Journal influence
Bookmark
Next issue
Simulation model for evaluating efficiency of multiprocessing for a set of parallel algorithmic structure
The article was published in issue no. № 2, 2012Abstract:The effectiveness of parallel processing depends on the type of algorithm parallelization and hardware architecture. It is important to estimate the projected effectiveness of problem parallelization for a particular hardware platform at the earliest stage of parallel software development. For this purpose, a simulation model of the future performance of hardware-software system are encouraged to develop for a set of parallel algorithmic structure – parallel algorithm.
Аннотация:
| Authors: (gertsen@jinr.ru) - , Russia, (evchepin@gmail.com) - , Ph.D | |
| Ключевое слово: |
|
| Page views: 8241 |
Print version Full issue in PDF (5.19Mb) Download the cover in PDF (1.31Мб) |
При разработке параллельного ПО одним из наиболее важных является начальный этап предсказания и оценки эффективности планируемой программно-аппаратной связки. Точный метод предсказания дает возможность проектировщику оценить производительность параллельного алгоритма до реализации, исследовать эффективность при выборе альтернативного алгоритма или изменении параметров аппаратной части, например, количества вычислительных узлов или пропускной способности сети, поможет в поиске точек, критичных для производительности, а также в определении подходящей для выбранного параллельного алгоритма аппаратной платформы. Наиболее распространенным подходом при проектировании параллельных платформ является использование экспертных мнений: специалисты в области вычислительных средств на основании имеющегося опыта осуществляют проектирование системы, обеспечивающей решение конкретной задачи или класса задач. Этот подход, безусловно, позволяет в некоторой степени оптимизировать структуру проектируемых систем, однако решения носят субъективный характер, поэтому для сложных распределенных систем полученные оценки и решения могут значительно отличаться от оптимальных показателей. При проектировании и оптимизации вычислительных систем зачастую используют моделирование, поэтому в данной статье предлагается разработанная имитационная модель (аналитическая модель представлена в [1]) параллельной обра- ботки в соответствии с используемыми параллельными алгоритмическими структурами. Модель предназначена для оценки эффективности распараллеливания параллельными алгоритмами на кластерной архитектуре, узлы которой могут содержать несколько процессоров и иметь многоядерную архитектуру. Исходными данными для модели являются схема планируемой аппаратной платформы, параллельная алгоритмическая структура, соответствующая программной задаче, время последовательной обработки и объем обрабатываемых данных. После проведенного анализа в качестве основного результата разработанной модели выбраны характеристики эффективности распараллеливания обработки данных – коэффициенты ускорения и эффективности, масштабируемость. Основные типы параллельных алгоритмических структур Разработчики в большинстве случаев выбирают давно известные алгоритмы распараллеливания или их незначительные модификации. В связи с этим крайне актуальным и перспективным является использование для автоматизации готового, но расширяемого набора параллельных алгоритмических структур. В ходе анализа существующих алгоритмов распараллеливания был сформирован следующий набор параллельных алгоритмических структур для моделирования [2]. 1. Точечный алгоритм реализует операцию над однородным множеством величин. Функция, применяемая к элементу множества, не зависит от остальных элементов. Неперекрывающиеся сегменты данных в этом случае распределяются по процессорам и независимо обрабатываются. 2. Локальный алгоритм (функция, применяемая к элементу множества, зависит от нескольких соседних элементов) аналогичен точечному алгоритму с тем отличием, что множество данных разбивается на перекрывающиеся фрагменты [3]. 3. Редукция использует ассоциативную операцию ко всем элементам множества, сводя его к одному элементу. Алгоритм параллельной редукции заключается в распределении по процессорам неперекрывающихся сегментов данных, независимом выполнении редукции до одного элемента и в сборке результатов для редукции на управляющем процессе (потоке). 4. Парадигма разделяй-и-властвуй осуществляет рекурсивную декомпозицию задачи на две или более подзадач того же типа, но меньшего размера с последующим комбинированием частичных результатов в конечный результат. В силу рекурсивной декомпозиции задачи распараллеливание в большинстве случаев сводится к параллельному выполнению рекурсий на разных процессорах, поэтому парадигму разделяй-и-властвуй зачастую отождествляют с параллельной рекурсивной обработкой. К этому классу можно отнести и параллельный алгоритм волновой схемы. 5. В алгоритме параллельной конвейеризации каждая ступень конвейера создается на отдельном процессоре, который производит обработку данных, полученных с предыдущей ступени конвейера. Предложенный набор содержит подходы распараллеливания как по данным, так и по задачам. Очевидно, что список не является полным, в будущем планируется его расширение новыми элементами. Стоит отметить, что, например, в области обработки изображений и сигналов он охватывает более 80 % операций. Имитационная модель предсказания производительности При прогнозировании производительности привлекательным выглядит подход, предполагающий использование имитационной модели исследуемой параллельной системы для сравнения нескольких вариантов, предложенных экспертами, или приближенных вариантов, полученных с помощью аналитических моделей. Сложность состава и алгоритмов работы реальных параллельных систем усложняет разработку их имитационных моделей и определяет целесообразность использования специализированных программных систем, ориентированных на моделирование вычислительных сетей и компонент. Такие программные системы генерируют модель сети на основе исходных данных о ее топологии и об используемых протоколах, о типах оборудования и приложений. В результате анализа для имитационного моделирования параллельного программно-аппаратного комплекса была выбрана система сетевого моделирования OMNeT++ с пакетом INET Framework. Пакет имеет готовые модели большинства стандартных сетевых протоколов, модели приложений, генераторы трафиков и различные аппаратные средства. Среда распространяется с открытым исходным кодом, что позволило доработать существующие модели. Построение имитационной модели параллельной обработки основано на том, что аппаратная схема сводится к набору вычислительных узлов, выполняющих параллельную обработку данных, хранилища данных и коммутативной среды, связывающей вычислительные узлы между собой и с хранилищем данных. Имитационная модель программно-аппаратного комплекса обработки данных формируется из набора моделей аппаратных компонент многопроцессорной системы и их технических характеристик – вычислительного узла, коммуникационной среды, коммуникационных устройств, хранилища данных, – а также моделей передачи данных по сети и обработки на вычислительных узлах. Компонентам заданной аппаратной схемы сопоставляются модели соответствующих устройств. 1. Модель вычислительного узла (модуль ComputeNode) строится на основе существующей модели стандартного узла StandartHost. Стандартный узел состоит из следующих модулей: ppp – реализует канальный уровень; eth – сетевой адаптер Ethernet; networkLayer – отвечает за сетевой уровень (IP протоколы и др.); pingApp – отвечает за приложения, связанные с протоколом ICMP; tcp, udp – обслуживают протокол TCP и UDP; tсpApp[], udpApp[] – приложения TCP, UDP; notificationBoard – регистрирует события на узле; routingTable – модуль для хранения таблицы маршрутизации; interfaceTable – таблица интерфейсов. В начале моделирования модули обмениваются конфигурационными сообщениями для выбора скорости и режима передачи. В модели стандартного узла отсутствует имитация аппаратных ресурсов при обработке данных на вычислительных узлах, поэтому модуль StandartHost был дополнен модулем аппаратных ресурсов вычислительного узла Resource, моделирующим занятие процессорного времени в узле обработки. За основу составного модуля Resource взяты модули для моделирования систем массового обслуживания: пассивная очередь; обслуживающее устройство, в которое могут поступать сообщения от нескольких очередей; класс, пересылающий сообщения соответствующим модулям в зависимости от типа сообщения; модуль, уничтожающий все входящие сообщения и класс сообщения с характерными параметрами. Время обслуживания данных вычисляется по формуле serviceTime=ByteLength*K+Const, где serviceTime – время обслуживания, ByteLength – длина сообщения, K – коэффициент. Так как модули приложения оперируют своим классом сообщения, в них были добавлены недостающие поля. 2. Модель хранилища данных использует модель вычислительного узла ComputeNode, учитывающую соответствующие параметры носителей информации. 3. Моделям сетевого концентратора и коммутатора сопоставляется модуль EtherSwitch, управляющий соответствием между портами и адресами MAC и передающий кадры EtherFrame соответствующим портам. Обе реализации имеют фиксированную задержку обработки кадров и конечную память. 4. Модель маршрутизатора реализована модулем Router, состоящим из тех же модулей, что и стандартный узел, за исключением модулей, лежащих выше сетевого уровня. 5. Модель сетевого соединения полностью определяется существующим модулем-классом Channel. 6. Для модели многопроцессорной обработки данных в соответствии с заданной параллельной алгоритмической структурой предусмотрена модель приложения для протокола TCP, использующая базовые классы-модули TCPBasicClientApp и TCPGenericSrvApp. В соответствии с выбранной параллельной алгоритмической структурой для обработки данных формируются модели приложений вычислительных узлов с определенными характеристиками и классами сообщений, которые передаются в ходе моделирования по сети многопроцессорной системы. При добавлении новой параллельной алгоритмической структуры необходимо определить характерные для нее свойства модели приложений. Разработанная имитационная модель была реализована в проблемно-ориентированной среде визуального программирования для разработки ПО параллельной обработки данных. Основные положения этого комплекса визуального программирования сформулированы в [2]. В данной среде исходная аппаратная схема планируемого программного-аппаратного комплекса представляется в виде взаимосвязи условных графических обозначений аппаратных компонент и их характеристик, а программная схема – в виде взаимосвязи функциональных блоков, которым сопоставлены соответствующие параллельные алгоритмические структуры. Для моделирования программно-аппаратного комплекса параллельной обработки данных автоматически генерируется модель как связанный набор моделей компонент, полностью соответствующих заданной аппаратной и функциональной схеме, и сохраняется в файл с расширением ned. В соответствии с выбранным параллельным алгоритмом обработки данных формируются модели приложений вычислительных узлов с характеристиками сообщений, которые будут передаваться по сети многопроцессорной системы. Для сгенерированных файлов OMNET++ (в том числе конфигурационного файла omnet.ini) производится имитационное моделирование с получением файла характеристики, содержащего статистические данные по работе системы. Для всех времен и размеров передаваемых данных используется вероятностная характеристика с нормальным распределением и среднеквадратичным отклонением в 3 % от заданной величины. Для усреднения полученных значений работа системы моделируется для нескольких проходов цепочки операций. В результате имитационного моделирования для оценки эффективности программно-аппа- ратной связки используются прежде всего следующие полученные характеристики: время параллельной обработки данных, загрузка вычислительных узлов многопроцессорной системы, очередь в каналах передачи. По полученным данным оцениваются коэффициенты ускорения и эффективности, масштабируемость, загрузка узлов многопроцессорной системы. Если обозначить P количество процессоров планируемой системы, n – объем обработанных в ходе моделирования данных, T1 – исходное время последовательного решения задачи, Tp – модельное время параллельной обработки на P процессорах, то коэффициент ускорения будет рассчитываться по формуле Масштабируемость выбранной системы оценивается по зависимости получаемого ускорения для программно-аппаратного комплекса от числа процессоров/ядер аппаратной платформы путем добавления в схему моделирования дополнительных вычислительных средств. Таким образом, результатом имитационного моделирования являются характеристики эффективности параллельного исполнения на планируемой аппаратной платформе ПО в соответствии с выбранными параллельными алгоритмическими структурами, после которого в случае неудовлетворительных характеристик проектировщиками принимается решение о корректировке параметров аппаратной платформы или алгоритмической части и о проведении нового моделирования. Подводя итоги, отметим, что разработанная имитационная модель нашла успешное применение и показала свою адекватность в ряде проектов по обработке изображений и сигналов. Например, в [4] приводится сравнение модельных и практических значений ускорения для КИХ-фильтра цифрового сигнала, соответствующего параллельной алгоритмической структуре – локальному алгоритму. КИХ-фильтр был реализован с помощью секционированной свертки, вычисленной через быстрое преобразование Фурье. В проекте для концерна «Системпром» (г. Москва) разработанное имитационное моделирование использовалось для прогнозирования эффективности параллельного выполнения алгоритма распознавания образов изображений, использующего метод SIFT (поиск локальных дескрипторов, инвариантных масштабированию) на кластерной архитектуре. Максимальное отклонение результатов имитационной модели в проектах составило 7 %. Оценка будущей эффективности программно-аппаратных комплексов позволила предсказать ускорение и масштабируемость планируемых систем, а также определить узкие места аппаратной платформы, сделать выбор оборудования до реализации, снизив тем самым риск нецелесообразных экономических затрат. Планируется разработать более подробную модель вычислительного узла, учитывающую в том числе и возможную обработку на графических процессорах, а также расширить имитационную модель новыми параллельными алгоритмическими структурами. Литература 1. Герценбергер К.В., Чепин Е.В. Аналитическая модель оценки производительности многопроцессорной обработки данных для набора параллельных алгоритмических структур. Бизнес-информатика // Междисциплинар. науч.-практич. журн. 2011. № 4 (18). С. 24–30. 2. Gertsenberger K.V., Chepin E.V. Using a CASE-oriented approach for parallel software development / In Proc. of the International Workshop on Computer Science and information technologies (CSIT'2008). Bashkortostan. Ufa State Aviation Technical University. 2008. Vol. 1, pp. 63–68. 3. Герценбергер К.В. Методы параллельной обработки изображений и сигналов в зависимости от локальности вычислений // Исследование, разработка и применение высоких технологий в промышленности: сб. тр. 7-й Междунар. науч.-практич. конф. Т. 2. СПб: Изд-во Политех. ун-та, 2009. С. 49–50. 4. Gertsenberger K.V., Chepin E.V. Implementation parallel processing of digital signals on cluster system / In Proc. of the International Workshop on Computer Science and information technologies (CSIT'2007). Bashkortostan. Ufa State Aviation Technical University. 2007. Vol. 1, pp. 152–155. |
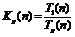 , а коэффициент эффективности по формуле
, а коэффициент эффективности по формуле 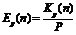 .
.| Permanent link: http://swsys.ru/index.php?id=3126&lang=en&page=article |
Print version Full issue in PDF (5.19Mb) Download the cover in PDF (1.31Мб) |
| The article was published in issue no. № 2, 2012 |
Perhaps, you might be interested in the following articles of similar topics:
- Программные средства автоматизации приборостроительного производства изделий радиоэлектронной аппаратуры
- Оптимизация обработки информационных запросов в СУБД
- Агентно-ориентированная технология проектирования
- Информационная система управления деятельностью персонала
- Психосемантический подход к оценкам сложности автоматизированных информационных систем
Back to the list of articles