Journal influence
Bookmark
Next issue
The technique and framework for dynamic vulnerabilities detection in binary executables
Abstract:The article introduces an original technique for binary executables security analysis that allows analyzing ne t-work applications security using fuzz testing which is effective for software bugs detection. Vulnerable network applications are a tremendous threat to network communications security. Vulnerabilities in web browsers and server software can cause a disastrous effect. A good example of it is HeartBleed critical vulnerability in OpenSSL TLS implementation that allows an unauthenticated remote attacker to retrieve critical data from a connected client or server. The technique uses a combination of dynamic binary instrumentation, code coverage analysis, potential erroneous data generation and results analysis. The author also presents a new way to assess effectiveness of each test iteration using code coverage visualization. In the second part the author describes a technique implementation as a software framework that al-lows detecting vulnerabilities in network and file – based applications with high-level of visualization and testing automatiza-tion. In addition, the author conducted a large-scale experimental evaluation of the system on 17 different network applications for different operation systems. The results of the experiment confirmed that system suit s well for vulnerability detection in modern applications. Moreover, the experiments helped detect several previously unknown vulnerabilities in the popular and wide-spread applications.
Аннотация:В работе дается описание оригинальной методики для динамического анализа уязвимостей в бинарном коде, которая позволяет проводить тестирование различных приложений, взаимодействующих в сети. Уязвимые сетевые программные продукты представляют огромную угрозу для безопасности различных информационных систем. Уязвимости в web-браузерах или в серверном программном обеспечении могут иметь серьезные последствия. Отличный пример – критическая уязвимость «HeartBleed», обнаруженная в реализации TLS OpenSSL и позволяющая злоумышленнику удаленно и без авторизации получать критическую информацию, в том числе закрытые ключи пользователей на уязвимом сервере. Для решения описанной проблемы используется сочетание технологий динамической бинарной инструментации, анализа покрытия кода и так называемого фаззинга – технологии генерации потенциально ошибочных данных и мо-ниторинга результата. Подход позволяет проводить итеративный анализ для заданного сетевого приложения в тестовой среде с использованием средств виртуализации. Для повышения качества тестирования в работе представлен новый подход к эффективному анализу каждой тестовой итерации с использованием анализа покрытия кода, оценки сложности участка выполненного кода с их после-дующей визуализацией. Описывается реализация методики в виде единого программного комплекса, позволяющего проводить поиск уязвимостей в сетевых и файловых приложениях со значительным уровнем производительности и автоматизации тестирования. Помимо этого, приводится экспериментальная оценка эффективности предложенного решения на 17 тестовых приложениях для различных операционных систем. В результате экспериментов были найдены две ранее неизвестные уязвимости в нескольких популярных приложениях, что подтверждает эффективность использования методики и программного комплекса для решения задачи поиска уязвимостей в бинарном коде.
| Authors: Shudrak M.O. (mxmssh@gmail.com) - Academician M.F. Reshetnev Siberian State Aerospace University, Krasnoyarsk, Russia | |
| Keywords: vulnerabilities detection, dynamic analysis, dynamic binary instrumentation, code coverage, fuzzing |
|
| Page views: 8766 |
Print version Full issue in PDF (6.61Mb) Download the cover in PDF (0.95Мб) |
Процесс разработки ПО невозможен без тех или иных ошибок, допускаемых программистами или архитекторами будущего программного продукта. Эти ошибки, в свою очередь, могут порождать серьезные проблемы, связанные с безопасностью вычислительных систем, в которых функционирует такой продукт. Наряду с ошибками в программном коде разработчики по тем или иным причинам могут оставлять программные закладки в своих продуктах для их будущего использования в различных целях. Достаточно показательным примером такой деятельности может служить кампания Агентства Национальной Безопасности США по внедрению программных закладок в межсетевые экраны корпорации CISCO.
Применение анализа бинарного кода во многом обусловлено высоким уровнем распространения проприетарного ПО, исходный код которого в большинстве случаев недоступен. Это особенно актуально для России в связи с высоким уровнем интеграции ПО зарубежного производства для обработки и защиты информации ограниченного доступа. Для решения этой проблемы существует ряд методик по проведению тестирования ПО, в том числе на предмет отсутствия недекларируемых возможностей. К сожалению, все эти методики оперируют с исходным кодом программного продукта и не предусматривают анализ безопасности исполняемых модулей. Даже при наличии исходного кода существует опасность того, что преобразования, выполняемые компилятором и различными оптимизаторами, могут значительно изменить поведение приложения, тем самым сделав результаты анализа недостоверными. В зарубежной литературе эта проблема названа «What You See Is Not What You eXecute» [1]. Таким образом, необходимость анализа безопасности бинарного кода обусловлена рядом вышеописанных факторов, которые могут порождать серьезные последствия, связанные с доступностью, целостностью или конфиденциальностью информации, обработку которой осуществляет уязвимый программный код. В последние годы для решения вышеописанных проблем стали активно применять методику динамического анализа, базирующегося на некоторых знаниях о тестируемом объекте, которые могут быть получены в результате его предварительного анализа. Динамический анализ предусматривает поиск ошибок и уязвимостей в исполняемом в какой-либо среде программном коде. Одно из главных преимуществ такого анализа – низкий уровень ошибок первого рода. Однако данный подход снижает покрытие кода и создает проблему полной имитации среды функционирования приложения, в рамках которой возникает та или иная ошибка. Для эксперта динамический анализ дает возможность получать информацию о конкретных функциях и их значениях в программе, запущенной на исполнение в целевой среде. Так, существует ряд реализаций [2, 3], выполняющих трансляцию бинарного кода в промежуточный язык с его последующим исполнением. Такой подход даeт возможность достаточно эффективно внедрять дополнительные функции в код для получения необходимой информации о ходе анализа и называется динамической бинарной инструментацией. Целью первого этапа динамического анализа является получение формата входных данных, обрабатываемых тестируемым кодом. Затем на основе полученной информации производится генерация потенциально ошибочных данных и выполняется их передача тестируемому приложению. Каждая итерация такого анализа сопровождается мониторингом тестируемого приложения на предмет появления в нeм исключительных ситуаций. Эта методика впервые была использована для тестирования Unix-программ Бартоном Миллером в 1988 году и названа термином «fuzz testing», или «fuzzing» [4]. В своей работе Миллер использовал генерацию псевдослучайных данных и передачу их тестируемому приложению в UNIX-системе. В русскоязычной литературе термин «fuzzing» получил распространение в транслитерации и записывается как фаззинг. В данной работе он будет употребляться в таком виде. В дальнейшем методика получила довольно широкое развитие и сегодня используется для тестирования широкого типа приложений, выполняющих обработку файловых структур, взаимодействующих с пользователями через интерфейс. При этом генерация потенциально ошибочных данных не ограничена псевдослучайными последовательностями, а включает в себя развитый аппарат формального описания протокола генерации данных, низкоуровневого анализа бинарного кода данных и мониторинга результатов. Многие эксперты считают, что на данный момент фаззинг является наиболее эффективной методикой для анализа бинарного кода [5]. Однако, несмотря на это, называют и один из самых весомых недостатков этой методики – существенную зависимость производительности от скорости обработки тестовых данных в анализируемом приложении и производительности монитора покрытия кода. Данная работа является продолжением предыдущих работ автора в области поиска уязвимостей и направлена на повышение производительности и эффективности методики автоматизированного поиска уязвимостей в бинарном коде. Динамический анализ бинарного кода Эффективная методика динамического анализа бинарного кода должна базироваться на некоторых знаниях о тестируемом объекте, которые могут быть получены в результате его предварительного анализа. Как уже было сказано, подавляющее большинство ошибок и уязвимостей в програм- мном коде появляются в результате некорректной обработки пользовательских данных. Таким образом, цель любого анализа заключается в получении формата входных данных, обрабатываемых тестируемым приложением. Затем на основе полученной информации необходимо провести тестирование, используя методику фаззинга. Каждая итерация такого анализа сопровождается мониторингом тестируемого приложения на предмет появления в нeм исключительных ситуаций. Общий алгоритм тестирования представлен на рисунке 1.
Для оценки покрытия кода важным параметром является граф потока управления (ГПУ), представленный в виде следующей четверки: CFG = (V, E, s, e), sÎV, e ÎV, где V – множество вершин, представляющих собой линейный блок на участке анализируемого кода; E Î V ´ V – множество дуг; s – входная вершина; e – выходная вершина; E(G) – множество дуг графа G; start(G) – входная вершина графа G; end(G) – выходная вершина графа G. Необходимо отметить, что ГПУ имеет лишь один вход и один выход. Путь в графе может быть представлен как упорядоченная последовательность номеров вершин. Определим через start(P) и end(P) начальную и конечную вершины пути P. Определим множество всех тестов для программы как T = {t1, t2, …, tn}, где n – количество тестовых итераций. Для оценки полноты покрытия кода тестовыми данными определим множество всех вершин во всех возможных CFG программы как M. Затем определим покрытие как множество сi = {Vi¢}, где сi – покрытие кода тестовыми данными в ГПУ для одной тестовой итерации ti; Vi¢ – множество всех вершин в CFG, кроме пройденных в ходе предыдущих тестов. Тогда общее покрытие кода в рамках тестирования запишется как множество P = {c1, c2, …, cn}, где n – количество генераций тестовых данных. Для определения эффективности тестирования дадим определение завершенности тестирования программы в виде Необходимо учитывать, что, чем выше уровень покрытия кода тестовыми данными, тем эффективнее фаззинг без учета эффективности подбора самих тестовых данных и алгоритма их мутации или генерации. Помимо этого, для получения актуальной оценки покрытия кода необходимо проводить динамическую бинарную инструментацию (ДБИ) каждого линейного блока в ГПУ для каждой тестовой итерации. Под инструментацией следует понимать процесс внедрения специального кода, отслеживающего факт передачи управления, перед каждым входом в линейный блок в рамках ГПУ (рис. 2).
Отдельно необходимо остановиться на оценке покрытия. Как было показано выше, процесс генерации тестовых данных должен обеспечиваться измеримым показателем эффективности. На сегодняшний день существует достаточно эффективный комплекс различных метрик для оценки сложности исходного кода, однако в рамках бинарного кода их применение крайне ограничено. Решением этой проблемы является декомпиляция бинарного кода для достижения некоторого уровня абстракции кода от его машинного представления. Согласно теореме Райса, декомпиляция в общем виде является алгоритмически неразрешимой задачей [6], однако в рамках данной работы нет необходимости в полноценном высокоуровневом аналоге, достаточно лишь провести частичную декомпиляцию, восстановив алгоритм функционирования участка анализируемого кода, и тем самым добиться необходимого уровня абстракции.
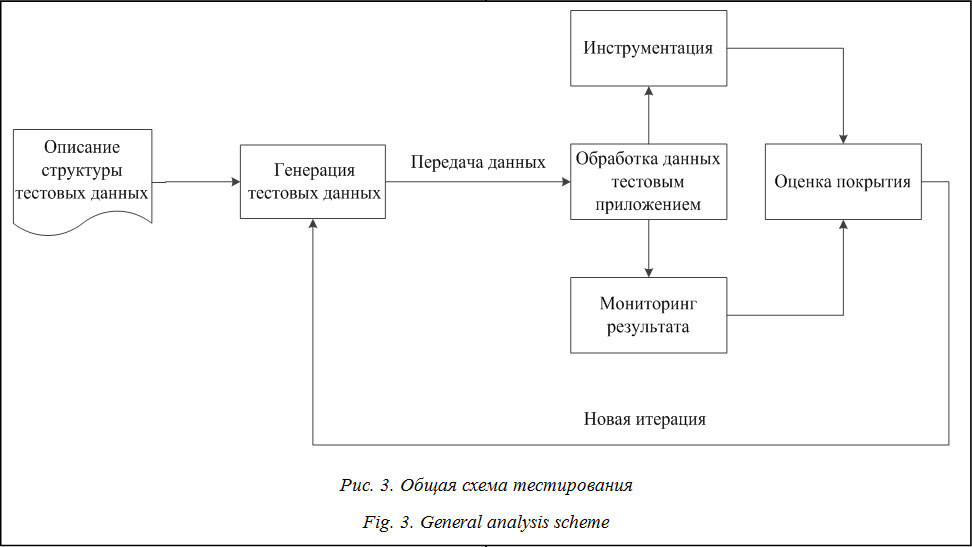
- количественные метрики, применяемые для количественной оценки некоторых единиц в программе; в рамках работы применяются метрики оценки количества строк кода (LOC), метрика Джилба и ABC-метрика; - метрики сложности потока управления, применяемые для оценки сложности ГПУ; в рамках работы применяются метрики оценки цикломатической сложности ГПУ, метрика Харрисона и Мейджела, метрика Пивоварского, метрика Шнейдевинда, а также метрика граничных значений; - метрики оценки сложности потока данных программы, позволяющие не только проводить анализ управляющих конструкций программы, но и учитывать обращения приложения к данным; для этого применяются метрика Спена, метрика Генри и Кафура, метрика Овиедо и Чепина; - гибридные метрики, позволяющие сочетать преимущества нескольких типов метрик и проводить оценку сложности покрытого кода как на основе количественных показателей, так и путем анализа управляющих конструкций в графе [8]. Реализация методики Рассмотрим практическую реализацию методики автоматизированного поиска уязвимостей. Как было показано в предыдущем разделе, для формирования тестовых данных необходимо использовать формальный язык описания протокола тестирования. В данной работе используется формальный язык для описания тестовых данных «Sulley», специально разработанный для тестирования приложений рабочей группой Университета Тулейна (США) и позволяющий описывать процедуру анализа с необходимым уровнем детализации [9]. Приведем пример описания тестирования приложения по протоколу FTP: (1) s_initialize(“ServerDATA”) (2) s_group(“commands”,values=[“TRUN”,”EXIT”] (3) s_block_start(“CommandBlock”, group=”commands”) (4) s_delim(‘’) (5) s_string(‘fuzz’) (6) s_static(‘\r\n’) (7) s_block_end() В данном примере описан формат генерации данных для двух команд FTP-протокола. Строки 1–3 инициализируют эти команды, а 4–7 описывают блоки, над которыми необходимо производить мутацию данных. Система анализа формального языка производит разбор описанного протокола и генерацию тестовых данных, которые затем передаются в тестируемое приложение. Общая схема тестирования бинарного кода, предложенная в рамках данной работы, представлена на рисунке 3. Согласно представленному алгоритму, на первом этапе описывается структура тестовых данных, а затем на основании этой структуры производится генерация теста с мутацией потенциально небезопасных участков и передачей этих данных приложению. Тестируемое приложение выполняет обработку потенциально небезопасных данных, а параллельно выполняются мониторинг приложения на предмет исключительных ситуаций, а также инструментация ГПУ. Полученные результаты используются для оценки покрытия кода тестовыми данными, после чего выполняется новая итерация анализа.
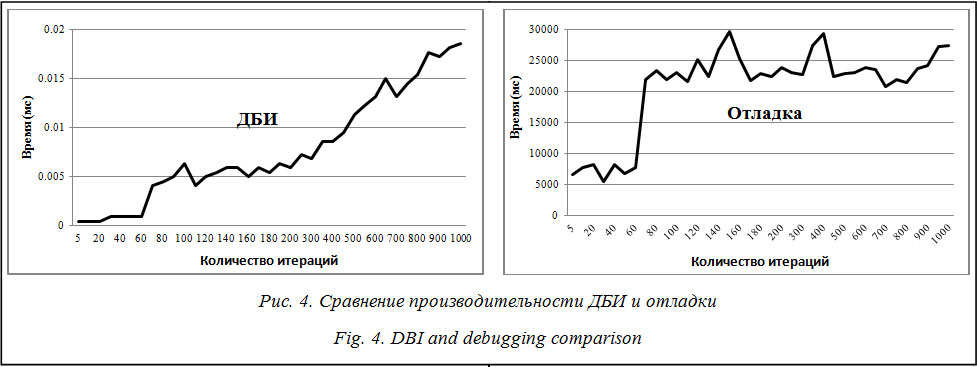
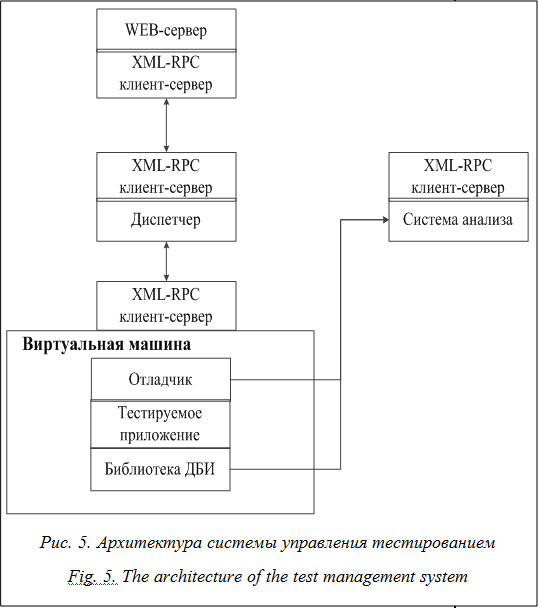
В ходе работы для сравнительной оценки эффективности технологий ДБИ и отладки было разработано тестовое приложение, которое выполняет некоторое вычисление (вычисление хеш-суммы по алгоритму SHA-1) заданное число раз. Сравнение эффективности решений приведено на рисунке 4. Стоит отметить, что показанное на рисунке превосходство на несколько порядков производительности ДБИ над отладкой объяснимо тем, что процесс установки флага TF и переключение контекста на отладчик является крайне затратной по времени операцией и не может использоваться для инструментации большинства приложений. Для оценки эффективности описанные в рамках работы решения были объединены в единый программный комплекс, управление которым реализовано через web-интерфейс (рис. 5). Реализация описанной на рисунке 5 архитектуры позволяет практически полностью автоматически разворачивать тестовые стенды в виде виртуальных машин с функционирующим в ней анализируемым приложением. Одним из самых важных требований, предъявляемых к системе, является возможность еe использования в различных операционных системах. Для этого было принято решение максимально (где это возможно) использовать кроссплатформенный язык программирования Python, а где невозможно – C/C++. Такой выбор продиктован тем, что наряду со своими широкими возможностями язык Python позволяет легко интегрироваться в проекты на C/C++.
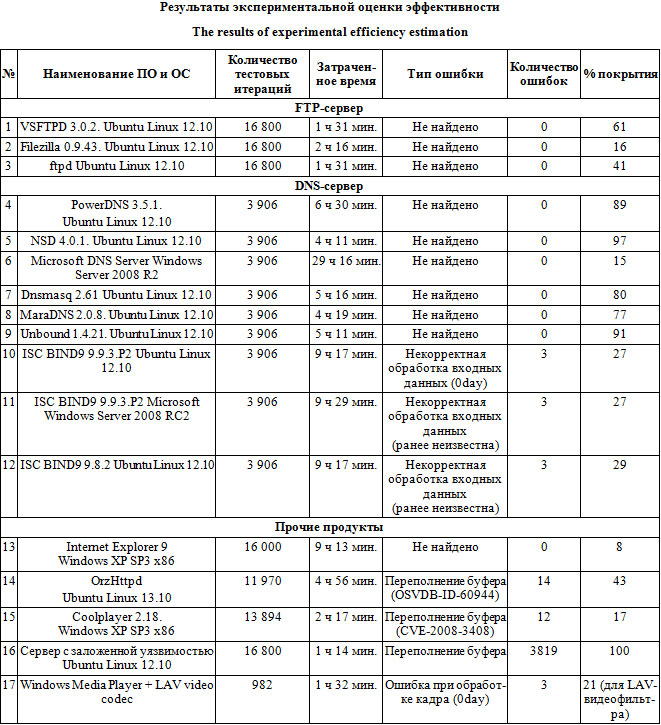
Согласно таблице, были развернуты и настроены по умолчанию 17 тестовых стендов. В качестве анализируемых приложений выбрано ПО различного уровня распространения. В ходе тестирования комплекс успешно обнаружил уязвимости в приложении собственной разработки с заранее известной уязвимостью и уже известные уязвимости в устаревших программных продуктах. Наиболее значительным результатом эксперимента является также факт обнаружения двух ранее неизвестных уязвимостей в популярных программных продуктах. Первая уязвимость была обна- ружена в свободно распространяемом видеофильтре LAV, она возникла при некорректной обработке ширины видеокадра. Так как ошибка не является критичной, официальный номер в международной базе уязвимостей CVE присвоен ей не был, а разработчик уведомлен об уязвимости в частном порядке.
В итоге можно отметить, что проведенный в ходе работы критический анализ методов динамического поиска уязвимостей в бинарном коде показал существующие недостатки с точки зрения производительности и генерации тестовых данных. В рамках работы для повышения эффективности тестирования было предложено использовать динамическую бинарную инструментацию оценки покрытия кода. Для генерации данных предложено использовать формальный язык описания протокола тестирования. Разработанная методика была реализована в виде программного комплекса, позволяющего проводить анализ безопасности ПО с высоким уровнем производительности и автоматизации. Комплекс включил в себя набор программных модулей, которые выполняют следующие задачи: анализ протокола тестирования и генерация на его основе тестовых данных с доставкой в анализируемый объект, получение графа потока управления для каждой тестовой итерации, оценка покрытия кода тестовыми данными. Экспериментальный анализ показал высокую эффективность предложенной методики и еe реализации для поиска уязвимостей в существующих программных продуктах, обеспечивая при этом высокий уровень производительности и визуализации информации о ходе анализа. С помощью разработанного комплекса было найдено несколько уязвимостей нулевого дня в популярных программных продуктах. Литература 1. Balakrishnan G., Reps T. WYSINWYX: What you see is not what you eXecute. Journ. ACM Transactions on Programming Languages and Systems (TOPLAS), August 2010, vol. 32, iss. 6, Article no. 23. 2. Pin – framework для динамической бинарной ин- струментации. URL: http://software.intel.com/en-us/articles/ pin-a-dynamic-binary-instrumentation-tool (дата обращения: 10.07.2014). 3. Derek B., Zhao Q. and Amarasinghe S. Transparent Dynamic Instrumentation. Proc. 8th ACM SIGPLAN/SIGOPS Conf. on Virtual Execution Environments, VEE'12, March 3–4, 2012, London, England, UK, ACM Press, 2012, pp. 133–144. 4. Miller B.P., Fredriksen L., and So B. An Empirical Study of the Reliability of UNIX Utilities (1990). Communications of the ACM, vol. 33, no. 12, pp. 32–44. 5. Kaksonen R., Laakso M., Takanen A. Software Security Assessment through Specification Mutations and Fault Injection. In Proc. 5th Joint Working Conf. on Communications and Multimedia Security (CMS'01), Darmstadt, Germany, 2001, рр. 115–126. 6. Rice H.G. Classes of recursively enumerable sets and their decision problems. Transactions of the American Mathematical Society, 1953, pp. 358–366. 7. Чернов А.В. Анализ запутывающих преобразований программ // Тр. Ин-та системного программирования РАН. 2003. С. 24–26. 8. Abran A. Software Metrics and Software Metrology Hoboken. NJ: Wiley-IEEE Computer Society, 2010. 9. Sulley Fuzzing Framework. URL: http://code.google.com/ p/sulley/ (дата обращения: 15.05.2014). References |

 , где TV – завершенность тестирования, причем 0 £ TV £ 1.
, где TV – завершенность тестирования, причем 0 £ TV £ 1.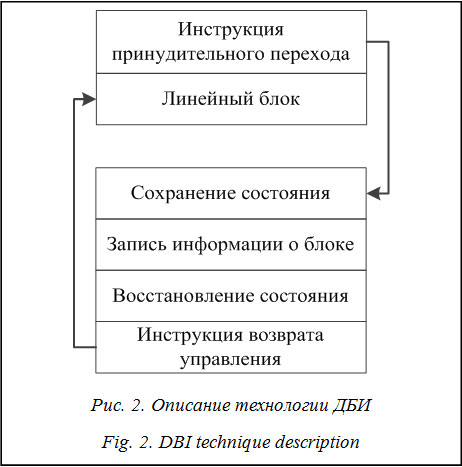
| Permanent link: http://swsys.ru/index.php?id=3901&lang=en&page=article |
Print version Full issue in PDF (6.61Mb) Download the cover in PDF (0.95Мб) |
| The article was published in issue no. № 4, 2014 [ pp. 78-84 ] |
Perhaps, you might be interested in the following articles of similar topics: