Journal influence
Bookmark
Next issue
formal methods of text authorship attribution and their usage in software products
The article was published in issue no. № 4, 2013 [ pp. 286-295 ]Abstract:The article represents the survey of authorship attribution methods. It also provides a description of the popular software systems to determine the author's style, focused on the Russian language. There was an attempt to make their comparative analysis, to identify advantages and drawbacks of approaches. An authorship attribution is often based on the assumption that the alleged author is known. The analysis of syntactic, lexical-phraseological and stylistic levels of text is the most interesting and the most difficult. Expert analysis of the author's style is a time consuming process, so the attention is paid to the formal methods of attribution. Currently, to establishing the authorship of texts the following methods are used: the approaches of pattern recognition theory, methods of mathematical statistics and probability theory, neural network algorithms, cluster analysis algorithms, etc. Among the challenges to research the field of authorship attribution there is a problem of choosing formal parameters characterizing the text and style of the author, the sampling problem of reference texts. The software products are not focused on integrated study and results comparison. They are applied to various problems of analysis of text styles with different frequency characteristics and different test material. To find a new or improve existing methods of attribution of texts further research is needed. It is also important to carry out experiments aimed at finding features that allow to clearly separate the authors styles, including the small sample size.
Аннотация:В данной статье делается обзор методов установления авторства текстов. В ней также описаны наиболее известные программные системы для определения авторского стиля, ориентированные на русский язык, предпринята по- пытка произвести их сравнительный анализ, выявить особенности и недостатки рассмотренных подходов. Задачу атрибуции текста чаще всего решают с целью идентификации автора, исходя из того, что автор текста известен. При этом анализ синтаксического, лексико-фразеологического и стилистического уровней текста представляет наибольший интерес и наибольшую сложность. Экспертный анализ авторского стиля является трудоемким процессом, поэтому в работе уделяется внимание именно формальным методам атрибуции. В настоящее время для установления авторства текстов применяются подходы из теории распознавания образов, математической статистики и теории вероятностей, алгоритмы нейронных сетей, кластерного анализа и др. К проблемам, затрудняющим исследования в области атрибуции текстов, относятся выбор лингвостилистических параметров, характеризующих текст и стиль автора, и составление выборки эталонных текстов. Имеющиеся программные продукты не ориентированы на комплексное исследование и сравнение результатов, они применяются для разных задач анализа стилей текстов с использованием различных частотных признаков и различного тестового материала. Необходимо проводить дальнейшие исследования, направленные на поиск новых или совершенствование уже имеющихся методов атрибуции текстов. Не менее важным является осуществление экспериментов, цель которых – поиск характеристик, позволяющих четко разделять стили авторов, в том числе и на малых объемах выборки.
| Authors: Batura T.V. (tatiana.v.batura@gmail.com) - A.P. Ershov Institute of Informatics Systems (IIS), Siberian Branch of the Russian Federationn Academy of Sciences, Novosibirsk, Russia, Ph.D | |
| Keywords: characteristics of text, text categorization, author's style, formal parameters of the text, authorship attribution, text attribution |
|
| Page views: 26052 |
Print version Full issue in PDF (7.95Mb) Download the cover in PDF (1.45Мб) |
При решении задачи установления авторства текста (или задачи атрибуции) неизбежно приходится обращаться к экспертам. Эксперты могут идентифицировать автора неизвестного текста или определить принадлежность произведения другому автору при помощи характерных языковых особенностей и стилистических приемов. Несомненно, подобные исследования трудоемки, однако задача установления авторства текстов возникает в различных областях и представляет интерес для филологов, литературоведов, юристов, криминалистов, историков. Поэтому встает вопрос о создании формальных методов ее решения. В настоящее время для атрибуции текстов применяются подходы из теории распознавания образов, математической статистики и теории вероятностей, алгоритмы нейронных сетей и кластерного анализа и многие другие. С развитием вычислительной техники появилась возможность реализовать методы, требующие огромных вычислений, чтобы облегчить работу экспертов. Существующие программные продукты позволяют учитывать и варьировать различные лингвостатистические параметры, разносторонне характеризующие текст. В статье приведен обзор различных формальных методов определения авторского стиля, предпринята попытка выявить их особенности и недостатки, сравнить программные продукты по атрибуции текстов, ориентированные на русский язык. Лингвостатистические параметры анализируемого текста Атрибуция текста – исследование текста с целью установления авторства или получения каких-либо сведений об авторе и условиях создания текстового документа. Как отмечено в [1], задачи атрибуции можно разделить на идентификационные и диагностические. Идентификационные задачи позволяют подтвердить или исключить авторство определенного лица, проверить тот факт, что автором всего текста был один и тот же человек или что написавший текст является при этом его настоящим автором. Идентификационные задачи решаются из предположения, что автор текста известен. Диагностические задачи позволяют определить личностные характеристики автора (образовательный уровень, родной язык, знание иностранных языков, происхождение, место постоянного проживания и др.) и/или определить факт сознательного искажения письменной речи. Диагностические задачи решаются из предположения, что автор текста неизвестен. В этих случаях обычно невозможно сопоставить исследуемый текст с текстами автора. Методы атрибуции позволяют исследовать текст на пяти уровнях: пунктуационном, орфографическом, синтаксическом, лексико-фразеологическом, стилистическом. На пунктуационном уровне выявляются особенности употребления автором знаков препинания и характерные ошибки. На орфографическом уровне выявляются характерные ошибки в написании слов. На синтаксическом уровне определяются особенности построения предложений, предпочтение тех или иных языковых конструкций, употребление времен, порядок слов и т.д. На лексико-фразеологическом уровне определяются словарный запас автора, особенности использования слов и выражений, склонность к употреблению редких и иностранных слов, диалектизмов, архаизмов, неологизмов, профессионализмов, навыки употребления фразеологизмов, пословиц, поговорок и т.д. На стилистическом уровне определяются жанр, общая структура текста, для литературных произведений – сюжет, характерные изобразительные средства (метафора, ирония, аллегория, гипербола, сравнение), стилистические фигуры (градация, антитеза, риторический вопрос и т.д.), другие характерные речевые приемы. Под авторским стилем обычно понимаются последние три уровня. Анализ именно синтаксического, лексико-фразеологического и стилистического уровней представляет наибольший интерес и наибольшую сложность. Существует довольно много методов анализа стиля. В целом их можно разделить на две большие группы – экспертные и формальные. Экспертные методы предполагают исследование текста профессиональным лингвистом-экспертом. Формальные методы чаще всего основаны на сравнении вычислимых характеристик текстов, как в теории распознавания образов. Применение теории распознавания образов в задаче атрибуции текстов можно встретить, например, в [2, 3]. В общем случае текст отображается в вектор вычисленных для него параметров, каждый из которых объективно характеризует некоторый набор особенностей текста. Автор также может быть представлен в виде аналогичного вектора параметров (вектора текстов, написанных данным автором). В качестве критерия близости двух текстов вводится «расстояние» между соответствующими векто- рами. В большинстве случаев в качестве характеризующих параметров текста выбираются статистические характеристики: количество использования определенных частей речи, знаков препинания, количество и длина предложений (измеренная в словах, слогах, знаках), объем словаря, количество полнозначных и служебных слов, средняя длина предложения в тексте и т.д. Основная проблема формальных методов анализа авторства состоит как раз в выборе параметров. Как было отмечено А.А. Марковым [4], существует целый ряд формальных статистических характеристик текстов, непригодных для установления авторства в силу одного из двух недостатков. Отсутствие устойчивости. Разброс значений параметра для текстов одного и того же автора настолько велик, что диапазоны возможных значений для разных авторов перекрываются. Очевидно, данный параметр не поможет различать авторов, а при использовании в составе группы параметров сыграет роль дополнительного шума. Отсутствие различающей способности. Параметр может принимать близкие значения для всех или большинства авторов, поскольку его значения определяются свойствами языка, на котором написаны тексты, а не индивидуальными особенностями создателя текста. Таким образом, параметры, используемые в формальных методах установления авторства, должны предварительно исследоваться на устойчивость и различающую способность, желательно на текстах большого количества различных авторов. В работе [5] выделены следующие три условия применимости формального параметра. Массовость. Параметр должен опираться на те характеристики текста, которые слабо контролируются автором на сознательном уровне. Это необходимо, чтобы устранить возможность сознательного искажения автором характерного для него стиля или имитации стиля другого автора. Устойчивость. Параметр должен сохранять постоянное значение для одного автора. Естественно, в силу случайных причин некоторое отклонение значений от среднего неизбежно, но оно должно быть достаточно мало. Различающая способность. В идеале параметр должен принимать существенно различные значения (превышающие колебания, возможные для одного автора) для разных авторов. Необходимо отметить, что выбрать параметры, которые гарантированно разделяют двух любых авторов, очень трудно. Поэтому на практике считается достаточным, чтобы параметр позволял уверенно различать между собой разные группы авторов, то есть существовало достаточно большое количество групп авторов, для которых средние значения параметра существенно различаются. Параметр, очевидно, не поможет различить тексты авторов из одной группы, но позволит уверенно различать тексты авторов, попавших в разные группы. Различать тексты авторов одной группы можно за счет одновременного использования достаточно большого вектора различных по характеру параметров – в этом случае вероятность случайного совпадения, соответственно, станет заметно меньше. Применение методов теории распознавания образов для атрибуции текстов В работах [2, 3] проблему атрибуции текстов предлагается решать методами теории распознавания образов. В качестве атрибутируемых объектов были отобраны 13 комедий Мольера в стихах. Существует гипотеза, что автором большинства стихотворных пьес, приписываемых Мольеру, являются П. Корнель и некоторые другие французские драматурги. Поэтому основной целью исследования стало применение математических методов для решения проблемы «Корнель–Мольер». Количество предложений в выбранных произведениях варьировалось от 72 до 1 293. Для описания априорных классов был взят 51 параметр. Из полученного априорного словаря выбрали небольшое количество информативных параметров при помощи схемы М.М. Бонгарда, предусматривающей двухступенчатое свертывание парамет- рического пространства. На первом этапе производилось автоматическое разбиение априорного набора информативных параметров на два подмножества, релевантных и нерелевантных для различения априорных классов. На втором этапе релевантность параметров для различения двух априорных классов определялась по t-критерию Стьюдента, пороговое значение которого равно 1,96 при уровне значимости a=0,05. Если наблюдаемое значение критерия превышало пороговое, параметр относился к числу информативных, в противном случае он исключался из дальнейшего рассмотрения. Информативный набор состоял из пяти параметров: число элементарных и сочиненных предложений, число спрягаемых форм глагола, подлежащих и местоимений-подлежащих. По результатам проведенного анализа качества классификации было установлено, что из 13 рассмотренных пьес автором 10 из них (6 на 95 % и 4 на 63–73 %) является П. Корнель, одна пьеса была атрибутирована на 68 % Ф. Кино, две оставшиеся пьесы были отнесены к отдельному апостериорному классу. Система «Лингвоанализатор» В работах [6, 7] описан ряд исследований, проведенных Д.В. Хмелевым, результатом которых явился вывод об эффективности применения алгоритмов сжатия данных для задачи определения авторства. Также был сделан вывод о том, что простейший подход с использованием цепей Маркова первого порядка показывает хорошие результаты на файлах большого объема и плохие по сравнению с другими методами на отрывках длиной в 2 000–5 000 символов. Этот метод был реализован в системе «Лингвоанализатор» (http:// www.rusf.ru/books/analysis). Существенное преимущество метода энтропийной классификации (с помощью сжатия) состоит в отсутствии предварительной обработки текста. Суть метода в том, чтобы добавлять текст, автор которого неизвестен, к тексту, принадлежащему конкретному автору, и смотреть, насколько хорошо сжимается эта добавка. Правильный исходный класс документа – это тот, на котором он сжимается лучше всего. Существует большое множество алгоритмов сжатия данных, каждый алгоритм имеет большое число модификаций и параметров. Все они реализованы в различных программах, которых в настоящий момент довольно много. В работе [6] приведены некоторые результаты эксперимента по сравнению точности определения авторства текста с использованием алгоритмов сжатия данных. Некоторые эксперименты проводились на массиве новостей агентства Рейтерс (Reuters Corpus Volume 1). Было отобрано 50 авторов с наибольшим объемом статей, всего 1 813 статей. Выборка случайно была разбита на 10 равных частей, одна из которых использовалась для тестирования. Лучший результат получен для метода с применением программы rar (точность 89,4 %). Другие эксперименты проводились на корпусе текстов, состоящем из 385 текстов 82 писателей. Тексты подверглись предварительной обработке: были склеены все слова, разделенные переносом, и опущены все слова, начинавшиеся с прописной буквы. Оставшиеся слова помещены в том порядке, в каком они находились в исходном тексте с разделителем из символа перевода строки. У каждого из писателей было отобрано по контрольному произведению. Остальные тексты были объединены в обучающие выборки. Объем каждого контрольного произведения составлял не менее 50 000–100 000 символов. Проведенные исследования показали, что программы сжатия угадывают истинных писателей весьма часто на текстах большого объема. Особенно хорошо проявляет себя программа rarw (точность 71 %), результаты применения которой превосходят реализацию других подходов в этой области. Тем не менее остаются и открытые вопросы. Например, почему использование программы rarw, применяющей модификацию алгоритма LZ, на файлах большого объема опережает многие другие методы, также применяющие модификацию LZ. Применение методов из теории вероятности и математической статистики для атрибуции текстов В некотором роде вышеназванное исследование продолжено в работе [8]. Предложенный метод основан на учете статистики употребления пар элементов любой природы, идущих друг за другом в тексте (букв, морфем, словоформ и т.п.), то есть на формальной математической модели последовательности букв (и любых других элементов) текста как реализации цепи Маркова. По тем произведениям автора, которые достоверно им созданы, вычислялась матрица переходных частот употребления пар элементов (букв, грамматических классов слов и т.п.). Она служила оценкой матрицы вероятности перехода из элемента в элемент. Для каждого из авторов строилась матрица переходных частот и оценивалась вероятность того, что именно он написал анонимный текст (или фрагмент текста). Автором анонимного текста считался тот, для кого вычисленная оценка вероятности больше. Исходный корпус текстов подвергался предварительной обработке и был представлен в четырех вариантах: а) пары букв в их естественных последовательностях в тексте – в словах (в той форме, в которой они употреблены в тексте) и пробелах между ними; б) пары букв в последовательностях букв в приведенных формах слов (словарных, лемматизованных или исходных); в) пары наиболее обобщенных грамматических классов слов (части речи, условные категории типа «конец предложения», «сокращение» и др.) в их последовательностях в предложениях текста; г) пары менее обобщенных грамматических классов слов; к ним относятся такие семантико-грамматические разряды, как одушевленные существительные, неодушевленные существительные, прилагательные качественные, относительные, притяжательные и т.п. В процессе предварительной обработки отбрасывались все слова, для которых не удалось автоматически определить грамматический класс, все знаки препинания, все слова с заглавной буквы, склеивались все слова, разделенные переносом, каждый символ кодировался числом. Была выполнена перекрестная проверка метода на материале 385 текстов 82 авторов. Показателем точности метода является процент правильно определенных произведений. Для варианта (а) получено 73 % точных определений, для (б) – 62 %, для (в) – 61 %. На материале варианта (г) получены значительно худшие результаты – 4 %. В работе [9] показано, что последовательность символов текста не обладает свойствами простой цепи Маркова. Таким образом, гипотеза, выдвинутая в [7, 8], опровергнута. Тем не менее на основе проведенных в [8] экспериментов был сделан вывод, что использование пар подряд идущих в тексте букв дает более точные результаты, чем использование таких языковых категорий, как одиночные грамматические классы слов и их пары. Поэтому было выдвинуто предположение, что в буквенных парных структурах частично отображаются полные структуры морфем словоформ текста – префиксальные, корневые, суффиксальные и флективные. Тем самым довольно большой объем словоизменительной и словообразовательной информации о структуре русских слов оказывается отображенным в статистике парной встречаемости букв, что и определяет довольно высокий уровень эффективности использования этой статистики для определения авторства текста. Другими словами, подсчет частоты употреблений пар букв позволяет учесть информацию о словаре, который используется автором, а также косвенно информацию о предпочитаемых им грамматических конструкциях. Система «Атрибутор» Как продолжение развития подхода, использующего в качестве стилевых признаков бинарные буквосочетания, А.Н. Тимашев [10] предложил применять трехбуквенные сочетания – триады. При таком методе анализу поддаются однобуквенные и двухбуквенные служебные слова, а это значительная часть наиболее частотных предлогов, союзов, частиц и междометий, которые традиционно считаются значимыми стилеметрическими показателями. По этой причине цепочки из двух, четырех и большего количества букв менее показательны, что и было доказано в процессе исследования. На основе данных рассуждений создан программный продукт для автоматического сравнения и классификации текстов по параметрам индивидуального авторского стиля под названием «Атрибутор» (http://www.textology.ru/web.htm). База этой программы содержит произведения 103 авторов и использует экспертную обработку текстов. В эталонную выборку, на которой происходило обучение «Атрибутора», попали в основном романы и повести отечественных писателей XIX–XX веков. Пополнение шло за счет ресурсов известных электронных библиотек, наибольшее количество текстов было получено в библиотеке М. Мошкова. Выборка производилась таким образом, чтобы тексты разных писателей в максимальной степени различались друг от друга, а тексты одного писателя были максимально близки. Те случаи, когда известный писатель в какой-то период своего творчества резко менял стиль изложения, отсеивались. Для обработки текста «Атрибутором» необходимо, чтобы его длина была не меньше 6 страниц. Ограничение на длину текста накладывается для того, чтобы избежать ошибок, связанных со сравнением статистически несопоставимых объектов. В обработку попадают все слова, кроме имен собственных. Система «СМАЛТ» Еще один программный продукт для определения авторства текстов – «СМАЛТ» (Статистические методы анализа литературного текста), основан на алгоритмах автоматизации морфологического и синтаксического анализа текстов (http://smalt.karelia.ru). Обработка текстов в разработанной системе производится в несколько этапов. На первом шаге выполняется автоматизированное разбиение исходного текста на лексические единицы, среди которых выделяются часть (или раздел), абзац, предложение, слово. На втором осуществляется морфологический разбор текста. На третьем – синтаксический разбор. Для проведения исследований была взята 81 публицистическая статья 60–70 гг. XIX в. из журналов «Время» и «Эпоха», цель – определение принадежности ряда статей Ф.М. Достоевскому. В качестве параметров были взяты следующие величины: средняя длина слова в буквах, средняя длина предложения в словах, индекс разнообразия лексики (отношения числа разных словоформ к числу словоупотреблений). Проводилось исследование с выборками разных объемов: в 200, 300, 400, 500 и 600 слов. Использовались частотные словари на каждые 500 слов текста. Все словоформы распределились в группы по 1, 2, …, 10 раз встречаемости в выборке. Далее определялось число словоформ в каждой группе, что означает распределение частот на уровне словаря, и покрываемость текста, что означает распределение частот на уровне текста. В работе [11] были выдвинуты гипотезы об эффективности выполнения некоторых методов для анализа текстов: метода проверки гипотез с помощью критерия Стьюдента, критерия Колмогорова–Смирнова на согласованность с заданным распределением, методов кластерного анализа, методики «сильный граф», в которой в качестве основной характеристики текстов рассматривалась матрица частот парной встречаемости грамматических классов слов. В ходе исследования были получены числовые значения критерия Стьюдента для всех статей. В группе статей Ф.М. Достоевского выявлялась статья с максимальным значением t-характеристики, в то время как в группе атрибутируемых статей и статей других авторов исключались статьи со значением t-характеристики, большим фиксированного. В методе иерархической кластеризации использовались две меры расстояния между объектами: евклидова мера и мера Чебышева. Для определения расстояния между кластерами применялись методы ближнего и дальнего соседа. Исследование было проведено на основе двух наборов признаков: основного, состоящего из частей речи (16 признаков), и расширенного, с подключением дополнительных морфологических параметров, например падеж, род и т.п. (156 признаков). В результате проведенных экспериментов не удалось установить, является ли автором рассматриваемых статей Ф.М. Достоевский, так как обе гипотезы (о том, что Ф.М. Достоевский – автор, и о том, что не автор) неверны. Применение методов «сильный граф», корреляционных плеяд и иерархической кластеризации показало неэффективность использования формально-грамматических параметров для определения принадлежности исследуемых статей Ф.М. Достоевскому. Недостаток предложенного метода состоит в том, что задачу определения авторства приходится сводить к задаче построения качественного и быстрого синтаксического анализатора. Последняя из задач является не менее трудной и до сих пор не решена на требуемом уровне. Система «Антиплагиат» Среди существующих автоматических средств, призванных помочь в решении проблемы атрибуции текстов, следует также упомянуть систему «Антиплагиат» (http://www.antiplagiat.ru). Этот интернет-сервис предлагает осуществить проверку текстовых документов на наличие заимствований из общедоступных сетевых источников. На первом этапе система собирает информацию из различных источников: загружает из Интернета и обрабатывает сайты, находящиеся в открытом доступе, базы научных статей и рефератов. Загруженные документы проходят процедуру фильтрации, в результате которой отбрасывается бесполезная с точки зрения потенциального цитирования информация (например, HTML-страницы с большим количеством рекламы, новостные заголовки и т.д.). На следующем этапе каждый из полученных таким образом текстов определенным образом форматируется и заносится в системную БД. Кроме того, в общую базу текстов поступают документы, загруженные на проверку пользователем, если такая возможность была разрешена им во время процедуры загрузки. Все пользовательские документы, загружаемые для проверки, ставятся в очередь на обработку. Проверка документа, например реферата среднего размера, занимает несколько секунд. Поиск совпадений осуществляется сравнением последовательностей символов без учета языковых особенностей и речевых взаимосвязей. За счет этого достигается высокая, в несколько секунд, скорость поиска совпадений. Система позволяет проводить атрибуцию текстов на различных языках. После проверки документа пользователь получает доступ к отчету, в котором представляются результаты. Структура отчета позволяет выделять в проверяемом тексте заимствованные части как по всем источникам, так и по их любому подмножеству. К сожалению, все программные алгоритмы, используемые в «Антиплагиате», являются коммерческой тайной компании «Форексис». К недостаткам системы можно отнести невозможность отлавливать заимствованный текст при условии, что в каждое предложение текста добавлено или убрано из него всего лишь одно слово. Сегодня существуют программы, например «Антиплагиат киллер» (http://otlichnik.biz/publ/antiplagiat_killer_ 2_0/1-1-0-4), позволяющие обходить систему «Антиплагиат». Авторский инвариант и лингвистические спектры В рамках относительно небольшого текста значения большинства формальных характеристик не позволяют установить авторский стиль. Кроме того, на коротких текстах часто не проявляются и другие характеристики, например, особенности использования автором фразеологизмов, метафор, эпитетов и т.д. С другой стороны, для текстов порядка 1 000–2 000 слов сохраняются грамматические особенности авторского стиля: частота употребления неполнозначных, служебных слов (частиц, союзов, предлогов, некоторых модальных слов, вводных выражений). Такой метод установления авторства текста иногда называют лингво- статистическим анализом неполнозначной лексики. В работе [5] исследователи вводят понятие авторского инварианта – формальной характеристики текста, удовлетворяющей условиям массовости, устойчивости и различающей способности. Авторский инвариант – характеристика текста, вычисленная как процент содержания служебных слов (их было взято 55) в тексте. Начальная выборка состояла из 2 000 слов, затем объем выборок последовательно увеличивался до 4 000, 8 000, 16 000 слов. Проведенный эксперимент показал, что дальнейшее увеличение объема выборок необязательно, так как искомый авторский инвариант был обнаружен уже при величине выборки в 16 000 слов. В качестве критерия стабилизации был взят следующий принцип. Объем выборки увеличивался до тех пор, пока не обнаруживался параметр, для которого средняя величина его отклонений от средних значений вдоль произведений всех исследуемых писателей оказывалась существенно меньше амплитуды колебаний параметра между текстами разных авторов. Эксперименты проводились на выборке из основных произведений 23 авторов трех веков – от XVIII до XX. В результате, например, был сделан вывод о том, что автором романа «Тихий Дон» не является М.А. Шолохов. Серьезным ограничением этого метода является очень низкая разделительная способность оценки в случае большого числа авторов (потенциально метод может разделять лишь 10 авторских стилей). Истоки этого метода восходят к работе Морозова Н.А. [12], который первым заметил, что именно особенности употребления служебных слов, лексем с общей семантикой, не привязан- ной к тематике художественного произведения, формируют авторский стиль и практически не поддаются имитации. В качестве характеристик авторского стиля он предложил брать часто используемые слова: предлоги, союзы, частицы, подсчитывая число употреблений каждой в отдельности. А графическое изображение их частот назвал лингвистическими спектрами. В конечном счете выяснилось, что лингвистические спектры слишком неустойчивы, чтобы служить серьезным основанием для разграничения авторского стиля. Система «Стилеанализатор» Проблему атрибуции текстов в [9, 13] предлагается решать при помощи нейронных сетей и методов иерархической кластеризации. В качестве меры сравнения матриц частот появления признаков предлагается использовать меру Кульбака и меру хи-квадрат. В работах также показано, что мера Хмелева из [7] является частным случаем меры Кульбака. Под частотным признаком понимается любой признак стиля текста, допускающий возможность нахождения частоты его появления в тексте (например, число появления абзацев в тексте). На основе проведенных исследований разработан программный комплекс «Стилеанализатор». В [9] были проведены исследования зависимости от объемов текстовых фрагментов качества классификации текстов по авторству, по жан- ровым типам и источникам с помощью деревьев решений, метода Хмелева и метода с использованием нейронных сетей. Для эксперимента были взяты два набора текстов: художественных произведений (156 текстов, три подмножества: 30, 20 и 10 авторов) и газетных статей (5 697 текстов, 57 журналистов за 2003–2004 гг.). Рассмотрены количественные признаки трех уровней: уровня букв, слов и предложений. Всего 14 различных наборов признаков. Было обнаружено, что для разных текстов с разным числом классов, для разных наборов признаков существует примерно постоянное минимальное значение объема фрагментов для приемлемой классификации. Оно составляет около 30 000–40 000 символов, или 5 000–6 000 слов, или 400–600 предложений. Было предложено использовать нейронные сети, обучающиеся без учителя и предназначенные для обработки больших массивов многомерной информации, – самоорганизующиеся карты Кохонена (Self-organizing map – SOM). За последние годы это направление является одним из наиболее развивающихся. С помощью SOM-сетей решаются многие проблемы классификации, обработки естественного языка, изображений, тестирования и обучения. Несмотря на широкое использование, SOM-сетям не хватает теоретической обоснованности: в основном они опираются на эмпирические результаты. В итоге был получен вывод о том, что в случае удачного нахождения универсального набора характеристик можно обрабатывать любое число авторов и текстов (большие массивы информации). Достаточно постоянно модифицировать карту, добавляя новые произведения, и оценивать, как они взаимодействуют с ранее присутствующими. Проведенные эксперименты показали, что метод Хмелева и его модификации выигрывают как в скорости обучения, так и в качестве классификации. Нейронные сети дают сопоставимое качество, но сильно проигрывают в скорости. Деревья решений обеспечивают наихудшее качество классификации, но при этом дают наглядный вид решения и по ходу производят отбор самых информативных признаков. Одним из серьезных недостатков метода является невозможность прогнозирования успешного результата. Генетический поиск на заданном наборе текстов может никогда не найти хороший вариант для разделения характеристик. Нет никакого критерия того, в правильном ли направлении движется поиск, верно ли он делает скачки, нужную ли скапливает информацию об исследуемом пространстве. Исследователь сам должен производить мониторинг поиска. Кроме того, нет механизмов, определяющих, сколько времени осталось до конца работы алгоритма, до того момента, когда дальнейший поиск не принесет значимых результатов. Другой проблемой метода является его трудоемкость. Число загруженных текстов, которое напрямую влияет на качество поиска, требует больших ресурсов от вычислительной системы (большой объем памяти и мощный процессор). Для нахождения по-настоящему универсальных характеристик необходимо обработать не один десяток мегабайт текстов, чтобы можно было с уверенностью заявить об их универсальности. Система «Авторовед» Продолжение исследований по применению нейронных сетей в сочетании с методом опорных векторов при установлении авторства текстов нашло отражение в работах [14, 15]. Если задачу определения авторства сформулировать как задачу классификации, то одним из широко применяемых выходов является построение бинарного классификатора. Все тексты, включая обучающую часть выборки, разворачиваются в очень большой вектор, индексируемый словами. После этого имеются два множества точек из обучающей выборки в многомерном пространстве: принадлежащие данному автору и не принадлежащие ему. Для того чтобы разделить эти множества, нужно поделить пространство на две части. Самый простой способ сделать это – построить гиперплоскость. Такую гиперплоскость можно построить с помощью метода опорных векторов (SVM – Support Vector Machines). После этого для клас- сификации текста с неизвестным автором достаточно проверить, в какую часть пространства он попал. Помимо метода опорных векторов, в качестве инструментов для атрибуции текстов в работе [15] были выбраны искусственные нейронные сети архитектуры многослойный перцептрон (MLP) и сети каскадной корреляции (CCN). CCN позволяют снизить временные затраты на обучение по сравнению с перцептроном за счет алгоритма автоматического построения топологии сети. SVM является наиболее точным из существующих сегодня методов классификации и в то же время наименее затратным по времени. Итоговое решение об авторе текста принимается ансамблем классификаторов по принципу мажоритарного голосования. В качестве характерных признаков текста для описания авторского стиля было предложено брать наиболее частые триграммы символов и наиболее частые слова русского языка. Основные результаты проведенных исследований получены на корпусе, состоящем из 215 прозаических текстов 50 русских писателей. Тексты были взяты из электронной библиотеки М. Мошкова. Размер каждого текста составляет более 100 000 символов. Использовались выборки объемом 1 000–100 000 символов (200–20 000 слов). Количество обучающих примеров каждого автора бралось равным 3, для тестирования использовалось по одной выборке автора. Эксперименты по 2, 5 и 10 авторам показали, что наиболее информативными авторскими признаками являются ограничения в 300–700 наиболее частотных триграмм и 500 наиболее частых слов. Автора можно определить с точностью в среднем 95–98 % при объеме текстовой выборки 20 000–25 000 символов. При этом начиная с 10 000 символов машина опорных векторов показывает лучшие из трех исследуемых классифи- каторов результаты. Установлено, что использо- вание при идентификации автора комбинации частот букв русского языка, знаков пунктуации, наиболее частых триграмм символов и наиболее частых слов увеличивает точность идентификации в среднем на 6–12 % на объемах текста до 10 000 символов.
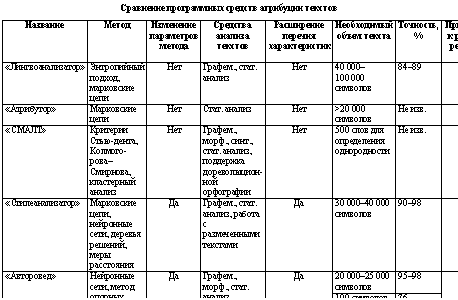
В заключение необходимо отметить, что в основе формальных методов атрибуции текстов лежит представление о том, что с возрастанием объема текста параметры, характеризующие авторский стиль, становятся устойчивыми с вероятностной точки зрения. Это позволяет устанавливать авторство по стабильно повторяющимся формальным характеристикам текста. Поэтому более высокое качество атрибуции достигается для текстов большого объема, а менее точный результат получается для текстов маленького объема. Открытым остается вопрос о выборе авторского инварианта (набора формальных параметров текста). Часто на практике решается ограниченный круг задач для предварительно заданного набора текстов. Настройка, тестирование и демонстрация инструментов анализа ориентированы только на эти тексты, и нет никакой гарантии, что методы будут эффективно справляться с задачей на других данных. Установив набор характеристик, исследователь сталкивается с проблемой их структуризации, в чем существенную помощь могут оказать классические статистические методы. С помощью факторного анализа и анализа главных компонент можно установить вклад той или иной характеристики в процесс распознавания автора, иерархический кластерный анализ позволит объединить отдельные характеристики в подгруппы, подгруппы в группы и т.д. Немалую помощь можно получить от нейронных сетей прямого распространения, если попытаться обучить сеть на наборе примеров, взяв в качестве входов отдельные характеристики, а затем оценивать, какое влияние оказывает тот или иной вход на систему выходов. Недостаточно исследованы зависимости качества классификации от объемов фрагментов и от числа классов. Наконец, имеющиеся программы анализа текстов не ориентированы на комплексное исследование и сравнение стилей текстов (для разных задач анализа стилей текстов с использованием различных частотных признаков, различного текстового материала и т.д.). Наиболее удачное сравнение доступных программных средств для определения авторства текстов есть в [15] и приведено в таблице. К проблемам, затрудняющим исследования в области атрибуции текстов, относится и составление выборки эталонных текстов. Желательно, чтобы произведения были подобраны следующим образом: тексты разных писателей в максимальной степени различаются, а тексты одного писателя максимально близки. Но было немало случаев, когда известный писатель в какой-то период своего творчества менял стиль изложения или произведения создавались в соавторстве. Эти факторы вызывают дополнительные сложности при решении задачи установления авторства. Необходимо проводить дальнейшие исследования, направленные на поиск новых или совершенствование уже имеющихся методов атрибуции текстов. Не менее важны эксперименты, целью которых является поиск характеристик, позволяющих четко разделять стили авторов, в том числе и на малых объемах выборки. Литература 1. Галяшина Е.И. Лингвистическая безопасность речевой коммуникации // ГЛЭДИС. URL: http://www.rusexpert.ru/magazine/034.htm (дата обращения: 02.10.2012). 2. Марусенко М.А. Атрибуция анонимных и псевдонимных литературных произведений методами теории распознавания образов. Л.: Изд-во ЛГУ, 1990. 164 с. 3. Родионова Е.С. Методы атрибуции художественных текстов // Структурная и прикладная лингвистика: межвуз. сб. СПб: Изд-во СПбГУ, 2008. Вып. 7. С. 118–127. 4. Марков А.А. Об одном применении статистического метода // Текстология.ru. URL: http://www.textology.ru/library/ book.aspx?BookId=8&textId=2 (дата обращения: 20.09.2012). 5. Фоменко В.П., Фоменко Т.Г. Авторский инвариант русских литературных текстов / В кн.: Новая хронология Греции: античность в cредневековье. М.: Изд-во МГУ, 1995. 422 с. 6. Хмелев Д.В. Классификация и разметка текстов с использованием методов сжатия данных. URL: http://compression.ru/download/articles/classif/intro.html (дата обращения: 21.09.2012). 7. Хмелев Д.В. Распознавание автора текста с использованием цепей А.А. Маркова // Вестн. МГУ. Сер. Филология. 2000. № 2. С. 115–126. 8. Кукушкина О.В., Поликарпов А.А., Хмелев Д.В. Определение авторства текста с использованием буквенной и грамматической информации // Проблемы передачи информации. 2001. Т. 37. № 2. С. 96–108. 9. Шевелев О.Г. Разработка и исследование алгоритмов сравнения стилей текстовых произведений: автореф. дис. … канд. техн. наук. Томск, 2006. 18 с. 10. Тимашев А.Н. Атрибутор // Текстология.ru. URL: http://www.textology.ru/atr_resum.html (дата обращения: 21.09.2012). 11. Рогов А.А., Сидоров Ю.В., Король А.В. Автоматизированная система обработки и анализа литературных текстов «СМАЛТ» // Русский язык: исторические судьбы и современность: тр. и матер. II Междунар. конгресса исследователей русского языка. М.: Изд-во МГУ, 2004. С. 485–486. 12. Морозов Н.А. Лингвистические спектры: средство для отличения плагиатов от истинных произведений того или дру- гого известного автора // Текстология.ru. URL: http://www.textology.ru/library/book.aspx?bookId=1&textId=3 (дата обращения: 25.09.2012). 13. Шевелев О.Г. Методы автоматической классификации текстов на естественном языке: учеб. пособие. Томск: ТМЛ-Пресс, 2007. 144 с. 14. Романов А.С., Мещеряков Р.В. Идентификация автора текста с помощью аппарата опорных векторов // Компьютерная лингвистика и интеллектуальные технологии: сб. докл. Междунар. конф. «Диалог 2009». М.: Изд-во РГГУ, 2009. Вып. 8. № 15. С. 432–437. 15. Романов А.С. Методика и программный комплекс для идентификации автора неизвестного текста: автореф. дис. … канд. техн. наук. Томск, 2010. 26 с. References 1. Galyashina E.I. GLEDIS. Available at: http://www.rusexpert.ru/magazine/034.htm (accessed 20 September 2012). 2. Marusenko M.A. Atributsiya anonimnykh i psevdonimnykh literaturnykh proizvedeniy metodami teorii raspoznavaniya obrazov [Attribution of anonymous and pseudonymous literary works using methods of the pattern recognition theory]. Leningrad State Univ. Publ., 1990, 164 p. (in Russ.). 3. Rodionova E.S. Strukturnaya i prikladnaya lingvistika: Mezhvuzovskiy sbornik [Structural and applied linguistics: Interuniv. collection]. 2008, iss. 7, pp. 118–127. 4. Markov A.A. Tekstologiya.ru [Textology.ru]. Available at: http://www.textology.ru/library/book.aspx?BookId=8&textId=2 (accessed 20 September 2012). 5. Fomenko V.P., Fomenko T.G. Novaya khronologiya Gretsii: Antichnost v Srednevekovye [New chronology of Greece: Antiquity in Medieval]. Moscow, Moscow State Univ. Publ., 1995, 422 p. (in Russ.). 6. Khmelyov D.V. Vsyo o szhatii dannykh, izobrazheny i video [All about compression of data, images and video]. Available at: http://compression.ru/download/articles/classif/intro.html (accessed 21 September 2012). 7. Khmelyov D.V. Vestnik MGU [Moscow University Philological Sciences Bulletin]. 2000, no. 2, pp. 115–126. 8. Kukushkina O.V., Polikarpov A.A., Khmelev D.V. Problemy peredachi informatsii [Problems of information transmission]. 2001, vol. 37, no. 2, pp. 96–108. 9. Shevelyov O.G. Razrabotka i issledovanie algoritmov sravneniya stiley tekstovykh proizvedeniy [Development and analysis of algorithms of texts styles comparing]. PhD thesis, Tomsk, 2006, 18 p. 10. Timashev A.N. Tekstologiya.ru [Textology.ru]. Available at: http://www.textology.ru/atr_resum.html (accessed 21 September 2012). 11. Rogov A.A., Sidorov Yu.V., Korol A.V. Trudy i materialy II Mezhdunar. kongressa issledovateley russkogo yazyka “Russkiy yazyk: istoricheskie sudby i sovremennost” [Proc. of the 2nd Int. Congress of researchers of Russian language “Russian language: historical destiny and contemporaneity”]. Moscow, MSU Publ., 2004, pp. 485–486. 12. Morozov N.A. Tekstologiya.ru [Textology.ru]. Available at: http://www.textology.ru/library/book.aspx?bookId=1&textId=3 (accessed 25 September 2012). 13. Shevelyov O.G. Metody avtomaticheskoy klassifikatsii tekstov na estestvennom yazyke: ucheb. posobie [Methods of automatic classification of texts in natural language: tutorial]. Tomsk, TML Press, 2007. 14. Romanov A.S., Meshcheryakov R.V. Kompyuternaya lingvistika i intellektualnye tekhnologii: Po materialam ezhegodnoy Mezhdunar. Konf. “Dialog 2009” [Computational linguistics and intelligent technology: based on annual Int. Conf. “Dialogue 2009”]. Moscow, RSUH Publ., 2009, iss. 8, no. 15, pp. 432–437. 15. Romanov A.S. Metodika i programmny kompleks dlya identifikatsii avtora neizvestnogo teksta [Method and software system to identificate the author of an unknown text]. PhD thesis, Tomsk, 2010. |
 Полученные методики были применены на практике для идентификации авторов коротких электронных сообщений во время внедрения программного комплекса, названного «Авторовед», в деятельность воинской части 51 952. Результаты показали, что авторство коротких текстов длиной 100 символов можно определить с точностью до 76±11 % в случае двух потенциальных авторов. При решении частной задачи по определению автора сообщения интернет-форума была достигнута точность 89±8 %. Таким образом, предложенный метод дает довольно хорошие результаты на коротких электронных сообщениях, что выгодно отличает его от других ранее предложенных методов.
Полученные методики были применены на практике для идентификации авторов коротких электронных сообщений во время внедрения программного комплекса, названного «Авторовед», в деятельность воинской части 51 952. Результаты показали, что авторство коротких текстов длиной 100 символов можно определить с точностью до 76±11 % в случае двух потенциальных авторов. При решении частной задачи по определению автора сообщения интернет-форума была достигнута точность 89±8 %. Таким образом, предложенный метод дает довольно хорошие результаты на коротких электронных сообщениях, что выгодно отличает его от других ранее предложенных методов.| Permanent link: http://swsys.ru/index.php?id=3703&lang=en&page=article |
Print version Full issue in PDF (7.95Mb) Download the cover in PDF (1.45Мб) |
| The article was published in issue no. № 4, 2013 [ pp. 286-295 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Применение байесовской сети в задаче классификации структурированной информации
- Метод частотно-морфологической классификации текстов
- Методы автоматической классификации текстов
- Интеллектуальная система автоматического определения категории потенциальных адресатов текста
- Построение корпуса текстов для настройки тонового классификатора
Back to the list of articles