Journal influence
Bookmark
Next issue
Probabilistic inference in weakly formalized knowledge bases
Abstract:The article introduces the process of probabilistic inference in weakly formalized knowledge bases. Semantic network is chosen as a graphical model of knowledge representation due to a convenient representation of automatically extracted data as a graph with links. The paper also contains a comparison of widely used production model approach with the proposed one. The authors describe main disadvantages of a production model approach that should be considered for developing such knowledge extraction systems. The aim of the work is new knowledge extraction from an automatically built knowledge base. Usually logical inference is used to achieve this aim in graphical models. In our case a domain model as well as a process of knowledge building (in particular by automatic or semi-automatic methods) restrict logical inference mechanism, so this algorithm is forced to work in conditions of uncertainty. Thus, standard logical inference algorithms provided for such model become irrelevant. The article proposes using probabilistic inference for the task and consequently using probabilistic inference programming language. The paper contains a comparison of several modern probabilistic logic programming languages like PRISM, ICL and ProbLog. The authors select a probabilistic logic programming language based on the results of this comparison. To implement probabilistic inference in a weakly formalized knowledge base we have selected ProbLog language (ProbLog2 in particular) that is a probability extension of Prolog.
Аннотация:В статье рассматривается процесс вероятностного вывода в слабоформализованных базах знаний. В качестве такой базы выбрана графическая модель представления знаний – семантическая сеть. Выбор обусловлен удобством представления автоматически извлеченных данных в виде графа со связями, а также удобством дальнейшего использования (чтения, изменения и поиска ошибок) данного графа. Также проводится сравнение широко используемого на данный момент продукционного подхода с предложенным, указываются основные недостатки продукционного подхода, которые необходимо учитывать при разработке подобных систем извлечения знаний. Целью исследования является извлечение новых знаний из автоматически полученных данных. Для достижения этой цели на графических моделях обычно производится логический вывод. Поскольку модель, а также способ получения данных (в данном случае автоматически или полуавтоматически) накладывают ограничения на механизм вывода, алгоритм вынужден работать в условиях неопределенности. Отсюда следует, что стандартные механизмы логического вывода, предусмотренные для данной модели, становятся неактуальными. В статье предлагается использовать вероятностный вывод и, следовательно, вероятностный язык логического программирования для его реализации. Также делается сравнение нескольких существующих языков вероятностного логического программирования, таких как PRISM, ICL и ProbLog. По результатам сравнения производится выбор языка вероятностного программирования для осуществления вывода. В качестве такого языка выбран язык ProbLog (в частности система ProbLog2), являющийся вероятностным расширением языка Prolog.
| Authors: Poleschuk E.A. (eapoleschuk@corp.ifmo.ru) - The National Research University of Information Technologies, Mechanics and Optics, St. Petersburg, Russia, Platonov A.V. (avplatonov@corp.ifmo.ru) - The National Research University of Information Technologies, Mechanics and Optics, St. Petersburg, Russia | |
| Keywords: probabilistic inference, semantic network, weakly formalized knowledge bases, problog, probabilistic logic programming, data uncertainty, relationships uncertainty |
|
| Page views: 10647 |
Print version Full issue in PDF (6.81Mb) Download the cover in PDF (0.36Мб) |
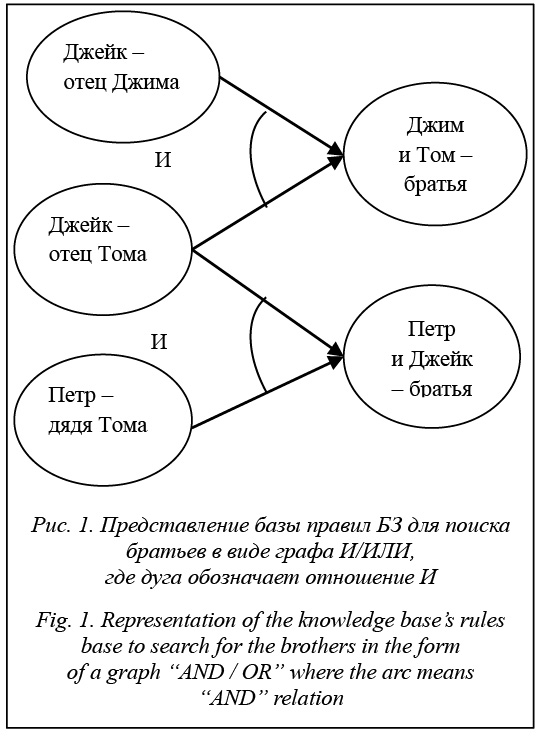
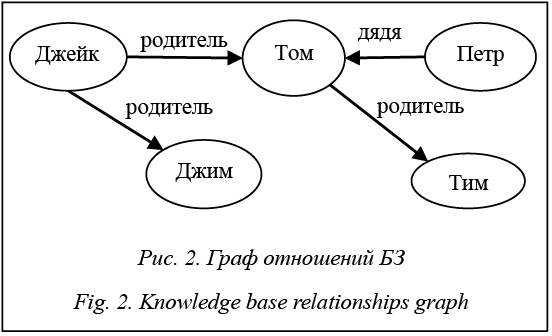
Одним из популярных подходов к представлению знаний является продукционный подход. Продукционная модель – это модель, в которой знания представлены с помощью правил «ЕСЛИ – ТО» [1]. Эта модель довольно просто интерпретируется человеком, так как правила в ней схожи с предложениями на естественном языке. Положительными сторонами данной модели являются также простота создания и интерпретации отдельных правил (ЕСЛИ X – человек, ТО Х смертен), изменения правил и пополнение базы правилами, довольно простой и прозрачный механизм логического вывода. Однако, помимо сильных сторон, у данной модели имеются и слабые: - не ясно, каким образом правила соотносятся между собой; - довольно сложно составить целостную картину знаний по отдельным правилам; - продукционная модель отличается от структуры знаний человека; - в логическом выводе отсутствует гибкость. Таким образом, задачи, решаемые с помощью продукционной модели, должны быть небольшими (оперировать небольшим объемом знаний) и не требующими гибкого вывода [2]. Ответ на интересующий вопрос можно получить в БЗ, основанных на продукционной модели, с помощью логического вывода (прямого или обрат- ного). Обратный логический вывод осуществляет поиск от целей к данным. При прямом выводе происходит поиск от данных к целям [3]. Прямой вывод используется тогда, когда по исходным данным требуется вывести все следствия (задача интерпретации или прогнозирования), тогда как обратный вывод применяется в случае необходимости проверки определенной гипотезы на соответствие фактам (задача диагностики). Подробные примеры приведены в [3]. Так как продукционная БЗ, как и программа на языке Problog, состоит из правил, соответственно, можно создавать программы, написанные на этом языке и осуществляющие логический вывод в этой БЗ. Такое соответствие на примере задачи поиска всех братьев, если известны имена людей и родственные отношения между ними, проиллюстрировано в таблице 1. Продукционную модель можно представить в виде графа (рис. 1 и 2).
Однако следует отметить, что логический вывод плохо работает с данными в условиях неопределенности. Далее речь пойдет о вариантах решения этой проблемы. Построение более или менее больших БЗ требует очень больших затрат ресурсов, так как это в основном выпоняется вручную. Поэтому логичным кажется использование методов машинного обучения для построения таких БЗ [4]. Эти методы, соответственно, обладают определенной точностью, то есть мы не совсем уверены в правильности данных, полученных автоматически. Отсюда следует вероятностная природа полученных данных, то есть явление неопределенности. Таблица 1 Соответствие программы на Prolog продукционной БЗ Table 1 Prolog program matching to a rule-oriented knowledge base
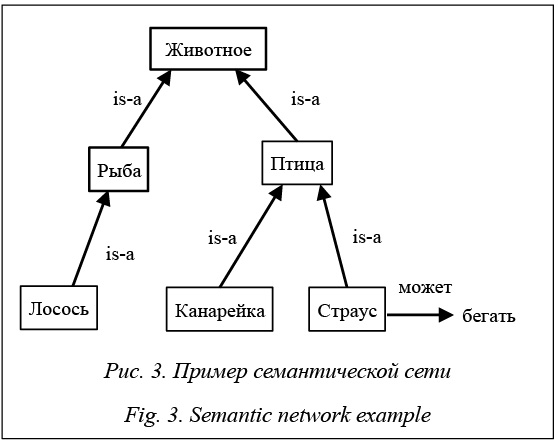
Графические модели представления знаний Поскольку самым удобным способом представления автоматически извлеченных данных является граф, сформируем структуру из автоматически извлеченных данных. В данной работе в качестве графической модели БЗ примем семантическую сеть [5].
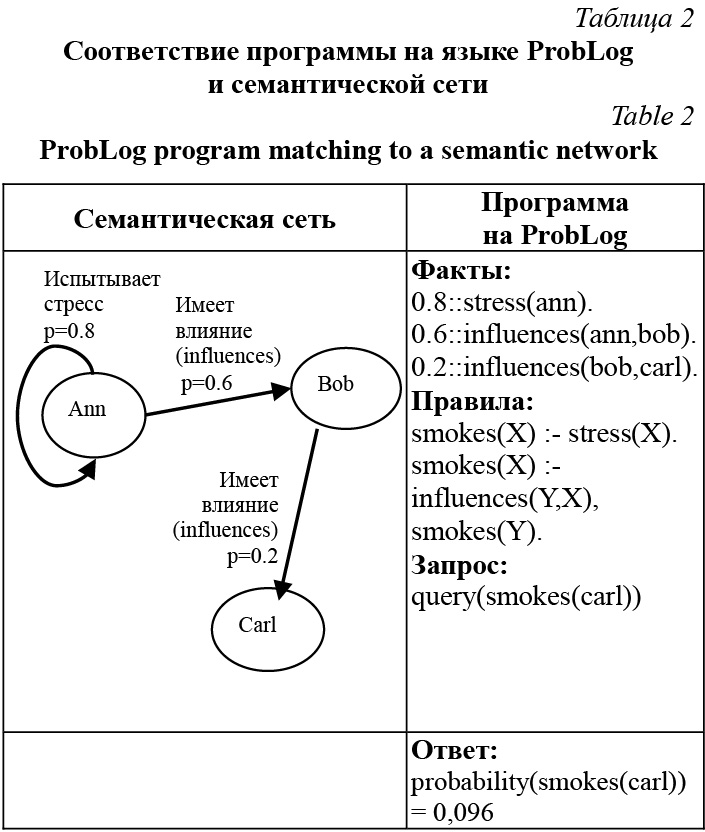
Вывод в графических моделях Учитывая вероятностную природу данных, получим слабоформализованную БЗ (здесь в существовании связей между элементами БЗ нет уверенности, поскольку данные получены автомати- чески). Представим полученную БЗ в виде взвешенного графа. Причем веса в графе обозначают степень уверенности алгоритма в правильности полученных данных. Однако так как данные оказываются неточными, вывод по ним стоит строить соответствующий. Задачу вывода в таких системах решает вероятностный вывод. Вероятностный вывод – более общий по отно- шению к логическому выводу, он позволяет оцени- вать степень уверенности в том, что полученный результат с нечетко определенными данными имеет место быть. Пусть дана графическая модель X. Хотим получить ответ на вероятностный запрос вида p(y|z), где Y – целевая переменная, а Z – входная переменная. Y и Z являются неперсекающимися подмножествами X. Эта задача известна как задача вероятностного вывода. Для объяснения механизма вероятностного вывода приведем пример программы на языке вероятностного программирования. На сегодня существует множество языков вероятностного логического программирования, например PRISM, ICL и ProbLog. В данной работе используется язык ProbLog (Probablistic Prolog), синтаксис которого схож с наиболее распространенным на данный момент языком Prolog [7]. В программе на языке ProbLog каждому факту присваивается какая-либо вероятность. Далее, как и в Prolog, определяются правила, по которым можно производить вывод. Результатом исполнения программы является оценка вероятности запрошенного факта. Стандартным примером программы на ProbLog является программа Smokers, которая показывает, каким образом отношения между людьми влияют на их привычку курить (табл. 2).
Входным множеством переменных в данном примере является множество фактов: Z = {0.8::stress(ann), 0.6::influences(ann,bob), 0.2::influences(bob,carl)}, а целевой переменной Y является переменная в запросе: Y = {smokes(carl)}. Символ :- в правилах обозначает импликацию, направленную влево, то есть выражение «smokes(X) :- stress(X).» следует читать так: если человек испытывает стресс, то он курит. Каждая строка заканчивается точкой (как в предложении на естественном языке), запятые обозначают совместное применение выражений, то есть «И». На данный момент задача вероятностного вывода становится наиболее актуальной, так как растет количество неточных данных и методы логического вывода работают уже не так хорошо. На эту тему существует много работ, в частности, в [8, 9] рассматривается вывод на основе конвертации исходной программы во взвешенную булеву формулу (пропозицонную), а также во взвешенную коньюнктивную нормальную форму. В работе [10] рассматривается вывод в графических моделях и, в частности, в семантических сетях, что наиболее близко к данной работе. Сравнение языков вероятностного логического программирования Сравним ProbLog с другими языками вероятностного программирования, а также с его предшественником – языком Prolog. Ранее было отмечено, что на данный момент существует несколько языков вероятностного вывода: PRISM [11], ICL [12], ProbLog и другие. ProbLog поддерживает ограниченный набор функций языка Prolog для выражения моделей в вероятностной логике. Главное различие между языком ProbLog and Prolog в том, что Prolog является полноценным языком вероятностного программирования, тогда как ProbLog – язык логического представления. Это означает, что не все функции языка Prolog, связанные с частью программирования (управляющие конструкции и ввод/вывод), не поддерживаются в языке ProbLog. В таблице 3 представлены основные характеристики каждого языка и основная, соответствующая этому языку система. По сравнению с другими языками вероятностного логического программирования ProbLog более выразителен по отношению к правилам, доступным в программе. Это, в частности, относится к PRISM и ICL. Эти языки выдвигают требования об ацикличности правил [13]. В языке ProbLog программа может быть зациклена, например: smokes(X) :- smokes(Y), influences(Y,X). Такие типы цикличных правил часто используются для задач классификации и анализа социальных сетей [14]. Также PRISM требует правила с унифицированной (все одинаковые) головой, которые должны иметь взаимоисключающие тела (все разные), то есть одновременно может быть истинно только одно такое тело. ProbLog [15, 16] не имеет такого ограничения, таким образом, правила с унифицированной головой могут иметь пересекающиеся тела (где голова правила – это часть правила до символа «:-», а тело – после). Например, тела двух правил сигнализации пересекаются: и кража, и землетрясение могут заставить сигнализацию сработать, однако они также могут произойти одновременно: сигнализация
Таблица 3 Обзор основных характеристик некоторых языков вероятностной логики и соответствующих им систем (реализации) Table 3 Review of key features of some probabilistic logic languages and corresponding implementation systems
В заключение отметим, что в работе рассмотрен процесс вероятностного вывода в слабоформализованных БЗ. В качестве базы выбрана семантическая сеть, поскольку в графической модели удобно представлять автоматически извлеченные данные. Также проведено сравнение продукционного подхода с представлением БЗ в виде семантической сети. В данной статье предложено использовать ве- роятностный вывод в графической модели и, сле- довательно, вероятностный язык логического программирования для его реализации. Также срав- ниваются несколько существующих языков вероят-ностного логического программирования, в результате для реализации механизма вероятностного вывода выбран язык ProbLog. Литература 1. Katerinenko R.S., Bessmertny I.A. A method for acceleration of logical inference in the production knowledge model. Programming and Computer Software, 2011, vol. 37, no. 4, pp. 197–199. 2. Уэно Х., Исидзука М. Представление и использование знаний. М.: Мир, 1989. 220 с. 3. Довбуш Г.Ф. Логическое программирование. ПГУПС, 2011. URL: http://ivc.clan.su/_fr/1/FLP_l9.pdf (дата обращения: 28.02.2016). 4. Petasis G., Karkaletsis V., Paliouras G., Krithara A., Zavitsanos E. Ontology population and enrichment: state of the art. Proc. 14th Intern. Conf., Philadelphia, Pennsylvania, USA, 2011, vol. 6050, pp. 134–166. 5. Bessmertny I.A. Knowledge Visualization Based on Semantic Networks. Programming and Computer Software, 2010, vol. 36, no. 4, pp. 197–204. 6. Roussopoulos N.D. A semantic network model of data bases. TR no. 104, DCS, Univ. of Toronto Publ., 1976. 7. Бессмертный И.А. Искусственный интеллект. СПб: Изд-во ИТМО, 2010. 132 с. 8. Fierens D., Van den Broeck G., Renkens J., et. al. Inference and learning in probabilistic logic programs using weighted boolean formulas. DCS, TPLP, 2015, vol. 15, no. 3, pp. 358–401. 9. Fierens D., Van den Broeck G., Thon I., Gutmann B., De Raedt L. Inference in probabilistic logic programs using weighted CNF’s. Proc Conf. AUAI, 2011, pp. 211–220. 10. Сукач Е.И., Ратобыльская Д.В., Мережа В.Л. Реализация вывода в семантической сети с использованием вероятностно-алгебраического моделирования // Открытые семантические технологии проектирования интеллектуальных систем. OSTIS- 2011: тр. Междунар. науч.-технич. конф. Минск: Изд-во БГУИР, 2011. C. 241–246. 11. Sato T., Kameya Y. PRISM: a language for symbolic-statistical modeling. Intern. Joint Conf. on Artificial Intelligence, 1997, vol. 15, pp. 1330–1339. 12. Poole D. The independent choice logic and beyond. In probabilistic inductive logic programming – theory and applications. LNCS, Springer, Berlin/Heidelberg, 2008, vol. 4911, pp. 222–243. 13. Sato T. and Kameya Y. Parameter learning of logic programs for symbolic-statistical modeling. JAIR, 2001, vol. 15, pp. 391–454. 14. Russell S.J., Norvig P. Artificial intelligence. A modern approach. 2nd ed. Upper Saddle River, NJ, Prentice Hall Publ., 2003, 1110 p. 15. De Raedt L., Kimmig A., and Toivonen H. ProbLog: A probabilistic Prolog and its application in link discovery. IJCAI, 2007, pp. 2462–2467. 16. Fierens D., Broeck G.V., Renkens J., et. al. Inference and learning in probabilistic logic programs using weighted Boolean formulas. Theory and Practice of Logic Programming, 2014, vol. 15, no. 3, pp. 358–401. | ||||||||||||||||||||||||||||||||||||||||||||||
| Permanent link: http://swsys.ru/index.php?id=4171&lang=en&page=article |
Print version Full issue in PDF (6.81Mb) Download the cover in PDF (0.36Мб) |
| The article was published in issue no. № 3, 2016 [ pp. 10-14 ] |
Perhaps, you might be interested in the following articles of similar topics: