Journal influence
Bookmark
Next issue
Spectral measure playback accuracy using permutative method of modeling stochastic processes
Abstract:The paper considers one of the standard permutation methods of modeling stochastic processes with given spectral and proba-bilistic measures. An advantage of this method is the lack of restrictions on the combination of the probability and the spectral measure. There is a hypothesis of the reasons of appearing and structure of the general playback accuracy of autocorrelated function of modelled pro-cess using this method. The authors suggest that the modelling error consists of two parts: the variation and methodical. The error analysis method is developed. It allows making a constant value of the variation component of an error. In other words, making it independent on the autocorrelation function parameters. In turn, it allows carrying out the dependence analysis of the methodological component of the error modeling from the autocorrelation function parameters. To test this hypothesis four series of numerical experiments on modeling of stochas-tic processes were carried out using specially selected combinations of distribution laws. Distribution laws were chose n for reasons of ab-sence or presence of systematic error conditions. Based on the characteristics of the analyzed method (on the presence of lea ding and driven processes) the authors have developed a procedure for the statistical analysis of modeling results. Implementing the statistical analysis proce-dures developed by results of modeling gave no reason to reject the hypothesis of the existence of two error components: variation and me-thodical. The paper shows that using of this analysis method can significantly reduce the effect of variation in the results of systematic error analysis. It proves the method of stochastic processes modeling for solving various problems.
Аннотация:В работе рассматривается один из универсальных перестановочных методов моделирования стохастических процессов с заданными спектральной и вероятностной мерами. Привлекательной особенностью метода является отсутствие ограничений на сочетания вероятностной и спектральной мер. Выдвинута гипотеза о причинах возникновения и составе общей погрешности воспроизведения автокорреляционной функции моделируемого процесса при использовании данного метода. Сделано предположение, что погрешность моделирования состоит из двух частей: вариационной и методической. Разработан и предложен способ анализа погрешности, позволяющий сделать постоянным значение вариационной составляющей погрешности, то есть сделать ее не зависящей от параметров автокорреляционной функции. Это, в свою очередь, позволяет проводить анализ зависимости методической составляющей погрешности моделирования от параметров автокорреляционной функции. Для проверки выдвинутой гипотезы были проведены четыре серии численных экспериментов по моделированию стохастических процессов при специально подобранных сочетаниях законов распределения. Законы распределения выбирались из соображений отсутствия или наличия условий возникновения методической погрешности. Основываясь на особенностях анализируемого метода, а именно на наличии ведущего и ведомого процессов, разработана процедура статистического анализа результатов моделирования. Проведение этой процедуры не дало оснований отвергнуть гипотезу о наличии двух составляющих погрешности: вариационной и методической. В работе показано, что использование предложенного метода анализа позволяет значительно уменьшить влияние вариационной составляющей на результаты анализа методической погрешности и тем самым обосновать возможность применения метода моделирования стохастических процессов для решения тех или иных задач.
| Authors: Kuznetsov B.F. (kuznetsovbf@gmail.com) - Irkutsk State Academy of Agriculture, Molodezny Settlement, Irkutsk region, Russia, Ph.D, Shishkina S.V. (svetlanashishkina@mail.ru) - National Research Irkutsk State Technical University, Irkutsk, Russia, Borodkin D.K. (borodkin_dk@mail.ru) - Angarsk State Technical Academy, Angarsk, Russia, Ph.D | |
| Keywords: slave process, master process, spectral measure, autocorrelation, error modeling, permutative method, stochastic process |
|
| Page views: 8843 |
Print version Full issue in PDF (6.61Mb) Download the cover in PDF (0.95Мб) |
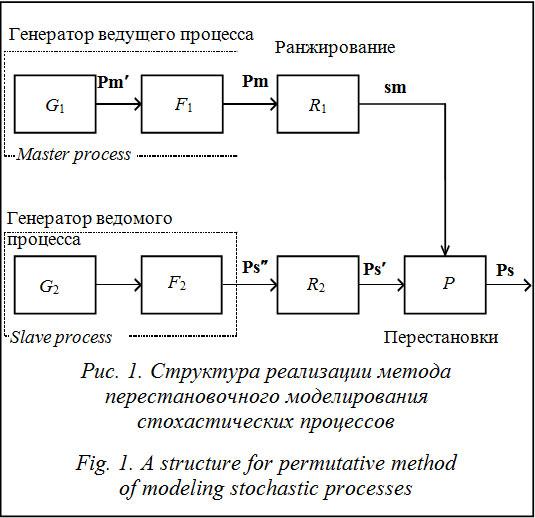
Генерирование случайных процессов с заданными вероятностной и спектральной мерами является одной из наиболее сложных задач стохастического моделирования [1]. Данное утверждение справедливо для всех законов распределения вероятностей, за исключением нормального распределения, для которого задача моделирования достаточно просто решается для произвольных спектральных мер [2]. До настоящего времени в арсенале исследователей отсутствуют универсальные методы, позволяющие решать эту задачу без существенных ограничений на вид спектральной или вероятностной меры. Тем не менее, в работе [3] был предложен метод, обладающий достаточной универсальностью по отношению к маргинальному закону распределения вероятностей и автокорреляционной функции (АКФ) моделируемого стохастического процесса. Несмотря на столь значимое достоинство, этот метод не получил широкого распространения в силу ряда причин. Основной причиной, ограничивающей его распространение, является отсутствие исследований точности моделирования АКФ. В силу особенностей метод обладает специфическим видом погрешности моделирования АКФ. Эта погрешность является методической и носит систематический характер, а значение погрешности зависит, как это будет показано далее, от множества параметров алгоритма моделирования. Механизм возникновения погрешности описан авторами метода [3], но каких-либо детальных исследований до сих пор не было проведено. В данной работе описываются разработка метода оценки точности воспроизведения (моделирования) заданной АКФ методом перестановок [3] и получение первоначальных сведений о свойствах методической погрешности. Прежде рассмотрим вариант реализации метода, разработанного авторами этой статьи (рис. 1).
Ведомый процесс, вектор Ps², формируется с заданным одномерным законом распределения. Как правило, эта процедура состоит из этапа формирования вектора с равномерным распределением с последующим его нелинейным преобразованием. На рисунке 1 приведена схема с нелинейным преобразованием, хотя в ряде случаев эта схема может изменяться, например для распределения Симпсона. Формирователь F2 может быть реализован нелинейной функцией или несколькими шагами алгоритма. Существующие методы позволяют в точности воспроизводить заданные одномерные законы распределения [5]. Следующий этап в рассматриваемом методе – ранжирование, то есть расположение элементов векторов Pm и Ps² в порядке возрастания. Для ведомого процесса результатом операции ранжирования является преобразованный вектор Ps¢, для ведущего – вектор перестановок sm. Заключительный этап метода – операция перестановки: на основании имеющегося вектора sm производится перестановка элементов вектора Ps¢: Таким образом, после завершения полного цикла моделирования можно вычислить оценки АКФ для вектора выходного процесса Ps и вектора ведущего процесса Pm. Введем обозначения для этих векторов оценок нормированной АКФ соответственно В качестве меры погрешности, как правило, используется некоторое расстояние между АКФ [6], например, для функций ra(t)и rb(t): Dab = ||q(t)[ra(t) – rb(t)]||, (1) где q(t) – некоторая весовая функция, учитывающая снижение значимости корреляции с увеличением корреляционного сдвига t. В частном случае для непрерывных АКФ выражение (1) можно записать как
Здесь во втором выражении учтено свойство четности АКФ. Формальный сомножитель, стоящий перед интегралом, может быть исключен, так как оценка точности метода производится в относительном виде, поэтому в дальнейших вычислениях сомножитель не используется. Весовая функция q(t) не имеет существенного влияния при относительной оценке, поэтому в дальнейшем она будет опущена. Приведенное выражение (2) соответствует непрерывному случаю. Переходя к требуемому дискретному случаю, перепишем его в виде
На основе одной теоретической (rt) и двух эмпирических АКФ ( Первая оценка погрешности будет определяться выражением вида
Выражение (4) отображает погрешность моделирования АКФ ведущего процесса. В предлагаемом методе формирование заданной АКФ для ведущего процесса базируется на соотношении
где h(t) – импульсная характеристика формирующего фильтра; Re(t), Rx(t) – АКФ сигнала на входе и выходе фильтра соответственно. Если входной сигнал e(t) – белый шум с интенсивностью Ф0, то есть Re(t) = 2pФ0d(t), где d(t) – дельта-функция, то
Так, для гауссовского стационарного процесса x(t) с АКФ вида rx(t) = e–a|t| на интервале наблюдения T дисперсия оценок АКФ будет определяться выражением
где aT ³106. (7) Таким образом, как видно из (6), изменение параметра АКФ приводит к изменению случайной составляющей погрешности моделирования, определяемой выражением (4). Вторая оценка погрешности будет определяться выражением
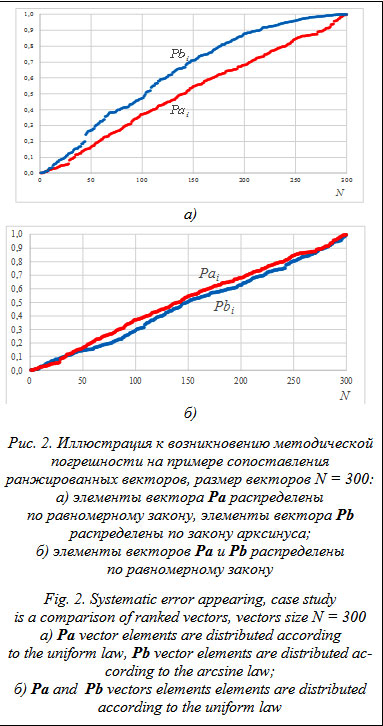
В данной оценке погрешности присутствуют две составляющие. Основная из них – методическая погрешность, имеющая систематический характер. Источником этой погрешности является невозможность точного сопоставления значений пар при ранжировании элементов векторов Pm и Ps² при различающихся законах распределения. На рисунке 2 приведены примеры ранжированных векторов Pa и Pb, элементы которых распределены на совпадающих интервалах [0, 1]: в первом случае по разным законам распределения (рис. 2а), во втором случае законы распределения совпадают (рис. 2б). Вполне очевидно, что и АКФ стохастического процесса, сформированного из вектора Pb путем перестановок, будет отличаться от АКФ вектора Pa. Во втором случае (рис. 2б) АКФ также будут отличаться, но значительно меньше, и самое главное, это отклонение будет иметь случайный, а не систематический характер, при N ®¥ отклонение будет стремиться к нулю. Именно эту погрешность авторы метода определили как основную и в работе [3] описали механизм ее возникновения. Следует отметить одну особенность методической погрешности: она сложным образом зависит от распределений, параметров и вида АКФ. Кроме того, с изменением параметров АКФ будет изменяться и погрешность. Это связано с тем, что формирование ведущего процесса (вектор Pm) в предлагаемом варианте реализации производится на основе линейного динамического преобразования Pm¢. Такое преобразование изменяет любой закон распределения вероятностей, если он не является нормальным, происходит так называемая нормализация. Очевидно, чем больше инерционность формирователя АКФ (см. F1 на рис. 1), тем сильнее будет трансформирован закон распределения выходного процесса. Ниже приведен пример для отвлеченного случайного процесса e(t), имеющего распределение арксинуса (закон распределения выбран из соображений наглядности). Для формирования случайного процесса x(t) с АКФ вида rx(t) = e–a|t|, (9) где a – параметр АКФ, определяющий скорость ее убывания, использован фильтр вида xi = aei + bxi–1, где a и b – параметры фильтра, определяемые на основе заданного параметра a [7]. Результаты численного эксперимента показаны на рисунке 3. Результаты проведенного эксперимента показывают, что уменьшение параметра a при формировании АКФ вида (9) приводит к изменению закона распределения выходного процесса, а следовательно, и к росту систематической погрешности. Можно с большой уверенностью предположить, что данное утверждение является верным для всех законов распределения, за исключением нормального закона, который инвариантен относительно линейного динамического преобразования. Третья возможная оценка погрешности формирования АКФ будет определяться выражением
Для анализа методической погрешности и ее зависимости от параметров АКФ необходимо уменьшить влияние случайной составляющей, что можно сделать двумя способами. Первый способ связан с увеличением интервала наблюдения (длины векторов) и количества параллельных экспериментов с последующим усреднением. Второй способ заключается в фиксировании дисперсии оценки АКФ в соответствии с выражением (6), для этого необходимо, чтобы aT = const. В таком случае при изменении параметра a будет изменяться только значение методической погрешности, значение случайной погрешности должно оставаться на одном уровне. Опишем алгоритм, реализующий предлагаемый метод. 1. Задаем [amin, amax] – интервал изменения параметра АКФ и Da – шаг изменения, предполагая, что АКФ имеет только один параметр, например случай (9). Определяем, до какого значения АКФ rE проводится анализ погрешности. Задаем коэффициент кратности K, определяющий, во сколько раз длина вектора N будет превышать длину корреляционного сдвига. 2. Определяем очередное значение ai = amin + + i × Da. Для этого вычислим корреляционный сдвиг tE исходя из заданного значения АКФ rE, решив уравнение r(t) – rE = 0. 3. Округляем полученное значение tE до ближайшего целого n, поскольку корреляционный сдвиг для стохастических процессов, представленных векторами, есть целая величина. Далее пересчитываем значение ai с учетом округления. Рассчитываем общую длину вектора N = nK. 4. Проводим цикл моделирования и вычисляем оценки погрешности по (4), (8) и (10). 5. Если ai < amax, переходим на шаг 2, иначе завершаем расчет. Для проверки приведенных предположений были выполнены численные эксперименты. В частности, рассмотрены три характерных случая параметров моделирования, результаты которых приведены ниже. Во всех трех случаях моделировались случайные процессы, с АКФ вида (9) коэффициент кратности K выбирался исходя из условия (7), диапазон изменения параметра a от 0,1 до 2,0, всего 10 точек. Случай 1. Законы распределения векторов Pm, Pm¢ и Ps² совпадают. Такое возможно только при условии, что все три вектора будут иметь нормальное распределение. Заметим, что данное сочетание законов распределений не имеет практической значимости, поскольку результат моделирования, вектор Ps, будет иметь нормальное распределение, а, как уже указывалось ранее, такую задачу можно решить и без привлечения алгоритмов перестановок. Подобное сочетание законов распределения позволяет изменять параметры формирующего фильтра F1 без изменения закона распределения элементов вектора Pm. В силу того, что у ведущего и ведомого процессов законы распределения совпадают, в результатах моделирования будет отсутствовать методическая погрешность, а применение алгоритма масштабирования длины вектора в зависимости от значения параметра a позволит сохранить дисперсию случайной погрешности на одном уровне.
Критерий Аббе–Линника позволяет проверить гипотезу об отсутствии тренда в погрешностях на основе следующей статистики [9]:
Если q ³ qcr, то нет оснований отвергнуть гипотезу, что наблюдаемые значения не содержат тренда, в противном случае считаем, что тренд есть. Для рассматриваемых условий проведения численного эксперимента qcr = 0,531 при уровне значимости p = 0,05 [10]. Численные значения полученных статистик приведены в таблице, в графическом виде результаты представлены на рисунке 4а. Как видно из приведенных графиков, оценки погрешности Dst и Dmt совпали и, как следствие, совпали линии регрессии. Это означает, что ведомый процесс практически точно воспроизвел ведущий процесс. Наблюдаемый на графиках наклон линии регрессии, очевидно, следует отнести к некомпенсированному увеличению вариативности оценки АКФ с уменьшением параметра a. Но использованные статистические критерии значимость наклона не подтверждают (см. табл.), так что можно считать, что разработанный алгоритм масштабирования с поставленной задачей справился.
Случай 2. Рассмотрим случай, когда вектор Pm имеет нормальный закон распределения, а элементы вектора Ps² распределены по закону арксинуса. Эксперимент проведен по аналогии с предыдущим случаем, а результаты расчета статистик представлены в таблице, в графическом виде результаты отображены на рисунке 4б. Как видно из результатов эксперимента, однозначно говорить о наличии зависимости погрешности моделирования от параметра a нельзя. Действительно, принципиально «расстояние» между векторами остается неизменным, как и в предыдущем эксперименте, так как законы распреде- ления ведущего и ведомого векторов остаются неизменными. Наблюдаемый наклон линии регрессии, очевидно, имеет ту же природу, что и в предыдущем случае. Случай 3. Особый интерес представляет третий случай, когда элементы вектора Pm¢ распределены по закону арксинуса, а элементы вектора Ps² – по нормальному закону. Очевидно, что распределение элементов вектора Pm будет изменяться с изменением параметра a (параметров фильтра F1 на рис. 1). При этом уменьшение параметра a (увеличение постоянной времени фильтра F1 на рисунке 1) будет нормализовать закон распределения Pm (см. рис. 3). Таким образом, «расстояние» между векторами Ps² и Pm будет уменьшаться. Если выдвинутое предположение верно, то на графиках зависимости погрешностей от параметра a будет наблюдаться положительный наклон линий регрессии. Графики на рисунке 4в подтверждают выдвинутое предположение визуально, а расчет статистик Аббе–Линника и Фишера, приведенный в таблице, подтверждает статистическую значимость наклона линии регрессии. Результаты рассмотренного случая моделирования позволяют говорить о том, что подтверждается модель возникновения погрешности моде- лирования случайных процессов анализируемым методом перестановок. Для убедительности рассмотрим еще один случай. Случай 4. Рассмотрим случай, когда элементы вектора Ps² и вектора Pm¢ распределены по закону арксинуса. Очевидно, что, как и в предыдущем случае, распределение элементов вектора Pm будет изменяться в зависимости от параметра a. Численные значения полученных статистик приведены в таблице, в графическом виде результаты представлены на рисунке 4г. Как и в предыдущем случае, результирующая погрешность Dst имеет статистически значимый наклон линии регрессии, но этот наклон уже имеет отрицательный знак. На основании результатов, полученных в данной работе, можно сделать следующие выводы. Данный метод расчета параметров проведения эксперимента по анализу погрешности моделирования позволяет значительно снизить влияние вариационной составляющей погрешности оценки АКФ, в результате чего появляется возможность выделить методическую составляющую и оценить ее реальный вклад в суммарную погрешность. Проведенные численные эксперименты показывают, что сделанное предположение о механизме возникновения методической погрешности можно считать верным. Действительно, в первых двух случаях, когда «расстояние» между ведущим и ведомым векторами не зависит от параметра АКФ, наклон линии регрессии результирующей погрешности Dst статистически незначим. Иными словами, погрешность моделирования не зависит от параметра АКФ. В двух последних случаях «расстояние» зависит от параметра АКФ и, как следствие, наклон линии регрессии погрешности Dst становится статистически значимым. Несмотря на наличие методической погрешности, метод имеет очень значимое преимущество, о котором говорилось в начале статьи, – отсутствие ограничений на вероятностную и спектральную меру моделируемого случайного процесса. Очевидно, что можно найти модификации данного метода, позволяющие снизить выявленную методическую погрешность, но это будет задачей дальнейших исследований. Литература 1. L’Ecuyer P. Non-uniform Random Variate Generations. Intern. Encyclopedia of Statistical Science, Springer-Verlagpp, 2011, Part 14, pp. 991–995. 2. Gregory K. Miller Probability: Modeling and Applications to Random Processes. Wiley-Interscience, 2006, 488 p. 3. Polge R.J., Holliday E.M., Bhagawan B.K. Generation of a pseudo-random set with desired correlation and probability distribution, Simulation, May 1973, pp. 153–158. 4. Лебедев А.Н. [и др.]. Вероятностные методы в инженерных задачах: справочник. СПб: Энергоатомиздат, 2000. 329 с. 5. Вадзинский Р.Н. Справочник по вероятностным распределениям. М.: Наука, 2001. 149 с. 6. Пригарин С.М. Методы численного моделирования случайных процессов и полей. Н.: Изд-во ИВМиМГ СО РАН, 2005. 259 с. 7. Прохоров С.А. Математическое описание и моделирование случайных процессов. Самара: Изд-во Самарского гос. аэрокосм. ун-та, 2001. 209 с. 8. Корн Г., Корн Т. Справочник по математике для научных работников и инженеров. М.: Наука, 2003. 832 с. 9. Линник Ю.В. Метод наименьших квадратов и основы математико-статистической теории обработки наблюдений. М.: Физматлит, 1958. 336 с. 10. Rajagopalan V. Selected Statistical Tests. ND, India, New Age Intern., 2006, 260 р. References |
 .
.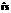 и
и  Кроме того, для оценки погрешности доступны и истинные значения требуемой АКФ в виде функции rt(t) от корреляционного сдвига t, на основании которой рассчитываются параметры формирователя F1 (рис. 1). Дискретные значения этой нормированной АКФ обозначим через вектор rt. В дальнейшем посредством r(t) будем обозначать нормированную АКФ, то есть rx(t) = Rx(t)/s2x и rx(0) = 1, где s2x – дисперсия случайного процесса x(t); Rx(t) – ненормированная АКФ случайного процесса x(t).
Кроме того, для оценки погрешности доступны и истинные значения требуемой АКФ в виде функции rt(t) от корреляционного сдвига t, на основании которой рассчитываются параметры формирователя F1 (рис. 1). Дискретные значения этой нормированной АКФ обозначим через вектор rt. В дальнейшем посредством r(t) будем обозначать нормированную АКФ, то есть rx(t) = Rx(t)/s2x и rx(0) = 1, где s2x – дисперсия случайного процесса x(t); Rx(t) – ненормированная АКФ случайного процесса x(t).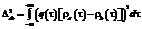 или
или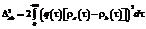 . (2)
. (2) , где ra =[ra] и rb =[rb] – дискретное представление для функций ra(t) и rb(t); n – максимальный корреляционный сдвиг (размер векторов ra и rb). Дальнейшие преобразования приводят к стандартному виду среднеквадратичного отклонения. Действительно, исключив зависимость значения погрешности от величины корреляционного сдвига и приведя результат к размерности АКФ, получаем
, где ra =[ra] и rb =[rb] – дискретное представление для функций ra(t) и rb(t); n – максимальный корреляционный сдвиг (размер векторов ra и rb). Дальнейшие преобразования приводят к стандартному виду среднеквадратичного отклонения. Действительно, исключив зависимость значения погрешности от величины корреляционного сдвига и приведя результат к размерности АКФ, получаем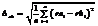 . (3)
. (3) ,
,  m), применив выражение (3), можно построить три оценки погрешностей моделирования. Рассмотрим их поочередно.
m), применив выражение (3), можно построить три оценки погрешностей моделирования. Рассмотрим их поочередно. . (4)
. (4) , (5)
, (5)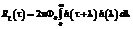 .
.
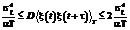 , (6)
, (6)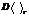 – дисперсия среднего на интервале T, T = N × Dt, Dt – шаг дискретизации по времени, в дальнейшем для простоты будем считать, что Dt = 1 (то есть T = N) [8]. Следует отметить, что (6) носит приблизительный характер [8] и верно только в случае выполнения неравенства
– дисперсия среднего на интервале T, T = N × Dt, Dt – шаг дискретизации по времени, в дальнейшем для простоты будем считать, что Dt = 1 (то есть T = N) [8]. Следует отметить, что (6) носит приблизительный характер [8] и верно только в случае выполнения неравенства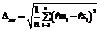 . (8)
. (8)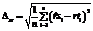 , (10)
, (10)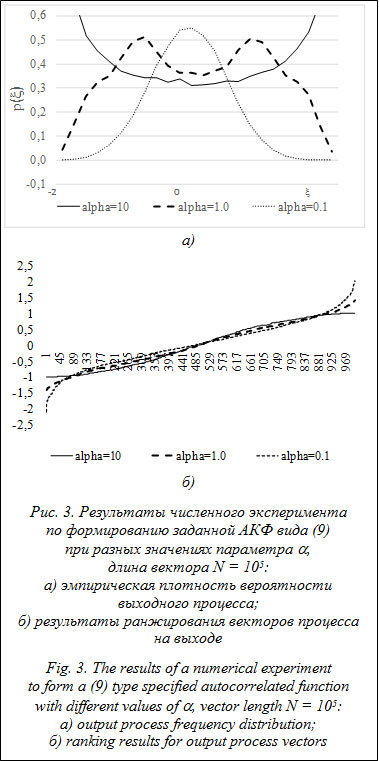
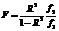 , где R2 – коэффициент детерминации; f1 – количество объясняющих переменных, в данном случае f1 = 1, f2 = m – f1 – 1 – число степеней свободы необъясненной дисперсии, m – количество экспериментальных точек, f2 = 8. Критическое значение статистики Фишера при указанных параметрах и при уровне значимости p = 0,05 составляет Fcr = 5,32. Регрессия признается значимой при выполнении условия F > Fcr.
, где R2 – коэффициент детерминации; f1 – количество объясняющих переменных, в данном случае f1 = 1, f2 = m – f1 – 1 – число степеней свободы необъясненной дисперсии, m – количество экспериментальных точек, f2 = 8. Критическое значение статистики Фишера при указанных параметрах и при уровне значимости p = 0,05 составляет Fcr = 5,32. Регрессия признается значимой при выполнении условия F > Fcr. .
.
| Permanent link: http://swsys.ru/index.php?id=3912&lang=en&page=article |
Print version Full issue in PDF (6.61Mb) Download the cover in PDF (0.95Мб) |
| The article was published in issue no. № 4, 2014 [ pp. 143-149 ] |
Back to the list of articles