Journal influence
Bookmark
Next issue
Application of case-based reasoning methods in information search systems
The article was published in issue no. № 3, 2013 [ pp. 114-119 ]Abstract:The paper discusses topical issues of modern information searchsystem development. These systems are the main search tool that can be used to search in the Internet. In addition, there is a stable trend to intellectualization of infor-mation search systems and search personalization. These searchengines are oriented to eliminate major disadvantages ofthe traditional context keyword search. We propose to use the artificial intelligence methods and, in particular, multi-agent ap-proach, methods and tools of plausible case-based reasoning for personalization and intellectualization of searching. A sim-plified structure of the Internet search engine and the main tasks of such engines are considered. We propose an architecture based on intelligent agents, providing the opportunityto Internet resources case-based search. The components of the pro-posed information search system architecture and main modules software implementation in MS Visual Studio 2010 using FIPA (Foundation for Intelligent Physical Agents) standard and ASP.NET technology under MS Windows operating system are considered in detail.
Аннотация:Рассматриваются актуальные вопросы построения современных информационных поисковых систем. Эти системы являются основным поисковым инструментом, который может применяться при поиске во всемирной сети Интернет. Кроме того, наблюдается устойчивая тенденциях интеллектуализации информационных поисковых систем и персонализации поиска. Указанные механизмы поиска направлены на устранение основных недостатков традиционного контекстного поиска по ключевым словам. Предлагается использовать методы искусственного интеллекта, в частности, мультиагентный подход, методы и средства правдоподобных рассуждений на основе прецедентов (CBR – Case-Based Reasoning), для обеспечения персонализации и интеллектуализации поиска. Рассмотрены упрощенная структура поисковой машины Интернета и основные задачи таких машин. Предложена архитектура информационной поисковой системы на базе интеллектуальных агентов, обеспечивающая возможность поиска ресурсов Интернета на основе прецедентов (накопленного системой опыта). Подробно рассмотрены компоненты предложенной архитектуры информационной поисковой системы и программная реализация основных модулей системы в MS Visual Studio 2010 с использованием стандарта FIPA (Foundation for Intelligent Physical Agents) и технологии ASP.NET под операционную систему MS Windows.
| Authors: Zo Lin Khaing (zo.lin2010@mail.ru) - National Research University “MPEI”, Moscow, Russia, Varshavskiy P.R. (VarshavskyPR@mpei.ru) - National Research University “MPEI”, Moscow, Russia, Ph.D, Ar Kar Myo (arkar2011@gmail.com) - National Research University “MPEI”, Moscow, Russia | |
| Keywords: multi-agent systems, Internet search engines, case-based reasoning, information retrieval system |
|
| Page views: 11454 |
Print version Full issue in PDF (13.63Mb) Download the cover in PDF (1.39Мб) |
Сегодня информационные поисковые системы (ИПС) – основной поисковый инструмент в сети Интернет [1]. Однако поиск в традиционных ИПС (поисковых машинах Интернета) неэффективен, так как по запросу пользователя зачастую выдается большое количество нерелевантных документов. Поэтому, когда речь идет о качестве поиска информации, понятие релевантности является определяющим. В настоящее время наблюдается устойчивая тенденция к интеллектуализации ИПС и персонализации поиска [2]. Именно к этому стремятся крупные компании на рынке поисковых систем Интернета (Google, Yandex и др.), активно внедряющие различные сервисы и инструменты поиска. Механизмы персонализации и интеллектуализации направлены на устранение основных недостатков традиционного контекстного поиска по ключевым словам. На пути создания персонализированных интеллектуальных ИПС много нерешенных проблем, но разработка подобных систем весьма актуальна, так как они имеют ряд преимуществ, а главное – приближают к решению проблемы выбора релевантной информации. Необходимо подчеркнуть, что для повышения эффективности ИПС интеллектуальные и персонализированные механизмы поиска должны применяться в комплексе с традиционными поисковыми средствами [3]. В данной работе для обеспечения персонализации и интеллектуализации поиска предлагается использовать методы искусственного интеллекта, в частности, мультиагентный подход [4] и методы правдоподобных рассуждений на основе прецедентов (CBR – Case-Based Reasoning) [5]. Поисковые машины Интернета Для поиска информации в Интернете используются специальные поисковые системы (поисковые машины). В России наиболее популярными являются Google, Яндекс, Поиск@Mail.ru и др. Поисковая машина Интернета предназначена для поиска информации в сети Интернет (по web-ресурсам и базам HTML-документов) и вывода результатов в соответствии с запросами пользователей. Ответ поисковой машины Интернета должен быть актуальным и информативным. Упрощенная структура такой машины приведена на рисунке 1 [3]. Рассмотрим основные з Для сбора информации (индексации сайтов) поисковые системы формируют свой индекс, используя программных агентов (роботов, пауков и др.), перемещающихся по сети в соответствии с переданными ИПС URL-адресами web-ресурсов и собирающих необходимую информацию. Работа программных агентов строится на алгоритмах, созданных в результате совместной работы лингвистов, программистов и аналитиков. Упрощенная структура индекса ИПС, которая содержит информацию о проиндексированных сайтах, ключевых словах, копиях HTML-страниц, документальных и пользовательских запросах, представлена на рисунке 2. Поскольку объем информации в Интернете колоссален, сбор и хранение данных требуют огромных мощностей – высокопроизводительных серверов с большим объемом памяти и мощными процессорами.
На этом подготовительный этап работы ИПС заканчивается и начинается выполнение основной задачи – поиск по индексу ИПС с учетом заложенных алгоритмов определения релевантности и дальнейшего ранжирования результатов и вывод ответов на запросы пользователей в удобном виде (то есть показываются сниппеты (выдержки из текста), в которых жирным шрифтом выделяются слова из запроса). Кроме того, поисковые машины анализируют реакцию пользователя на информацию, выданную ИПС. У поисковой машины Google есть панель-бар (надстройка к браузеру), с помощью которой пользователь может высказать свое отношение к тому сайту, на который его перенаправила поисковая машина. Многие российские поисковые машины учитывают статистику переходов пользователя по результатам поиска, оценивая популярность соответствующих интернет-ресурсов.
Под персонализацией поиска понимается предоставление пользователю индивидуальных, персонализированных результатов в зависимости от его информационных потребностей, приоритетов, интересов, географического и социального положения, возраста и других особенностей [2]. Существуют три большие группы методов оценки предпочтений аудитории: – коллаборативная фильтрация, позволяющая получать автоматические прогнозы относительно интересов пользователя по собранной информации о предпочтениях множества пользователей; – эвристическое моделирование, предпо- лагающее создание математической модели рассматриваемой сложной системы на основе гипотезы о ее структуре и функциях; в отличие от коллаборативной фильтрации применение эвристического моделирования оправдано на небольших выборках объектов; – поведенческий таргетинг, обеспечивающий мониторинг за действиями и предпочтениями пользователя, как правило, без его участия, что позволяет определить интерес потребителя к той или иной информации или услуге; по итогам анализа формируется профиль пользователя, на основе которого ему выдается персонализированная информация, соответствующая его информационным потребностям. В работе предлагается осуществлять накопление информации о запросах и предпочтениях пользователя с помощью методов на основе прецедентов (CBR-методов) [5]. Собранная программными агентами ИПС информация будет помещаться в хранилище – библиотеку прецедентов (БП) и подвергаться математической и статистической обработке. Подход на основе CBR-методов позволяет решить новую, неизвестную задачу, используя или адаптируя решение уже известной задачи. CBR-методы активно применяются в различных областях, таких как медицинская диагностика, юриспруденция, технические системы, системы экспертной диагностики и др. Данный подход составляет основу машинного обучения и предоставляет широкие возможности для формирования корпоративной памяти, а также накопления разнородной информации (как структурированных, так и слабоструктурированных данных, включая мультимедиа данные). Как правило, CBR-методы реализуют четыре основных этапа, образующих так называемый CBR-цикл, представленный на рисунке 3 [5]: – извлечение наиболее соответствующего (подобного) прецедента (или прецедентов) для сложившейся ситуации из БП; – повторное использование извлеченного прецедента для попытки решить текущую проблему; – пересмотр и адаптация в случае необходимости полученного решения в соответствии с текущей проблемой; – сохранение вновь принятого решения как части нового прецедента. Преимущества CBR-методов: – возможность напрямую использовать опыт, накопленный системой, без интенсивного привлечения эксперта в той или иной предметной области; – возможность сокращения поиска решения поставленной задачи за счет использования уже имеющегося решения для подобной задачи; – возможность исключения повторного получения ошибочного решения; – отсутствие необходимости полного и углубленного рассмотрения знаний о конкретной предметной области (вместо детального построения модели предметной области можно ограничиться учетом только существенных особенностей предметной области); – возможность применения эвристик, повышающих эффективность решения задач. Архитектура ИПС на основе прецедентов Для реализации ИПС на основе прецедентов предлагается использовать мультиагентную среду, основными компонентами которой являются взаимодействующие между собой мобильные (интеллектуальные) агенты [4]. Агенты могут как функционировать на серверной стороне ИПС, выполняя традиционные функции поисковой машины Интернета, так и являться клиентским прикладным ПО, которое может встраиваться или дополнять браузер пользователя. Такие агенты позволяют реализовать интеллектуальный поиск и обеспечивают многосторонний мониторинг предпочтений пользователя.
– пользовательский интерфейс для организации взаимодействия пользователей с ИПС; – блок управления (Management Block), который содержит инструменты, предназначенные для координации и поддержки работы основных компонентов ИПС; – блок индексирования (Indexing Block), выполняющий сбор и обработку информации (индексацию интернет-ресурсов) и формирование индекса ИПС; – блок CBR (CBR Block), содержащий компоненты, связанные непосредственно с реализацией методов поиска решения на основе прецедентов; – программу поиска, применяемую не зарегистрированными в системе пользователями для поиска информации в ИПС; – индекс – базу проиндексированных документов ИПС. Пользовательский интерфейс предоставляет возможность регистрации в ИПС новых пользователей и выполнения авторизации в системе для зарегистрированных пользователей. Диалог с пользователем осуществляется через web-браузер с помощью web-интерфейса, реализующего набор шаблонов запросов к системе (запросы на индексирование документов в ИПС и поисковые запросы к ИПС). Для каждого зарегистрированного пользователя доступна возможность сохранения и учета их личных предпочтений (прецедентов) при выполнении поиска в ИПС (персонализированный поиск). Для незарегистрированных пользователей ИПС предусмотрена возможность традиционного поиска по ключевым словам с использованием программы поиска ИПС. С помощью пользовательского интерфейса формируются список URI для индексирования интернет-ресурсов и список поисковых запросов пользователей к ИПС, а также выдаются результаты поиска пользователям. В состав блока управления входят web-служба учета агентов и агент управления с реестром программных модулей. Web-служба учета агентов объединяет в себе функции системы управления агентами (Agent Management System) и каталога внешних интерфейсов агентов (Directory Facilitator), описываемых в стандарте FIPA (Foundation for Intelligent Physical Agents) по базовой архитектуре мультиагентных систем [7]. Данная web-служба публикует информацию об адресах и именах всех агентов, зарегистрированных в системе, а также о доступных сервисах, предоставляемых данными агентами. Агент управления отвечает за создание, удаление и поддержание функционирования рабочих групп поисковых роботов в блоке индексирования и CBR-агентов при выполнении персонализированного поиска. В соответствии со списком запросов на индексирование (список URI) агент управления создает новых поисковых агентов (роботов) или активизирует работу уже зарегистрированных в системе и имеющих свободные ресурсы роботов, передавая им соответствующие URI для индексирования интернет-ресурсов. Робот – это программа, предназначенная для сбора и обработки данных в Интернете с целью занесения их в индекс ИПС. Робот заходит на web-страницу, анализирует ее содержимое, сохраняет его в базе ИПС и отправляется по ссылкам на следующие web-страницы. Как правило, роботы сохраняют копии html-страниц, заголовки информационных ресурсов, аннотации, обнаруженные ключевые слова и выявленные META-теги, а также добавляют в список URI ИПС новые обнаруженные ссылки на другие web-ресурсы. Порядок обхода страниц, частота визитов, защита от зацикливания, а также критерии выделения значимой информации определяются поисковыми алгоритмами [1, 3]. На основе списка поисковых запросов пользователей агент управления создает новых CBR-агентов, загружая в них соответствующие идентификаторам пользователей БП. Если на момент запроса в системе уже есть зарегистрированные CBR-агенты, БП которых соответствуют идентификаторам пользователей, агент управления проверяет их на предмет наличия свободных ресурсов и по возможности включает в работу по новым запросам пользователей. В состав блока CBR входят CBR-агенты и хранилище БП. CBR-агенты получают пользовательские поисковые запросы и осуществляют поиск решения в своих БП. CBR-агент занимается поиском решения в БП с использованием стандартных алгоритмов извлечения прецедентов и CBR-цикла [5]. Если CBR-агент не смог найти решение, удовлетворительное по точности (согласно выбранной метрике и заданному пороговому значению), он может сообщить об этом агенту управления, передавая ему информацию о решении, ближайшем к заданному пороговому значению. В свою очередь агент управления включает в рабочую группу по данному поисковому запросу дополнительных CBR-агентов, с которыми может взаимодействовать CBR-агент, для получения ответа на запрос пользователя и пополнения своей локальной БП новыми прецедентами. Основные программные компоненты предложенного архитектурного решения, обеспечивающие как традиционные, так и интеллектуальные механизмы поиска, были реализованы средствами MS Visual Studio 2010 на платформе Microsoft.NET с использованием технологии ASP.NET под операционную систему MS Windows. Литература 1. Ландэ Д.В. Поиск знаний в Internet. М.: Диалектика, 2005. 2. Харитоненков А.В. Семантические модели персонализации поиска в документальных массивах сети Интернет // Журн. науч. публ. аспирантов и докторантов. 2009. № 9. 3. Башмаков А.И., Башмаков И.А. Интеллектуальные информационные технологии: учеб. пособие. М.: Изд-во МГТУ им. Н.Э. Баумана, 2005. 4. Тарасов В.Б. От многоагентных систем к интеллектуальным организациям: философия, психология, информатика. М.: Эдиториал УРСС, 2002. 5. Варшавский П.Р., Еремеев А.П. Моделирование рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений // Искусственный интеллект и принятие решений. 2009. № 2. С. 45–47. 6. Бредихин К.Н., Варшавский П.Р. Архитектура системы распределенного вывода на основе прецедентов для интеллектуальных систем // Программные продукты и системы. 2011. № 1. С. 50–53. 7. FIPA: The Foundation for Intelligent Physical Agents. Abstract Architecture Specification, 2004. URL: www.fipa.org (дата обращения: 10.07.2012). References 1. Lande D.V., Poisk znaniy v Internet [Knowledge retrieval in the Internet], Moscow, Dialektika, 2005. 2. Kharitonenkov A.V., Zhurnal nauchnykh publikatsy aspirantov i doktorantov [Academic paper journal for postgraduates and Ph.D.], 2009, no. 9. 3. Bashmakov A.I., Bashmakov I.A., Intellektualnye informatsionnye tekhnologii: ucheb. posobie [Intelligent IT: study guide], Moscow, MGTU a.n. N.E. Baumana, 2005. 4. Tarasov V.B., Ot mnogoagentnykh sistem k intellektualnym organizatsiyam: filosofiya, psikhologiya, informatika [From multi-agent systems to intelligent companies: philosophy, phycology, computer science], Moscow, Editorial URSS, 2002. 5. Varshavsky P.R., Eremeev A.P., Iskusstvennyy intellect i prinyatie resheniy [Artificial intelligence and decision making], 2009, no. 2, pp. 45–47. 6. Bredikhin K.N., Varshavsky P.R., Programmnye produkty i sistemy [Software & Systems], 2011, no. 1, pp. 50–53. 7. FIPA: The Foundation for Intelligent Physical Agents. Abstract Architecture Specification, 2004, available at: www.fipa.org (accessed 10 July 2012). |
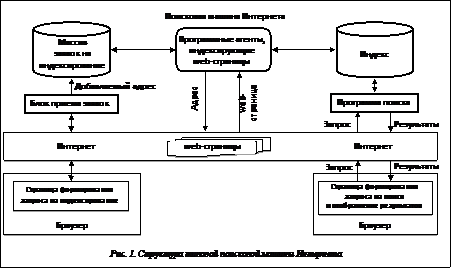 адачи поисковых машин Интернета: индексация сайтов и формирование БД поисковой машины Интернета (сбор и обработка данных), поиск информации (по копиям данных, хранимых в ее БД (индексе)), выдача результатов по запросам пользователей.
адачи поисковых машин Интернета: индексация сайтов и формирование БД поисковой машины Интернета (сбор и обработка данных), поиск информации (по копиям данных, хранимых в ее БД (индексе)), выдача результатов по запросам пользователей.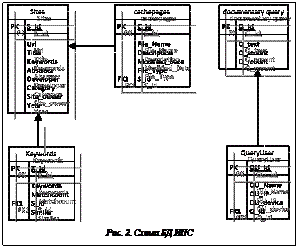 Определение тематических групп, рубрицирование сайтов по темам и т.д. могут выполняться автоматически или вручную (например, многие поисковые системы имеют собственные каталоги сайтов, сформированные опытным редактором, который точно относит некий ресурс к конкретной рубрике в огромном списке сайтов). Для определения важности ресурса в сети разработчиками ИПС используются различные коэффициенты и методы, основанные на учете внешних ссылок на сайты: тематический индекс цитирования у Яндекса, PageRank у Google, коэффициент популярности у Рамблера.
Определение тематических групп, рубрицирование сайтов по темам и т.д. могут выполняться автоматически или вручную (например, многие поисковые системы имеют собственные каталоги сайтов, сформированные опытным редактором, который точно относит некий ресурс к конкретной рубрике в огромном списке сайтов). Для определения важности ресурса в сети разработчиками ИПС используются различные коэффициенты и методы, основанные на учете внешних ссылок на сайты: тематический индекс цитирования у Яндекса, PageRank у Google, коэффициент популярности у Рамблера. Персонализация поиска и методы на основе прецедентов
Персонализация поиска и методы на основе прецедентов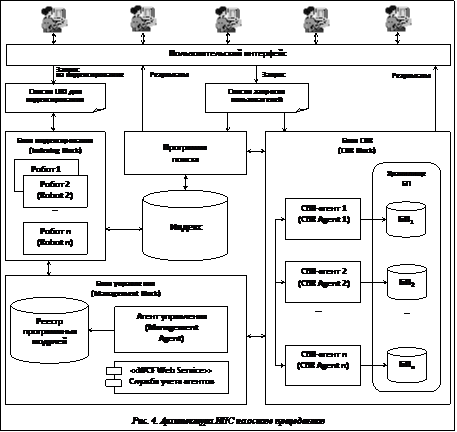 На базе архитектуры системы распределенного вывода на основе прецедентов для интеллектуальных систем [6] была предложена мультиагентная архитектура ИПС (рис. 4), включающая в себя следующие основные компоненты:
На базе архитектуры системы распределенного вывода на основе прецедентов для интеллектуальных систем [6] была предложена мультиагентная архитектура ИПС (рис. 4), включающая в себя следующие основные компоненты:| Permanent link: http://swsys.ru/index.php?id=3570&lang=en&page=article |
Print version Full issue in PDF (13.63Mb) Download the cover in PDF (1.39Мб) |
| The article was published in issue no. № 3, 2013 [ pp. 114-119 ] |
Perhaps, you might be interested in the following articles of similar topics: