Journal influence
Bookmark
Next issue
Lexical ontologies WordNet in Semantic Wеb research
The article was published in issue no. № 4, 2009Abstract:The Semantic Web Research has resulted in the last years in significant outcomes. In this paper we review the last outcomes of Semantic Web technologies and descuss the requirements for lexical ontologies like WordNet. We describe Russian WordNet that is a lexical database for the Russian language and a conversion of Russian WordNet to RDF/OWL
Аннотация:В статье дается обзор технологий Semantic Wеb и определяется место в них лексических онтологий WordNet. Особое внимание уделяется лексической онтологиии WordNet для русского языка (Russian WordNet), разрабатываемой авторами статьи. Описаны структура онтологии, ее состав и возможные сферы применения. Разработка новых методик работы с подобными базами знаний с целью организации веб-добычи семантических данных является одной из приоритетных научных задач.
| Authors: (serge_yablonsky@hotmail.com) - , Ph.D, (serge_yablonsky@hotmail.com) - | |
| Keywords: russian wordnet, wordnet, lexical ontologies, semantic web |
|
| Page views: 18104 |
Print version Full issue in PDF (4.85Mb) |
В настоящее время исследователями все больше осознается необходимость перехода от документов, читаемых компьютером, к документам, понимаемым компьютером, что является одним из важнейших путей развития World Wide Web. Такой переход становится возможным на основе технологий Semantic Web (W3C Semantic Web Activity – http://www.w3.org/2001/sw/Activity). Проект Semantic Web (SW) предложил Тим Бернерс-Ли (Tim Berners-Lee) – один из основоположников WWW и нынешний председатель WWW-консорциума (W3C). Концепция SW заключается в организации такого представления информации в сети, чтобы допускалась не только ее визуализация, как это происходит сейчас, но и эффективная автоматическая обработка. Для этого необходимо решить целый ряд задач [1]. Выделяются следующие этапы развития WWW-сети. 1. Web 1.0 – объединение в сети информации и постоянное ее пополнение. 2. Web 2.0 – объединение в социальные сети людей – Social Web. 3. Web 3.0 – объединение в сети знаний. 4. Web 4.0 – объединение в сети людей и компьютеров для общения и получения знаний наравне друг с другом. Первые два этапа уже пройдены, третий и четвертый – перспектива. Базовая модель SW, по Тиму Бернерс-Ли, включает следующие компоненты: URI/IRI – универсальный идентификатор ресурсов; расширяемый язык разметки (XML); общая схема описания ресурсов RDF; метаданные и схема RDF Schema (RDFS); онтологии и языки их описания (OWL: OWL Lite, OWL DL, OWL Full); метаданные и схема OWL Schema (OWLS); язык запросов SPAROL к RDF-хранилищам; агенты/сервисы WSDL и схемы WSDLS и пр. Для RDF-данных разработаны форматы сериализации данных и обеспечивается интероперабельность приложений. Консорциум W3C предложил и использует стандарты по форматам XML, Namespace (пространства имен), RDF и RDFS (RDF-схем), которые позволяют специфицировать словари используемых терминов. Разрабатываются соответствующие спецификации для существующих и новых приложений (http://www.w3. org/RDF/). Результаты исследований уже используются в коммерческих целях [1]. В сети сформированы огромные ресурсы в виде RDF/OWL-баз знаний. Общий объем мета-информации достиг критической массы и неуклонно растет. На сентябрь 2006 г. пространство имен OWL было использовано в 113 000 документов Semantic Web (это 8 % от общего объема), пространство имен RDFS – в 677 000 документов (47 %). В августе 2007 г. в сети насчитывалось более 2 биллионов RDF-троек. В области представления знаний в виде онтологий консорциум W3C предложил стандарт на спецификацию онтологий – язык Web Ontology Language (OWL) (http://www.w3.org/2004/OWL/). OWL основан на RDF/RDF Schema и дополнительном словаре для представления свойств и классов. При разработке онтологий используется широкий спектр структур, представляющих знания о той или иной предметной области: глоссарий, простая таксономия, тезаурус (таксономия с терминами), понятийная структура с произвольным набором отношений, полностью аксиоматизированная теория. Онтологии различаются по ряду параметров. Выделяют различные основания для их классификации. Онтологии различают в зависимости от набора элементов, содержащихся в них, а также типов вводимых отношений. Классификация онтологий возможна по количеству и качеству понятий, в них включаемых. Онтологии верхнего уровня (top-ontology) обычно насчитывают примерно 100−3000 концептов. В них включены наиболее абстрактные категории, обладающие свойством универсальности, которые представляют базовое разбиение действительности на категории. Как правило, они строятся теоретиками и философами. Зачастую концепты даже не лексикализуются. Преимуществом таких онтологий является возможность их использования во многих областях и во многих языках. Для данного рода онтологий характерен ограниченный набор обобщенных отношений, которые можно отнести к базовым (родовидовые отношения, отношения часть–целое и ассоциативные отношения). В этих онтологиях на верхнем уровне разбиения такие понятия, как сущность, явление, объект, процесс, роль, являются типичными. К другому типу относятся онтологии среднего уровня (mid-level ontology − Suggested Upper Merged Ontology (SUMO) − http://www.ontologyportal.org/), в которых элементов обычно значительно больше (500–10000 концептов). Они представляют мир в целом, являясь в общем случае неаксиоматизированной областью. Сложность заключается в том, что для данного вида онтологий требуется выводить слишком большое количество аксиом. Обычно эта проблема решается с помощью методов автоматизированного вывода аксиом из уже существующих онтологий. Построением онтологий среднего уровня чаще всего занимаются когнитологи и лингвисты. Онтологии нижнего уровня, или так называемые онтологии предметной области (domain ontologies), наиболее обширны – обычно насчитывают около 2000–20000 концептов. Они описывают конкретные предметные области с их спецификой. При этом круг решаемых задач и вопросов, на которые отвечает онтология, ограничен выбранной областью. Для данного типа онтологий характерно наличие отношений, специфичных для конкретной области. Для них также возможно построение большого количества аксиом и правил. В большинстве случаев этот тип онтологий строится экспертами области знания или при их содействии. В связи с большой спецификой каждой предметной онтологии ее повторное использование зачастую возможно только в рамках самой предметной области. Примеры таких онтологий: UNSPSC (United Nations Standard Products and Services Codes) – http://www.unspsc.org/; NAICS (North American Industry Classification System) – http://www.census.gov/epcd/www/naics.html; SCTG (Standard Classification of Transported Goods) –http://www.statcan.ca/english/Subjects/Standard/sctg/sctg-menu.htm; E-cl@ss – http://www.eclass.de/; RosettaNet – http://www.rosettanet.org. Особый тип онтологий – лексические (или лингвистические). Их отличительное свойство – использование в одном ресурсе (лексикализованных) понятий (слов) вместе с их языковыми свойствами. Основным источником понятий в онтологиях данного типа являются значения языковых единиц. Их также отличает набор отношений, обычно свойственный языковым элементам: синонимия, гипонимия, меронимия и ряд других. К лингвистическим онтологиям относятся WordNet – http://wordnet.princeton.edu/; MikroKosmos – http://crl.nmsu.edu/Research/Projects/mikro/index. html; Sensus – http://www.isi.edu/natural-language/ projects/ONTOLOGIES.html и др. Круг задач, решаемых такими онтологиями, тесно взаимосвязан с обработкой естественного языка. Главной характеристикой лингвистических онтологий является то, что их единицы связаны со значениями языковых выражений (слов, именных групп и т.п.), что важно, когда речь идет о создании новых онтологий и лексикализации существующих. Существуют отображения большинства известных онтологий (SUMO, OpenCyc и др.) на WordNet. Важное направление исследований – использование онтологий верхнего или среднего уровня для разработки онтологий в конкретных предметных областях. В качестве такой общей онтологии при разработке предметно-ориентированных онтологий часто используется лингвистическая онтология WordNet. Работа над WordNet [2] ведется в Принстонском университете (США) с начала 80-х годов. Сейчас доступна версия 3.0, выпущенная в декабре 2006 г. (http://wordnet.princeton.edu/wordnet/ download/). Существующая версия WordNet (PWN) охватывает общеупотребительную лексику современного английского (american) языка (табл. 1). Основой WordNet являются синсеты – множества слов-синонимов, обозначающие один и тот же концепт в заданном контексте. Для синсета явно указываются часть речи и толкование. Каждое слово, входящее в состав синсета, дополнительно может иметь ряд атрибутов, например, признак доминантности, пометы типа «идиома», «близкое значение» и т.д. Для каждого синсета может быть приведен пример его употребления в заданном контексте – определяется набор речений и фразеологизмов, определяются толкования. Таблица 1 Статистика WordNet 3.0
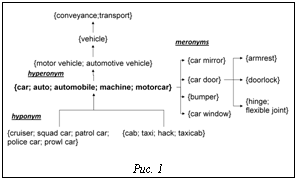
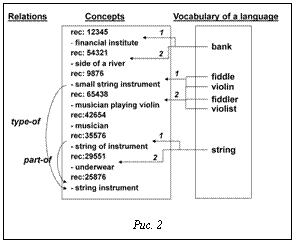
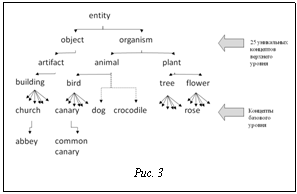
Основные отношения между синсетами зависят от части речи [2]. Пример некоторых отношений WordNet приводится на рисунке 1. Пример связи между отношением, концептом и словом в WordNet приведен на рисунке 2, а общая иерархия концептов WordNet на рисунке 3.
В период с марта 1996 г. по сентябрь 1999 г. при финансировании Европейской комиссии был создан многоязычный вариант WordNet – EuroWordNet. Эта лексическая система объединила в себе WordNet-словари английского, датского, испанского, итальянского, немецкого, французского, чешского и эстонского языков, а за основу был взят Принстонский WordNet версии 1.5. В 2004 г. завершилась работа над проектом BalkaNet, объединяющим греческий, болгарский, турецкий, чешский, французский, румынский и сербский языки. WordNet является единственной многоязычной лексической онтологией, охватывающей свыше 50 языков. EuroWordNet и BalkaNet являются закрытыми платными лексическими ресурсами в отличие от свободно распространяемого WordNet. В настоящее время известно о нескольких реализациях подобных WordNet лексических БД для русского языка. · Проект RussNet разрабатывается с 1999 г. на филологическом факультете СПбГУ (http://project.phil.pu.ru/RussNet/index_ru.shtml). · Проект тезауруса RuThes, используемого в университетской информационной системе «РОССИЯ» МГУ (УИС «РОССИЯ») (http://uisrussia.msu.ru/is4/servlet/is4.wwwmain); закрытый коммерческий ресурс. · Russian WordNet (http://www.pgups.ru/WebWN/wordnet.uix). Методика и принципы построения словаря проекта RussNet ориентированы на длительный процесс разработки ресурса группой лингвистов без какой-либо автоматизации процесса построения и связи с исходным WordNet. Проект RuThes невозможно оценить из-за его закрытости. Проект Russian WordNet (RWN) [3] ставит задачу создания русской версии WordNet, сопоставимой по числу лексических единиц с английской версией, на основе широкого привлечения различных лингвистических ресурсов и автоматизации разработки. Для построения RWN используются лингвистические ресурсы компании «Руссикон» (www.russicon.ru) и словари, свободно распространяемые в Интернете. Коллектив разработчиков RWN в 2003 г. выиграл конкурс издательства Oxford Press на лучший исследовательский проект по использованию словарей Oxford Press. Благодаря этому издательство Oxford Press предоставило для создания русской версии WordNet XML версии следующих словарей: Oxford Russian Dictionary; New Oxford Dictionary of English, 2nd Edition; New Oxford Thesaurus of English. Эти ресурсы используются для автоматизации процесса построения русско-английского WordNet. Разработка RWN предполагает решение следующих задач (рис. 4). · Построение русской версии WordNet, достаточно полно (100−120 тыс. лексических единиц) описывающей лексику русского языка и сопоставимой по числу лексических единиц с английской версией. Для этого используются морфологический анализатор, лексические ресурсы [4, 5], словари, свободно распространяемые в Интернете, и ряд печатных изданий. · Интеграция с другими лексическими системами на основе использования технологии SW. · Автоматизированное построение межъязыкового индекса, определяющего соответствие между синсетами PWN и RWN, на основе использования электронных версий словарей издательства Oxford Press, ряда доступных в Интернете англо-русских и русско-английских словарей, WordNet-Domains. На сегодняшний день RWN включает: 55397 существительных, образующих 71729 синсетов; 34400 глаголов, образующих 44998 синсетов; 25315 прилагательных, образующих 33571 синсет; 10071 наречие, образующее 9716 синсетов.
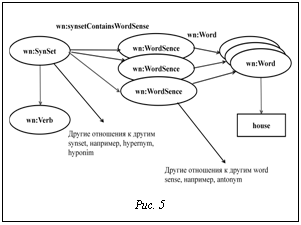
Редактор TenDrow предназначен для создания и редактирования широкого класса тезаурусов и близких к ним структур, он позволяет · работать с СУБД Oracle9i/10g/11g и Interbase/Firebird; · осуществлять обмен данными между БД и OWL-представлением WordNet (экспорт/импорт данных); · поддерживать форматы лексических файлов Princeton WordNet 2.0 и VisDic1.3.36 (для загрузки в БД). В рамках технологии SW консорциум W3C разрабатывает стандарт RDF/OWL-представления WordNet. Первая рабочая версия стандартного представления RDF/OWL для WordNet 2.0 была принята W3C Working Group (http://www.w3.org/ TR/wordnet-rdf/) в 2006 г. RDF/OWL-модель PWN основывается на трех основных классах свойств: Synset, WordSense и Word. Первые два делятся на четыре подмножества лексических типов – noun, verb, adjective и adverb, а последний состоит из одного подмножества Collocation. Описание основных свойств RDF/OWL-представления WordNet приведено в таблице 2. Графическая интерпретация RDF/OWL-представления WordNet приведена на рисунке 5. Таблица 2
RDF/OWL-представление WordNet было взято за основу для RDF/OWL-представления RWN и может использоваться как один из компонентов технологии W3C/SemanticWeb совместно с PWN в системах управления корпоративными знаниями, в поисковых системах, в технологиях SW, в различных системах обработки текстовой информации, в автоматизированных системах обучения. Литература 1. Хорошевский В.Ф. Пространства знаний в сети Интернет и Semantic Web // Искусственный интеллект и принятие решений. 2008. № 1. 2. Fellbaum C. WordNet: an Electronic Lexical Database. MIT Press, Cambridge. MA. 1998. 3. Balkova V., Suhonogov A., Yablonsky S. Russian WordNet. From UML-notation to Internet/Intranet Database Implementation. In: Proceedings of the Second International WordNet Conference, GWC 2004. Brno, Czech Republic, 2004, pp. 31–38. 4. Yablonsky S.A. Russicon Slavonic Language Resources and Software. RWN. In: A. Rubio, N. Gallardo, R. Castro & A. Tejada (eds.) Proceedings First International Conference on Language Resources & Evaluation. Granada, Spain, 1998, pp. 1141–1147. 5. Yablonsky S.A. Russian Morphology: Resources and Java Software Applications. In: Proceedings EACL03 Workshop Morphological Processing of Slavic Languages. Budapest, Hungary, 2003. |

 Для проекта RWN разработаны методы и программные средства, позволяющие значительно сократить время разработки. Так, разработаны редактор TenDrow [3] для редактирования WordNet и пакет специальных утилит построения WordNet и ILI-индекса.
Для проекта RWN разработаны методы и программные средства, позволяющие значительно сократить время разработки. Так, разработаны редактор TenDrow [3] для редактирования WordNet и пакет специальных утилит построения WordNet и ILI-индекса.| Permanent link: http://swsys.ru/index.php?id=2359&lang=en&page=article |
Print version Full issue in PDF (4.85Mb) |
| The article was published in issue no. № 4, 2009 |
Perhaps, you might be interested in the following articles of similar topics: