Journal influence
Bookmark
Next issue
The operations of grammatics’ transformation
The article was published in issue no. № 1, 2010Abstract:To increase the resolution of information system and to perform the semantic data transformations on the syntactic level the usage of data format based on grammar is suggested. The operations of grammatics’ transformation permitting the generating of languages with required features are under discussion.
Аннотация:Для повышения разрешающей способности АИС и выполнения семантических преобразований данных на синтаксическом уровне предложено использовать формат данных, формальной основой которого является грамматика. Рассмотрены операции преобразования грамматик, позволяющие порождать языки с требуемыми свойствами.
| Authors: Drozhdin V.V. (drozhdin@yandex.ru) - Penza State University, Penza, Russia, Ph.D, (drozhdin@spu-penza.ru) - | |
| Keywords: grammatics’ transformation, grammatics, formal language, information system |
|
| Page views: 14599 |
Print version Full issue in PDF (4.03Mb) Download the cover in PDF (1.25Мб) |
Широкое внедрение автоматизированных информационных систем (АИС) в различные сферы деятельности человека требует все более интенсивного взаимодействия с ними людей с различным уровнем образования и квалификации. Однако взаимодействие с АИС резко ограничивается низкой способностью распознавания информации системой (только на уровне типов данных и полей форм) и невозможностью ввода и вывода данных в различных альтернативных формах (например, в краткой и полной форме, в виде «фамилия, имя и отчество» или «инициалы и фамилия») без соответствующего изменения программного обеспечения. Поэтому целесообразно ввести некоторый промежуточный уровень – формат данных, который в синтаксическом представлении данных позволил бы хотя бы частично учитывать их семантику и прагматику (ценность и удобство использования данных для решения определенных практических задач). Формат данных – это форма синтаксического представления данных, отражающая основные закономерности их построения, определяемые семантикой и использованием. Например, представление данных в краткой или полной форме, в форме, требуемой определенным документом или пользователем, и др. Формальной основой формата данных является грамматика, точно определяющая все синтаксические закономерности их построения. Между форматом данных и грамматикой есть определенные различия: - грамматика отражает только синтаксическую (конструктивную) сторону данных, а формат учитывает как синтаксическую сторону, так и использование, и семантику данных; - грамматика задает только единственный способ построения данных, а формат, отражая основные закономерности конструирования данных, может использовать различные грамматики для их построения; - формат выступает ограничением (играет роль управления) для грамматики представления конкретного набора данных; - формат может быть сформирован раньше, чем разработаны специализированные грамматики для представления данных, поэтому данные будут представляться и обрабатываться в рамках некоторой универсальной грамматики (например, последовательность символов или текст); - грамматика может изменяться и совершенствоваться, а формат будет оставаться фиксированным, но изменение формата почти всегда будет приводить к изменению грамматики. Формат представления набора данных, обладающих высокой степенью подобия, можно задать относительно небольшой совокупностью грамматических правил, что требует минимального объема памяти для хранения данных [1]. Набор данных сложной структуры может быть представлен системой форматов с иерархической или сетевой структурой. Это обеспечивает компактное хранение самих форматов данных и повышает возможность правильного распознавания данных в случае их перестановки или неполноты. Для выявления формата данных целесообразно использовать аналитический подход, разработанный в математической лингвистике для анализа естественных и формальных языков [2]. Пусть значения набора данных xÎX представляют собой конечные последовательности символов x=a1a2…an, где aiÎA. Все множество значений данных X составляет язык LX={xi çi Î I}, где I – номерное множество. Основываясь на анализе языка LX, АИС должна разработать эффективную грамматику GX=(T, N, P, S), удовлетворяющую условию LX=L(GX), где T=A – множество терминальных символов; N={nj ç jÎJ} – множество нетерминальных символов; P={p} – множество правил подстановки, заданных в виде продукций p: x®y, порождающих по слову x слово y; S – начальный символ грамматики, представляющий слова из LX в GX [3]. Для обеспечения высокой эффективности алгоритмов порождения грамматики GX и обработки данных на ее основе целесообразно строить грамматику GX в форме контекстно-свободной грамматики. Для осуществления преобразования грамматики G=(T, N, P, S) необходимо привести множество ее правил P к виду
Принципиальной особенностью грамматик вида (1) является то, что правая часть начального символа S состоит только из нетерминальных символов, каждый из которых имеет свою позицию (номер) и обладает семантическими и синтаксическими свойствами. Такая группировка правил отражает структуру порождаемых цепочек символов. Пример 1. Рассмотрим грамматику GA, представленную в виде (1), которая порождает последовательности символов типа «адрес»:
где e – пустая последовательность. Преобразование грамматики G вида (1) в грамматику G' такого же вида зададим формулой:
где q – допустимая операция над грамматикой G. Операции преобразования грамматик (3) предоставляют возможность задавать грамматику G' через грамматику G и наоборот. Таким образом, необязательно задавать обе грамматики с помощью четверок (T, N, P, S), достаточно иметь одну грамматику и множество допустимых операций q, чтобы сформировать требуемое разнообразие грамматик с определенными характеристиками. Рассмотрим подробнее операции преобразования грамматик. Замена цепочки символов – это операция получения грамматики G' из грамматики G вида (1) заменой правила pk грамматики G, порождающего цепочку символов a, на правило pk' грамматики G', порождающего цепочку символов b:
где pk : nk ® a; pk' : nk ® b. Пусть имеется грамматика G=(T, N, P, S) вида (1), множество правил P которой содержит некоторое правило pk: nk®a, pkÎP, nkÎN, где a – некоторая цепочка, состоящая из символов, принадлежащих словарю Т. Для получения грамматики G' операция замены цепочки символов (4) выполняет следующие действия. 1. Изменяет множество правил P: P'=P\pkÈpk'. Примечание. Множество правил P' может быть дополнено и другими правилами, необходимыми для вывода цепочки b; 2. Изменяет множество терминальных символов Т: - дополняет символами множества H1, которые входят в цепочку b, но не входят во множество Т (H1ÇТ=Æ): Т'=ТÈH1; - удаляет символы множества H2, которые входят в цепочку символов a, но не порождаются другими правилами грамматики G': Т'=Т\H2. Таким образом, после применения операции (4) к грамматике G получим новую грамматику G'=(T', N, P', S), которая будет порождать такие же цепочки символов, как грамматика G, но вместо цепочки a будет порождать цепочку b. Пример 2. Операцию замены цепочки символов продемонстрируем на грамматике (2). Грамматика GA порождает адреса в формате «ул. улица №_дома-№_квартиры» (например, «ул. Мира 12-34»). Курсивом в формате выделены поля, значения которых изменяются в различных порождаемых цепочках. Преобразуем грамматику GA таким образом, чтобы новая грамматика Удаление цепочки символов, qудал, является частным случаем операции замены цепочки символов, так как в качестве b выступает пустая цепочка символов e:
где pk : nk ® a; pk' : nk ® e. Для получения грамматики G' операция удаления цепочки символов (5) выполняет следующие действия: 1) изменяет множество правил P: P'=P\pkÈpk'; 2) изменяет множество терминальных символов путем удаления символов множества H2: Т'=T\H2. Множество H2 состоит из символов цепочки a, которые больше не порождаются другими правилами грамматики G'. Таким образом, после применения операции (5) к грамматике G получим новую грамматику G'=(T', N, P', S), которая будет порождать такие же цепочки символов, как грамматика G, за исключением цепочки a. Пример 3. Преобразуем грамматику (2) таким образом, чтобы новая грамматика Множество правил P' грамматики
Вставка цепочки символов, qвстав, позволяет получить грамматику G' путем добавления цепочки символов a в позицию k начального символа S грамматики G:
Таким образом, получим грамматику G'=(T', N', P', S'), в которой: 1) в позиции k начального символа S установлен нетерминальный символ 2) множество терминальных символов T дополнено множеством символов H, входящих в цепочку a (HÇТ=Æ): Т'=ТÈH; 3) множество нетерминальных символов дополнено символом N'=NÈ{ 4) множество правил P изменено следующим образом:
Примечание. Множество правил P' может быть дополнено и другими правилами, необходимыми для вывода цепочки a. Пример 4. Изменим грамматику (2) таким образом, чтобы она порождала адреса, в которых вначале указывается почтовый индекс:
В новой грамматике
Модификация числовых цепочек позволяет получить грамматику G' из грамматики G вида (1) путем изменения цепочки символов x, являющейся числовой переменной и порождаемой нетерминальным символом nk правила pk, на цепочку символов y, порождаемую из x по закону f:
где pk:nk®a, nk.val=x; pk' : nk®b, nk.val=y; y=f(x). Обозначение nk.val, приписывающее значение параметра val нетерминальному символу nk, будем рассматривать как расширение контекстно-свободной грамматики Хомского, называемое атрибутной грамматикой. Атрибутная грамматика позволяет каждому символу (терминальному и нетерминальному) порождающей контекстно-свободной грамматики приписать конечное число семантических параметров – атрибутов, которые принимают некоторые значения (они могут быть целыми, символьными цепочками, признаками, матрицами значений и т.п.) [4]. Допустимы следующие операции числовых преобразований, используемые в качестве закона преобразования f: - сложение: y=x+k; - вычитание: y=x-k; - умножение: y=x*k; - деление: y=x/k; - тригонометрические функции: например, y=sin(x); - другие математические операции над числами. Здесь k – произвольный коэффициент, учитываемый в законе f. После применения операции (7) к грамматике G будет получена грамматика G'=(T, N, P', S) со множеством правил P': P'=P\pkÈpk'. Пример 5. Рассмотрим грамматику GД=(T, N, P, S) вида (1), порождающую даты 21-го столетия, в которой запись года представлена в сокращенном формате (01, 09, 14 и т.д.):
Преобразуем грамматику GД при помощи операции (7) таким образом, чтобы запись года была представлена в полном формате (например, 2001, 2009 и т.д.): Изменение порядка следования цепочек позволяет получить грамматику G' из грамматики G вида (1) путем взаимного изменения позиций двух нетерминальных символов в начальном символе S грамматики G:
Пусть задана грамматика G=(T, N, P, S) вида (1) со множеством правил P:
Для получения грамматики G' операция изменения порядка следования цепочек (7) модифицирует только начальный символ S, переставляя местами нетерминальные символы Рассмотрим комплексное преобразование грамматики G с помощью множества допустимых операций преобразования Q. Пример 6. Модифицируем грамматику (8), порождающую даты в формате «дд.мм.гг» (европейский формат), таким образом, чтобы новая грамматика порождала даты в формате «мм/дд/гг» (американский формат). Для этого используем множество операций Q: Q={qпоряд, qзам}. Применим к грамматике GД следующую последовательность операций:
где p2' : n2 = / , p4' : n4 = / и получим грамматику GД' вида: GД'=(T', N, P', S'), в которой множество терминальных символов
Таким образом, в работе дано развернутое определение формата данных и перечислены его свойства. Рассмотрена формальная составляющая формата – грамматика, и определено множество основных операций преобразования грамматик. Литература 1. Дрождин В.В., Баканов А.Б. Грамматика описания домена фамилий // Вопросы радиоэлектроники. Сер.: Электронная вычислительная техника. 2007. Вып. 1. С. 77–82. 2. Маркус С. Теоретико-множественные модели языков. М.: Наука, 1970. 332 с. 3. Линьков В.М., Дрождин В.В., Лушникова Е.В. Порождение грамматики описания данных в информационных доменно-ориентированных средах // Проблемы информатики в образовании, управлении, экономике и технике: сб. стат. III Всеросс. науч.-технич. конф. Пенза, 2003. С. 8–11. 4. Карпов Ю.Г. Теория и технология программирования. Основы построения трансляторов. СПб: БХВ-Петербург, 2005. |
 (1)
(1) (2)
(2) , (3)
, (3) (4)
(4)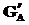 порождала адреса в формате «улица улица №_дома-№_квартиры» (например, «улица Мира 12-34»):
порождала адреса в формате «улица улица №_дома-№_квартиры» (например, «улица Мира 12-34»):  , где p1 : n1 ® ул.; p1' : n1 ® улица.
, где p1 : n1 ® ул.; p1' : n1 ® улица. (5)
(5) .
.
 . (6)
. (6) ;
;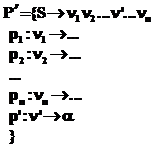
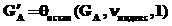 .
.
 , (7)
, (7) (8)
(8) .
. . (9)
. (9)
 .
. ,
, , а множество правил
, а множество правил  :
: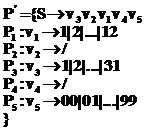
| Permanent link: http://swsys.ru/index.php?id=2425&lang=en&page=article |
Print version Full issue in PDF (4.03Mb) Download the cover in PDF (1.25Мб) |
| The article was published in issue no. № 1, 2010 |
Perhaps, you might be interested in the following articles of similar topics:
- Методики оптимизации транспортно-погрузочного комплекса предприятия
- Анализ особенностей процессов управления требованиями к информационным системам государственных структур
- Моделирование информационных ресурсов при процессной организации системы управления предприятием
- Управление развитием надежных кластерных структур информационных систем
- Математическое обеспечение информационно-аналитической медицинской системы
Back to the list of articles