительных инфраструктур. Для этого в большинстве современных Гридов используется объединение ресурсных центров отдельных организаций. Программное обеспечение, применяемое для их интеграции, рассчитано на ресурсные центры с кластерной архитектурой: входящие в их состав компьютеры связаны корпоративной сетью и в совокупности управляются системой пакетной обработки. Программное обеспечение предполагает полное выделение ресурсов центров в Грид. В последнее время повысился интерес к другому варианту организации Грид-инфраструктур из отдельных пространственно-распределенных, но некластеризованных компьютеров [1]. Причина в том, что подключенные к сети рабочие станции, серверы приложений, персональные компьютеры многочисленны и мало загружены, а их суммарная производительность довольно велика. Однако в этом случае требуется применение новых программных методов управления, так как компьютеры не выделяются в Грид полностью, а делятся между внешними заданиями, поступающими из Грида, и процессами их владельцев, поэтому будем называть их разделяемыми. В связи с этим необходимо решить две проблемы. Во-первых, обеспечить разделение ресурсов компьютера для выполнения основных процессов и выполнения внешних заданий, причем безусловный приоритет должен отдаваться первым. Во-вторых, сделать возможным завершение заданий в указанный предельный срок, так как в зависимости от деятельности владельца компьютера его загрузка меняется во времени, в результате доля остающихся свободными и достающихся заданиям Грида ресурсов отличается от их номинального количества. Первой проблеме посвящен ряд исследований (например [2,3]), в которых дана оценка ресурсного потенциала разделяемых компьютеров, количества остающихся свободными ресурсов, влияния внешних программ на интерактивную работу пользователей. В [4] предложен метод заимствования циклов, позволяющий безболезненно использовать свыше 90 % свободных циклов процессора. В данной работе предлагается подход к решению второй проблемы путем использования статистических характеристик компьютеров и учета их в алгоритме планирования распределения заданий. Статистические характеристики разделяемых компьютеров Для планирования в Гриде с разделяемыми компьютерами наиболее важными являются характеристики, определяющие загрузку ресурсов и позволяющие ее прогнозировать. Разработаны модели [5,6], которые предсказывают состояние ресурсов в пределах коротких отрезков времени (1–15 секунд). Эти модели служат основой для разработки механизмов разделения ресурсов компьютера. В Гриде обрабатываются задания с длительным (порядка часа) временем выполнения, и для планирования их распределения между компьютерами целесообразно использование статистических, усредненных по большим временным интервалам характеристик компьютеров. В контексте работ по созданию системы управления заданиями в Гриде с разделяемыми некластеризованными компьютерами проведено исследование возможностей улучшения стандартных методов планирования путем составления прогноза загрузки ресурсов на основе статистических характеристик. В качестве основного показателя, характеризующего функционирование компьютера с точки зрения его работы на Грид, введем понятие эффективной производительности. Эффективная производительность компьютера в некотором интервале времени T определяется как средняя величина процессорной мощности, которая остается неиспользованной при работе владельца компьютера и может быть получена внешним заданием. Она задается в условных единицах по отношению к производительности эталонного компьютера, принимаемой за 1. Если задание (рассматриваются счетные задания) на эталонном компьютере выполняется за время T, то на компьютере с эффективной производительностью H оно выполнится за время T/H. В системе управления Гридом данные, по которым вычисляется эффективная производительность, собираются отдельно для каждого компьютера. Для этого в составе менеджера, управляющего обработкой внешних заданий на компьютере, реализована программа, получающая от операционной системы значения текущей загрузки процессора [7] и периодически посылающая их в информационную базу планировщика. По собранным данным составляется прогноз эффективной производительности. Предлагаемый способ получения прогноза основан на предположении, что деятельность владельца компьютера в основном регулярна, мало отличается день ото дня, в течение суток могут быть перерывы в работе, а в конце рабочего дня компьютер, как правило, отключается. В связи с этим прогноз эффективной производительности представляется набором значений H, относящихся к временным интервалам, на которые разбиваются сутки. Для вычисления H на одном интервале производится усреднение полученных от компьютера значений текущей загрузки процессора методом скользящего окна значений H, относящихся к нескольким предыдущим суткам. Следует отметить, что существуют нерегулярные факторы, например, отпуск, когда компьютер может быть выключен в течение длительного времени. Учесть их трудно, и следует исходить из того, что прогноз не является точным. Использование прогноза эффективной производительности в алгоритме планирования В получивших известность системах управления разделяемыми компьютерами Condor, BOINC, Entropia, XtremWeb, OurGrid не учитывается то, что эффективная производительность не совпадает с номинальной, меняясь во времени в соответствии с ведущейся на них основной деятельностью. Вследствие этого возникают ситуации, когда задание, распределенное на некоторый компьютер, не успевает завершиться в заданный пользователем предельный срок. Прогноз эффективной производительности позволяет дать оценку времени завершения задания и использовать ее как дополнительный критерий при выборе компьютера. Таким способом можно уменьшить число отказов – превышений предельного срока – даже при неточном предсказании. Сформулируем условия, в которых решается задача планирования. В Грид поступает поток заданий {Ji, i=1,2,…}, они распределяются по компьютерам {Ck, k=1,…,Nc} в режиме онлайн, то есть каждое задание распределяется независимо от других. Исходными данными планирования являются: · характеристики заданий – длина (время выполнения на эталонном компьютере) Wi и предельный срок выполнения Di; · характеристики компьютеров – эффективная производительность Hk. Обычно для разделяемых компьютеров используются стратегии планирования, которые опираются лишь на характеристики заданий: First Come-First Serve (FCFS), List Scheduling, Earliest deadline first (EDF). Однако любое из них может быть модифицировано для учета эффективной производительности компьютеров. Сравним качество планирования алгоритмов FCFS и его модификации ECP-FCFS (Effective Computer Power – FCFS). Критерием является число отказов по превышению предельного срока. Алгоритм FCFS. 1. Если очередь не пуста и имеются свободные компьютеры, выбирается случайный компьютер и на него распределяется первое задание из очереди. 2. В противном случае ожидается поступление задания или освобождение компьютера. Алгоритм ECP-FCFS. На шаге 1 меняется способ выбора исполнительного компьютера: выбирается первое задание из очереди; задание распределяется только на тот компьютер, где оно может выполниться в срок. Если таких компьютеров нет, делается попытка распределить следующее задание из очереди. Оценка качества планирования Сравнение алгоритмов FCFS и ECP-FCFS выполнено путем моделирования их работы на синтетических входных данных, которые описывают поток заданий и характеристики компьютеров ресурсного пула. Компьютеры в количестве Nc=100 имеют эффективную производительность, генерируемую случайным образом по равномерному распределению из диапазона [0,1; 1,0]. Длина заданий и время их поступления также задаются равномерным распределением. Диапазон длины – [150; 750], задания поступают на временном отрезке [0; TS], где TS – минимально возможное время обработки пакета, вычисляемое как отношение суммарной длины всех заданий к суммарной производительности компьютеров. Предельный срок выполнения заданий выбирается пропорционально их длине Di=αi*Wi. Коэффициент αi фактически определяет нижнюю границу эффективной производительности, при которой задание может выполниться в срок; αi равномерно распределены в диапазоне [1,1; 5,0]. В результате моделирования обработки пакета 1 000 заданий выяснилось, что количество отказов алгоритма FCFS (201, то есть 20,1 % от числа заданий) превосходит количество отказов алгоритма ECP-FCFS (30, то есть 3 %). Улучшение, которое дает учет эффективной производительности, значимое, но не слишком большое. Объясняется это тем, что компьютеры со слабой производительностью (H<0,5), на которых в основном и происходят отказы, вносят небольшой вклад в суммарную производительность Грида. Если число таких компьютеров увеличивается, преимущество ECP-FCFS становится весьма существенным. Был проведен эксперимент, в котором к описанному компьютерному пулу дополнительно добавлены слабые (H=0,2) компьютеры. График зависимости количества отказов от числа добавленных компьютеров представлен на рисунке 1. Хотя суммарная производительность растет, в алгоритме FCFS число отказов линейно увеличивается, в то время как в ECP-FCFS оно остается постоянным.
Рис. 1. Зависимость числа отказов от количества добавленных слабых компьютеров В реальности прогнозируемая производительность будет отличаться от получаемой заданием во время выполнения. В следующем эксперименте изучалось влияние точности прогноза на число отказов. Относительное отклонение реально получаемой производительности Hr от прогнозируемой H задается величиной Q, Hr=H*(1+Q). Значения Q генерируются по нормальному распределению со средним значением 0 и стандартным отклонением σ. Величина σ является параметром исследования: при σ=0 время выполнения заданий совпадает с прогнозируемым, при больших σ оно может значительно отклоняться от прогноза.
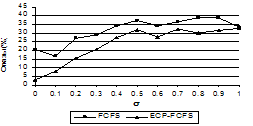
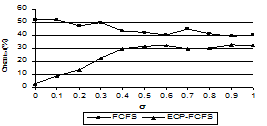
Рис. 2. Зависимость числа отказов от параметра σ Рисунок 2 иллюстрирует условия, когда производительность компьютеров и коэффициенты αi (определяющие предельные сроки заданий) распределены равномерно. Как видно из графика, использование прогноза в алгоритме ECP-FCFS уменьшает число отказов в исследованном диапазоне 0≤σ<1. При добавлении в пул слабых компьютеров (рис. 3) преимущество становится еще более заметным.
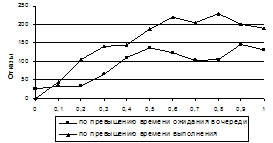
Рис. 3. Зависимость числа отказов от параметра σ в случае добавления 100 слабых компьютеров Эффективное использование пула разделяемых компьютеров Помимо уменьшения числа отказов, учет эффективной производительности компьютеров дает дополнительный эффект: при точном прогнозе (σ=0) невозможность обработки задания в срок определяется в период его нахождения в очереди, так что задание даже не распределяется на компьютер. Когда σ≠0, возможны два вида отказов: по превышению времени ожидания в очереди и по превышению времени выполнения (рис. 4).
Рис. 4. Соотношение числа отказов по превышению времени ожидания в очереди и по превышению времени выполнения Наличие прогноза позволяет, во-первых, заблаговременно информировать владельцев заданий о невозможности их обработки в срок и, во-вторых, не тратить ресурсы впустую. Для оценки продуктивности задействованной мощности ресурсного пула используем степень полезной загрузки ресурсов U теми заданиями, которые завершаются в срок: Суммирование в числителе отношения ведется по всем заданиям, обработанным в срок; STi и FTi – время старта и завершения задания i; Для исходного пула (с равномерным распределением производительности) полезная загрузка составляет 40 %. Когда к нему добавляются слабые компьютеры, суммарная мощность возрастает, но доля полезной загрузки уменьшается до 15 % (рис. 5).
Рис. 5. Доля полезной загрузки ресурсов в суммарной мощности пула в зависимости от числа добавленных компьютеров
Причина отказа в обслуживании заданий на незанятых компьютерах в том, что эти компьютеры имеют недостаточно высокую производительность для выполнения заданий в срок. Более полная загрузка ресурсов может быть достигнута с помощью известного способа запуска заданий в виде пачек подзаданий [8]. Задание J разбивается на множество подзаданий {SJ1,…, SJM}, каждое из которых выполняет часть вычислений. Наибольший эффект такое разбиение дает, если подзадания не зависят друг от друга и могут выполняться параллельно. Тогда можно обработать всю совокупность подзаданий в срок, определенный для задания J, но при меньших требованиях к производительности компьютеров. Время обработки задания J длины W на компьютере с производительностью H составляет Если задание J разбито на M подзаданий SJi, которые отличаются только входными данными, то время обработки каждого Эффективность декомпозиции и параллельного выполнения заданий иллюстрирует таблица. В первой строке приведены данные по обработке исходного пакета заданий, во второй – пакета, который получается из исходного путем разбиения заданий на подзадания одинаковой длины.
Количество подзаданий выбирается таким образом, чтобы каждое могло выполниться на компьютерах с минимальной производительностью (в данном случае 0,2). Приводятся стандартные показатели планирования – время счета пакета заданий и степень загрузки ресурсов, а также количество отказов. Как видно из этих данных, пакет с разбиением на подзадания обрабатывается с существенно меньшим числом отказов за меньшее время. Эффект объясняется более высокой степенью загрузки ресурсов. Выигрыш будет еще более ощутимым для пула, содержащего большое количество слабых компьютеров. Результаты моделирования позволяют сделать вывод, что учет эффективной производительности является необходимым аспектом планирования в Гриде с разделяемыми компьютерами, обеспечивающим предсказуемость обработки заданий. Развитие работ предполагает реализацию рассмотренных механизмов предсказания и планирования в системе управления Гридом и их опробование на действующем полигоне. Литература 1. Fedak G., He H., Lodygensky O. et al. EDGeS:A Bridge Between Desktop Grids and Service Grids. ChinaGrid Annual Conference, Aug 20–22, 2008. 2. Anderson D.P., Fedak G. The Computational and Storage Potential of Volunteer Computing. IEEE/ACM International Symposium on Cluster Computing and the Grid, Singapore, May 16–19, 2006. 3. Dinda P., Memik G., Dick R., Lin B., Mallik A., Gupta A., Rossoff S. The User In Experimental Computer Systems Research, Proceedings of the Workshop on Experimental Computer Science (ExpCS 2007), June 2007. (http://www.presciencelab.org/Clairvoyance/expcs07.pdf). 4. Eggert L., Touch J.D. Idletime Scheduling with Preemption Intervals. Proc. SOSP 005. (http://www.isi.edu/ touch/pubs/sosp2005.pdf). 5. Dinda P., O'Hallaron D. Host load prediction using linear models. In The 8th IEEE Symposium on High Performance Distributed Computing, 1999. 6. Brevik J., Nurmi D., Wolski R. Automatic Methods for Predicting Machine Availability in Desktop Grid and Peer-to-peer Systems, CCGrid 2004 GP2PC Workshop, 2004, Chicago, IL. (http://pompone.cs.ucsb.edu/~nurmi/mypapers/ccgrid04.pdf). 7. Березовский П.С., Коваленко В.Н. Состав и функции системы диспетчеризации заданий в Гриде с некластеризованными ресурсами. (Препр. ИПМ им. М.В. Келдыша РАН). – М., 2007. – № 67. – С. 1–29. 8. Mutka M. Considering deadline constraints when allocating the shared capacity of private workstations. Int. Journal in Computer Simulation, vol. 4, no.1, pp. 4163, 1994. |

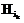 – эффективная производительность компьютера во время выполнения задания. В знаменателе MS – время счета пакета заданий;
– эффективная производительность компьютера во время выполнения задания. В знаменателе MS – время счета пакета заданий; 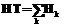 , где Hk – эффективная производительность компьютера за время MS; суммирование ведется по всем компьютерам ресурсного пула.
, где Hk – эффективная производительность компьютера за время MS; суммирование ведется по всем компьютерам ресурсного пула.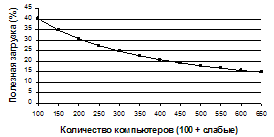
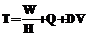 , где
, где  – время выполнения; Q – время ожидания в очереди; DV – время доставки входных и выходных файлов. Тогда минимальная производительность компьютера, обеспечивающая выполнение задания до наступления предельного срока DL, равна
– время выполнения; Q – время ожидания в очереди; DV – время доставки входных и выходных файлов. Тогда минимальная производительность компьютера, обеспечивающая выполнение задания до наступления предельного срока DL, равна 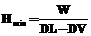 .
.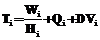 . Все множество подзаданий будет обработано за тот же предельный срок DL, что и исходное задание, если
. Все множество подзаданий будет обработано за тот же предельный срок DL, что и исходное задание, если 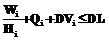 для всех i=1,..,M. Предполагая, что длительность выполнения всех подзаданий и время доставки файлов примерно одинаковые и равны соответственно
для всех i=1,..,M. Предполагая, что длительность выполнения всех подзаданий и время доставки файлов примерно одинаковые и равны соответственно 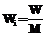 , Dvi=
, Dvi= 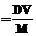 , можно дать следующую оценку минимальной производительности компьютеров:
, можно дать следующую оценку минимальной производительности компьютеров: 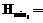
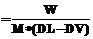 . При условии, что время доставки файлов каждого подзадания много меньше времени его выполнения, требования к производительности компьютеров снижаются в M раз.
. При условии, что время доставки файлов каждого подзадания много меньше времени его выполнения, требования к производительности компьютеров снижаются в M раз.| Permanent link: http://swsys.ru/index.php?id=2001&lang=en&page=article |
Print version Full issue in PDF (3.60Mb) |
| The article was published in issue no. № 1, 2009 [ pp. 3 ] |
Back to the list of articles