Journal influence
Bookmark
Next issue
Software to solve the problems of optimizing transport objects placement based on the algorithm of projection clustering
Abstract:The choice of the logistics centers optimal placing is an important task for all types of transportations. Solving it for real problems of a region or country leads to mathematical algorithms of high complexity. The paper proposes a mathematical model and a new method for solving the problem of logistics centers optimal placement of a two-tier transportation network based on the mathematical apparatus of a cluster analysis. As geoinformation parameters of supplier plants, as well as a road topology, stations or other objects of transport infrastructure are given, there is the problem of an optimal choice of logistics centers. For example, logistics centers for a railways network can be container points. The optimization criterion is minimization of the total traffic volume in ton-kilometers from production to container points. For this purpose, the model of partitioning objects into clusters is used as an optimization mathematical model. The required clusters are subsets of production points with their own centers (container points). Since cluster centers must be located at railway stations, the article suggests a new clustering algorithm with a projection. The paper investigates the possibilities of such clustering algorithm called k-means pro. It also considers the methodology of selecting the number of centers (clusters) by a generalized economic indicator of transportation costs and costs for creating logistics centers. Based on the created software, there are some examples of calculations for enterprises and railways of the Volga Federal District.
Аннотация:Выбор оптимального расположения логистических центров является актуальной задачей для всех видов перевозок. Решение ее для реальных задач региона или страны приводит к математическим алгоритмам высокой сложности. В статье предлагаются математическая модель и новый метод решения задачи оптимального размещения логистических центров двухуровневой сети перевозок на основе применения математического аппарата кластерного анализа. При заданных геоинформационных параметрах производств-поставщиков, а также заданной топологии дорог, станций или других объектов транспортной инфраструктуры ставится задача оптимального выбора логистических центров. Для сети железных дорог логистическими центрами могут быть, например, контейнерные пункты. Критерием оптимизации является минимизация общего суммарного объема перевозок в тонно-километрах от производств до контейнерных пунктов. Для этого в качестве оптимизационной математической модели используется модель разбиения объектов на кластеры. Искомыми кластерами являются подмножества точек-производств со своими центрами – контейнерными пунктами. Поскольку центры кластеров обязательно должны находиться на железнодорожных станциях, предложен новый алгоритм кластеризации с проекцией. Исследованы возможности такого алгоритма кластеризации, названного k-means pro. Рассмотрена методика выбора количества центров (кластеров) по обобщенному экономическому показателю затрат на перевозки и создание логистических центров. Приведены примеры расчетов для предприятий и железных дорог Приволжского федерального округа на основе созданного ПО.
| Authors: B.A. Esipov (bobpereira@yandex.ru) - Samara National Research University (Associate Professor), Samara, Russia, Ph.D | |
| Keywords: projection defect, projection clustering, logistic centers, two-tier network container transportations |
|
| Page views: 6349 |
PDF version article Full issue in PDF (29.74Mb) |
В настоящее время задача реконструкции и развития транспортной системы страны сталкивается с трудностями поиска оптимальных мест размещения транспортных коммуникаций. Современные решения по размещению элементов транспортных систем не всегда отвечают требованиям рациональности вследствие сложности и многовариантности задач. Основной проблемой является то, что строительство транспортных объектов производится однократно, в то время как эксплуатация – в течение многих десятилетий [1].
В работе решается задача выбора мест расположения транспортных объектов при заданных координатах точек производств, их объемах продукции, а также при заданной сети дорог в виде множества точек (станций), где возможно построение логистических центров. В качестве критерия оптимизации выступают общие затраты на перевозку и создание новых объектов инфраструктуры. Поскольку объемы перевозимой продукции фиксированные, оптимизация связана прежде всего с сокращением расстояний при перевозках от производств до логистических центров и обратно [1]. Постановка задачи оптимального размещения транспортных объектов на основе теории центров обслуживания потребителей приводит к многоразмерным задачам дискретной оптимизации на основе переборных алгоритмов NP-сложности и не позволяет решать поставленные задачи для десятков тысяч предприятий и тысяч железнодорожных станций [2–4]. Классические задачи о кратчайшем расстоянии между точками и их центром на плоскости решаются, когда точки, для которых находится центр, заданы. В общем случае оптимизация расстояний от точек до центров подмножеств точек должна достигаться вариацией самих подмножеств точек, что приводит к задаче оптимальной кластеризации исходного множества точек и определения оптимальных центров кластеров. Известно, что при боль- ших n полный перебор таких вариантов определяется величиной порядка kn–1, где k – количество кластеров, а n – количество точек (производств). Поэтому для практических задач необходимы методы, радикально уменьшающие перебор вариантов [4, 5]. Математическая модель размещения транспортных объектов на основе кластерного анализа В данной работе для оптимального выбора мест расположения контейнерных пунктов (КП) и контейнерных накопительно-распределительных центров (КНРЦ) предлагается применить универсальную методологию разбиения множества объектов с заданными свойствами на подмножества при заданных критериях разбиения и получения центров этих подмножеств, обладающих оптимальными свойствами. В качестве такой универсальной процедуры предлагается использовать математические методы кластеризации объектов, известные как кластерный анализ [5, 6]. Геометрическая близость объектов от центра гарантирует минимизацию расстояний при перевозке, а учет веса каждого объекта, выражающего объем перерабатываемой объектом продукции, оптимизирует общие затраты на перевозки. Большое достоинство кластерного анализа и в том, что он позволяет производить разбиение объектов не по одному параметру, а по целому набору признаков. Анализ литературы по кластерному анализу и опыт использования стандартных программных средств кластерного анализа позволяют утверждать, что принципиально возможно решать поставленные задачи для практических задач большой размерности (для федеральных округов и всей страны в целом) [7, 8]. Однако при подходе к решению практических задач оптимизации местоположения КП и КНРЦ на основе идеи кластеризации возникла новая проблема, решение которой развивает сами методы кластерного анализа. Так, при применении алгоритмов кластеризации по известному методу k-means [6] считается, что оптимальный центр может находиться в любой точке пространства параметров, определяющих объекты. Если параметры – это геометрические координаты центров производства, то центр лежит в любой точке плоскости. На практике следует рассмотреть случай, когда центр обязательно должен находиться в одной из заданных точек (например, на железнодорожной линии или станции). Таким образом, при решении задачи определения мест КП и КНРЦ приходится решать задачу кластеризации с проекцией на функцию, когда центр обязательно должен находиться на железнодорожной магистрали, или с проекцией на точки – на железнодорожной станции. В работе предлагается новый алгоритм класте- ризации с проекцией на множество точек, названный k-means pro, и исследуется возможность его применения в практических задачах проектирования транспортной инфраструктуры [4]. Входными данными алгоритма являются множество объектов кластеризации X = {x1, …, xn}, их веса V = {v1, …, vn} и допустимое множество проекций Y = {y1, …, yp}. Каждый j-й объект и каждая допустимая точка-проекция заданы в G-мерном пространстве RG, то есть xj = (xj1, …, xjG) и yr = (yr1, …, yrG). Единственным управляющим параметром является число кластеров k, на которые производится разбиение S = {S1, …, Sk} множества Х. В результате получается несмещенное разбиение S* = {S*1, …, S*k}, центры которого – это оптимальное множество проекций C* Í Y. Введем следующие обозначения: n – количество объектов кластеризации; p – количество точек допустимого множества проекций; i, i’ – номер кластера; j – номер объекта; r – номер точки множества проекций; l – номер координаты точки; m – номер текущей итерации; G – размерность пространства, в котором выполняется кластеризация. Расстояние между точками в G-мерном пространстве определяется по евклидовой метрике, где tl и t2 – две любые точки пространства RG:
Алгоритм k-means pro. 1. Выберем начальное разбиение
2. Пусть построено m-е разбиение
Вычислим набор векторов средних где 3. Определим множество проекций средних для текущего разбиения:
4. Построим минимальное дистанционное разбиение, порождаемое множеством Cm, и возьмем его в качестве 5. Если Sm+1 ¹ Sm, то переходим к п. 2, заменив m на m+1; если Sm+1 = Sm, то полагаем Sm = S*, Cm = C* и заканчиваем работу алгоритма. Поскольку на последовательности разбиений S0, S1, …, Sm, строящейся в алгоритме, функционал качества разбиений Начальное разбиение Для проверки устойчивости результатов и получения различных зависимостей менялся выбор е0, получались 100 различных реализаций, из них выбиралась наилучшая, а также усреднялись полученные параметры для построения различных графиков. Исследование алгоритма k-means pro
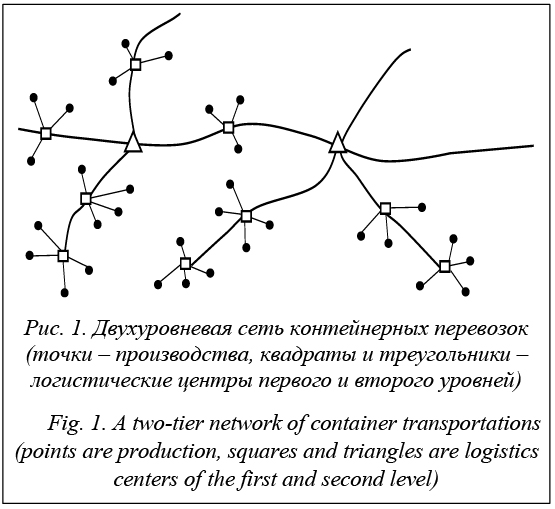
Разработанный алгоритм применен для решения задачи оптимального выбора мест расположе- ния КП для заданных 900 производств и 137 железнодорожных станций Приволжского федерального округа (ПФО). Производства определялись географическими координатами и объемом контейнеропригодной продукции. Множество железнодорожных станций задано на сети 7 железных дорог, расположенных на территории ПФО. Результат при k = 42 показан на рисунке 4, где точками изображены заданные производства, малыми квадратиками – железнодорожные станции, большими квадратами – найденные станции-КП. Показаны кластеры производств.
Представляет интерес соотношение показателей качества кластеризации для обычного алгоритма и алгоритма кластеризации с проекцией. В первом случае центры кластеров определяются исключительно из свойств расположения объектов (точек) и критерия оптимальности кластеризации D. Такую кластеризацию в контексте данной работы можно назвать свободной. В рассматриваемом случае центры кластеров обязательно должны находиться на железнодорожной линии, и это является ограничением для самого процесса кластеризации. Алгоритм каждый раз проектирует центры кластеров на железнодорожную линию. В результате получаем вариант кластеризации с проекцией и, очевидно, с другим значением критерия Dпр. Для классического алгоритма k-means
Для k-means pro
Назовем дефектом проекции разницу критериальных величин качества свободной кластеризации и кластеризации с проекцией: Δ = Dпр – D. Зависимость Δ /D от k для производств ПФО показана на рисунке 7. Из графика видно, что при значительном увели- чении числа КП растет дефект проекции, то есть в некоторых случаях, когда разница существенна, возможно, выгоднее строить КП на новых станциях, а не размещать их в существующей инфраструктуре. Вышеприведенные графики дают возможность количественно оценить такие варианты. Выбор оптимального количества кластеров Выбор оптимального числа кластеров является проблемным вопросом кластерного анализа [5, 7]. Рассмотрим экономический подход к выбору оптимального количества кластеров k. В данном случае это число определяет количество логистических центров (КП). Итак, пусть количество КП не задано (k неизвестно), но известна приведенная к одному году нормативная стоимость затрат на создание одно- го КП – с. Тогда в качестве критерия оптимиза- ции при кластеризации нужно взять величину общих затрат на перевозку плюс затраты на созда- ние КП:
Поскольку первое слагаемое в (1) уменьшается при увеличении k, а второе увеличивается от k, величина E имеет минимум, который и определяет оптимальное k при условии, что эта величина попадает в интервал, определяемый ограничениями (2) и (3). На рисунке 8 показаны возможные случаи решения оптимизационной задачи (1), (2), (3). Очевидно, что ограничения (2) и (3) существенно влияют на выбор оптимального k.
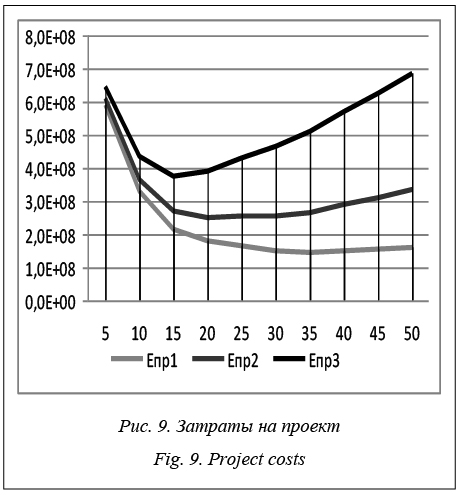
Рассмотрим результаты оптимизации количества КП по критерию E для ПФО в виде графика зависимости общих затрат от k при различных с.
В предложенной методике оптимальное количество КП зависит от величины с. Эта величина является, во-первых, нормативной, то есть усредненной и зависящей от даты проектирования, во-вторых, приведенной, так как увязывает текущие затраты Е1 и капитальные (единовременные) затраты сk. Как известно, это связано также с необходимостью оценки срока окупаемости КП. Все это показывает, что оптимизация числа k возможна только при тщательной экспертной оценке величины c. Заключение Полученные результаты показывают возможность и порядок расчетов различных вариантов постановок задач оптимизации размещения транспортных объектов на основе применения алгоритмов кластерного анализа. Разработанный алгоритм k-means pro и программные средства его реализации показали высокую эффективность при решении прикладных задач. Созданные программные средства применены для решения задач проектирования инфраструктуры перевозок на примере ПФО. Предложенные в статье модели, алгоритм и программы позволят лицам, принимающим решения, количественно оценить оптимальные и подоптимальные варианты в конкретных условиях проектирования при оптимизации количества терминальных объектов и мест их размещения. Литература 1. Кириллова А.Г. Оптимальный выбор расположения терминала как логистического центра при организации контейнерных и контрейлерных перевозок // Транспорт: наука, техника, управление. 2010. № 10. С. 22–25. 2. Москвичев О.В. Модели, методы и алгоритмы оптимизации контейнерно-транспортной системы железнодорожного транспорта на основе кластерного подхода // Транспорт Урала. 2017. № 2. С. 36–60. 3. Михалевич B.C., Трубин В.А., Шор Н.З. Оптимизационные задачи производственно-транспортного планирования. М.: Наука, 1986. 260 с. 4. Есипов Б.А., Москвичев О.В., Складнев Н.С., Алешинцев А.О. Разработка и исследование алгоритма кластеризации с проекцией для решения задач оптимизации транспортной инфраструктуры // Перспективные информационные технологии: тр. Междунар. науч.-технич. конф. Самара: Изд-во СамНЦ РАН, 2017. С. 633–637. 5. Мандель И.Д. Кластерный анализ. М.: Финансы и статистика, 1988. 177 с. 6. Прикладная статистика. Классификация и снижение размерности; [под ред. С.А. Айвазяна]. М.: Финансы и статистика, 1989. 607 с. 7. Миркин Б.Г. Методы кластер-анализа для поддержки принятия решений: обзор: препр. WP7/2011/03. М.: Изд-во ВШЭ, 2011. 88 с. 8. Бериков В.Б., Лбов Г.С. Современные тенденции в кластерном анализе. Н.: Изд-во Ин-та матем. им. С.Л. Соболева СО РАН, 2009. С. 16–21. 9. MacQueen J. Some methods for classification and analysis of multivariate observations. Proc. 5th Berkeley Symp. on Math. Statistics and Probability, 1967, pp. 281–297. 10. Arthur D. and Vassilvitskii S. How Slow is the k-means Method? Proc. 2006 Symp. on Comp. Geometry (SoCG), ACM Press., pp. 144–153. |
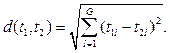
 ,
,
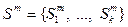 .
.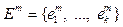 , то есть
, то есть 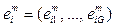 ,
,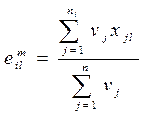 ; ni – количество точек i-го кластера.
; ni – количество точек i-го кластера. .
.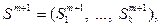 то есть
то есть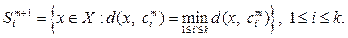
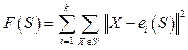 не возрастает, причем F(Sm) = F(Sm+1), только если Sm=Sm+1, для любого начального разбиения S0 алгоритм через конечное число шагов заканчивает работу. Сложность вычислений по этому алгоритму оценивается как O(nkm), где n – количество кластеризуемых объектов; k – количество кластеров; m – количество итераций.
не возрастает, причем F(Sm) = F(Sm+1), только если Sm=Sm+1, для любого начального разбиения S0 алгоритм через конечное число шагов заканчивает работу. Сложность вычислений по этому алгоритму оценивается как O(nkm), где n – количество кластеризуемых объектов; k – количество кластеров; m – количество итераций.

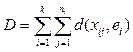 ,
,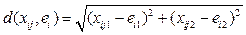 .
.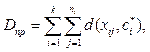
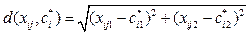 .
.
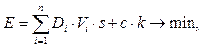 (1)
(1)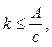 (2)
(2)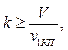 (3)
(3) – затраты на перевозку; Di – расстояние от точки-производства до КП; Vi – объем производства контейнеропригодной продукции i-го производства; s – тариф на перевозку 1 тонно-километра.
– затраты на перевозку; Di – расстояние от точки-производства до КП; Vi – объем производства контейнеропригодной продукции i-го производства; s – тариф на перевозку 1 тонно-километра.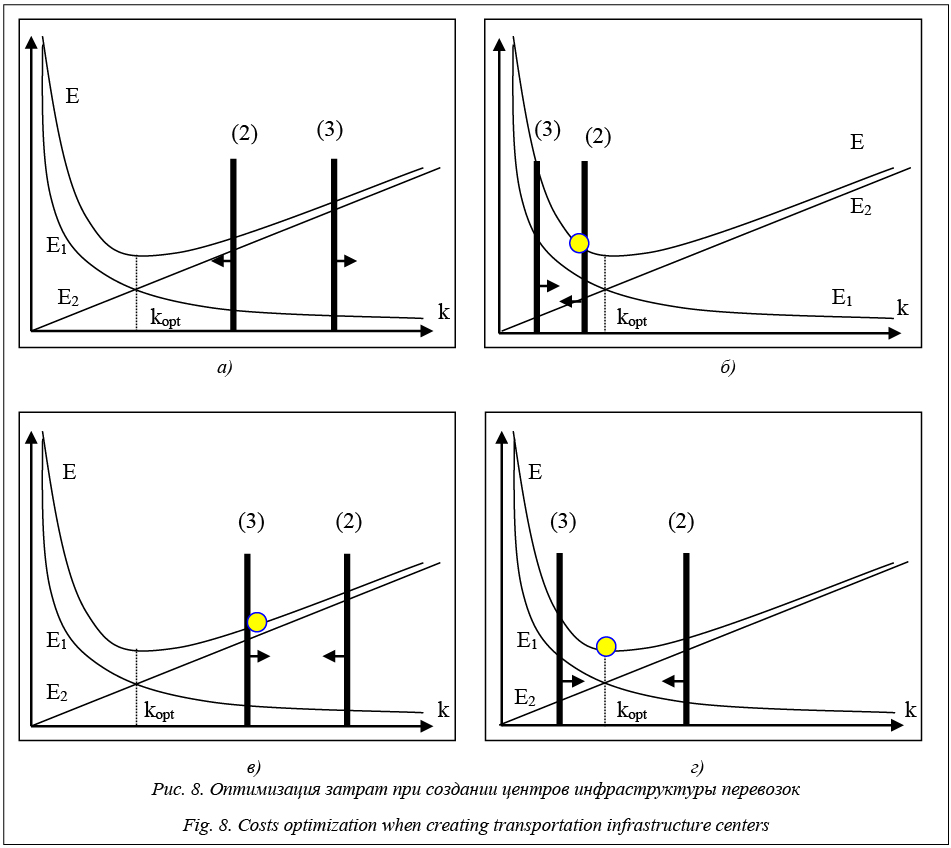
| Permanent link: http://swsys.ru/index.php?id=4390&lang=en&page=article |
Print version Full issue in PDF (29.74Mb) |
| The article was published in issue no. № 1, 2018 [ pp. 5-11 ] |
Back to the list of articles