Journal influence
Bookmark
Next issue
Investigation of the load prediction methods in computer and computer systems
Abstract:The problem of process and resource management in large scale computer systems with thousands of components is important and has not been solved yet. Thus, a user has to determine the amount of resources needed for a computer system in advance and distribute parallel program fragments to achieve a desired acceleration effect and minimize resource usage. However, even for simple paralleling logic problems such a static planning strategy results in average resource utilization is no more than 15–20 %. The paper is devoted to the problem of computing system load level forecasting to create adaptive methods and algorithms for resource dynamic management and optimization algorithms. The paper presents the data of an experimental investigation of predicting workload of processors. It is based on various filtration methods of high-frequency signal which is processes assessable workload. The results show that among well known filters the median filters are the most precise. The results are used for the development of adaptive algorithms intended for resources optimization, in particular, for allocation of processor resources in computers and large computer systems.
Аннотация:Проблема управления процессами и ресурсами в больших компьютерных системах, насчитывающих сегодня десятки и сотни тысяч компонентов, актуальна и практически не решена. Поэтому пользователь вынужден заранее самостоятельно определять необходимое количество компонентов этих систем и так распределять фрагменты параллельной программы на них, чтобы получить ускорение при выполнении программы и в то же время минимизировать объем используемых ресурсов. Однако даже для задач с простой логикой распараллеливания этот способ статического планирования процессов и ресурсов приводит к тому, что среднее использование ресурсов оказывается не более 15–20 %. Статья посвящена исследованию проблемы прогнозирования загруженности компонентов компьютерных систем с целью создания адаптивных методов и алгоритмов динамического управления ресурсами и оптимизации их использования. В ней приведены данные экспериментального исследования прогнозирования загруженности основного ресурса системы – ее процессора, которые основаны на различных методах фильтрации высокочастотного сигнала, каковым является измеряемая загруженность процессов компьютерных систем. Результаты исследования показывают, что медианные фильтры имеют наибольшую точность предсказания загруженности процессоров. На их основе разработаны адаптивные алгоритмы, предназначенные для оптимизации ресурсов, в частности, количества процессоров, в работе больших компьютерных систем: кластеров, систем управле-ния и обработки информации.
| Authors: Brazhnikova Yu.S. (kutepov@appmat.ru) - National Research University “MPEI”, Moscow, Russia, Goritsky Yu.A. (kutepov@appmat.ru) - National Research University “MPEI”, Moscow, Russia, Ph.D, Kutepov V.P. (vkutepov@appmat.ru) - National Research University “MPEI”, Moskow, Russia, Ph.D, Pankov N.A. (nicolay.a.pankov@gmail.com) - National Research University “MPEI”, Moscow, Russia | |
| Keywords: computer systems load management, parallel processes, computer systems |
|
| Page views: 8498 |
Print version Full issue in PDF (4.84Mb) Download the cover in PDF (0.35Мб) |
Создание компьютерных систем (КС) с десятками и сотнями тысяч компьютерных компонентов [1] актуализировало проблему разработки эффективных методов управления их ресурсами. При этом в качестве критерия эффективности обычно рассматривается требование минимизации используемых ресурсов КС при удовлетворении требований к выполняемому в общем случае потоку программ. Для КС общего назначения такими требованиями являются достижение максимальной реальной производительности (среднего количества программ, выполняемых в единицу времени). Для кластеров и многоядерных компьютеров критерий эффективности – это достижение заданного (минимального в теоретическом плане) времени выполнения параллельной программы при условии использования минимального количества компонентов КС.
В силу примитивного характера средств управления КС в настоящее время программист, используя, например, кластер и MPI, должен сам определить оптимальную степень распараллеливания (зернистость) и необходимое количество компонентов КС, затем распределить процессы таким образом, чтобы достигалось желаемое время выполнения параллельной программы. В результате, как показывает практика, даже для этой простой модели параллелизма, применяемой в MPI и исключающей возможность порождения процессов (имеется в виду MPI-1), процессоры или компьютеры кластера используются всего на 10–15 %. Аналогичное состояние в решении проблемы управления наблюдается в обобществляемых или слабо связанных в отличие от кластеров КС, называемых GRID, CLOUDS, то есть в глобальных компьютерных сетях. Управление подобными КС усложняется вследствие неоднородности их компонентов и большой удаленности выделяемых ресурсов, необходимости объективного учета оплаты за используемые пользователями ресурсы. Сложность проблемы создания эффективных средств управления большими КС заключается в том, что порождение процессов имеет случайный характер, то же самое относится к их сложности и, следовательно, к генерируемым процессами требованиям к различным ресурсам КС [2–6]. Поэтому в реализации на КС созданных нами высокоуровневых языков параллель- ного программирования (языка функционального параллельного программирования [7] и языка граф-схемного потокового программирования [8]) мы используем адаптивные методы для управления процессами и ресурсами в КС [5, 6]. Их главная особенность заключается в измерении и прогнозировании загруженности ресурсов КС (процессоров, памяти, каналов, периферийных устройств) и построении на этой основе системы решающих правил, позволяющих в динамике регулировать объем ресурсов, необходимый для эффективного выполнения программ и процессов. В статье приведены результаты экспериментального исследования методов прогнозирования загруженности процессоров КС – основного ресурса, по эффективности использования которого обычно определяют реальную производительность КС. Кроме того, дан сравнительный анализ полученных результатов, подтверждающий тезис о возможности с достаточно высокой точностью прогнозировать загруженность процессоров КС. Отметим, что у этого результата есть и другое, самостоятельное значение, показывающее, что случайные процессы загруженности, в частности, загруженности процессоров и компьютеров КС, имеют вполне закономерную стохастическую природу. Экспериментальное исследование методов прогнозирования загруженности процессоров Приведем результаты выполненного авторами экспериментального исследования прогнозирования загруженности процессора компьютера по данным ее измерения стандартными средствами ОС сегодняшних компьютеров. При этом для обеспечения большой точности измеряемые счетчиками значения загруженности представляют собой высокочастотный процесс, а интервалы измерений находятся в пре- делах нескольких микросекунд. Поэтому предска- зывать изменение загруженности с достаточной точностью можно, лишь применяя соответствующие методы сглаживания процесса или подавления его высокочастотной составляющей.
Для получения достоверных результатов применялся широкий круг хорошо известных приложений, таких как Microsoft Visual Studio, MathСad, MSOffice, SQL Server, браузеры и др. Для сбора и обработки статистических данных было разработано специальное приложение, позволяющее варьировать дискретность измерений процесса загруженности процессора компьютера, метод сглаживания и метод прогнозирования изменения загруженности. Прогноз изменений параметров загруженности есть смысл делать на 0,5–1 сек. вперед из-за нестационарности и непредсказуемости графиков загруженности процессора. Предсказываемое значение загруженности
Все рассмотренные методы сглаживания были экспериментально исследованы с помощью программ MathCAD. Для приведенной в статье реализации процесса загруженности вычислялись средняя и максимальная ошибки предсказания загруженности процессора и их дисперсии на 0,5 сек. вперед. Экстраполятор на основе экспоненциального сглаживания. Экспоненциальное сглаживание – один из простейших и распространенных приемов выравнивания временного ряда. Экспоненциальное сглаживание можно представить как фильтр, на вход которого последовательно поступают члены исходного ряда, а на выходе формируются текущие значения экспоненциальной средней. При экспоненциальном сглаживании предыдущие значения параметров учитываются с убывающими по экспоненциальному закону весами. В простейшем случае для нахождения очередного сглаженного значения используются только текущее измерение и предыдущее сглаженное значение. Формула прогнозирования имеет вид (в соответствии с (1)): На рисунке 1 приведен пример прогнозирования на основе экспоненциального сглаживания загруженности процессора (X – график загруженности процессора, Exp – экспоненциальное сглаживание X). На этом рисунке и рисунке 2 промежуток между съемами данных принят равным 0,5 сек., количество измерений t =1200, прогноз приводится на 1 шаг вперед. В данном методе ошибки предсказания загруженности в первую очередь зависят от параметра x. Средняя ошибка прогнозирования определяется по формуле Значения ошибки прогнозирования в зависимости от параметра x приведены в таблице 1. Экстраполятор с равномерным окном. При экстраполяции с равномерным окном происходит усреднение по T предыдущим измерениям с равными весами. Формула экстраполятора с равномерным окном имеет следующий вид: Таблица 1 Зависимость ошибки прогнозирования от параметра x Table 1 A misprediction depending on x parameter
Рассматривается одношаговый экстраполятор с равномерным окном. Экспериментальные данные ошибок прогнозирования загруженности процессора в зависимости от параметра ширины окна T для этого метода сглаживания приведены в таблице 2. Таблица 2 Экспериментальные данные ошибок прогнозирования Table 2 Misprediction experimental data
Экстраполятор с подбором весовых коэффициентов. При экстраполяции с подбором весовых коэффициентов происходит усреднение по T предыдущим измерениям с различными весами. Формула экстраполятора с подбором весовых коэффициентов имеет следующий вид: Вес произвольного i-го измерения ci, в первую очередь, определяется коэффициентом убывания весов s и вычисляется по формуле Рассматривается одношаговый экстраполятор с подбором весовых коэффициентов. Средняя и максимальная ошибки прогнозирования загруженности в зависимости от параметров T и s для этого метода сглаживания приведены в таблице 3. Таблица 3 Средняя и максимальная ошибки прогнозирования Table 3 An average and maximal misprediction
Медианный фильтр. Медианные фильтры достаточно часто применяются на практике для предварительной обработки цифровых данных как альтернатива средним арифметическим значениям отсчетов в оценке выборочных средних значений. Медианой числовой последовательности x1, x2, …, xn при нечетном n является средний по значению член ряда, получающегося при упорядочивании этой последовательности по возрастанию (или убыванию). Для четных n медиану обычно определяют как среднее арифметическое двух средних отсчетов упорядоченной последовательности.
Достоинством медианных фильтров является простота структуры, позволяющая легко реализовать фильтр как аппаратными, так и программными средствами. Медианный фильтр не применяется для ступенчатых и пилообразных функций, однако он хорошо подавляет одиночные импульсные помехи (случайные шумовые выбросы отсчетов и промахи). Медианные фильтры имеют следующие недостатки: − медианная фильтрация – метод нелинейной обработки сигналов, так как медиана суммы двух произвольных последовательностей не равна сумме их медиан – это усложняет математический анализ их характеристик; нельзя разграничить влияние этих фильтров на сигнал и шум, что для линейных фильтров делается очень просто; − фильтр вызывает уплощение вершин треугольной функции; − подавление гауссовского шума менее эффективно, чем у линейных фильтров; − двумерная обработка приводит к более существенному ослаблению сигнала. Авторами были промоделированы различные реализации медианных фильтров, где в качестве верхней границы окна брался текущий показатель измерения загруженности (рис. 2), таким образом, Таблица 4 Ошибки прогнозирования для медианного фильтра Table 4 Mispredictions for a median filter
Сравнение методов В таблице 5 приведены наилучшие значения средней, максимальной и дисперсии ошибки прогнозирования для каждого из методов. Таблица 5 Наилучшие значения ошибки прогнозирования Table 5 The best values of misprediction
Из приведенных данных видно, что экспоненциальное сглаживание, экстраполятор с равномерным окном и экстраполятор с подбором ширины окна и весовых коэффициентов дают близкие результаты. Медианный фильтр в среднем дает улучшение результатов на 25–35 % по сравнению с предыдущими методами. Средняя дисперсия ошибки при прогнозировании для данной реализации путем выбора константы по предыдущему значению составила 0,101. Значения средней ошибки прогнозирования загруженности процессора путем выбора единственной константы для всей реализации (например, предполагаем, что процесс всегда принимает значение 0,3) следующие:
Очевидно, что в зависимости от выбора конкретной константы средняя ошибка прогнозирования существенно изменяется. Значит, не зная поведения процесса, нельзя выбрать такую константу (отсутствие прогнозирования), которая всегда давала бы приемлемые результаты. Поэтому необходимо постоянно прогнозировать загруженность компонентов КС для достижения успешного и эффективного управления процессами в КС. В заключение отметим, что исследования точности прогнозирования загруженности процессора с применением рассмотренных фильтров были выполнены на достаточно представительном наборе приложений. Полученные данные позволяют сделать вывод, что наиболее точным методом прогнозирования загруженности процессора является медианный фильтр. При этом преимущество медианных фильтров особенно заметно для процессов с высокой амплитудой колебания параметра загруженности. На так называемых гладких графиках процессов этот эффект не столь очевиден. Помимо всего, медианный фильтр достаточно просто реализуется на практике и требует немного времени на определение прогноза загруженности. Результаты выполненных исследований составили основу для построения эффективных алгоритмов управления параллельными процессами на кластерах и распределенных компьютерных системах. Литература 1. Проект по составлению рейтинга и описанию 500 самых мощных вычислительных систем мира. URL: http://www.top500. org (дата обращения: 05.04.2015). 2. Кутепов В.П., Фальк В.Н. Формы, языки представления, критерии и параметры сложности параллелизма // Программные продукты и системы. 2010. № 3. С. 16–26. 3. Кутепов В.П. О параллелизме с разных сторон // Параллельные вычисления и проблемы управления: матер. 5-й Междунар. конф. М.: Изд-во ИПУ РАН, 2010. 4. Тауб С., Шафри Х. Улучшенная поддержка распараллеливания в следующей версии Visual Studio // Журнал для разработчиков MSDN Magazine. 2008. № 11 (83). 5. Кутепов В.П. Интеллектуальное управление процессами и загруженностью в вычислительных системах // Изв. РАН. ТиСУ. 2007. № 5. 6. Kutepov V.P. Scheduling parallel processes and load balancing in large-scale computing systems. Proc. Intern. Symp. on Distributed Computing and Application for Business? Engineering and Science. China, 2007, vol. 1. 7. Кутепов В.П., Шамаль П.Н. Реализация языка функционального параллельного программирования FPTL на многоядерных компьютерах // Изв. РАН. ТиСУ. 2014. № 3. 8. Кутепов В.П., Маланин В.Н., Панков Н.А. Граф-схемное потоковое параллельное программирование: язык, процессная модель, реализация на компьютерных системах // Изв. РАН. ТиСУ. 2012. № 1. 9. Айфичер Э., Джервис Б. Цифровая обработка сигналов. Практический подход // М.: Вильямс, 2004. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 на момент будущего представляется как константа, равная полученному сглаженному значению
на момент будущего представляется как константа, равная полученному сглаженному значению  в текущий момент времени:
в текущий момент времени: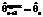 . (1)
. (1)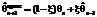 , где qn – измеренное значение параметра в n-й момент времени;
, где qn – измеренное значение параметра в n-й момент времени;  , а максимальная ошибка прогнозирования по формуле
, а максимальная ошибка прогнозирования по формуле 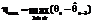 .
. , где qn-k – измеренное значение параметра в (n–k)-й момент времени, k≥1;
, где qn-k – измеренное значение параметра в (n–k)-й момент времени, k≥1;  где qn-i – измеренное значение параметра в (n–i)-й момент времени;
где qn-i – измеренное значение параметра в (n–i)-й момент времени;  , где
, где 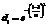 .
.
 , где qn,
, где qn, | Permanent link: http://swsys.ru/index.php?id=4012&lang=en&page=article |
Print version Full issue in PDF (4.84Mb) Download the cover in PDF (0.35Мб) |
| The article was published in issue no. № 2, 2015 [ pp. 135-139 ] |
Perhaps, you might be interested in the following articles of similar topics: