Journal influence
Bookmark
Next issue
Using the pattern recognition methods for estimation of IT-projects development duration at the first stages of engineering
The article was published in issue no. № 3, 2011Abstract:The formalized target setting for estimation of new projects duration is described. The formulas and algorithm for searching the close projects based on the pattern recognition theory are given. The method for estimation of the project engineering duration is offered and the description of the developed software realizing the offered method is given.
Аннотация:Описана формализованная постановка задачи оценки длительности новых проектов. Приведены формулы и алгоритм для нахождения близких проектов, основанные на использовании теории распознавания образов. Предложен метод для оценки длительности разработки на начальной стадии и приведено описание разработанного программного продукта, реализующего данный метод.
| Authors: (kulikova@sigasis.ru) - , Ph.D, (a1p2m3@gmail.com) - | |
| Keywords: pattern recognition method, software product, IT-projects, development duration estimation, investments |
|
| Page views: 17342 |
Print version Full issue in PDF (5.05Mb) Download the cover in PDF (1.39Мб) |
Задача определения длительности разработки ИТ-проектов связана с вытекающим из свойств проектной деятельности парадоксом: потребность в решении этой задачи бывает максимальной тогда, когда возможности ее решить минимальны. Поясним это утверждение. Согласно ГОСТу 34.601-90, первоначальный расчет длительности проекта требуется на стадии формирования требований к автоматизированным системам (АС). Оценка целесообразности проводится на основе сопоставления затрат и эффекта (результатов) от предполагаемого проекта. Затраты, в свою очередь, являются линейной функцией от длительности работ. При этом еще нет никакой информации об объеме проекта, его функциональности и сложности, поскольку полное обследование предстоит выполнить на следующей стадии. Таким образом, требуется оценить целесообразность проекта и принять решение о продолжении работ на основе практически нулевой информации об этом проекте. Далее на стадии разработки концепции АС детально обследуется объект автоматизации, разрабатываются альтернативные варианты концепции, причем для каждого варианта оцениваются необходимые на их реализацию ресурсы. Затем выбирается наиболее оптимальный вариант, для которого разрабатывается техническое задание (ТЗ). На данной стадии имеется полное представление об объекте автоматизации, только об общей идее проекта, границах и об архитектуре будущей АС. При этом необходимо оценить длительность будущего проекта. Более четкое представление о проекте формируется в процессе разработки ТЗ, в котором прописываются все требования к АС. По ее завершении имеется информация о функциональном составе АС, перечне выходных документов, а также обо всех ограничениях (в виде нефункциональных требований), накладываемых на проект. На этом заканчивается предпроектная подготовка и начинается собственно проектирование (техническое и рабочее), расчеты длительности разработки проводить уже не требуется. Именно на этапе проектирования появляется информация, позволяющая достоверно рассчитать длительность проекта. Дело в том, что существующие методы аналитических расчетов длительности основаны на использовании в качестве аргументов таких характеристик проекта, как число строк (команд), количество функциональных точек и т.п., которые становятся известными в ходе детального проектирования и написания кода. На этих стадиях, как уже было сказано, потребность в расчете длительности проекта становится минимальной. Таким образом, при решении задач оценки длительности новых проектов сама проектная деятельность обусловливает необходимость использования методов анализа статистических данных. На взгляд авторов, наиболее оптимальным является метод распознавания образов, который, в свою очередь, входит в группу методов, использующих концепцию нейронных сетей. Для оценки длительности новый проект относят к одному из классов, полученных на основе статистических данных о выполненных ранее проектах. При этом для каждого класса известно значение длительности (интервала), которое и припишут новому проекту. По мере накопления информации о выполненных проектах будет уточняться набор классов и, возможно, сужаться интервал длительности.
Для решения поставленной задачи рассматривается множество проектов Р={р1, р2, …, рn}. Каждый из них характеризуется величиной длительности ti (i=1, …, n), а все величины составляют множество длительностей T={t1, t2, …, tn}. Проект может быть описан набором признаков Х={х1, х2,…, хm}, доступных на ранних этапах проектирования, каждый из которых тем или иным образом влияет на величину длительности проекта. При этом n – общее количество проектов; m – количество измеряемых признаков. Путем измерения значений признаков каждому из элементов рiÎР будет поставлен в соответствие вектор xi=(xi1, xi2, …, xim), где xij – количественное значение признака xjÎХ. Значения признаков нормируются и приводятся к значениям в диапазоне [0, 1]. В результате получим матрицу М(n,m), состоящую из векторов xi=(xi1, xi2, …, xim). Выполненный проект, для которого известны реальная длительность разработки (tiÎT), а также значения признаков xjÎХ, будем называть известным проектом, а проект, для которого требуется найти предполагаемую длительность разработки, при этом известны лишь значения признаков X, – новым проектом. Человеко-машинная система оценки длительности проектов состоит из трех блоков – обучение, распознавание, накопление данных (рис. 2).
Задача распознавания состоит в указании принадлежности входного образа проекта, представленного вектором признаков, к одному из предварительно определенных классов. За счет накопления статистической информации о реальной длительности выполненных проектов системой будет достигаться требуемая точность в оценке длительности новых проектов. Обучение происходит в результате выполнения шагов, представленных на рисунке 3. На первом из них выполненные проекты разбиваются на классы в зависимости от попадания их фактической длительности в определенный интервал Tl±D, где l – номер класса. Построенную таким образом модель классов будем считать эталонной, или референтной, моделью. На следующем шаге анализируются выполненные проекты и изучаются общие свойства проектов, имеющих близкие значения длительности, а также определяются отличительные характеристики проектов с различной длительностью. В результате выбираются признаки, влияющие на длительность ИТ-проектов, доступных на ранних стадиях проектирования. Строится матрица М(m, n). Осуществляется нормализация признаков. Далее выбирается метрика для определения меры близости объектов, и на ее основе имеющиеся проекты разбиваются на классы. На третьем шаге проведенная классификация оценивается с точки зрения совпадения полученных классов с классами референтной модели. При неудовлетворительной классификации анализируются выбранные признаки и их веса и методом подбора получаемые классы приближаются к референтной модели. В случае совпадения полученных классов процесс обучения на данной итерации считается завершенным, системе разрешается переходить к распознаванию. По мере накопления статистических данных на последующих итерациях функционирования система будет переходить в режим обучения (доучивания). Классификация проектов на основе признаков осуществлялась с использованием метода k ближайших соседей [1–3], при котором проект относится к тому классу, к которому принадлежит большинство ближайших к нему известных проектов (их количество определяется числом k). Близость двух проектов определяется на основе евклидова расстояния:
где wj – вес j-го признака; xsj – значения признака xj для нового проекта (ps); xij – значение признака xj для проекта pi из множества известных проектов P.
ts=f(Tk), (2) где f(Tk) – функция получения среднего значения (
При данном методе расчета требуется правильный выбор параметра k, так как с его увеличением снижается четкость границ классов, а при уменьшении понижается достоверность. Поэтому на практике его поиск осуществляется эвристическими методами, такими как перекрестная проверка или описанный выше алгоритм обучения. Метод поиска k ближайших соседей имеет следующие достоинства [2]: · предназначен для работы как с количественными, так и с качественными данными; · автоматически улучшает точность работы при увеличении количества исторических данных; · логично вписывается в концепцию работы с БД, содержащими статистические данные.
1. Признаки группы разработчиков X1: опыт работы в прикладной области, навыки владения языками и инструментарием, знание одних и тех же принципов разработки, общая квалификация программистов, слаженность команды, использование программных инструментов. 2. Признаки заказчика (объекта, для которого разрабатывается проект) X2: количество отделов, количество филиалов, число сотрудников, число квалифицированных ИТ-сотрудников, число сотрудников с высшим образованием, характеристика продуктов/услуг, сменяемость персонала, количество сотрудников, непосредственно отвечающих за разрабатываемое ПО. 3. Признаки проекта X3: объем обрабатываемых данных, степень требуемой документированности, похожесть на прошлые проекты, сложность продукта, необходимая надежность, требования по быстродействию, аппаратные ограничения, уровень предполагаемого пользователя, количество пользователей, требования к безопасности, поддержка различных платформ. 4. Признаки, характерные для конкретной группы продуктов X4. На данном этапе разработки выделены признаки для одной из групп ПО – web-приложений. К ним относятся расположение (внешнее, внутреннее), частота обновлений, интеграция с существующими системами (текущими, планируемыми), количество стандартных и нестандартных модулей. Первые три группы являются универсальными и применяются для всех проектов, а четвертая группа зависит от вида проекта.
Основными объектами системы оценивания являются следующие: · пользователи – зарегистрированные пользователи системы, привязанные к группам разработчиков; · группы – группы разработчиков, преимущественно из числа своих специалистов, для повышения точности оценки; · проекты – все проекты по разработке ПО; завершенные проекты отмечаются специальным флагом и содержат информацию о реальных результатах (сроках, трудоемкости и т.п.) работы; · свойства проекта – атрибуты проекта, по которым проводится оценка; · атрибуты – список атрибутов для оценки проектов; · типы оценок – диапазоны (варианты) экспертных оценок; · шкалы – наборы коэффициентов, применяемых для более точной оценки; · классы проектов – список типов проектов, имеющих разные наборы атрибутов; · расчет – подсчет оценки на первом этапе; · результаты – реальные исторические данные завершенных проектов. Для хранения данных в системе оценки длительности разработана БД, упрощенная схема которой приведена на рисунке 5. Программный продукт реализован в виде веб-приложения на интерпретируемом языке программирования PHP с использованием СУБД MySQL в качестве хранилища данных; доступ осуществляется через обычный браузер. Основой для приложения выбран Zend Framework, на базе которого разработан собственный фреймворк AbsLibrary, ориентированный на работу с отображаемыми в БД объектами, избавляющий разработчика от решения технических задач и позволяющий сконцентрироваться на требуемых функциях оценки. Выделим основные свойства разработанного фреймворка: · использует архитектуру MVC (как и приложения, написанные с его применением); · является шаблоном для разработки архитектуры приложения; · предоставляет простые средства для выполнения действий над объектами, отображаемыми в таблицы БД (с поддержкой связанных таблиц): поиск, просмотр, добавление, изменение, удаление, работа со списками, экспорт и импорт, изменение свойств и методов объектов; · содержит встроенные средства кэширования, создания логов и обработки ошибок; · содержит гибкую систему контроля доступа (ACL), механизм авторизации; · поддерживает темы оформления; · содержит средства для управления меню. Авторами предусмотрена возможность подстройки процесса расчета без необходимости изменять накопленные данные о проектах или перепрограммировать систему. К таким методам относятся использование шкал, изменение используемой метрики, добавление подготовки данных (online), такой как нормализация или масштаби- рование. Шкалы, введенные в формулу (1) как группа наборов значений wj, позволяют изменять степень влияния конкретных признаков в соответствии с их значимостью для проекта. Поскольку проект имеет модульную структуру, изменить метрику можно с помощью реализации дополнительного модуля, не изменяя всю систему. Предварительная обработка данных может происходить с помощью дополнительного обработчика (перед передачей их для вычисления расстояния близости). При оценке инвестиционной привлекательности ИТ-проекта наиболее важным и одновременно наиболее сложным для расчета показателем является длительность его разработки. Это связано с тем, что она используется при расчете многих характеристик проекта в качестве основной переменной. Однако на этапе принятия решения о начале инвестирования отсутствует большое количество информации о характеристиках проекта, на основе которых обычно рассчитывают продолжительность разработки, а доступные для этого этапа методы (например экспертные оценки) дают низкую точность. Поэтому авторами разработан метод, позволяющий проводить оценку длительности разработки ИТ-проекта на ранних сроках. Предлагаемый метод основан на комбинировании принципов распознавания образов, на использовании статистических данных, опосредованных экспертных оценок и механизмов обучения и самообучения. Также данный метод имеет возможность адаптивной настройки для специфических условий. На основе этого метода разработано ПО, позволяющее проводить расчет длительности ИТ-проектов. Литература 1. Сегаран Т. Программируем коллективный разум; [пер. с англ.]. СПб: Символ-Плюс, 2008. 368 с. 2. Чубукова И.А. Data Mining – Интернет-университет информационных технологий. ИНТУИТ.ру. М.: БИНОМ, 2008. 384 с. 3. Метод k-ближайших соседей – BaseGroup Labs. URL: http://www.basegroup.ru/glossary/definitions/nearest_neighbor/ (дата обращения: 02.06.2010). |
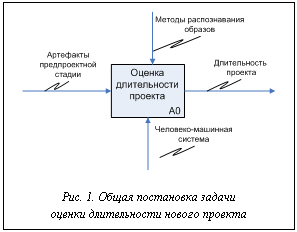 Опишем формализованную постановку задачи оценки длительности новых проектов. Требуется на основе данных, имеющихся в распоряжении на предпроектных стадиях, получить оценку длительности нового проекта, используя современные методы распознавания образов (рис. 1).
Опишем формализованную постановку задачи оценки длительности новых проектов. Требуется на основе данных, имеющихся в распоряжении на предпроектных стадиях, получить оценку длительности нового проекта, используя современные методы распознавания образов (рис. 1).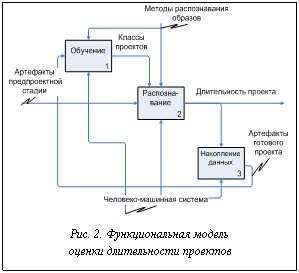 В процессе обучения первоначальная выборка Р разбивается на однородные подмножества (классы) так, чтобы каждый класс состоял из объектов, близких по той или иной метрике. При- менительно к решаемой задаче классом будем считать совокупности проектов с близкими значениями длительности. Для перехода от непрерывной переменной, каковой является длительность, к дискретной, разобьем возможные значения длительностей на интервалы. Тогда каждому классу будет соответствовать метка, являющаяся средней длительностью проектов в полученных интер- валах.
В процессе обучения первоначальная выборка Р разбивается на однородные подмножества (классы) так, чтобы каждый класс состоял из объектов, близких по той или иной метрике. При- менительно к решаемой задаче классом будем считать совокупности проектов с близкими значениями длительности. Для перехода от непрерывной переменной, каковой является длительность, к дискретной, разобьем возможные значения длительностей на интервалы. Тогда каждому классу будет соответствовать метка, являющаяся средней длительностью проектов в полученных интер- валах. (1)
(1)
 ):
): . (3)
. (3)

| Permanent link: http://swsys.ru/index.php?id=2816&lang=en&page=article |
Print version Full issue in PDF (5.05Mb) Download the cover in PDF (1.39Мб) |
| The article was published in issue no. № 3, 2011 |
Perhaps, you might be interested in the following articles of similar topics:
- Оценка рисков с использованием СППР в условиях неопределенности
- Численные методы определения пространственного положения летательного аппарата на основе 2d-оптических изображений
- Модель анализа и прогнозирования технологических параметров для процесса электронно-лучевой сварки
- Аппаратно-программный комплекс диагностики состояния ионосферы по характеристикам сигналов радиопередатчиков диапазона очень низких частот
- Программное обеспечение для сбора, обработки и передачи данных о техническом состоянии поверхности коллектора электродвигателя
Back to the list of articles