Journal influence
Bookmark
Next issue
Numerical particle-in-cell code for CPU-GPU hybrid systems
The article was published in issue no. № 1, 2014 [ pp. 36-43 ]Abstract:The paper presents efficiency analysis of parallel programs for ions evolution analysis in particle-in-cell model. Parallel programs for hybrid computing systems with CPU (Central Processing Units, central processors) and GPU (Graphic Processing Units, graphic accelerators) devices were developed. The programs are applied for ions behavior direct modeling in mass spectrometers traps based on Fourier transform. The paper demonstrates the possibilities of using GPU for speeding-up repeated Poisson’s equation with Dirichlet boundary conditions solution, which is based on Fast Fourier Transform, that is implemented in cuFFT library – FFT procedures library for CUDA (Compute Unified Device Architecture). Effective performance and memory bandwidth are compared with GPU peak characteristics for different devices. The chosen algorithm scales according to its complexity estimate. The programs for trapping fields calculation between random shaped electrodes on hybrid systems with simultaneous CPU and GPU data processing were developed. Every parallel process of the field calculation program solves a system of linear equations using GPU with LAPACK procedures that are implemented in CULA library. Calculations on “Lomonosov” supercomputer show that parallel GPU usage efficiency significly depends on choosing of parallel program process distribution nodes. Accelerators can be efficiently used for finding coulomb interaction between ions with solution of Poisson’s equation boundary problem. Parallel computing of fields that inducted by every single surface on CPU can be done when solving linear equations systems on GPU achieving good efficiency.
Аннотация:В работе представлено исследование эффективности параллельных программ для расчета эволюции ионов в рамках модели частиц в ячейке. Разработаны параллельные программы для гибридных вычислительных систем, содержащих устройства CPU (Central Processing Units, центральные процессоры) и GPU (Graphic Processing Units, графические ускорители). Программы применяются для прямого моделирования поведения ионов в ловушках масс-спектрометров на основе преобразования Фурье. Показана возможность использования GPU-устройств для ускорения многократного решения краевых задач для уравнения Пуассона на основе быстрого преобразования Фурье, реализованного в библиотеке cuFFT – библиотеке процедур быстрого преобразования Фурье для архитектуры CUDA (Compute Unified Device Architecture). Проведено сравнение реально достигаемой производительности и задействования полосы пропускания памяти при вычислении решения с пиковыми характеристиками GPU для разных установок. Показано, что выбранный алгоритм решения первой краевой задачи для уравнения Пуассона масштабируется в соответствии с асимптотической оценкой сложности. Разработаны программы расчета полей, удерживающих ионы в ловушке в произвольной геометрии электродов для работы на гибридных системах, сочетающих в себе одновременную обработку данных на CPU и GPU. В каждом из параллельных процессов программы расчета поля решение алгебраических уравнений осуществляется на GPU через процедуры LAPACK, реализованные в составе библиотеки CULA. Результаты расчетов на суперкомпьютере «Ломоносов» показали, что эффективность параллельного исполь-зования GPU существенно зависит от выбранной схемы распределения процессов параллельной программы. Ускорители могут эффективно использоваться для определения кулоновского взаимодействия ионов с помощью решения первой краевой задачи для уравнения Пуассона. Параллельные вычисления полей на CPU от каждой поверхности электрода можно проводить совместно с решением алгебраических систем на GPU с достаточной эффективностью.
| Authors: Popova N.N. (popova@cs.msu.su) - Lomonosov Moscow State University, Moscow, Russia, Ph.D, Nikishin N.G. (truecoldfault@gmail.com) - Lomonosov Moscow State University, Moscow, Russia | |
| Keywords: lapack, computing systems, cula, cufft, cuda, graphics accelerators, gpu, hybrid systems cpu-gpu |
|
| Page views: 9715 |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
Системы, основанные на использовании GPU (Graphic Processing Units, графических ускорителей), привлекают особое внимание исследователей [1]. Быстрое развитие программного и аппаратного обеспечения, позволяющего использовать графические ускорители для вычислений общего назначения [2], ставит вопрос об эффективности применения таких систем для моделирования больших молекулярных структур, особенно для разработок в сфере нанотехнологий [3]. При исследовании поведения заряженных частиц в электрических и магнитных полях широко распространена модель частиц в ячейках [4]. Очень важным приложением такой модели является программное моделирование в области масс-спектроскопии. Так, масс-спектрометры на основе ионного циклотронного резонанса и преобразования Фурье являются лидирующими устройствами в области определения масс для задач протеомики. Для прямого моделирования поведения ионов в таких установках, а также для исследования физических эффектов, влияющих на точность работы этих устройств, cоздан целый ряд программ [5, 6]. В них расчет парного кулоновского взаимодействия частиц осуществляется через вычисление на трехмерной разностной сети коллективного самосогласованного поля, покрывающего объем ловушки экспериментальной установки. Поиск такого поля проводится на каждом шаге по времени с помощью решения задачи для уравнения Пуассона. Для удовлетворительной точности необходимо порядка миллиона временных шагов, поэтому требование быстрого решения является ключевым. Наиболее часто применяемый здесь метод основан на использовании быстрого преобразования Фурье [5]. С помощью данного подхода были созданы параллельные программы для расчета подобных задач на суперкомпьютерах, в частности на суперкомпьютере IBM Blue Gene/P, установленном на факультете вычислительной математики и кибернетики (ВМК) Московского государственного университета им. М.В. Ломоносова (МГУ). Однако желательно иметь возможность моделирования таких задач еще и на многоядерных системах с использованием вычислительных ресурсов GPU. В настоящей работе для решения краевой задачи для уравнения Пуассона используются различные графические ускорители и библиотека cuFFT для быстрого преобразования Фурье. При этом основное внимание уделяется тому, насколько применяемые устройства позволяют ускорить вычисления на основе модели частиц в ячейке. Также исследуется эффективность нахождения решения для различных параметров задачи и асимптотической сложности алгоритма. Основная программа является параллельной и написана на языке Fortran. В ней расчет внешних удерживающих полей на разностной сетке от системы электродов произвольной формы реализован на основе параллельных алгоритмов решения пограничных интегральных уравнений [6]. В конечном счете задача сводится к решению алгебраической системы уравнений с плотной матрицей. В настоящей работе решение системы находится с использованием библиотеки CULA, реализующей ряд процедур пакета LAPACK на основе технологии NVIDIA CUDA. Альтернативой данной библиотеке может служить библиотека MAGMA, разрабатываемая в университете штата Теннесси, Ноксвилл (США). Полноценное сравнение MAGMA и CULA не входит в задачи этой работы. Расчеты осуществлялись на системах с различными GPU, в том числе на суперкомпьютере «Ломоносов» НИВЦ МГУ, где имеется возможность использования гибридных вычислительных систем с CPU (Central Processing Units) и GPU. Система позволяет реализовывать различные стратегии распределения параллельных процессов по CPU-устройствам с параллельным выполнением части задач на GPU. В работе проведено сравнение различных схем такого распределения. Постановка задачи моделирования эволюции частиц в ячейке Рассмотрим модель частиц в ячейке при моделировании поведения многих ионов в ловушках различных установок, в частности масс-спектрометра [5]. Для определения траекторий частиц требуется решить N уравнений Ньютона для каждой частицы под действием силы Лоренца:
где электрическое поле E определяется по вычисленным потенциалам: utrap(ri) – первый член в правой части – по потенциалу удерживающего поля ловушки; urf(ri, t) – последний член в правой части – по потенциалу поля возбуждения (заданного по времени); uc(ri, t) – третий член – по кулоновскому потенциалу парного взаимодействия частиц, который необходимо рассчитывать на каждом шаге по времени. Обозначим через uwall значение потенциала на стенках электродов. Тогда имеем соотношения:
В методе частица-сетка есть два раздела вычислений, которые являются наиболее трудоемкими и требуют специальных модулей в программе. В первом разделе рассчитываются силы парного кулоновского взаимодействия частиц. Особенность задачи при моделировании масс-спектрометра заключается в том, что необходимо моделировать эволюцию большого числа ионов (порядка миллиона) в течение нескольких миллионов шагов по времени. Во втором разделе вычисляется удерживающее ионы поле ловушки, создаваемое системой раздельных электродов сложной формы. Определение кулоновского взаимодействия ионов с помощью решения краевой задачи для уравнения Пуассона Для избежания попарного вычисления взаимодействий между частицами в модели частиц в ячейке вводится пространственная трехмерная разностная сетка (xk, yl, zm). В рассматриваемой области потенциал кулоновского поля определяется плотностью заряда r(ri, t), который, в свою очередь, вычисляется на сетке при помощи интерполяции зарядов частиц qi, находящихся внутри ячейки, в узлы данной разностной сети:
Здесь Vol – объем ячейки; Wk,l,m – веса интерполяции, величина которых зависит от положения частицы относительно узла (k, m, l). Тогда коллективный потенциал кулоновского поля uc находится из решения первой краевой задачи для уравнения Пуассона на пространственной сетке:
по найденному потенциалу вычисляется сила, действующая на все ионы внутри ячейки:
В результате количество действий для учета парного взаимодействия меняется с O(Np×Np) на O(Np×M), где M – число ячеек сети. Количество рассматриваемых частиц должно быть велико по сравнению с размерностью пространственной сетки. Это требуется для того, чтобы избежать флуктуаций силы при переходе через границы ячеек. Обычно берут порядка ста частиц на одну ячейку. Таким образом, решение первой краевой задачи для уравнения Пуассона (3) на пространственной сетке является ключевым для расчета сил парного взаимодействия частиц. Переформулируем задачу (3) для трехмерной разностной сети размера N1´N2´N3, равномерно покрывающей прямоугольную область [0, L1]´[0, L2]´[0, L3]. Тогда координаты узлов сетки задаются следующими выражениями: xi=khi, i=1, 2, 3, (5) где hi=Li/Ni – шаги разностной сетки по каждому из направлений. Сама задача примет вид:
Здесь Программная реализация решения задачи Дирихле на основе cuFFT Для вычисления коллективного потенциала кулоновского поля действий на языке NVIDIA CUDA C (расширение языка C/C++) был написан модуль, содержащий три процедуры. Первая процедура включает в себя инициализацию работы с графическим ускорителем, выделение необходимой памяти, вычисление собственных значений для дальнейшего использования в программе. Вторая предназначена для решения задачи Дирихле на GPU с использованием дискретного преобразования Фурье. Использование именно Фурье-преобразования для решения этой задачи существенно, так как соответствует принципам работы реальных устройств масс-спектроскопии. Третья процедура завершает работу с картой, освобождая всю выделенную память. Предполагается, что инициализация и завершение работы с ускорителем вынесены за пределы временного цикла, чтобы избежать повторных вычислений. Взаимодействие с основной программой осуществляется через отдельный интерфейсный модуль, обеспечивающий возможность вызова процедур, описанных на языке C, из основной программы на Fortran. Для гарантии соответствия типов при его описании использовались именованные константы, предоставляемые модулем ISO_C_BINDING, который входит в стандарт Fortran 2003. Внутри главной процедуры решения уравнения для осуществления преобразования Фурье используются вызовы библиотеки cuFFT версии 5.5 из состава окружения CUDA Toolkit. Особенность использования этой библиотеки в том, что она не содержит процедур для синус-преобразований, которые в данном случае необходимы для того, чтобы полученное решение удовлетворяло нулевым граничным условиям. Поэтому для получения нужного результата применимы следующие соображения. Расширяем сеточную функцию в два раза по каждому из направлений, продолжив ее нечетно относительно границ трехмерной области. Применив к расширенной функции дискретное преобразование Фурье, получим результат, на исходном множестве эквивалентный применению синус-преобразования. Таким образом, процедура решения будет состоять из следующих этапов. 1. Пересылка значений r из основной оперативной памяти в память GPU. 2. Переупорядочение массива этих значений из расположения по столбцам, принятого в Fortran, на расположение по строчкам, принятое в C. 3. Нечетное продолжение сеточной функции r на вдвое большую область по каждому из направлений, что влечет за собой увеличение количества элементов в массиве в восемь раз. 4. Прямое преобразование Фурье продолженной сеточной функции. 5. Деление всех мнимых частей (только они ненулевые) полученного образа на собственные значения разностной задачи. 6. Обратное преобразование Фурье образа решения. 7. Нормировка каждого из элементов результирующего массива на общее количество элементов в нем. 8. Обратное переупорядочение массива по столбцам. 9. Пересылка части массива, соответствующего полученному решению u на исходной области, из памяти GPU в основное ОЗУ. Разделим условно процедуру решения на две части. К первой отнесем прямое и обратное преобразования Фурье, а также деление на собственные числа. Будем считать, что непосредственно к вычислению решения относятся только эти шаги. Остальные действия отнесем ко второй части, которую можно рассматривать как подготовку данных.
Nop=2NFFT+(2Ng)3, NFFT=5(2Ng)3log2((2Ng)3), (6) где Nop – общее количество операций; NFFT – количество операций, необходимое для реализации алгоритма быстрого преобразования Фурье над массивом комплексных чисел. Общая асимптотическая сложность составляет Оценка эффективности используемых систем с GPU и программной реализации алгоритма Тестирование программы проводилось на нескольких системах с различными GPU. Для технических характеристик карт, полученных через CUDA runtime API, рассчитываются следующие величины: BWtheor – максимально возможная пропускная способность памяти; Они вычисляются по формулам:
При проведении тестов измерялось время решения задачи для уравнения Пуассона на каждом шаге и вычислялось среднее по 100 шагам. Про- ведено сравнение вычислений с точным аналитическим решением. Решение считалось удовлетворительным, если абсолютная ошибка составляла величину ~10–5. Время оценивалось при помощи интерфейса CUDA event API, содержащего функции управления событиями и позволяющего вычислить время между двумя событиями в программе. Для оценки производительности программ с использованием GPU обычно используют две метрики: BWeff – достигнутая пропускная способность памяти и Perfeff – достигнутая производительность [7]. Первая метрика рассчитывается по следующей формуле:
где RB – количество прочитанных данных в байтах; WB – количество записанных. В нашем случае RB=WB=N3, то есть требуются чтение сеточной функции rh и запись ответа uh. Достигнутая производительность определяется соотношением
Чтобы мультипроцессоры карты были достаточно загружены обработкой элементов, не будем рассматривать сетки с N<32. Время решения за- дачи в зависимости от числа точек (одинаковое число точек по каждому из направлений) на устройстве GeForce GTX TITAN для одинарной и двойной точности (усреднение по 100 шагам по времени) показано в таблице 1. Таблица 1 Время решения задачи Дирихле на устройстве GeForce GTX TITAN
Эти данные можно аппроксимировать в смысле наименьших квадратов. Результат представлен на рисунке 1. С увеличением размера задачи накладные расходы начинают играть все меньшую роль и на первый план выходит вычислительная составляющая. Время вычисления решения составляет от 50 до 70 % от общего и растет с увеличением размера задачи. В таблице 2 показано отношение времени, затраченного непосредственно на вычисление решения, к общему времени выполнения процедуры, включающему пересылку и подготовку данных. Таблица 2 Доля вычислений от общего времени решения задачи одинарной точности на GeForce GTX TITAN
Сравнение эффективности решения задачи Дирихле, пиковой и достигнутой пропускной способности памяти, пиковой и достигнутой производительности на GeForce GT 640, Tesla C2075 и GeForce GTX TITAN на разных устройствах было проведено для характерного для задачи числа точек по каждому из направлений (усреднение по 100 итерациям для решения задачи с одинарной точностью Ng=128). Соответствующие результаты приведены в таблице 3. Таблица 3 Сравнение времени решения задачи
Из таблицы видно сильное превосходство ускорителей GeForce GTX TITAN и Tesla C2075 над GeForce GT 640 по количеству потоковых мультипроцессоров (14 против 2) и по пропускной способности памяти, что находит свое отражение в результатах, сокращая время вычисления в 2–3 раза. Кроме того, GeForce GTX TITAN за счет большего количества ядер на мультипроцессоре показывает лучшие, чем Tesla C2075, результаты. Анализ вычисленных метрик позволяет заключить, что при выбранном количестве точек сети порядка 1,7×107 пиковая производительность GPU-устройств не достигается. Для достижения пиковой производительности требуется на 2 порядка больше данных. И такие задачи могут возникать при обработке больших БД экспериментальных измерений. Но в данном случае выбиралось разумное количество точек сети для серийных расчетов по модели частиц в ячейках. Такое количество данных еще допускается широтой пропускания памяти. В данном случае широта пропускания не используется полностью. Это объясняется тем, что после чтения исходных данных каждый раз приходится останавливаться для того, чтобы подготовить их для преобразования Фурье. Остановка включает в себя транспонирование и расширение массива в 8 раз – «тяжелые» операции для памяти GPU, обладающей высокой латентностью. Это оказывает влияние на достигнутую вычислительную производительность. В зависимости от ускорителя она составляет от 44 до 150 Гфлопс, что соответствует 4–10 % от пиковой. Но, несмотря на не самый оптимальный для использования всех ресурсов GPU алгоритм, задача решается достаточно быстро для использования в приложениях. Определение потенциалов удерживающего поля от электродов произвольной формы Перейдем к вычислению потенциала поля от незамкнутых электродов произвольной формы. Оно проводится с помощью потенциала двойного слоя. Для этого требуется решить уравнение Лапласа DV=0 (10) с граничными условиями первого рода на электродах, окружающих ловушку:
где k=1, 2, …, K – номер поверхности электрода; Uk – заданный постоянный потенциал на каждой поверхности. Ищем решение в виде потенциала двойного слоя:
Здесь P – точка на поверхности S; M – точка наблюдения (точка трехмерной разностной сети, покрывающей объем ловушки);
где U1 – известный потенциал только на единственной поверхности 1. Подход к решению задачи со многими поверхностями (10)–(11) состоит в поиске решения как суммы потенциалов двойного слоя Wk, создаваемого каждой поверхностью:
Неизвестные дипольные моменты vk(P) на каждой поверхности дают решение задачи – потенциал V(M). После определения vk(P) подставляем дипольные моменты в выражение для Wk:
Дипольные моменты vk(P) получаются из граничного условия для потенциала двойного слоя, когда точка M сначала помещается на первую поверхность Внешняя часть поверхности является отталкивающей, а внутренняя притягивающей.
В этой форме в левой части оставляем интегрирование только по поверхности k (точка P), при этом точка наблюдения потенциала Таким образом, переписываем систему уравнений в форме
со следующей правой частью:
Решение системы интегральных уравнений для системы поверхностей на гибридных вычислительных системах c CPU и GPU После написания квадратур для интегралов полная система для набора поверхностей (17) может быть переписана в форме алгебраических уравнений. Обозначим интегралы для поверхности n после дискретизации как
где F учитывает квадратурную формулу; N1, N2 – число сеточных точек по двум напрвлениям; Пусть s – номер итерации, тогда получаем следующую итерационную процедуру:
Здесь правая часть известна с предыдущей итерации. Ее первый член – заданный поверхностный потенциал, а второй найден на предыдущем шаге и представляет собой влияние других поверхностей на распеделение дипольного момента с номером n0. Главным преимуществом этой формы является возможность независимого решения уравнений для каждой поверхности, что важно для параллельных вычислений. Каждое уравнение переписываем в форме алгебраической системы
где Y – линейный вектор решения; Ф – линейный вектор известной правой части; На любой итерации алгоритма электрический потенциал, индуцированный на каждой поверхности электрода, может быть вычислен независимо. Это делается параллельно для всех поверхностей с номерами ns=1, 2, …, m. Для этого в программе порождается m+1 MPI-процесс, каждый из которых соответствует своей поверхности ns, за исключением процесса с номером 0. На каждой итерации определяются поля, индуцированные собственной поверхностью процесса на всех других поверхностях с номерами nd. Поля обозначаются как Vind(ns, nd). Эти поля посылаются в нулевой процесс и складываются. Там же определяется и полное поле, индуцированное всеми электродами. Затем индуцированное поле на каждом электроде ns посылается обратно на соответствующий вычислительный процесс с номером ns и определяется новая правая часть в уравнениях. На новой итерации используется модифицированное граничное условие для каждой поверхности. В каждом MPI-процессе, выполняемом на CPU, требуется решать алгебраическую систему уравнений (20) со своей матрицей и правой частью. В программе это решение проводится с помощью GPU-устройств параллельно для каждой поверхности. Схема параллельного алгоритма показана на рисунке 2. Решение алгебраических систем уравнений на каждой поверхности с помощью библиотеки CULA на GPU При параллельном вычислении полей от каждой поверхности электрода решение алгебраической системы выполняется на устройствах GPU с использованием библиотеки CULA версии R17 для плотных матриц. Параметры задачи выбраны так, что алгебраическая система уравнений (20) имеет матрицу размера N1´N2, N1=N2=N=35, 45, 55, 65, 75.
1. Двадцать MPI-процессов распределяются по одному процессу на вычислительное ядро процессора. Доступ к каждому из GPU осуществляется одновременно с нескольких процессов. Для осуществления такой стратегии достаточно трех узлов суперкомпьютера. 2. Каждый из 20 MPI-процессов запускается на своем вычислительном узле.
По второй схеме каждый процесс получает доступ к GPU сразу, без ожидания и выполняет подзадачи одного процесса до получения окончательного ответа. В таблице 4 показаны среднее время решения СЛАУ при использовании первого и второго вариантов и отношение этих значений. Чем больше параллельно обращающихся к одному GPU процессов, тем сильнее разброс времени возвращения из процедуры решения. Время выполнения процедуры решения СЛАУ в зависимости от условного номера параллельного процесса при характерном числе точек в матрице N=65 показано на рисун- ке 4. В каждом параллельном процессе на CPU используется GPU для решения алгебраической системы уравнений. Для сравнения показано также время решения при использовании лишь одной видеокарты GeForce GT 740M (+). Таблица 4 Сравнение среднего времени решения СЛАУ одним процессом при использовании первого и второго вариантов
Таким образом, задача моделирования работы масс-спектрометров на основе ионного циклотронного резонанса и преобразования Фурье может быть решена на гибридных системах. В заключение отметим, что в статье представлены результаты реализации кода Pic3D частиц в ячейке для моделирования работы масс-спектрометров на основе ионного циклотронного резонанса и преобразования Фурье на гибридных системах с CPU и GPU.
В настоящее время происходят интенсивное распространение и развитие технологий для GPGPU, что выражается в частом обновлении архитектур и, как следствие, в появлении новых возможностей. В качестве примера здесь можно привести появление функций Hyper-Q в последней версии архитектуры NVIDIA Kepler. Возможность повышения эффективности параллельного использования графических ускорителей за счет новых свойств представляет немалый интерес и требует особого исследования. Литература 1. Chapman B., Desprez F., Joubert G.R., Lichnewsky A., Peters F., Priol T. (Eds.). Parallel Computing: From Multicores and GPU’s to Petascale. Elsevier Science, IOS Press., 2010, vol. 19, 739 p. 2. Wilt N. The CUDA Handbook, A Comprehensive Guid to GPU Programming, Peatson Education, Inc, 2013, 494 p. 3. Попов A.M. Вычислительные нанотехнологии. М.: МАКС Пресс, 2009. 280 с. 4. Хокни Р., Иствуд Дж. Численное моделирование методом частиц. М.: Мир, 1987. 640 с. 5. Nikolaev E.N., Heeren Ron M.A., Popov A.M., Realistic modeling of ion cloud motion in a Fourier transform ion cyclotron resonance ctll by use of a particle-in-ctll approach, Rapid Communication in Mass Spectrometry, 2007, vol. 21, is. 22, pp. 3527–3546. 6. Misharin A., Popov A. Parallel numerical code “parTfield” to simulate ion optical elements for any electrode geometry. Proc. 60th ASMS Conf. on Mass Spectrometry, 2012, May 20–24, Vancouver, Canada. 7. Malony A.D., Biersdorff S., Shende S., Jagode H., To- mov S., Juckeland G., Dietrich R., D. Poole, Lamb Ch. Parallel Performance Measurement of Heterogeneous Parallel Systems with GPUs, Parallel Processing (ICPP), Intern. Conf., 2011, pp. 176–185. References 1. Chapman B., Desprez F., Joubert G.R., Lichnewsky A., Peters F., Priol T. Parallel Computing: From Multicores and GPU’s to Petascale. Elsevier Science, IOS Press., 2010, vol. 19, 739 p. 2. Wilt N. The CUDA Handbook. A Comprehensive Guid to GPU Programming. Peatson Education Publ., 2013, 494 p. 3. Popov A.M. Vychislitelnye nanotekhnologii [Computing nanotechnologies]. Moscow, MAKS Press, 2009, 280 p. 4. Hockney R.W., Eastwood J.W. Computer Simulation Using Particles. Taylor & Francis Publ., 1989, 540 p. 5. Nikolaev E.N., Heeren Ron M.A., Popov A.M. Realistic modeling of ion cloud motion in a Fourier transform ion cyclotron resonance ctll by use of a particle-in-ctll approach. Rapid Communication in Mass Spectrometry. John Wiley & Sons Publ., 2007, vol. 21, iss. 22, pp. 3527–3546. 6. Misharin A., Popov A. Parallel numerical code “parTfield” to simulate ion optical elements for any electrode geometry. Proc. of the 60th ASMS Conf. on Mass Spectrometry. May 20–24, 2012, Vancouver, Canada. 7. Malony A.D., Biersdorff S., Shende S., Jagode H., To- mov S., Juckeland G., Dietrich R., D. Poole, Lamb Ch. Parallel Perfomance Measurement of Heterogeneous Parallel Systems with GPUs. Int. Conf. on Parallel Processing (ICPP). 2011, pp. 176–185. |

 (1)
(1) (2)
(2) (3)
(3) (4)
(4)
 и rh – сеточные функции, заданные значениями функций uc и r в узлах сетки; Dh – разностная аппроксимация трехмерного оператора Лапласа.
и rh – сеточные функции, заданные значениями функций uc и r в узлах сетки; Dh – разностная аппроксимация трехмерного оператора Лапласа.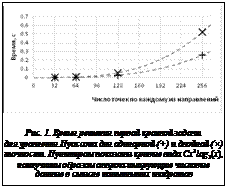 Предположив, что исходная трехмерная сетка содержит Ng узлов по каждому из направлений, оценим количество операций с плавающей точкой для осуществления первой части по следующим формулам:
Предположив, что исходная трехмерная сетка содержит Ng узлов по каждому из направлений, оценим количество операций с плавающей точкой для осуществления первой части по следующим формулам: .
. – пиковая производительность на операциях с одинарной точностью;
– пиковая производительность на операциях с одинарной точностью;  – пиковая производительность на операциях с двойной точностью. Эти параметры зависят только от характеристик ускорителей.
– пиковая производительность на операциях с двойной точностью. Эти параметры зависят только от характеристик ускорителей. (7)
(7) (8)
(8) (9)
(9) , Тфлопс
, Тфлопс , Тфлопс
, Тфлопс (11)
(11) (12)
(12) – расстояние между точками P и M; np – нормаль к поверхности в точке P; vp – неизвестная поверхностная плотность дипольного момента, различная на каждой поверхности. Для любой vp потенциал W(M) удовлетворяет уравнению Лапласа по переменной M. На поверхности данный потенциал имеет разрыв. Если мы имеем только одну поверхность, то условие (11) приводит к следующему интегральному уравнению для неизвестной плотности момента v(P):
– расстояние между точками P и M; np – нормаль к поверхности в точке P; vp – неизвестная поверхностная плотность дипольного момента, различная на каждой поверхности. Для любой vp потенциал W(M) удовлетворяет уравнению Лапласа по переменной M. На поверхности данный потенциал имеет разрыв. Если мы имеем только одну поверхность, то условие (11) приводит к следующему интегральному уравнению для неизвестной плотности момента v(P): (13)
(13) (14)
(14) (15)
(15) (первое уравнение), затем на вторую поверхность
(первое уравнение), затем на вторую поверхность  (второе уравнение), k-ю поверхность
(второе уравнение), k-ю поверхность  (k-е уравнение) и т.д. Таким образом получаем систему уравнений для дипольных моментов vk(P) на каждой поверхности. vk(P) определяются граничными условиями, а именно значениями Uk на каждой поверхности и потенциалами, наведенными другими поверхностями. В каждом уравнении один из интегралов в сумме имеет сингулярность. Это происходит при i=k и при равенстве соответствующих координат точек
(k-е уравнение) и т.д. Таким образом получаем систему уравнений для дипольных моментов vk(P) на каждой поверхности. vk(P) определяются граничными условиями, а именно значениями Uk на каждой поверхности и потенциалами, наведенными другими поверхностями. В каждом уравнении один из интегралов в сумме имеет сингулярность. Это происходит при i=k и при равенстве соответствующих координат точек  В численной схеме такие члены c интегрируемой особенностью должны иметь специальную аппроксимацию.
В численной схеме такие члены c интегрируемой особенностью должны иметь специальную аппроксимацию. (16)
(16) тоже находится на этой поверхности. В правой части уравнения имеются два члена. Первый член – приложенный потенциал на поверхности k, второй – сумма потенциалов от всех поверхностей Si в системе, которые индуцируют электрическое поле на данной поверхности (точка
тоже находится на этой поверхности. В правой части уравнения имеются два члена. Первый член – приложенный потенциал на поверхности k, второй – сумма потенциалов от всех поверхностей Si в системе, которые индуцируют электрическое поле на данной поверхности (точка  (17)
(17) (18)
(18) , (19)
, (19) – решение для n-й поверхности.
– решение для n-й поверхности.

 (20)
(20) – матрица, включающая геометрические характеристики электродов. Так как матрица является плотной, для решения можно использовать соответствующие стандартные процедуры библиотеки LAPACK.
– матрица, включающая геометрические характеристики электродов. Так как матрица является плотной, для решения можно использовать соответствующие стандартные процедуры библиотеки LAPACK.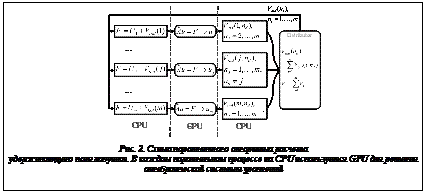 Расчеты проводились на суперкомпьютере «Ломоносов». Каждый из вычислительных узлов суперкомпьютера оборудован двумя 4-ядерными CPU и двумя GPU Tesla X2070, по характеристикам аналогичными Tesla C2070. Это позволяет использовать различные стратегии распределения параллельных процессов по узлам. Были использованы две схемы (рис. 3).
Расчеты проводились на суперкомпьютере «Ломоносов». Каждый из вычислительных узлов суперкомпьютера оборудован двумя 4-ядерными CPU и двумя GPU Tesla X2070, по характеристикам аналогичными Tesla C2070. Это позволяет использовать различные стратегии распределения параллельных процессов по узлам. Были использованы две схемы (рис. 3).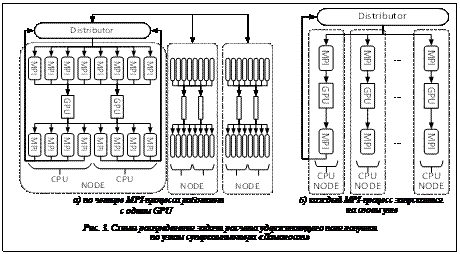 При использовании первой схемы несколько процессов конкурируют за ресурсы GPU, каждое из которых единовременно может выполнять лишь один CUDA-контекст, соответствующий одному MPI-процессу. При этом процедура решения СЛАУ в CULA немонолитна и разбивается на некоторое количество подзадач, что позволяет переключать контексты нескольких процессов по мере необходимости. Накладные расходы на такие переключения сокращаются при увеличении размеров обрабатываемых данных.
При использовании первой схемы несколько процессов конкурируют за ресурсы GPU, каждое из которых единовременно может выполнять лишь один CUDA-контекст, соответствующий одному MPI-процессу. При этом процедура решения СЛАУ в CULA немонолитна и разбивается на некоторое количество подзадач, что позволяет переключать контексты нескольких процессов по мере необходимости. Накладные расходы на такие переключения сокращаются при увеличении размеров обрабатываемых данных.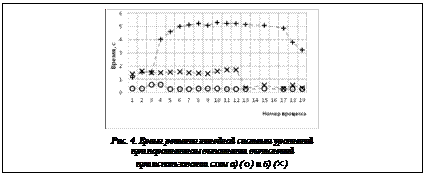 Вычисления показывают, что ускорители могут быть использованы для определения кулоновского взаимодействия ионов с помощью решения первой краевой задачи для уравнения Пуассона и параллельного вычисления полей от каждой поверхности электрода через решение алгебраических систем с достаточной эффективностью. Эффективность параллельного использования GPU существенно зависит от выбранной схемы распределения процессов параллельной программы.
Вычисления показывают, что ускорители могут быть использованы для определения кулоновского взаимодействия ионов с помощью решения первой краевой задачи для уравнения Пуассона и параллельного вычисления полей от каждой поверхности электрода через решение алгебраических систем с достаточной эффективностью. Эффективность параллельного использования GPU существенно зависит от выбранной схемы распределения процессов параллельной программы.| Permanent link: http://swsys.ru/index.php?id=3755&lang=en&page=article |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
| The article was published in issue no. № 1, 2014 [ pp. 36-43 ] |
Perhaps, you might be interested in the following articles of similar topics: