Journal influence
Bookmark
Next issue
Ha-cluster of data collection system
The article was published in issue no. № 4, 2013 [ pp. 149-153 ]Abstract:The article describes the high available cluster (failover cluster) architecture of the software system for automation of data collection procedures. This architecture allows implementing software systems that provide service availability with needed guarantee. The article describes all parts of the software system such as server side and client side software. The paper is focused on server side components of the system, that works in the hight available cluster. The author gives the description of method for distribution packets between different failover cluster nodes. This method eliminates the use of the central failover cluster nodes. The basic idea of the method is that client software automatically selects first available cluster node using special procedure discribed in the article. The author also discusses algorithms for the distribution of packets between cluster nodes within the server software.
Аннотация:Описывается архитектура кластера высокой доступности программной системы автоматизации процедуры сбора данных. Приводятся причины, в силу которых требуется повышение отказоустойчивости системы. Основное вни- мание уделено описанию компонентов, расположенных на серверной стороне и работающих в режиме отказоустойчивого кластера. Кроме того, приводятся способы распределения запросов между различными узлами отказоустойчивого кластера, позволяющие отказаться от использования центрального узла кластера. Предлагаемый метод заключается в том, что за перераспределение запросов между узлами отвечает клиентское программное обеспечение, которое осуществляет выбор доступного узла путем выполнения специальной процедуры, описанной в статье. В данном исследовании рассмотрены механизмы распределения пакетов между узлами внутри отказоустойчивого кластера, позволяющие проводить асинхронную репликацию данных даже в том случае, если один из узлов некоторое время был недоступен.
| Authors: I.Yu. Artemov (i_artemov@ak-obs.ru) - Tver State Technical University (Senior Lecturer), Tver, Russia | |
| Keywords: cluster, mobile terminal, server, software architecture, control management |
|
| Page views: 13676 |
Print version Full issue in PDF (7.95Mb) Download the cover in PDF (1.45Мб) |
Большинство крупных производителей заинтересованы в повышении эффективности работы сотрудников отделов продаж (торговых/медицинских представителей – ТП). Одним из возможных способов повышения эффективности является использование систем SFA (Sales Force Automation). Крупные производители напрямую не осуществляют продажу продукции, этим занимаются дистрибьюторы (как правило, территориально распределенные по всей стране), в штате которых работают сотрудники производителя. Необходимо учитывать тот факт, что у дистрибьюторов и производителя разные корпоративные информационные системы (КИС). При этом одна часть данных, собранных ТП, должна передаваться дистрибьюторам (заказы продукции), а другая – производителю (информация о представленности продукции в торговой точке). С учетом всего перечисленного сегодня наиболее часто используются следующие варианты развертывания SFA-систем: 1) у каждого дистрибьютора устанавливается серверное оборудование SFA-системы; данный сервер подключается к КИС дистрибьютора и отвечает за обслуживание небольшой группы ТП; 2) в специализированном дата-центре устанавливается сервер SFA-системы, который отвечает за обслуживание всех дистрибьюторов и ТП. В связи с тем, что у производителя достаточно много дистрибьюторов (как правило, сотни), первый вариант развертывания SFA-систем харак- теризуется как высокой стоимостью владения (совокупная стоимость оборудования, ПО и дальнейшей поддержки аппаратно-программного комплекса), так и чрезвычайно низкой надежностью (возрастает вероятность выхода оборудования из строя, нестабильность каналов связи у дистрибьюторов и т.д.) [1, 2]. Главным достоинством данного варианта является возможность распределения нагрузки на серверные элементы SFA-системы и ускорения попадания данных в КИС дистрибьютора. Второй вариант развертывания SFA-системы (единый сервер) позволяет в большей или меньшей степени устранить недостатки первого варианта, однако в данном случае к серверу SFA-системы предъявляются повышенные требования по надежности аппаратно-программного комплекса в целом. На самом деле проблема надежности становится первоочередной, так как выход центрального узла из строя приведет к коллапсу всей SFA-системы.
Проведенные предварительные исследования показали, что фактически единственным способом, которым можно повысить отказоустойчивость системы, является организация кластера, состоящего из нескольких узлов [3]. Под кластером понимается группа компьютеров, объединенных высокоскоростными каналами связи и представляющая, с точки зрения пользователя, единый аппаратный ресурс. К кластеру SFA-системы OMOBUS предъявляются следующие основные требования: – гарантированная высокая отказоустойчивость системы при возможном выходе аппаратного обеспечения сервера из строя; – отсутствие в кластере центрального узла; – полностью автономная работа всех узлов кластера (взаимное влияние узлов должно быть абсолютно исключено); – введение узлов в эксплуатацию после сбоя без необходимости временной остановки всей системы. Среди известных видов кластеров выделим [3]: – отказоустойчивые кластеры (High-Availability Clusters – HA-кластеры высокой доступности) с холодным и горячим резервами, с модульной избыточностью; – кластеры с балансировкой нагрузки (Load Balancing Clusters); – вычислительные кластеры (High Perfomance Computing Clusters); – grid-системы. Для решения поставленной задачи необходимо использовать кластеры высокой доступности с модульной избыточностью. Только в этом случае гарантируется, что разные узлы кластера будут находиться всегда в едином состоянии либо различия гарантированно не повлияют на дальнейшую работу. При этом количество узлов, входящих в кластер, должно быть не менее двух, желательно расположенных в разных дата-центрах. Все остальные виды кластеров по тем или иным причинам не позволяют решить поставленную задачу в полной мере: отказоустойчивые кластеры с холодным/горячим резервом подразумевают потенциальную возможность простоя, если основной узел вышел из строя и не гарантирует эквивалентность данных, хранящихся на узлах; кластер с балансировкой нагрузки предполагает наличие центральных узлов, отвечающих за диспетчеризацию данных; вычислительные кластеры и grid-системы используются для других целей.
Концептуально HA-кластер SFA-системы OMOBUS включает следующие основные элементы (в скобках указываются названия модулей, разработанных в рамках реализации задачи, описываемой в данной статье): – специально спроектированный мобильный терминал (omobus-mobile), который может осуществлять выбор доступных узлов кластера; – FTP-сервер Pure-FTPd для обмена данными, в рамках которого происходит репликация (omobus-pk-repl) полученных пакетов на другие узлы кластера; – сервер документов, отвечающий за обработку данных, напрямую полученных на данный узел с мобильных терминалов; – сервер документов (omobus-node), который обрабатывает данные, полученные с других узлов кластера; – агрегационное хранилище данных, реализованное на основе системы управления реляционных БД (в текущий момент времени поддерживаются СУБД Postgres и Firebird); – генератор данных для дистрибьютора; – генератор данных для производителя; – единая шина (Enterprise Service Bus – ESB), к которой подключены производитель, дистрибьюторы и SFA-система OMOBUS. Как видно из рисунка 2, процедура выбора доступного узла кластера реализована на стороне мобильного терминала. Данный подход позволяет отказаться от использования центрального узла кластера, который отвечает за диспетчеризацию принимаемых потоков данных. Фактически за диспетчеризацию данных отвечает каждый мобильный терминал самостоятельно. Список узлов кластера загружается при запуске мобильного терминала из текстового конфигурационного файла. Из этого же файла загружаются параметры, связанные с проверкой доступности узла кластера (тайм-аут выполнения процедуры подключения к узлу). Код процедуры проверки доступности узла написан на языке C с использованием BSD sockets [4]. Данный подход позволяет добиться высокой производительности и переносимости кода. В настоящий момент процедура проверки доступности узла используется на терминалах, работающих под управлением Windows Mobile и Android. Схема проверки доступности узла кластера приводится на рисунке 3. Как видно из приведенной схемы, в ходе выполнения процедуры выбирается первый доступный узел из списка. Проверка доступности узла осуществляется путем выполнения определенных действий (для предотвращения длительных задержек, связанных с сетевыми интерфейсами, все перечисленные действия выполняются в неблокирующем режиме, который предполагает, что выполняющаяся в текущий момент операция имеет строго предписанное максимальное значение времени выполнения), а именно: – подключение к требуемому узлу путем вызова функции connect; перед вызовом данной функции выполняется определение IP-адреса по DNS-имени; – получение приветствия со стороны ftp-сервера согласно RFC959; данная процедура выполняется с помощью функции recv. Узел считается доступным и готовым к приему данных только в случае, если все перечисленные шаги выполнены успешно. При штатной работе кластера большая часть данных будет передаваться на первый узел кластера. В результате этого возникает вторая задача, которая подразумевает репликацию полученных на каждый узел данных на другие узлы кластера. Данная задача решается с помощью модуля omobus-pk-repl. Модуль omobus-pk-repl работает на каждом узле кластера и отвечает за репликацию входящих потоков данных на общие ресурсы, доступные всем заинтересованным сторонам. Данный модуль написан на языке C с использованием компилятора gcc и может работать под управлением любой unix-подобной операционной системы (Linux, FreeBSD и т.д.). Модуль omobus-pk-repl интегрируется с ftp-сервером Pure-FTPd (http://www.pureftpd.org/project/pure-ftpd), который вызывает данный модуль для всех входящих потоков данных. Входящий поток данных представляет собой набор специально оформленных файлов (пакетов), содержащих структурированные данные в текстовом формате (XML – eXtensible Markup Language). При необходимости пакеты могут сжиматься с помощью алгоритма deflate или Барроуза–Уилера. Исходя из этого omobus-pk-repl выполняет следующие операции. · Распаковывается исходный пакет (если это необходимо). Для распаковки пакетов, сжатых с помощью алгоритма deflate, используется библиотека zlib (http://www.zlib.net/), а Барроуза–Уилера – bzip2 (http://www.bzip.org/). · Выполняются разбор данных, хранящихся в формате XML, и их первичная проверка с помощью функций библиотеки libxml2 (http://www. xmlsoft.org/). · · Если все проверки прошли успешно, пакет дублируется в локальную папку, к которой имеется доступ через FTP с других узлов. Дальнейший ввод реплицированных пакетов осуществляется с помощью сервера документов omobus-node, который загружает данные, хранящиеся на удаленном узле. С учетом того, что сервер документов работает с высокой периодичностью (не реже двух раз в минуту), узлы оказываются в полностью идентичном состоянии в любой момент времени. В том случае, если узел (например node1) выходит из строя (допустим, по причине поломки аппаратуры) или временно недоступен (проблемы в дата-центре или плановое обслуживание оборудования), мобильные терминалы перестают обнаруживать такой узел и отправляют данные на первый доступный узел из оставшихся в эксплуатации (node2). На узле node2 реплицированные для узла node1 пакеты будут накапливаться до тех пор, пока узел node1 не будет возвращен к активной работе. Как только это произойдет, все накопленные данные будут загружены на узел node1 и обработаны. После этого узлы станут идентичными (по данным, которые в них хранятся). В настоящий момент времени разработанное ПО находится в стадии финального тестирования. Реальная эксплуатация кластера SFA-системы OMOBUS намечена на ноябрь–декабрь 2013 года. Планируется, что кластер будет состоять из двух узлов (каждый из них оснащен двумя восьмиядерными процессорами Intel Xeon и 32 Gb RAM), которые разместятся в разных дата-центрах. К кластеру планируется подключить около 500 мобильных терминалов, предназначенных для работы на территории всей страны. В заключение следует отметить, что полученная архитектура кластера высокой доступности с избыточной модульностью позволяет реализовать SFA-систему, работающую в режиме 24X7X365, то есть фактически обеспечить необходимый сервис в непрерывном режиме в любой момент времени круглый год. Литература 1. Everitt B.S., Landau S., Leese M. Cluster Analysis. A Hodder Arnold Publ., 2001, pp. 120–234. 2. Пономаренко В.С., Листровой С.В., Минухин С.В., Знахур С.В. Методы и модели планирования ресурсов в GRID-системах. Украина, Харьков: Издат. дом ИНЖЭК, 2008. 408 с. 3. Стивенс Р., Раго С. UNIX: профессиональное программирование: 2-е изд. СПб: Символ-Плюс, 2007. 1040 с. 4. Стивенс Р., Феннер Б., Рудофф Э.М. UNIX: разработка сетевых приложений: 3-е изд. СПб: Питер, 2007. 1039 с. References 1. Everitt B.S., Landau S., Leese M. Cluster Analysis. A Hodder Arnold Publ., 2001, pp. 120–234. 2. Ponomarenko V.S., Listrovoy S.V., Minukhin S.V. Metody i modeli planirovaniya resursov v GRID- sistemakh [Planing methods and models for resourses in GRID-systems]. Ukraine, Kharkov, INZHEK Publ., 2008, pp. 95–102 (in Russ.). 3. Stivens R., Rago S. UNIX professionalnoye programmirovaniye [UNIX professional programming]. 2nd ed., St. Petersburg, Simvol-Plyus Publ., 2007, pp. 504–532. 4. Stivens R., Fenner B., Rudoff E.M. UNIX: razrabotka setevykh prilozheniy [UNIX developing network applications]. 3rd ed., St. Petersburg, Piter Publ., 2007, pp. 185–222. |
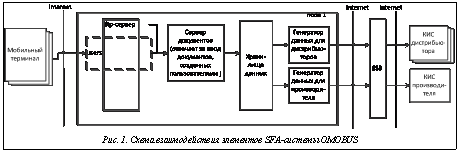 В данной статье описывается разработка архитектуры развертывания серверной составляющей SFA-системы OMOBUS (см. рис. 1), которая позволила бы повысить отказоустойчивость системы в целом и полностью устранила бы возможные риски, связанные с простоем системы.
В данной статье описывается разработка архитектуры развертывания серверной составляющей SFA-системы OMOBUS (см. рис. 1), которая позволила бы повысить отказоустойчивость системы в целом и полностью устранила бы возможные риски, связанные с простоем системы.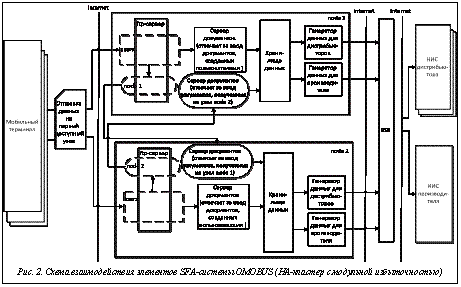 С учетом всего перечисленного схема элементов HA-кластера с модульной избыточностью будет иметь вид, приведенный на рисунке 2. Как видим, кластер не содержит центральный узел, все элементы кластера равноправны и не зависят друг от друга. Выход любого узла кластера из строя не повлечет за собой отказ всей системы.
С учетом всего перечисленного схема элементов HA-кластера с модульной избыточностью будет иметь вид, приведенный на рисунке 2. Как видим, кластер не содержит центральный узел, все элементы кластера равноправны и не зависят друг от друга. Выход любого узла кластера из строя не повлечет за собой отказ всей системы.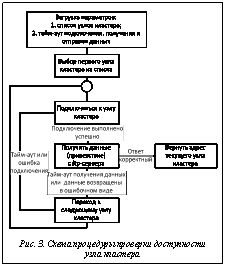 Выполняется проверка соответствия разобранного XML предписанной схеме документов, хранящейся в формате XSD (XML Schema Definition). Это позволяет провести тонкую проверку входящих данных на соответствие требуемой спецификации.
Выполняется проверка соответствия разобранного XML предписанной схеме документов, хранящейся в формате XSD (XML Schema Definition). Это позволяет провести тонкую проверку входящих данных на соответствие требуемой спецификации.| Permanent link: http://swsys.ru/index.php?id=3675&lang=en&page=article |
Print version Full issue in PDF (7.95Mb) Download the cover in PDF (1.45Мб) |
| The article was published in issue no. № 4, 2013 [ pp. 149-153 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Использование параллельной обработки данных для оптимизации работы программного обеспечения
- Программный комплекс автоматизации процедуры сбора данных
- Веб-модель распределенной информационной системы реального времени
- Унифицированное описание функционирования информационных радиоэлектронных систем для оценки программного обеспечения учебно-тренировочных средств
- Информационно-коммуникационная технология комплексного управления деятельностью студентов
Back to the list of articles