Journal influence
Bookmark
Next issue
Architecture of advanced high performance microchips
The article was published in issue no. № 3, 2012 [ pp. 63-68 ]Abstract:This article reviews new approaches related to high reliable high performance processors provided for super computers of exaflops range. The article shows basic problems that are encountered in the process of improving computing systems performance, it describes trends in the area of microprocessor performance increase. It is difficult to provide synchronization when the chip size is larger than several millimeters. High consumption rate of synchronization pulse tree in modern high performance 45 nm chips results into use of self- clocked logic together with clocked logic. This work provides pattern of hybrid standard core-based processor, which are implemented based on clocked logic, and coprocessors implemented in the form of thread machine with self- clocked logic.
Аннотация:Рассматриваются новые подходы к созданию высоконадежных и высокопроизводительных микропроцессоров для суперЭВМ эксафлопсного диапазона. Приведены основные проблемы, касающиеся производительности вычис-лительных систем, описаны направления повышения производительности микропроцессоров. Сложность синхрони-зации при размерах кристалла, больших нескольких единиц миллиметра, и высокое потребление питания дерева синхроимпульсов в современных высокопроизводительных микропроцессорах при технологических нормах 45 нм вызывают необходимость использования наряду с синхронной логикой самосинхронной логики. Предлагается схема гибридного процессора, содержащего стандартные вычислительные ядра, реализованные с применением синхронной логики, и сопроцессоры, используемые как потоковая машина с самосинхронной логикой.
| Authors: Bobkov S.G. (bobkov@cs.niisi.ras.ru) - Federal State Institution "Scientific Research Institute for System Analysis of the Russian Academy of Sciences" (SRISA RAS) (Professor, Deputy Director), Moscow, Russia | |
| Keywords: self-timed, data flow, computer architecture, microprocessors architecture, supercomputer technologies, supercomputer |
|
| Page views: 10227 |
Print version Full issue in PDF (7.64Mb) Download the cover in PDF (1.33Мб) |
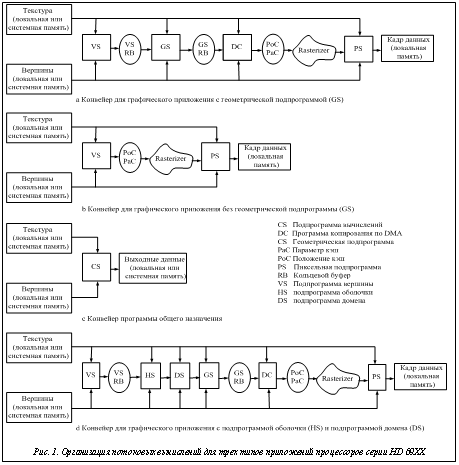
Одной из основных характеристик вычислительных систем является производительность. Для создания высокопроизводительных систем требуются принятие комплекса мер по увеличению производительности с одновременным учетом таких факторов, как ограничения по потребляемой мощности, стоимости, размеру кристалла, надежности функционирования, а также наличие качественных компиляторов и параллельное программирование. Основным фактором, способствующим повышению производительности, является создание высокопроизводительного микропроцессора [1]. Производительность микропроцессора определяется частотой его функционирования, возможностью одновременного выполнения нескольких инструкций, обработки нескольких потоков данных, наличием нескольких ядер, архитектурными особенностями (например, возможностью аппаратного выполнения сложных функций, таких как sinx, бабочка и пр.), наличием большого объема встроенной кэш-памяти различного уровня. Следующим фактором является организация подсистемы памяти в целом. Особенно остро стоит проблема повышения скорости обмена данными с ОЗУ для задач с большими объемами данных, не позволяющих эффективно использовать кэш-память. В таких случаях ускорение возможно прежде всего за счет введения режимов прямого доступа к памяти (DMA), предвыборок, увеличения частоты и ширины памяти. Для систем реального времени и многопроцессорных систем важны аппаратное выполнение функций синхронизации процессов, организация прерываний и контроля функционирования вычислительной системы и ее отдельных узлов. Большие потери производительности (до нескольких раз для некоторых задач) вычислительных систем происходят при обмене между отдельными микросхемами в силу ограничений по скорости передачи данных по плате. Поэтому интеграция функций на одном кристалле и создание систем на кристалле приводят не только к повышению надежности системы и сокращению ее габаритов в силу уменьшения числа компонент, но и к повышению производительности системы в целом. При создании микросборок (систем в корпусе) возможны оптимизация выводов кристаллов с учетом их характеристик и числа в микросборке и соответствующее уменьшение емкости контактов. Это приводит к снижению потребления питания и повышению скорости обмена данными. Уменьшение числа мостовых схем обусловливает сокращение задержки на передаваемые данные. Создание комплектов СБИС под вычислительные системы позволяет оптимизировать потребляемую мощность, габариты и повысить производительность системы. Введение сопроцессоров под выделенные задачи позволяет в несколько раз поднять производительность систем на них. Например, в современных коммуникационных микропроцессорах имеются десятки встроенных сопроцессоров, аппаратно выполняющих функции сжатия данных, криптографии, контроля, TCP и пр. Следующим шагом повышения производительности является создание многопроцессорных модулей и систем. Эффективность многопроцессорной системы во многом зависит от решаемых задач (возможности параллельного выполнения отдельных частей программы) и ПО параллельного выполнения задач. Повышение производительности современных микропроцессоров обеспечивается в основном за счет увеличения тактовой частоты, создания многоядерных и многотредовых процессоров, введения специализированных вычислительных узлов (сопроцессоров). Больших успехов в повышении производительности графических процессоров достигли компании AMD и NVIDIA. Повышение производительности обеспечивается созданием в микросхеме мощных параллельных вычислителей с плавающей запятой, функционирующих по принципу потоковых машин. Эти процессоры уже активно используются в качестве вычислительных узлов суперЭВМ. Однако они практически подошли к пределу своей производительности с точки зрения архитектурных и схемотехнических решений. То есть повышение производительности подобных процессоров осуществляется прежде всего за счет перехода на новые технологические нормы и соответствующего увеличения количества вычислительных блоков и их частоты. Используя стандартные архитектурные и схемотехнические решения, невозможно добиться кардинального улучшения характеристик микропроцессоров и вычислительных систем в целом. Рассмотрим основные факторы, препятствующие повышению производительности микропроцессоров. · Невозможность увеличения частоты более 3–5 ГГц из-за существенного повышения потребления питания и, следовательно, тепловыделения, которое нельзя отвести от кристаллов стандартными средствами. Кроме того, повышение частоты достигается в основном за счет увеличения количества ступеней в конвейере микропроцессора, что приводит к большим потерям времени в случае перезагрузки конвейера при конфликте по управлению и при переключении на новую задачу. · Разброс параметров транзисторов и существенное возрастание токов утечки при использовании топологических норм 45 нм и ниже. В результате для достижения предельных параметров необходимо оптимизировать каждый проект под конкретный технологический маршрут. Диапазон вариации электрических параметров внутри одного и того же кристалла составляет 1–3 мм. Если размер модуля СБИС не превышает 2 мм, внутри модуля сохраняются корреляции статических параметров элементов и возможна схемотехническая компенсация технологических вариаций. · Сложность синхронизации функционирования микропроцессора в кристалле, размер ко- торого больше нескольких единиц миллиметра. Потребление питания дерева синхроимпульсов в современных высокопроизводительных микропроцессорах достигает 30 %. · Значительные перекрестные наводки и импульсные помехи, возникающие при технологических нормах 45 нм и ниже, что приводит к снижению плотности упаковки на 10–20 %. · Необходимость введения средств, повышающих надежность микросхемы, при увеличении числа транзисторов до нескольких сот миллионов и уходе на глубокий субмикрон. В противном случае микросхема будет сбиваться с вероятностью, которая не позволит использовать ее в высокопроизводительных многопроцессорных ЭВМ и компьютерах, где требуется бессбойная работа (серверы высокой доступности, промышленные компьютеры и т.п.). Итак, задача разработки архитектуры и схемотехнических решений, позволяющих существенно снизить вышеперечисленные эффекты, является одной из центральных для повышения производительности микропроцессоров. Основными направлениями работ в этой области являются создание многоядерных сетей на кристалле, многотредовых ядер, потоковых машин, а также специализация вычислительных устройств и создание неоднородных вычислительных узлов. Архитектура микросхем «сеть на кристалле» ориентирована на использование физически и программно совместимых модулей. Каждый модуль включает микропроцессор и средства коммутации. Модули образуют вычислительную сеть с множествами каналов связи. Такая архитектура позволяет решать задачи энергосбережения и синхронизации (при большом размере кристалла из-за разброса параметров невозможно синхронизовать все устройства стандартным способом). Один из главных способов уменьшения потребления питания – оптимизация информационных потоков, так как энергопотребление микросхемы в активном режиме определяется частотой переключения элементов, нагруженных на длинные линии. Распределенная память под каждый вычислительный узел, а не глобальная, как это делается в микропроцессорах с технологическими нормами выше 100 мкм, позволяет существенно снизить энергопотребление. Архитектура SMT (Simultaneous Multithreading) – многотредовая, или многонитевая, позволяет организовать параллельные вычисления для различных процессов. Тред – это минимальный аппаратный функциональный блок микропроцессора, поддерживаемый операционной системой и использующий общие ресурсы с другими тредами (кэш-память, регистры). Обычно это результат от разделения компьютерных программ на две или более одновременно выполняемые задачи. В потоковых процессорах вычислительная задача представляется в виде потокового графа, каждый узел которого реализуется на соответствующих вычислительных узлах. Необходимо дать однозначное соответствие каждого узла графа и вычислительного узла, а также определить порядок передачи данных между вычислительными узлами для организации потока вычислений. Для каждой посылки данных должна однозначно определяться стадия выполнения на вычислительном графе задачи. Поскольку в общем случае необходимо передать данные с выхода одного вычислительного узла потоковой машины на вход любого другого, требуется организовать систему коммутации. Как и в любой системе коммутации, в пересылаемых данных должны быть выделены поля, определяющие направления коммутации. Кроме того, следует определить набор данных, передающихся на один и тот же вычислительный узел одновременно для исключения сбоя в процессе вычислений. Вычисление операции (программы узла) активизируется при появлении операндов на всех входах узла – модели вычислений, основанной на управлении данными (data driven computation). Нет необходимости использовать счетчик команд, который обязателен в универсальных ЭВМ. Выполнение команды активизируется самими данными, что позволяет одновременно исполнять многие команды в машине. Специализация микропроцессоров предполагает аппаратное или микропрограммное выполнение функций, требуемых для выделенного класса задач, наличие дополнительных интерфейсов, оптимизации встроенной памяти, включая кэш-память, и интерфейса с внешней памятью и т.п. Как указывалось выше, наибольшие показатели производительности (несколько Тфлопс) достигаются на графических процессорах. В них заложены все основные механизмы повышения производительности: сеть на кристалле многотредовых процессоров, потоковые вычисления и специализация под выделенный круг задач. На рисунке 1 показана организация вычислений различных функций в процессорах HD 6900 компании AMD [2]. Главный процесс (хост) дает команду управляющему процессору загрузить программу и данные во внутреннюю память процессора. Управляющий процессор организует вычисления на матрице параллельных потоковых процессоров, как показано на рисунке 1. Процессоры могут выполнять вычисления над целочисленными или плавающими числами. Каждый вычислительный узел имеет свой канал памяти. Обмен памятью может осуществляться по DMA-каналу. По окончании вычислений управляющий процессор отправляет хосту аппаратно сгенерированное прерывание. Основные недостатки подобных процессоров – сложность программирования, ограниченная область применения и большое потребление энергии на кристалл. Как уже упоминалось выше, дерево синхронизаций требует порядка 30 % мощности. Это и есть резерв повышения производительности и надежности систем. Предлагается реализовать вычислительные узлы как матрицу потоковых самосинхронных процессоров (сеть на кристалле), выполняющих выделенные функции. Рассмотрим задачу горения в различных типах двигателей. Ее решение возможно на компьютерах эксафлопсного диапазона, требуемая точность – не менее 64 разрядов. Современные вычисли
Таким образом, при разбиении на относительно мелкие вычислительные узлы (функции) снижается зависимость самосинхронной логики от наличия различных паразитных элементов, перекрестных наводок и прочих воздействий, свойственных современным кристаллам с предельными технологическими нормами, что в целом повышает надежность всей схемы. Предлагаемая схема гибридного процессора, когда часть функций (управление, ввод/вывод, статистика и пр.) лежит на стандартном процессоре, а сопроцессор реализован как потоковая машина, показана на рисунке 2. На нем не отражены коммуникационные каналы и внешние интерфейсы, поскольку в данном рассмотрении это непринципиально. Для примера структурная схема процессора состоит из двух узлов, при создании микропроцессора с предельными технологическими нормами число узлов может достигать 16 и более. Вычислительный модуль организован как потоковая машина на базе самосинхронных узлов. Поскольку суммарно вычислительные модули занимают большую часть кристалла по сравнению с универсальными ядрами, а процесс вычислений во многом определяется вычислительными ядрами, надежность такого процессора приближается к надежности полностью самосинхронного процессора. Реализация потокового выполнения функций должна производиться на базе сумматоров, умножителей и делителей двойной точности. Такой подход позволит перенастраивать (перепрограммировать) эти функции в зависимости от получаемого кода инструкций. Таким образом, предложены архитектура и принципы проектирования высокопроизводительных микропроцессоров, ориентированных на выполнение выделенных задач, позволяющие в несколько раз поднять надежность микросхемы и до 30 % снизить потребляемую мощность за счет создания гибридного потокового процессора с использованием синхронной и самосинхронной схемотехники. Производительность таких процессоров должна быть несколько выше производительности рассмотренных графических процессоров благодаря исключению времени установки и сохранению сигнала по отношению к тактовому импульсу в самосинхронной схемотехнике. Литература 1. Бобков С.Г. Высокопроизводительные микропроцессорные системы. Саарбрюккен, Германия: LAMBERT Acade- mic Publishing GmbH & Co. KG, 2012. 248 с. 2. AMD Reference Guide «HD 6900 Series Instruction Set Architecture». URL: http://developer.amd.com/sdks/AMDAPPSDK/assets/AMD_HD_6900_Series_Instruction_Set_Architecture.pdf (дата обращения: 07.04.2012). 3. Varshavsky V., Kishinevsky M., Marakhovsky V. [et al.]. Self-timed Control of Concurrent Processes. Kluver Academic Publishers, 1990, 245 p. |
 тельные системы не позволяют достичь подобной производительности. Задача, помимо стандартных операций умножения, сложения и деления с плавающей запятой двойной точности, требует выполнения целого ряда сложных функций, таких, как экспонента, сложная степень, тригонометрические функции и пр. Причем эти функции наиболее массовые. Стандартный подход к вычислению таких функций – использование операций умножения, сложения и деления. Очевидно, програм- мное выполнение потребует много времени на вычисления, необходимо будет произвести десятки и сотни операций для каждой функции. Аппаратная реализация функций возможна с использованием табличных методов вычислений, однако для быстрого выполнения операций двойной точности потребуются таблицы размером в сотни килобайт, что не позволяет эффективно использовать их в современных процессорах. То есть при любом методе реализации этих функций увеличивается количество выполняемых операций. Потоковые машины позволяют наиболее естественно решать такие задачи, а самосинхронная логика даст возможность существенно снизить потребление питания и время выполнения операций. В синхронной системе все события происходят по тактовому сигналу, в самосинхронных схемах [3] операция выполняется в момент окончания переходных процессов переключений элементов схемы. При этом обеспечивается правильное функционирование таких схем независимо от задержек элементов, их составляющих. Таким образом, условия начала операции потоковых машин и окончания в самосинхронных схемах определяются по одним и тем же механизмам, во всей цепочке вычислений имеется причинно-следственная связь, которая естественным образом реализуется в сочетании самосинхронной логики и потоковых вычислений. Однако этот принцип самосинхронной логики нельзя распространить на весь кристалл в целом. В синхронной схеме частота увеличивается за счет мощного клокового дерева, то есть ресурсы микросхемы во многом расходуются на синхронность всех процессов, и в результате производительность микросхемы становится высокой. В самосинхронных схемах это невозможно сделать для многих сигналов, и на больших длинах линий передачи скорость выполнения операций будет падать, а с учетом разбросов параметров кристалла производительность самосинхронных схем будет существенно ниже синхронных для технологий 45 нм и лучше. Кроме того, проведенные исследования тестовых структур самосинхронных схем, изготовленных с нормами 180 нм, показали, что самосинхронные схемы весьма чувствительны к перекрестным наводкам. Схемы правильно отрабатывают свои функции, однако из-за перекрестных наводок быстродействие падает на десятки процентов, несмотря на то, что размер блоков составляет единицы кв. мм. Для норм 45 нм и ниже проблемы с перекрестными наводками и импульсными помехами становятся особенно критичными. Более того, для таких норм возникают проблемы разброса параметров транзисторов и высоких токов утечек. Выход представляется в ограничении размеров самосинхронных схем. То есть проект должен разбиваться на многие функционально законченные узлы с небольшой площадью на кристалле (меньше 1 мм2). Таким образом, для достижения максимальной производительности необходимо сочетание синхронных и самосинхронных подходов.
тельные системы не позволяют достичь подобной производительности. Задача, помимо стандартных операций умножения, сложения и деления с плавающей запятой двойной точности, требует выполнения целого ряда сложных функций, таких, как экспонента, сложная степень, тригонометрические функции и пр. Причем эти функции наиболее массовые. Стандартный подход к вычислению таких функций – использование операций умножения, сложения и деления. Очевидно, програм- мное выполнение потребует много времени на вычисления, необходимо будет произвести десятки и сотни операций для каждой функции. Аппаратная реализация функций возможна с использованием табличных методов вычислений, однако для быстрого выполнения операций двойной точности потребуются таблицы размером в сотни килобайт, что не позволяет эффективно использовать их в современных процессорах. То есть при любом методе реализации этих функций увеличивается количество выполняемых операций. Потоковые машины позволяют наиболее естественно решать такие задачи, а самосинхронная логика даст возможность существенно снизить потребление питания и время выполнения операций. В синхронной системе все события происходят по тактовому сигналу, в самосинхронных схемах [3] операция выполняется в момент окончания переходных процессов переключений элементов схемы. При этом обеспечивается правильное функционирование таких схем независимо от задержек элементов, их составляющих. Таким образом, условия начала операции потоковых машин и окончания в самосинхронных схемах определяются по одним и тем же механизмам, во всей цепочке вычислений имеется причинно-следственная связь, которая естественным образом реализуется в сочетании самосинхронной логики и потоковых вычислений. Однако этот принцип самосинхронной логики нельзя распространить на весь кристалл в целом. В синхронной схеме частота увеличивается за счет мощного клокового дерева, то есть ресурсы микросхемы во многом расходуются на синхронность всех процессов, и в результате производительность микросхемы становится высокой. В самосинхронных схемах это невозможно сделать для многих сигналов, и на больших длинах линий передачи скорость выполнения операций будет падать, а с учетом разбросов параметров кристалла производительность самосинхронных схем будет существенно ниже синхронных для технологий 45 нм и лучше. Кроме того, проведенные исследования тестовых структур самосинхронных схем, изготовленных с нормами 180 нм, показали, что самосинхронные схемы весьма чувствительны к перекрестным наводкам. Схемы правильно отрабатывают свои функции, однако из-за перекрестных наводок быстродействие падает на десятки процентов, несмотря на то, что размер блоков составляет единицы кв. мм. Для норм 45 нм и ниже проблемы с перекрестными наводками и импульсными помехами становятся особенно критичными. Более того, для таких норм возникают проблемы разброса параметров транзисторов и высоких токов утечек. Выход представляется в ограничении размеров самосинхронных схем. То есть проект должен разбиваться на многие функционально законченные узлы с небольшой площадью на кристалле (меньше 1 мм2). Таким образом, для достижения максимальной производительности необходимо сочетание синхронных и самосинхронных подходов.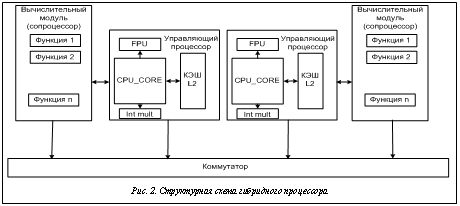 Другим важным аспектом самосинхронных схем является их высокая надежность в силу 100 %-ной самопроверяемости. При переходе на предельные технологические нормы сбои суперЭВМ становятся постоянными и при отсутствии должных мер контроля и исправления ошибок сложные задачи просто не будут иметь окончания. Самосинхронная логика позволяет существенно упростить решение этой проблемы.
Другим важным аспектом самосинхронных схем является их высокая надежность в силу 100 %-ной самопроверяемости. При переходе на предельные технологические нормы сбои суперЭВМ становятся постоянными и при отсутствии должных мер контроля и исправления ошибок сложные задачи просто не будут иметь окончания. Самосинхронная логика позволяет существенно упростить решение этой проблемы.| Permanent link: http://swsys.ru/index.php?id=3216&lang=en&page=article |
Print version Full issue in PDF (7.64Mb) Download the cover in PDF (1.33Мб) |
| The article was published in issue no. № 3, 2012 [ pp. 63-68 ] |
Perhaps, you might be interested in the following articles of similar topics: