Journal influence
Bookmark
Next issue
Developing ontology schemas based on spreadsheet transformation
Abstract:Using ontologies is a widespread practice in the in creating intelligent systems and knowledge bases, in particular, for the conceptualization and formalization of knowledge. However, most modern ap-proaches and tools provide only manual manipulation of concepts and relationships, which is not al-ways effective. In this regard, using various information sources, including spreadsheets, is relevant for the automated creation of ontologies. This paper describes a method for the automated creation of ontological schemes in the OWL2 DL format based on the analysis and transformation of data extracted from spreadsheets. A feature of the method is the use of the original canonical relational form for the intermediate representation of spreadsheets, which provides the unification of input data. The method is based on the principles of model transformation and comprises four primary stages: converting the original spreadsheets with an arbitrary layout into a canonical (relational) form; obtaining fragments of the ontological scheme; ag-gregation of separate fragments of the ontological scheme; generation of the code of the ontological scheme in the OWL2 DL format. The method is implemented in the form of two software tools integrat-ed by the data: TabbyXL as the console Java application for table conversion and the PKBD.Onto plugin as the extension module for Personal Knowledge Base Designer (software for expert systems prototyping). The transformation of a spreadsheet with information about minerals is considered as an illustrative example, and the transformation result is presented in the form of a fragment of an ontolog-ical scheme. The method and tools are used in the educational process at the Institute of Information Technologies and Data Analysis of the Irkutsk National Research Technical University (INRTU).
Аннотация:Использование онтологий является широко распространенной практикой при создании интеллектуальных систем и баз знаний, в частности, для концептуализации и формализации знаний. Большинство современных подходов и инструментальных средств обеспечивают только ручное манипулирование концептами и отношениями, что не всегда эффективно. В связи с этим для автоматизированного формирования онтологий актуально использование различных информационных источников, в том числе электронных таблиц. В данной работе описывается метод автоматизированного создания онтологических схем в формате OWL2 DL на основе анализа и преобразования данных, извлекаемых из электронных таблиц. Особенностью метода является использование для промежуточного представления электронных таблиц оригинальной канонической реляционной формы, обеспечивающей унификацию входных данных. Метод основан на принципах трансформации моделей и состоит из четырех основных этапов: преобразование исходных электронных таблиц с произвольной компоновкой в каноническую (реляционную) форму; получение фрагментов онтологической схемы; агрегация от-дельных фрагментов онтологической схемы; генерация кода онтологической схемы в формате OWL2 DL. Реализация метода осуществлена в форме двух интегрированных по данным программных средств: консольного Java-приложения TabbyXL для преобразования таблиц и модуля расширения (плагина PKBD.Onto) для системы прототипирования продукционных экспертных систем Personal Knowledge Base Designer. В качестве иллюстративного примера рассмотрено преобразование электронной таблицы с информацией о минералах, приведен результат в форме фрагмента онтологической схемы. Метод и средства используются в учебном процессе в Институте информационных технологий и анализа данных Иркутского национального исследовательского технического университета.
| Authors: Dorodnykh N.O. (tualatin32@mail.ru) - Institute of system dynamics and control theory SB RAS, Irkutsk, Russia, Ph.D, Yurin A.Yu. (iskander@irk.ru) - Institute of system dynamics and control theory SB RAS, National Research Irkutsk State Technical University, Irkutsk, Russia, Ph.D, A.V. Vidiya (vidiya_av@icc.ru) - Matrosov Institute for System Dynamics and Control Theory of Siberian Branch of Russian Academy of Sciences (Programmer), Irkutsk, Russia | |
| Keywords: code generation, transformation of models, owl, ontological schema, conceptual model, canonical spreadsheet, spreadsheet |
|
| Page views: 4849 |
PDF version article Full issue in PDF (7.81Mb) |
Использование технологий семантического веба, в том числе онтологий [1], является широко распространенной практикой при создании интеллектуальных систем и баз знаний. В большинстве случаев онтологии используются системными аналитиками и экспертами предметной области на этапах концептуализации и формализации знаний [2]. При этом применяется различный инструментарий (например, Protégé, ONTOedit, Menthor Editor, Semaphore Ontology Editor, OntoStudio, WebOnto, Fluent Editor), который в основном обеспечивает только ручное манипулирование концептами и отношениями. Слабая интеграция подобных систем с другими информационными источниками (например, с БД, текстами, таблицами, концептуальными моделями и др.) в части импорта понятий и отношений предметной области снижает эффективность данного процесса. В качестве источника информации для ав-томатизированного формирования онтологий могут выступать электронные таблицы. В настоящее время в мире циркулирует большой объем электронных таблиц, представленных в форматах HTML, XLS, XLSX, CSV [3]. Информация в данных таблицах характеризуется большим разнообразием и разнородностью компоновок, стилей, содержания, форм и форматов представления, а также высокой скоростью роста ее объема. Большой объем и свойства структуры таких таблиц делают их ценным источником в приложениях науки о данных и бизнес-аналитики. Однако, как правило, они не сопровождаются явной семантикой, необходимой для машинной интерпретации своего содержания так, как задумано их автором. Накапливаемая в таблицах информация часто является неструктурированной и нестандартизированной. Для проведения анализа этих данных необходимы их предварительное извлечении и трансформация к структурированному представлению в соответствии с заданной формальной моделью.
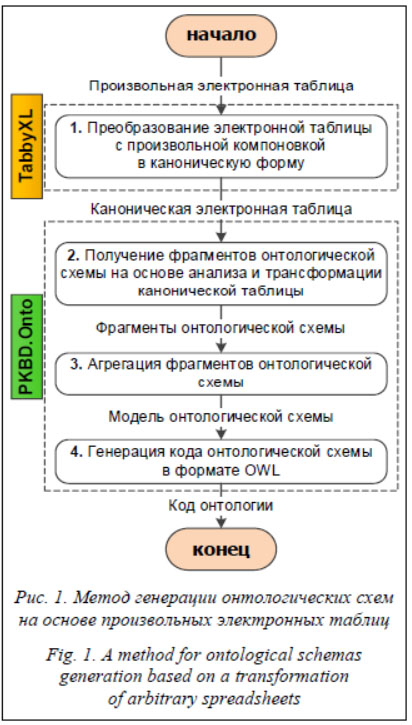
Таким образом, постановку задачи можно формализовать следующим образом: необходимо определить оператор T преобразования произвольных электронных таблиц: T: ASXLSX ® OSOWL, (1) где ASXLSX – исходная произвольная электронная таблица в формате Excel (XLSX); OSOWL – целевая онтологическая схема в формате OWL2 DL. Особенностью подхода является использование определенной канонической (реляционной) формы представления электронных таблиц, обеспечивающей унификацию входных данных. Предлагаемый подход реализован в форме программного модуля расширения, а именно плагина PKBD.Onto для системы прототипирования продукционных экспертных систем – Personal Knowledge Base Designer (PKBD) [7]. Также рассмотрен пример применения предлагаемого подхода и модуля для создания онтологических схем в формате OWL при решении учебной задачи. Метод разработки онтологических схем на основе электронных таблиц
Метод основан на принципах трансформации моделей – одного из основных понятий в области модельно-ориентированного подхода (Model-Driven Engineering) [8]. Основной осо-бенностью разработанного метода, определя-ющей его новизну, является использование канонической (реляционной) формы для представления электронных таблиц, обладающих произвольной структурой. Используя (1), подробнее рассмотрим оператор преобразования T, который с формальной точки зрения может быть представлен в виде цепочки горизонтальных экзогенных трансформаций: T = (TAS-CS, TCS-OSM, TOSM-OS), TAS-CS: ASXLSX ® CSXLSX, TCS-OSM: CSXLSX ® OSM, TOSM-OS: OSM ® OSOWL, (2) где CSXLSX – исходная электронная таблица, представленная в канонической (реляционной) форме; OSM – модель онтологической схемы; TAS-CS – набор правил трансформации исходной произвольной электронной таблицы в формате XLSX в каноническую форму; TCS-OSM – набор правил трансформации канонической элек-тронной таблицы в модель онтологической схемы; TOSM-OS – набор правил трансформации модели онтологической схемы в код онтологии на терминологическом уровне T-Box в формате OWL2 DL. Используя (2), подробнее рассмотрим основные этапы метода. Этап 1. Преобразование исходных электронных таблиц с произвольной компоновкой в каноническую (реляционную) форму. Данное преобразование (TAS-CS) включает такие фазы, как распознавание (recognition), ролевой (функциональный) и структурный анализ [9]. Используем следующую структуру канонических таблиц: CSXLSX = {D, RH, CH}, где D – блок данных, который описывает конкретные значения данных (записи), принадлежащие к одному и тому же типу данных (например, числовые, текстовые и т.д.); RH – набор заголовков строк; CH – набор заголовков столбцов (значения в ячейках блоков заголовков могут быть разделены символом «|», с помощью которого осуществляется представление иерархических отношений между заголовками (разделение категорий на подкатегории)). Эта структура основана на каноническом представлении таблиц, предложенном в [10] и адаптированном для системы TabbyXL [11], которая используется на данном этапе. Для реализации преобразования TAS-CS используется предметно-ориентированный язык Cells Rule Language (CRL) [9]. При этом набор правил может быть реализован для конкретной задачи с учетом требований к исходным и целевым данным. В результате сформирован набор CRL-правил для двух выделенных форм таблиц [5]. Эти правила учитывают следующие основные случаи. · Ячейки, расположенные в блоке заголовков столбцов и строк, могут содержать только один уровень заголовков. · Ячейки, расположенные в блоке заголовков как столбцов, так и строк, могут содержать несколько заголовков. Эти заголовки также могут быть рассмотрены как иерархические отношения. · Ячейки, расположенные в блоке заголовков столбцов (шапке), могут содержать несколько уровней заголовков, а ячейки, расположенные в блоке заголовков строк (заглушке), только один уровень заголовков. В этом случае заголовки столбцов могут быть интерпретированы как иерархические отношения, представляющие родительско-дочерние связи между разными категориями сущностей. · Ячейки, расположенные в блоке заголов-ков строк (заглушке), могут содержать несколько уровней заголовков, а ячейки, расположенные в блоке заголовков столбцов (шапке), только один уровень заголовков. В таком случае заголовки строк могут быть интерпретированы как иерархические отношения, представляющие родительско-дочерние связи между разными категориями сущностей. При этом осуществляется разделение каждой объединенной ячейки в исходной произвольной электронной таблице. Этап 2. Получение фрагментов онтоло-гической схемы. Основная цель этого этапа – получить шаблонные онтологические фрагменты в виде набора классов и их отноше-ний (свойств-объектов и свойств-значений), которые описывают определенную предметную область, на основе анализа и трансформации данных из канонических электронных таблиц. Анализ канонических электронных таблиц осуществляется построчно. При этом ячейки могут содержать несколько значений (понятий) с разделителем «|». Значение ячейки с разделителем «|» интерпретируется как иерархия либо классов (понятий), либо конкретных объектов (экземпляров классов), либо свойств. В авторском методе используются следующие основные эвристические правила преобразования (TCS-OSM) канонических электронных таблиц. Правило 1. ЕСЛИ RH соответствует только одному CH, ТО RH преобразуется в класс со свойствами из CH. Правило 2. ЕСЛИ RH соответствует только одному CH и в то же время RH содержит два значения с разделителем «|», то есть RH = (RH – 1, RH – 2), ТО RH – 1 преобразуется в класс со свойствами из CH и с дополнительным свойством Name, которое соответствует второму значению в RH – 2. Правило 3. ЕСЛИ RH содержит два значения с разделителем «|» и они соответствуют двум значениям CH с разделителем «|», ТО RH и CH преобразуются в соответствующие классы и указывается связь между ними. Правило 4. ЕСЛИ RH соответствует трем значениям CH, то есть CH = (CH – 1, CH – 2, CH – 3), с разделителем «|», ТО RH преобразуется в класс со свойством CH – 1, а CH – 2 и CH – 3 преобразуются в соответствующие классы и указывается связь между ними. Подобные правила разработаны и для ситуации, когда RH и CH меняются местами, то есть структура классов формируется исходя из меток в блоке заголовков столбцов CH. При этом все полученные иерархические связи интерпретируются как объектные свойства (отношения между классами). По умолчанию значения свойств (range) устанавливаются на основе записей из блока данных D. Основными результатами этого этапа являются фрагменты модели онтологической схемы OSM. Эти фрагменты необходимо агрегировать, включая операции по уточнению названий классов, их свойств и отношений, а также их возможное слияние и разделение. Этап 3. Агрегация отдельных фрагментов онтологической схемы в единую полную модель OSM. Данная модель предназначена для унифицированного представления и хранения знаний, извлеченных из различных информационных источников. Модель позволяет абстрагироваться от особенностей описания знаний на различных языках и их диалектах, используемых при реализации онтологий (OWL, RDFS и др.). Используя (2), подробнее опишем основные элементы OSM: OSM = (C, OP, DP, DT), где C – набор классов; OP – набор объектных свойств; DP – набор свойств-значений; DT – набор типов данных XML-схемы. Для автоматического агрегирования фрагментов онтологической схемы используются следующие эвристические правила. · Классы с одинаковыми именами объединяются, формируя общий набор свойств-значений и объектных свойств. · Дублирующие классы с одинаковыми именами и структурой свойств удаляются. · Классы с похожими именами объединяются. Полученные фрагменты модели онтологической схемы могут описывать одни и те же объекты или процессы. Предлагается использовать простой метод сравнения строк, основанный на расстоянии Левенштейна [12], чтобы определить сходство между двумя именами классов. Если расстояние Левенштейна меньше или равно 3, то будем считать классы подобными. Однако этого может быть недостаточно, так что, обращаем внимание и на структуру классов (названия свойств должны частично совпадать). · Создание новых объектных свойств (отношений между классами), если существуют одноименные классы и свойства-значения. При этом создается новый класс с именем свойства-значения, а одноименное свойство-значение удаляется. · Повторяющиеся объектные свойства между классами удаляются. · Дублирующие свойства-значения удаляются. Этап 4. Генерация кода онтологической схемы в формате OWL2 DL на основе модели онтологической схемы (TOSM-OS). Данное преобразование можно описать с помощью специальных языков трансформации моделей, например, Transformation Model Representation Language (TMRL) [13]. В предлагаемом исследовании для реализации трансформаций авторы использовали язык программирования общего назначения. При этом все трансформации можно наглядно представить в виде следующего набора соответствий:
Полученный OWL-код онтологии может быть уточнен (модифицирован) с помощью различных редакторов онтологического моделирования, например Protégé и др. Таким образом, основным результатом метода является набор классов и их свойств, которые определяют онтологическую схему на терминологическом уровне T-Box. Программная реализация Первый этап метода разработки онтологических схем на основе анализа и трансформации электронных таблиц реализован с использованием средства TabbyXL. Это консольное Java-приложение [11], которое обрабатывает файлы электронных таблиц в формате Excel (XLSX) или CSV. Каждый файл Excel может содержать одну или несколько электронных таблиц с произвольной структурой. TabbyXL использует CRL-правила для преобразования данных, извлекаемых из этих таблиц, в канони-ческую форму. Преобразованные данные сохраняются в отдельных файлах. Этапы 2–4 метода реализованы в форме программного модуля расширения (плагина) – PKBD.Onto для системы прототипирования продукционных экспертных систем PKBD [7]. PKBD реализован в форме настольного приложения, ориентированного на непрограммирующих пользователей. Основная цель PKBD – создание прототипов баз знаний, использующих формализм логических правил. PKBD обладает модульной архитектурой, которая дает возможность динамически подключать модули для поддержки различных языков представления знаний и возможность интеграции с инструментами концептуального и онтологического моделирования при импорте и экспорте понятий и отношений.
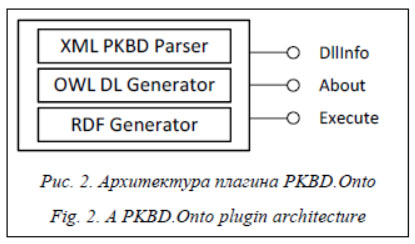
В архитектуре (рис. 2) плагина PKBD.Onto можно выделить модули: - поддержки формата концептуальных моделей PKBD, обеспечивающего доступ и манипуляцию элементами входной модели; - преобразования входной модели в формат OWL2 DL; - преобразования входной модели в набор связанных данных в формате RDF (может рассматриваться как средство для получения наборов конкретных фактов). Пример применения
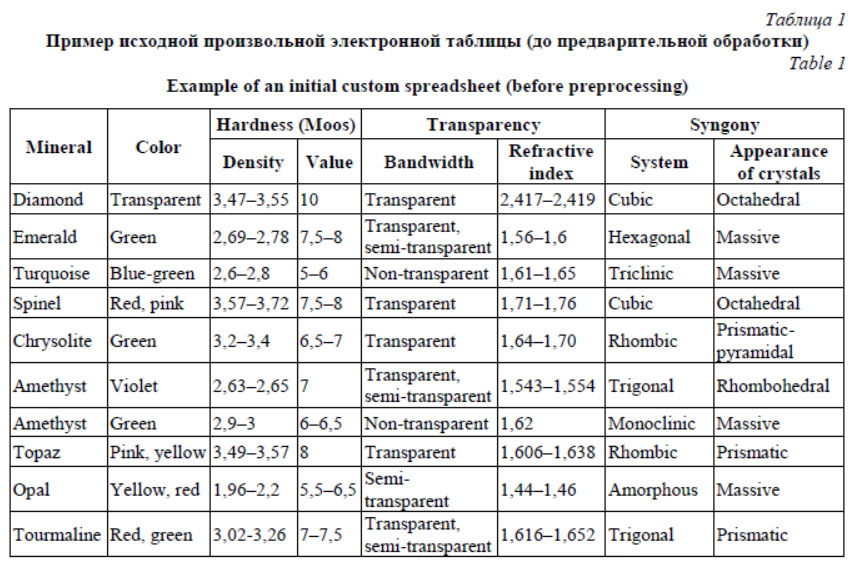
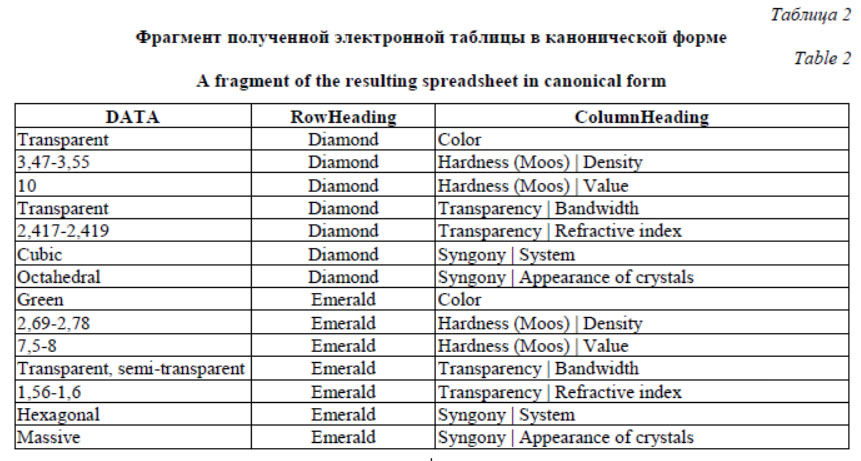
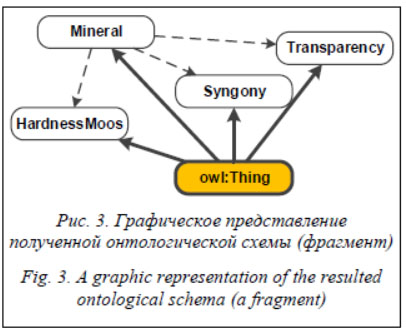
Далее был проведен анализ полученной канонической электронной таблицы средствами PKBD, в частности, плагином PKBD.Onto, в результате которого были извлечены фрагменты онтологической схемы. Полученные фрагменты потребовали объединения и уточнения: так, в результате применения правил агрегации все минералы объединены в класс (шаблон) Diamond, который было необходимо переименовать в Mineral.
Заключение В статье описаны метод и средство в форме плагина для инструментального средства PKBD для генерации онтологических схем (он-тологий на терминологическом уровне T-Box). При этом в качестве исходных данных исполь-зованы электронные таблицы в формате MS Excel (XLSX), обладающие произвольной компоновкой и приведенные к канонической форме. Плагин PKBD.Onto позволяет создавать быстрые прототипы онтологий на основе электронных таблиц. Полученные OWL-коды онтологических схем являются синтаксически корректными, при этом содержательную оценку результатов должен выполнять конечный пользователь (эксперт). Доработанные и уточненные онтологии в дальнейшем можно использовать для построения интеллектуальных систем и баз знаний. Работа выполнена при финансовой поддержке Совета по грантам Президента России, проект MK-1647.2020.9. Литература 1. Guarino N. Formal Ontology in Information Systems. IOS Press, 1998, 348 p. 2. Гаврилова Т.А., Кудрявцев Д.В., Муромцев Д.И. Инженерия знаний. Модели и методы. СПб: Лань, 2016. 324 с. 3. Lehmberg O., Ritze D., Meusel R., Bizer C. A large public corpus of web tables con-taining time and context metadata. Proc. XXV Intern. Conf. WWW Companion, 2016, pp. 75–76. DOI: 10.1145/2872518.2889386. 4. Dorodnykh N.O., Yurin A.Yu., Shigarov A.O. Conceptual model engineering for industrial safety inspection based on spreadsheet data analysis. Communications in computer and information science. In: Modelling and Development of Intelligent Systems, 2020, pp. 51–65. 5. Yurin A.Yu., Dorodnykh N.O. A reverse engineering process for inferring conceptual models from canonicalized tables. Proc. SIBIRCON, 2020, pp. 485–490. DOI: 10.1109/SIBIRCON48586.2019.8958458. 6. Grau B.C., Horrocks I., Motik B., Parsia B., Patel-Schneider P., Sattler U. OWL 2: The next step for OWL. SSRN Electronic Journal, 2018. URL: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3199412. (дата обращения: 21.07.2020). DOI: 10.2139/ssrn.3199412. 7. Yurin A.Yu., Dorodnykh N.O. Personal knowledge base designer: Software for expert systems prototyping. SoftwareX, 2020, vol. 11, art. 100411. DOI: 10.1016/j.softx.2020.100411. 8. Cretu L.G., Florin D. Model-Driven Engineering of Information Systems: Principles, Techniques, and Practice. Apple Academic Press, 2014, 350 p. 9. Shigarov A.O., Mikhailov A.A. Rule-based spreadsheet data transformation from arbitrary to relational tables. Information Systems, 2017, vol. 71, pp. 123–136. DOI: 10.1016/j.is.2017.08.004. 10. Tijerino Y.A., Embley D.W., Lonsdale D.W., Ding Y., Nagy G. Towards ontology generation from tables. World Wide Web, 2005, vol. 8, no. 3, pp. 261–285. DOI: 10.1007/s11280-005-0360-8. 11. Shigarov A.O., Khristyuk V.V., Mikhailov A.M. TabbyXL: Software platform for rule-based spreadsheet data extraction and transformation. SoftwareX, 2019, vol. 10, art. 100270. DOI: 10.1016/j.softx.2019.100270. 12. Levenshtein V.I. Binary codes capable of correcting deletions, insertions, and reversals. Dokl. Akad. Nauk SSSR, 1965, vol. 163, pp. 845–848. 13. Дородных Н.О., Юрин А.Ю. Язык для описания моделей трансформаций. Proc. ITAMS., 2018, vol. 2221, pp. 70–75. URL: http://ceur-ws.org/Vol-2221 (дата обращения: 05.08.2020). References
|
| Permanent link: http://swsys.ru/index.php?id=4788&lang=en&page=article |
Print version Full issue in PDF (7.81Mb) |
| The article was published in issue no. № 1, 2021 [ pp. 124-131 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Перспективы применения технологии семантического WEB в интеллектуальных хранилищах данных
- Метод автоматизированного синтеза виртуальных организационных структур для задач управления региональной безопасностью
- Программная реализация алгоритмов для создания прототипов баз знаний на основе визуального моделирования и трансформаций
- Разработка и применение распределенных пакетов прикладных программ
- Использование концепт-карт для автоматизированного создания продукционных баз знаний
Back to the list of articles