Journal influence
Bookmark
Next issue
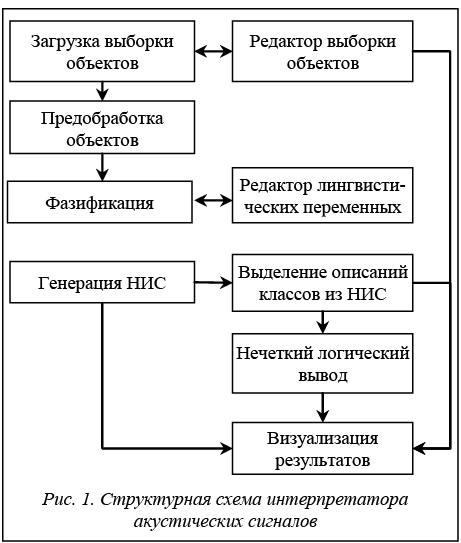
Signals interpreter based on neural-like hierarchical structure
The article was published in issue no. № 1, 2014 [ pp. 92-97 ]Abstract:The article considers the possibility of applying hybrid system that integrates a strategy of neural network models and methods of processing data to create fuzzy classification rules and interpret acoustic signals using developed in-terpreter. Acoustic signals interpreter is based on the idea of growing pyramidal network that is adapted for working with fuzzy descriptions of objects. Class models in constructed network are interpreted in fuzzy statements that serve as a set of production rules for a fuzzy logic conclusion. The production rules are presented as understandable verbal terms for expert. The paper discusses program implementation of the interpreter. It also describes an algorithm for constructing hierarchical neural structure and the production rules forming procedure. The article presents the results of testing a software implementa-tion of the interpreter in actual recordings of acoustic signals (respiratory noises and a voice signals).
Аннотация:Рассматривается возможность применения гибридной системы, интегрирующей стратегии нейросетевых моделей и методы обработки нечетких данных для построения классификационных правил и интерпретации акустических сигналов с помощью разработанного интерпретатора. Интерпретатор акустических сигналов основан на идее растущей пирамидальной сети, адаптированной для работы с нечеткими описаниями объектов. Модели классов, со-держащиеся в построенной сети, интерпретируются в нечеткие высказывания, которые служат набором продукци-онных правил для нечеткого логического вывода. Продукционные правила представляются в понятных эксперту вербальных терминах. В статье рассматривается программная реализация интерпретатора, описываются алгоритм построения нейроподобной иерархической структуры и процедура формирования продукционных правил, приводятся результаты апробации программной реализации интерпретатора на реальных записях акустических сигналов, представленных дыхательными шумами и речевыми сигналами.
| Authors: Filatova N.N. (nfilatova99@mail.ru) - Tver State Technical University, Tver, Russia, Ph.D, Khaneev D.M. (nfilatova99@mail.ru) - Tver State Technical University, Tver, Russia, Sidorov K.V. (nfilatova99@mail.ru) - Tver State Technical University, Tver, Russia | |
| Keywords: test set, learning sample, production rule, fuzzy set, acoustic signal, growing pyramidal networks, neural-like hierarchical structure, software, interpreter |
|
| Page views: 13127 |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
В последние полтора-два десятилетия существенно повысился интерес к средствам интерпретации различных сигналов, отражающих физио- логические процессы, протекающие в организме человека. Для большинства из них характерны нестационарность, высокая степень зависимости от методики записи сигналов, неточная локализация точек регистрации, что увеличивает субъективность регистрируемых зависимостей. Большой интерес вызывают методы и средства анализа акустических сигналов как результатов неинвазивных и наиболее быстрых методик исследования [1]. В данной работе рассматривается возможность применения гибридной системы [2], интегрирующей стратегии нейросетевых моделей и методы обработки нечетких данных для построения классификационных правил и интерпретации акустических сигналов с помощью разработанного интерпретатора. В интерпретатор загружаются реальные записи акустических сигналов, на основе которых формируется представление вторичных признаков. Вторичные признаки приводятся к нечеткому виду, что позволяет создавать правила классификации сигналов в понятных эксперту вербальных терминах. Правила строятся путем интерпретации закономерностей, содержащихся в нейроподобной иерархической структуре, построенной в процессе обучения. Каждое правило представляют собой нечеткую модель одного из классов сигналов. Полученные продукционные правила проходят проверку у эксперта. Программная реализация интерпретатора
Модуль предобработки сигналов предназначен для первичной обработки данных, включающей фильтрацию, нормализацию, автоматическое определение оптимального значения параметров аттрактора, восстановленного из исследуемого акустического сигнала, расчет аттрактора и спектральной плотности мощности, формирование на основе аттрактора вектора вторичных признаков. Результатом работы модуля является вектор X, представляющий сигнал набором дискретных признаков. Модуль фазификации осуществляет преобразование вектора X в лингвистическую шкалу и переход к нечетким признакам. Модуль генерации НИС предназначен для построения графовой модели (G) классов обучающей выборки (ОВ). Структура G отражает связи между приз- наками объектов ОВ. Модуль выделения описа- ний классов из НИС предназначен для выделения наборов продукционных правил из построен- ной НИС. Модуль нечеткого логического вывода решает задачу классификации с помощью построенных продукционных правил и вычисляет значение функции соответствия объекта описанию класса. Алгоритм генерации нейроподобной иерархической структуры Алгоритм построения НИС представлен в работе [3]. НИС является развитием идей растущих пирамидальных сетей [4] и представляет собой ориентированный ациклический граф в ярусно параллельной форме, не имеющий вершин с одной заходящей дугой, все дуги ориентированы от нижних уровней к верхним. Все вершины сети делятся на два типа: рецепторы и ассоциативные элементы. Рецепторы являются входами сети и расположены на нулевом уровне иерархии. Вершина сети считается возбужденной, если возбуждены все смежные с ней вершины предшествующего уровня. Первоначально сеть состоит из рецепторов, соединенных исходящими дугами с заключительной вершиной верхнего уровня Y, которая выполняет вспомогательную роль в процессе генерации сети. Каждому терму лингвистической переменной признака ставится в соответствие входной рецептор, в результате чего их количество равно суммарному числу термов всех признаков. Каждый ассоциативный элемент характеризуется следующими параметрами: уровень в иерархии сети; состояние (возбужденное/невозбужденное); класс, породивший данный элемент; число рецепторов l, от которых существует путь к нему; значения счетчиков возбуждений mcl1–mclk, которые определяют реакцию вершины на входные объекты ОВ классов cl1–clk соответственно, где k – количество классов, представленных в ОВ. Построение НИС выполняется в два последовательных этапа. На первом этапе формируются конъюнктивные зависимости значений признаков. Ввод новых вершин реализован последовательным выполнением правил PK1 и PK2 после подачи очередного объекта на вход сети.
Правило PK2. Из графа выделяется множество возбужденных вершин Ve (ассоциативные элементы и рецепторы), уровень иерархии которых ниже предпоследнего. Далее рассматривается каждая вершина vi множества Ve. Если у vi нет смежных возбужденных вершин, расположенных на следующем уровне иерархии, vi добавляется в множество S и выполняется переход к следующей вершине vi+1 множества Ve. По окончании просмотра множества Ve в сеть добавляется новый ассоциативный элемент vn. На вход vn заводятся дуги от вершин множества S, причем у элементов из множества S ликвидируются исходящие дуги к вершине Y. Исходящей дугой vn соединяется с заключительной вершиной верхнего уровня сети Y. В результате построений первого этапа ассоциативные элементы, смежные с вершиной Y, образуют множество Vc, с каждым элементом которого ассоциируется объект из ОВ с уникальными комбинациями значений нечетких признаков. Множество Vc полностью описывает все объекты ОВ. На втором этапе алгоритм выделяет из пирамид с вершинами в множестве Vc минимально возможное количество контрольных элементов. Контрольные элементы представляют собой ассоциативные элементы с наиболее часто встречающимся набором значений признаков, характерных для объектов определенного класса. Принцип выделения контрольных элементов описан далее. На вход сети поочередно подаются объекты ОВ, после подачи объекта происходит распространение возбуждения по всем вершинам, в ходе которого корректируются значения параметров вершин mcl1–mclk и l. Затем из всех ассоциативных элементов сети выбирается множество контрольных элементов по следующим условиям (в порядке приоритетности): 1) у ассоциативного элемента заполнен только один из счетчиков mcl1–mclk; 2) максимальное значение счетчика mclj среди других ассоциативных элементов сети, где j – класс, представляемый данной вершиной; 3) максимальное значение счетчика l. Все найденные вершины заносятся во множество контрольных элементов сети. Вершины сети предпоследнего уровня (рис. 2), смежные с заключительной вершиной Y (U1–Un), образуют множество Vc, и каждая из них характеризует группу близких объектов с одинаковой комбинацией значений признаков HПp. Ассоциативные элементы K1, K2, K3 являются контрольными вершинами классов с номерами 1, 2 и 3 соответственно. HП1, HП2, …, HПp – нечеткие признаки (p=1, 2, …, P – порядковый номер нечеткого признака, где P – количество нечетких признаков). Продукционные правила для каждого класса выделяются на основе анализа его контрольных элементов. Рецепторы, из которых имеется путь к контрольному элементу, объединяются конъюнктивной связью Для каждого класса из множества его Интерпретация дыхательных шумов Выборки дыхательных шумов (ДШ) получены с помощью устройства регистрации 3M Littmann 4100, а также из открытых источников (база примеров патологий фирмы 3M). Все записи имеют частотный диапазон 0–4 кГц, частоту дискретизации 8 000 Гц, разрешение 16 бит. Запись ДШ с помощью устройства 3M Littmann 4100 производилась у здоровых людей и у пациентов с патологическими изменениями функции дыхания в трех точках корпуса, выделенных в соответствии с принятыми методиками аускультации. ДШ субъективно классифицированы экспертом (врачом высокой квалификации с хорошим состоянием органов слуха) на два класса: НОРМА, ПАТОЛОГИЯ. В качестве разделяющих признаков выбраны спектральные характеристики сигнала. Выбор обоснован тем, что для определенных видов ДШ характерен определенный частотный состав. Каждый объект ДШ анализируется в частотном диапазоне 185–2 000 Гц с шагом 11 Гц и рассматривается в виде описания из признаков спектральной плотности мощности (СПМ), рассчитывающихся по методу Уэлча с применением оконного быстрого преобразования Фурье: S(v)ДШ=áS1, S2, …, Sbñ, PX=áPx1, Px2, …, Pxuñ, (1) где S(v) – вектор признаков СПМ; v – номер объекта; b – номер признака СПМ, b=1, …, 163; Pxi – ордината спектра мощности на частоте fi=Dx×i; xi соответствует одному признаку; Dx – шаг по частоте; Dx=fx/Fw; fx – частота дискретизации; Fw – ширина окна FFT. Для построения НИС использована ОВ из 32 объектов, иллюстрирующих классы НОРМА и ПАТОЛОГИЯ (рис. 3). С помощью НИС созданы два правила, наибольший интерес представляет описание класса ПАТОЛОГИЯ (табл. 1). Таблица 1 Детализация составляющих правила по значимости (на примере класса ПАТОЛОГИЯ)
Для каждого класса в соответствии с продукционным правилом вычисляется степень принадлежности для объекта. Объект ассоциируется с тем классом, степень принадлежности к которому выше среди других классов.
Следует отметить, что использование графиков СПМ в качестве объектов классификации позволяет НИС выделить (при формировании правил) наиболее информативные интервалы частот. При классификации СПМ в качестве основной гипотезы H0 принято утверждение «Объект принадлежит классу НОРМА», следовательно, будем считать отнесение объекта с диагнозом НОРМА к классу ПАТОЛОГИЯ ошибкой первого рода, а отнесение объекта с диагнозом ПАТОЛОГИЯ к классу НОРМА – ошибкой второго рода. Результаты классификации ДШ по ОВ (32 объекта) и тестовой выборке (ТВ) (37 объектов) представлены в таблице 2. Таблица 2 Результаты классификации ДШ
Из результатов распознавания интерпретатором ДШ видно, что имеются ошибки второго рода, но при этом общий уровень успешности классификации довольно высокий. Интерпретация эмоций в речевых сигналах Для построения классификатора эмоций, проявляющихся в естественной речи, была сформирована база русской эмоциональной речи, состоящая из 210 фраз различных дикторов. При создании базы в качестве испытуемых выступили 16 человек (11 мужчин и 5 женщин) в возрасте от 18 до 27 лет. Для активизации эмоций (положительных и отрицательных) применялись видеостимулы, сопровождающиеся звуковыми дорожками. Для объективного подтверждения изменения эмоций у каждого испытуемого регистрировалась 19-канальная электроэнцефалограмма (ЭЭГ), позволяющая в реальном времени отслеживать изменение электрической активности головного мозга при восприятии стимулов разного знака.
Регистрация образцов РС осуществлялась микрофоном «Genius» (частотный диапазон 50 Гц–20 кГц; импеданс 2,2 кОм; чувствительность –60±4 дБ). Образцы РС продолжительностью до 3 секунд сохранялись в файлах формата PCM (.wav) с частотой дискретизации 22 050 Гц и разрешением 16 бит. Для съема ЭЭГ использовался компьютерный энцефалограф-анализатор «Энцефалан-131-03». Образцы ЭЭГ продолжительностью по 1 минуте сохранялись в файлах формата (.EEG, .ASCII) с частотой дискретизации 250 Гц. В работе использованы признаки на основе реконструкции аттрактора (максимальные векторы аттрактора по четырем квадрантам), определяемые по результатам двухмерной проекции [5]:
t=0, 1, …, s–1, s=N–(m–1)t, где Rj(i) – максимальный вектор аттрактора в j-м квадранте, j=1, …, 4; i – номер объекта, i=1, 2, …, M; M – количество объектов; N – число точек временного ряда; t – задержка по времени между элементами временного ряда; m – размерность вложения. Каждый объект РС описывается в виде вектора из 5 признаков аттрактора и 300 признаков СПМ (анализируется частотный диапазон 2–5 кГц):
где A(l), S(l) – вектор признаков аттрактора и СПМ; l – номер объекта, l=1, …, 210; k – номер признака СПМ, k=1, …, 300. В таблице 3 приведены составы ОВ и ТВ, где КЛАСС 1 – положительные эмоции; КЛАСС 2 – нейтральное состояние; КЛАСС 3 – отрицательные эмоции (рис. 5). Таблица 3 Структура ОВ и ТВ РС
На основе анализа ОВ созданы варианты НИС, получены правила классификации. Их применение к ОВ и ТВ иллюстрирует таблица 4. Таблица 4 Результаты классификации РС
Полученные результаты показали довольно высокую точность классификации эмоционально окрашенных образцов речи при разных способах их описания. Применение аттракторов позволяет снизить ошибку классификации. В заключение подчеркнем, что ядро програм- много комплекса (модули предобработки, фазификации, генерации НИС, выделения описаний классов из НИС, нечеткого логического вывода) является инвариантным к предметной области и может рассматриваться как универсальный компонент для проектирования интерпретаторов различных сигналов. Литература 1. Rangayyan R.M. Biomedical Signal Analysis: A Case-Study Approach. Wiley IEEE Press, NY, 2002, 516 p. 2. Колесников А.В. Гибридные интеллектуальные системы: Теория и технология разработки. СПб: СПбГТУ, 2001. 711 с. 3. Ханеев Д.М., Филатова Н.Н. Пирамидальная сеть для классификации объектов, представленных нечеткими признаками // Изв. ЮФУ: сер.: технич. науки. 2012. № 9 (134). С. 45–49. 4. Гладун В.П. Растущие пирамидальные сети // Новости искусственного интеллекта. 2004. № 1. С. 30–40. 5. Сидоров К.В., Филатова Н.Н. Применение методов нелинейной динамики для распознавания эмоции радости в речи // Науч.-технич. вестн. информ. технологий, механики и оптики. 2012. № 5 (81). С. 110–114. References 1. Rangayyan R.M. Biomedical signal analysis: a case-study approach. Wiley IEEE Press, NY, 2002, 516 p. 2. Kolesnikov A.V. Gibridnye intellektualnye sistemy: Teoriya i tekhnologiya razrabotki [Gibrid intelligent systems: a theory and development technology]. St. Petersburg, St. Petersburg State Polytech. Univ. Publ., 2001, 711 p. 3. Khaneev D.M., Filatova N.N. Pyramidal network to classify objects that presented by fuzzy features. Izvestiya YuFU. Tekhnicheskie nauki [Izvestiya SFedU. Engeneering Sciences]. 2012, no. 9 (134), pp. 45–49. 4. Gladun V.P. Growing pyramidal networks. Novosti iskusstvennogo intellekta [News of artificial intelligence]. 2004, no. 1, pp. 30–40. 5. Sidorov K.V., Filatova N.N. Using methods of nonlinear dynamics to joy emotion recognition in a speech. Nauch.-tekhnich. vestnik inform. tekhnologiy, mekhaniki i optiki [Scientific and Technical Journ. of Information Technologies, Mechanics and Optics]. 2012, no. 5 (81), pp. 110–114. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Правило PK1. Из графа выделяется множество невозбужденных ассоциативных элементов Vd, которое сортируется по условию возрастания уровня вершины в иерархии сети. Далее рассматривается очередная вершина vt множества Vd, у которой выделяются смежные возбужденные вершины, расположенные на предыдущем уровне иерархии, и заносятся в множество Va. Если мощность множества Va меньше двух, выполняется переход к следующей просматриваемой вершине vi+1, иначе в сеть вводится новый ассоциативный элемент vn. Дуги от вершин из множества Va к vi ликвидируются, и вместо них вводятся дуги, соединяющие вершины из Va с новой вершиной vn. Выход нового элемента vn соединяется исходящей дугой с входом vi. Уровни всех вершин, к которым существуют пути из нового ассоциативного элемента vn, рекурсивно повышаются на 1 (граф приводится к ярусно-параллельной форме), выполнение правила прерывается. Переход правила к следующей вершине осуществляется только при условии, что выполнение правила для предыдущей вершины не изменило структуру сети.
Правило PK1. Из графа выделяется множество невозбужденных ассоциативных элементов Vd, которое сортируется по условию возрастания уровня вершины в иерархии сети. Далее рассматривается очередная вершина vt множества Vd, у которой выделяются смежные возбужденные вершины, расположенные на предыдущем уровне иерархии, и заносятся в множество Va. Если мощность множества Va меньше двух, выполняется переход к следующей просматриваемой вершине vi+1, иначе в сеть вводится новый ассоциативный элемент vn. Дуги от вершин из множества Va к vi ликвидируются, и вместо них вводятся дуги, соединяющие вершины из Va с новой вершиной vn. Выход нового элемента vn соединяется исходящей дугой с входом vi. Уровни всех вершин, к которым существуют пути из нового ассоциативного элемента vn, рекурсивно повышаются на 1 (граф приводится к ярусно-параллельной форме), выполнение правила прерывается. Переход правила к следующей вершине осуществляется только при условии, что выполнение правила для предыдущей вершины не изменило структуру сети. , где C – номер класса, n – номер контрольного элемента класса.
, где C – номер класса, n – номер контрольного элемента класса.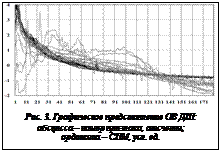 Детализация логического вывода продукционного правила победившего класса по объекту позволяет выделить подгруппы внутри классов, а также ядро класса. Из таблицы 1 видно, что подправила 3, 4, 5, 6 покрывают большую часть объектов ОВ и представляют собой ядро класса ПАТОЛОГИЯ.
Детализация логического вывода продукционного правила победившего класса по объекту позволяет выделить подгруппы внутри классов, а также ядро класса. Из таблицы 1 видно, что подправила 3, 4, 5, 6 покрывают большую часть объектов ОВ и представляют собой ядро класса ПАТОЛОГИЯ.

 (2)
(2)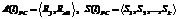 , (3)
, (3)| Permanent link: http://swsys.ru/index.php?id=3765&lang=en&page=article |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
| The article was published in issue no. № 1, 2014 [ pp. 92-97 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Алгоритм классификации графиков с последовательным укрупнением признаков
- Автоматическая система обнаружения и распознавания автотранспортных средств на изображении
- Метод создания параллельных программных средств моделирующих комплексов военного назначения
- Повышение скорости логического вывода продукционных экспертных систем путем использования аспектно-ориентированного подхода
- Алгоритм детектирования объектов на фотоснимках с низким качеством изображения
Back to the list of articles