Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: (byg@yandex.ru) - , Ph.D, (midli@mail.ru) - , Ph.D | |
| Ключевое слово: |
|
| Page views: 15661 |
Print version Full issue in PDF (1.26Mb) |
В статье рассмотрено решение задачи проверки корректности статистической информации, представляемой ее первичными источниками (учреждениями, предприятиями, отдельными юридическими и физическими лицами), для контроля тех или иных показателей, например, экономической или социологической ситуации в регионе. Метод решения основан на известных статистических процедурах, но является оригинальным, разработанным специально под условия данной задачи. Имеется множество первичных источников информации, предоставляющих, например, ежеквартально информацию в соответствующий орган ее сбора и первичной обработки. Информация собирается и хранится в базах данных (БД). Предположим, что собраны массивы такой информации за несколько последних лет. Характер информации различный. Есть источники, данные от которых меняются в соответствии с некими трендами, есть источники, характеризующиеся чисто случайными данными. Известно, что в системах сбора и обработки данных поступающая информация может быть искажена различного рода помехами. Относительно поступающих данных можно принять следующие формальные предположения. 1. Данные по каждому источнику информации независимы друг от друга, во всяком случае на этапе предварительного анализа могут рассматриваться отдельно. 2. Данные имеют числовой характер, поступают к потребителю в последовательные моменты времени, следовательно, значения каждого показателя {x(t)} = {xt}, где t – моменты календарного времени, могут рассматриваться как временной ряд. 3. Каждый из таких рядов соответствует математической модели вида x(t) = f(t) + e(t), (1) где f(t) – детерминированная (трендовая) составляющая; e(t) – случайная составляющая типа белого шума (с независимыми случайными значениями), то есть модели с трендом (линейным, нелинейным, сезонным, циклическим и т.д.), либо математической модели вида x(t) = m + e(t), (2) где m = const, то есть модели без тренда. 4. Случайная составляющая e(t) предполагается стационарной, по крайней мере для нескольких последних наблюдений, имеющей нулевое математическое ожидание, конечную дисперсию и неизвестное, но непрерывное симметричное одномодальное распределение (при моде, совпадающей с математическим ожиданием, то есть равной нулю). 5. Для каждого источника вид и параметры моделей с течением времени могут изменяться, но в течение нескольких (5¸11) последних наблюдений эти модели сохраняют стационарность по параметрам. Известные математические подходы для решения поставленной задачи разработаны только для модели (2) – это методы выделения аномальных или резко выделяющихся наблюдений [1], предполагающие знание закона распределения составляющей e (обычно постулируется нормальный закон). Предлагаемая методика проверки информации на достоверность включает в себя выполнение следующих этапов. Этап 1. Отбор N последних имеющихся значений рассматриваемого показателя, то есть значений xt-1, xt-2,…, xt-N (рекомендуемый диапазон значений: 5 £ N £ 11). Этап 2. Проверка гипотезы о виде модели временного ряда – (1) или (2), то есть проверка гипотезы о наличии или отсутствии в данных временного тренда. Если принимается гипотеза о справедливости модели (1), то переход к этапу 4, в противном случае, к этапу 3. Этап 3. Оценивание параметра m модели (2) и дисперсии случайной составляющей e. Переход к этапу 5. Этап 4. С использованием модели тренда расчет прогнозируемого значения Этап 5. Ввод очередного значения xt. В случае справедливости модели (1) – переход к этапу 7. Этап 6. Проверка гипотезы об аномальности (недостоверности) нового значения xt. В случае принятия гипотезы – выдача соответствующего сообщения и ожидание реакции пользователя. При отвержении гипотезы – переход к этапу 1 (с подстановкой t = t + 1). Этап 7. С учетом найденных на этапе 4 прогнозируемого значения Поясним некоторые этапы более детально. Второй этап: проверка гипотезы о виде модели временного ряда. 1. Постулируется модель тренда в виде полинома второй степени: f(t) = c0 + c1t + c2t2, (3) где c0¸c2 – коэффициенты модели. 2. Методом наименьших квадратов [2] определяется вектор с = (с0, c1, c2)T данных коэффициентов по отобранным данным: с = (FT×F)-1 ×FT×Y, (4) где в данном случае
Замечание. В случае поквартального представления данных число N используемых наблюдений необходимо выбирать нечетным, чтобы не остались незамеченными сезонные изменения. 3. Проверяется гипотеза о наличии тренда, которая базируется на следующем утверждении. Достаточным условием для принятия гипотезы, что степень модели тренда не нулевая, является значимость коэффициентов при первой или второй степенях t. Поясним данное утверждение. Казалось бы, достаточно ограничиться проверкой только коэффициента при t, но он может быть нулевым, если тренд – четная функция относительно середины интервала наблюдений. Для выяснения значимости r-го коэффициента модели (r = 1,2) сформулируем нуль-гипотезу H0: cr=0, (6) зададимся уровнем значимости a (например, a = 0.1, a = 0.05 и т.д.) и на основании неравенства Чебышева для случайных величин с непрерывным симметричным одномодальным распределением [3] и с учетом (6) запишем неравенство: P(| где оценка дисперсии
где
а drr – r-й диагональный элемент дисперсионной матрицы (r = 0,1,2) D = F-1 = (FT×F)-1. (10) Полагая теперь a = найдем: dr = Откуда получаем неравенство для проверки нуль-гипотезы: при выполнении которого данная гипотеза отвергается (с уровнем значимости a). Таким образом, если хотя бы один из коэффициентов (c1 или c2) признается значимым, принимается модель (1), в противном случае – модель (2). Третий этап: оценивание параметра m модели (2) и дисперсии случайной составляющей e. Соответствующие оценки находятся по формулам [2-4]:
Шестой этап: проверка гипотезы, что новое поступившее значение xt является аномальным (недостоверным) при справедливости модели (2). Проверка данной гипотезы осуществляется на основе неравенства Чебышева (как отмечалось, такая форма данного неравенства справедлива при случайной составляющей модели с непрерывным симметричным одномодальным распределением): P(| Задаваясь уровнем значимости a (например, a=0.05), запишем P(| откуда с учетом (16) получаем неравенство
при выполнении которого гипотеза о недостоверности новой информации принимается, в противном случае данная гипотеза отвергается. Четвертый этап: с использованием модели тренда расчет прогнозируемого значения Предлагается комбинированная модель тренда, объединяющая модели Хольта-Винтерса и авторегрессии 2-го порядка [5]. Метод Хольта-Винтерса является усовершенствованием метода экспоненциального сглаживания временного ряда. При использовании метода необходимо последовательно вычислять сглаженные значения ряда и значение тренда, накопленное в любой точке ряда. Соответствующие формулы имеют вид:
x1t = y1t-1 + y2t-1, (20) где через x1t, y1 и y2 обозначены соответственно прогнозируемое значение ряда, сглаженное значение ряда и тренд, рассчитываемые по всем точкам ряда, a и b – константы сглаживания, относящиеся к оценкам уровня и тренда соответственно. Выбор значений этих констант является достаточно субъективным. Лучше всего начать моделирование с a=b=0.7, а затем по необходимости их несколько варьировать. В первой точке ряда значения y11 и y21 не рассчитываются, для их расчета не существует предшествующих экспериментальных значений. Во второй точке ряда принимается, что сглаженное значение y12 в точности равно наблюдаемому x2, а микротренд за этот период считается линейным и рассчитывается как разность между текущим и прошлым значениями отклика y2 = x2 – x1. Начиная с третьей точки, можно пользоваться указанными выше формулами. Модель авторегрессии 2-го порядка позволяет достаточно хорошо прогнозировать циклические (в том числе сезонные) тренды. В данном случае математическое описание авторегрессии имеет вид: x2t = c0(t)×xt-1 + c1(t)×xt-2, (21) где c0(t) и c1(t) – коэффициенты модели, которые определяют "скользящим" методом наименьших квадратов с использованием только M последних наблюдений (рекомендуемое значение: 4 £ M £ 7, при этом должно выполняться, естественно, M < N) и в соответствии с соотношениями: с(t) = (F(t)T×F(t))-1 ×F(t)T×Y(t), (22) где с(t) = [c0(t), c1(t)]T,
Агрегирование двух частных моделей реализуется с помощью логической формулы: "Если (|x1t-1 – xt-1| £ |x2t-1 – xt-1|), то xpt = x1t, иначе xpt = x2t", (24) где через xpt= Иначе говоря, если для предыдущего момента времени более точной оказывалась модель Хольта-Винтерса, при выполнении очередного прогноза необходимо использовать ее, в противном случае (если более точной была модель авторегрессии) необходимо использовать модель авторегрессии. Пример 1. Приводимые ниже результаты (моделирование проводилось в среде Mathcad) демонстрируют работу такой гибридной модели, когда данные генерируются соотношением xt=5sin(0.1t)+0.01t2+et, x0=x1=0, t=2,3,… , (25) то есть содержат циклическую составляющую, нелинейный (квадратичный тренд) и случайную компоненту (et Î (-0.1,0.1)). Результаты прогноза отражает рисунок 1. При расчетах принято M=6. Каждая из используемых частных моделей дает худший результат. Как показали вычислительные эксперименты, предложенная гибридная модель, вообще говоря, более устойчива по отношению к случайной составляющей временного ряда. Рисунок 2 иллюстрирует то, как комбинированная модель прогнозирует значения циклического тренда с периодом в 4 временных интервала (квартала) при данных, генерируемых по выражению xt=5sin(2pt/4). (26) Как видно, комбинированная модель дает идеальное совпадение прогнозируемых и реальных значений. Реализация рассматриваемого четвертого этапа сводится к реализации следующей процедуры: 1) по N имеющимся последним значениям ряда xt, xt-1,…, xt-N с использованием формул (19-24) рассчитывается прогнозируемое значение xpt = 2) по нескольким (N1=5¸9; N1
Заметим, что данная оценка, скорее всего, является заниженной, но это только уменьшает вероятность пропуска недостоверного наблюдения. Седьмой этап: с учетом найденных на этапе 4 прогнозируемого значения Проверка данной гипотезы осуществляется исходя практически из тех же соображений, что и на этапе 6, и сводится к проверке неравенства:
при выполнении которого гипотеза о недостоверности данных принимается (с уровнем значимости a), в противном случае отвергается. Для иллюстрации приведенной методики рассмотрим следующий пример. Пример 2. В среде Mathcad сгенерирована следующая последовательность из 8 независимых случайных чисел, равномерно распределенных в интервале (0, 10) и приведенных с точностью до двух знаков после запятой: 0.01, 1.93, 5.85, 3.50, 3.04, 1.74, 7.10, 8.23. Этап 1. Используем первые 7 из них (N=7) для выяснения вопроса, не является ли восьмое значение недостоверным. Будем полагать, что данные представлены через единичные интервалы времени. Этап 2. 1. Постулируем квадратичную модель тренда (3). 2. Запишем выражения для соответствующих матрицы и вектора, полагая, что первый момент времени – 0, а (t-1)-й равен 6, и методом наименьших квадратов по формуле (4) найдем вектор коэффициентов с=(1.07,1.01,-0.06)T:
3. Далее, задаваясь уровнем значимости a= 0.05 и в соответствии с выражениями (8)-(12), находим: δ1=3.40, δ2=0.09. Теперь, используя (13), делаем вывод, что данное неравенство не выполняется ни для первого, ни для второго коэффициента квадратичной модели тренда (3), то есть принимается гипотеза, что представленный временной ряд тренда не содержит и, следовательно, для него справедлива модель (2). В соответствии с разработанной методикой в этом случае осуществляется переход к третьему этапу. Этап 3. По представленным значениям и по соотношениям (14), (15) находим: m=3.31, σ2=6.03. Переходим к этапу 5. Этап 5. Очередное значение xt=x7=8.23. Этап 6 сводится к проверке неравенства (18), которое в данном случае имеет левую часть |xt–m|= =|8.23–3.31|=4.92 и (при уровне значимости a=0.05) правую часть Сопоставление левой и правой частей показывает, что неравенство (18) не выполняется, следовательно, значение xt=8.23 нельзя считать недостоверным (хотя оно и выделяется по сравнению с другими представленными значениями временного ряда). Полученный вывод является правильным. Поставленная задача по выделению недостоверных данных представляется решенной. Очевидные достоинства методики: минимум априорной информации, простота вычислений, возможность вероятностной интерпретации результата (то есть гарантируется вероятность ошибки 1-го рода на уровне a). Список литературы 1. Айвазян С.А., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Основы моделирования и первичная обработка данных. Справочное изд. - М.: Финансы и статистика, 1983. 2. Хартман К., Лецкий Э., Шефер В. и др. Планирование эксперимента в исследовании технологических процессов. - М.: Мир, 1977. 3. Корн Г., Корн Т. Справочник по математике для научных работников и инженеров. - М.: Наука, 1974. 4. Гмурман В.Е. Теория вероятностей и математическая статистика. - М.: Высш. шк., 1977. 5. Бокс Дж., Дженкинс Г. Анализ временных рядов. Прогноз и управление. - М.: Мир, 1974. - Вып.1. |
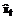 и нахождение оценки остаточной дисперсии.
и нахождение оценки остаточной дисперсии.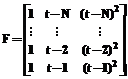 ,
,  . (5)
. (5)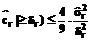 , (7)
, (7) находится с использованием стандартного подхода [2], по выражению
находится с использованием стандартного подхода [2], по выражению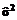 drr, (8)
drr, (8)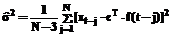 , (9)
, (9)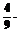
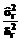 , (11)
, (11)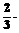
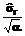 . (12)
. (12)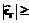
 ×
× , (14)
, (14)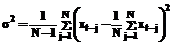 . (15)
. (15)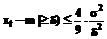 ,d>0. (16)
,d>0. (16)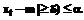 , (17)
, (17) , (18)
, (18)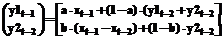 , (19)
, (19)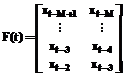 ,
, 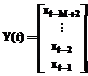 . (23)
. (23)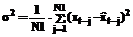 . (27)
. (27)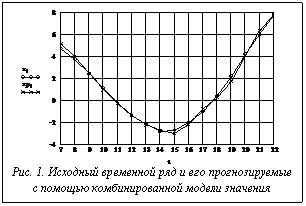
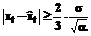 , (28)
, (28)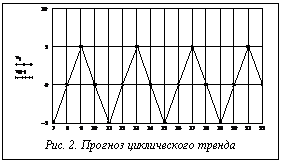
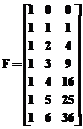 ,
, 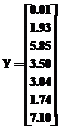
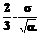 =7.32.
=7.32.| Permanent link: http://swsys.ru/index.php?id=466&lang=en&page=article |
Print version Full issue in PDF (1.26Mb) |
| The article was published in issue no. № 1, 2006 |
Perhaps, you might be interested in the following articles of similar topics:
- Новый подход к проблеме коллективного выбора на базе удовлетворения взаимных требований сторон
- Нейроподобная сеть для решения задачи оптимизации антенной решетки
- Макроэкономическая балансовая модель для стран с элементами переходной экономики
- Сравнение сложных программных систем по критерию функциональной полноты
- Системы баз данных и знаний, разработанные в Республике Куба
Back to the list of articles