Journal influence
Bookmark
Next issue
Algotithmization of the including related lexeme procedures into the structure of the information-vocabulary basis
The article was published in issue no. № 4, 2009Abstract:The paper considers problems of adaptive algorithm modification of the basis informational component structuring of the multilingual-adaptive training technology to use the technique of foreign vocabulary training by means of intralingual associative fields building.
Аннотация:В статье рассмотрены вопросы модификации адаптивного алгоритма структурирования базисного информационного компонента мультилингвистической адаптивно-обучающей технологии для применения методики обучения иностранной лексике посредством построения внутриязыковых ассоциативных полей.
| Authors: (kovalev.fsu@mail.ru) - , Ph.D, (kovalev.fsu@mail.ru) - , (kovalev.fsu@mail.ru) - | |
| Keywords: lexically related components, frequency, information-vocabulary basis, multilingual adaptive-training technology |
|
| Page views: 8173 |
Print version Full issue in PDF (4.85Mb) |
Методика обучения иностранной лексике на основе лексически связанных (ЛС) компонентов (ЛСК-методика) [1] строится на специально подготовленной информационно-терминологической базе. Особенность данной методики состоит в том, что она позволяет искусственно формировать строго организованные системы внутриязыковых ассоциативных связей непосредственно в процессе обучения иностранной лексике. Являясь при этом частью мультилингвистической адаптивно-обучающей технологии [2], ЛСК-методика также учитывает языковые аналоги изучаемых лексем на всем множестве языков, с которыми работает [3]. Построение информационно-терминологического базиса (ИТБ) [4] как совокупности лексически связанных компонентов (ЛС-компонентов) – задача сама по себе неоднозначная. Многое зависит от требований, которые предъявляются к базису лингвистами и специалистами предметных областей, привлеченными к разработке. Такими требованиями могут быть фиксированное количество основных лексем или связанных лексем в компоненте, время разработки базиса, его качество, оцениваемое по некоторым критериям, и т.д. Перед тем как перейти непосредственно к алгоритмам формирования ИТБ ЛСК-методики, следует кратко описать структуру ЛС-компонентов. ЛС-компонент Структура ЛС-компонента схематично представлена на рисунке.
Лексему, связанную со всеми без исключения лексемами ЛС-компонента ИТБ, принято называть основной лексемой, лексемы, имеющие только одну связь, – связанными лексемами. Нисходящий алгоритм формирования ЛС-компонентов Рассмотрим разработанный ранее [1] нисходящий алгоритм (Н-алгоритм) формирования ЛС-компонентов. 1. Подготовка ИТБ. 1.1. Для каждой лексемы ИТБ вычисляется значение Li.
где mik – относительная частота сочетания i-й и k-й лексем, отражающая силу ассоциативной связи; qi – относительная частота, выражающая долю лексической единицы в тексте, подвергшемся статистической обработке при составлении частотного словаря, 0<1, 1.2. ИТБ упорядочивается по убыванию значения Li (таким образом, чем меньше будет порядковый номер лексемы, тем выше вероятность образования на ее основе ЛС-компонента). 1.3. Данные о лексических связях упорядочиваются по убыванию значения qkmik (тем самым увеличивается вероятность попадания в ЛС-компонент тех из связанных лексем, которые более всего могут улучшить качество ИТБ). 2. Поиск оптимального количества основных лексем. 2.1. Осуществляется перебор возможного количества основных лексем k от 1 до значения, равного объему ИТБ (возможно сужение интервала поиска разработчиком). 2.2. Для текущего значения k определяются основные лексемы (k первых лексем ИТБ). 2.3. Для выбранных основных лексем определяются связанные лексемы (как правило, задается максимум их количества). 2.4. Подсчитывается значение функции качества. 2.5. Если перебор окончен, переходим к пункту 2.6, иначе – возврат к пункту 2.1. 2.6. Определяем максимум функции качества (оптимальное число основных лексем kmax). 3. Формирование ИТБ как совокупности ЛС-компонентов (искомый ИТБ получается при прохождении пунктов 2.2 и 2.3 для kmax основных лексем). Восходящий алгоритм формирования ЛС-компонентов В целом данный алгоритм показывает неплохие результаты как по качеству ИТБ, так и по времени исполнения. Тем не менее, если обратиться к пунктам 2.2 и 2.3, становится очевидным, что связанные лексемы определяются согласно порядку основных лексем. Это может быть нерационально: естественно, что связанная лексема, являясь частью одного ЛС-компонента, уже не может быть частью другого, даже если она подходит ему больше (речь идет о конечном значении L(n)). Таким образом, возникает задача о нахождении наиболее подходящих связанных лексем для ЛС-компонентов в процессе их формирования. Эту задачу можно решить от обратного, то есть не подбирая для основных лексем связанные. Алгоритмы формирования ЛС-компонентов, реализующие данный принцип, будем называть «Восходящими» (В-алгоритмы). При этом данные о лексических связях (п. 1.3 Н-алгоритма) можно не упорядочивать. Итак, структура В-алгоритма будет следующей. 1. Подготовка ИТБ. 1.1. Для каждой лексемы ИТБ вычисляется значение Li. 1.2. ИТБ упорядочивается по убыванию значения Li (таким образом, чем меньше будет порядковый номер лексемы, тем выше вероятность образования на ее основе ЛС-компонента). 2. Поиск оптимального количества основных лексем. 2.1. Осуществляется перебор возможного количества основных лексем k от 1 до объема ИТБ (возможно сужение интервала поиска разработчиком). 2.2. Для текущего значения k определяются основные лексемы (k первых лексем ИТБ). 2.3. Осуществляется перебор неосновных (потенциально связанных) лексем, и для каждой неосновной лексемы выбирается наиболее подходящая основная (из множества, сформированного в п. 2.2) по критерию:
Таким образом, вычисляется максимальный прирост L(n), который обеспечивается вхождением текущей неосновной j-й лексемы как связанной в ЛС-компонент, образованный i-й лексемой (как правило, задается максимум количества связанных лексем). 2.4. Подсчитывается значение функции качества. 2.5. Если перебор окончен, переходим к пункту 2.6, иначе – возврат к пункту 2.2. 2.6. Определяем максимум функции качества (оптимальное число основных лексем kmax). 3. Формирование ИТБ как совокупности ЛС-компонентов. 3.1. Незадействованные в ЛС-компонентах лексемы из числа основных (kmax) помечаем как неосновные. Нахождение наиболее подходящих связанных лексем порождает свободные элементы из числа потенциально основных лексем, что во многом ухудшает L(n); поэтому не задействованные в ЛС-компонентах лексемы из числа основных (kmax) помечаем как неосновные. 3.2. Для полученного значения kmax основных лексем осуществляем шаги 2.2 и 2.3 и тем самым получаем искомый ИТБ. Сравнительный анализ приведенных алгоритмов Проведем сравнение алгоритмов на трех ИТБ одинаковой структуры, но различного объема [5]. Настраиваемые параметры базиса: - максимальное количество связей, приходящихся на одну лексему (10); - максимальное значение абсолютной частоты лексем (100/50000); - максимальное значение частоты сочетаний лексем (20/50000); - объем материала, по которому произведен частотный анализ (50000); - коэффициент связанности лексем (1). В таблице 1 приведены результаты теста 1 (объем базиса – 1000 терминов). В таблице 2 – результаты теста 2 (объем базиса – 2000 терминов). В таблице 3 – результаты теста 3 (объем базиса – 5000 терминов). Результаты тестирования для времени исполнения и L(n) приведены в сводной таблице 4. Таблица 1
Таблица 2
Таблица 3
Таблица 4
Оценить, насколько улучшает структуру базиса тот или иной алгоритм, невозможно ввиду ограничений и специфики L(n), которая служит для нахождения оптимального числа основных лексем и не может использоваться как абсолютный показатель качества ИТБ; но можно, используя экстремальные значения этой функции, сравнить алгоритмы формирования ЛС-компонентов между собой. В таблице 4 приведены результаты трех экспериментов (DL(n)=max L(n)–min L(n)), согласно которым В-алгоритм превосходит Н-алгоритм на 8,54; 6,16; 5,12 %, соответственно. Снижение этого превосходства сложно объяснить, поскольку проведено всего три эксперимента. Можно предположить, что негативное влияние свободных элементов из числа основных лексем (которые записаны как связанные) на L(n) становится сильнее с ростом ИТБ и постепенно подавляет положительное влияние наиболее подходящих связанных лексем. Поскольку ИТБ, с которыми работает ЛСК-методика, предметно-ориентированы и их объем, как правило, не превышает 5000 терминов, ограничимся тем, что В-алгоритм превосходит Н-алгоритм по качественным показателям на 5–10 %. По времени исполнения заметна тенденция: при увеличении объема ИТБ в n раз время исполнения алгоритмов возрастает в геометрической прогрессии, причем для В-алгоритма это время возрастает в n раз быстрее (исключая помехи на больших объемах ИТБ). Несмотря на большую негативную разницу по времени исполнения, В-алгоритм формирует более качественную структуру ИТБ. Поскольку операция формирования ИТБ выполняется только один раз, показатель качества много важнее времени исполнения алгоритма. Таким образом, В-алгоритм может успешно использоваться при формировании ИТБ как совокупности ЛС-компонентов. Единственным его серьезным недостатком является не время исполнения, а то, что заранее невозможно предугадать, сколько именно основных лексем будет в ИТБ. Когда же разработчик выставляет жесткие требования к количеству основных лексем (ЛС-компонентов) или когда важно время исполнения (очень большие объемы ИТБ), следует использовать Н-алгоритмы формирования ЛС-компонен- тов, в противном случае предпочтение следует отдавать В-алгоритмам. Подытоживая, отметим, что в данной статье проанализирован нисходящий алгоритм формирования ЛС-компонентов, выявлены его негативные стороны, сформулирована задача улучшения качества ИТБ. В рамках ее решения разработан конкретный В-алгоритм, а также сформулированы общие принципы работы восходящих алгоритмов формирования ЛС-компонентов. Проведен сравнительный анализ алгоритмов формирования ЛС-компонентов восходящего и нисходящего видов на базе экспериментов над ИТБ различных размеров. Литература 1. Ковалев И.В., Лесков В.О., Карасева М.В. Внутриязыковые ассоциативные поля в мультилингвистической адаптивно-обучающей технологии // Системы управления и информационные технологии. 2008. № 3.1 (33). С. 157–160. 2. Ковалев И.В. Системная архитектура мультилингвистической адаптивно-обучающей технологии и современная структурная методология // Телекоммуникации и информатизация образования. 2002. № 3. С. 83–91. 3. Карасева М.В., Лесков В.О. Автоматизация формирования информационной базы мультилингвистической адаптивно-обучающей технологии // Вестник СибГАУ. 2007. № 4 (17). С. 117–124. 4. Ковалев И.В., Огнерубов С.С., Лохмаков П.М. Программно-алгоритмические средства персонификации информационно-терминологического базиса в области аэрокосмической техники // Авиакосмическое приборостроение. 2007. № 9. С. 67–72. 5. Лесков В.О. Комплекс программного моделирования КПМ v. 1.0 М.: ВНТИЦ, 2008. № 50200802242. |

 ,
,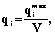 где qimax=max q{qi1, qi2,…, qin} – абсолютная частота появления лексической единицы в тексте; qi1, qi2,…, qin – частоты из мультилингвистического словаря, если речь идет о мультилингвистической адаптивно-обучающей технологии [4].
где qimax=max q{qi1, qi2,…, qin} – абсолютная частота появления лексической единицы в тексте; qi1, qi2,…, qin – частоты из мультилингвистического словаря, если речь идет о мультилингвистической адаптивно-обучающей технологии [4]. , L(n) показывает сумму взвешенных вероятностей знания лексем по всему базису, естественно, чем больше эта сумма, тем более удачно построен базис.
, L(n) показывает сумму взвешенных вероятностей знания лексем по всему базису, естественно, чем больше эта сумма, тем более удачно построен базис. .
.| Permanent link: http://swsys.ru/index.php?id=2382&lang=en&page=article |
Print version Full issue in PDF (4.85Mb) |
| The article was published in issue no. № 4, 2009 |
Back to the list of articles