Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: Matveev, Yu.N. (matveev4700@mail.ru) - Tver State Technical University (Professor), Tver, Russia, Ph.D, () - , () - | |
| Ключевое слово: |
|
| Page views: 11942 |
Print version Full issue in PDF (1.26Mb) |
Повышение оперативности диагностики работающего технологического оборудования – одно из приоритетных направлений повышения надежности и безопасности функционирования установок и производств, работа которых потенциально связана с опасностью для здоровья и жизни персонала и для окружающей среды. Как правило, наименее надежными узлами оборудования являются его движущиеся части. Обычно движение носит вращательный или циклически повторяющийся характер. Большинство методик диагностики зарождающихся дефектов основывается на поиске аномальных периодических всплесков, серий импульсов в сигналах, снимаемых с датчиков на соответствующем оборудовании [1]. Был разработан алгоритм поиска этих аномальных признаков для стационарных процессов. Он обладает предельной простотой и малой ресурсоемкостью, однако он изначально полагает, что флуктуациями тренда полезного сигнала можно пренебречь на текущем интервале генеральной совокупности. Для динамических процессов, когда полезный сигнал может вести себя непредсказуемо на текущем интервале, требуется принципиально новый подход. С другой стороны, не стоит забывать, что анализ технологических процессов с целью диагностики и ранней идентификации нештатной ситуации имеет смысл вести только в режиме реального времени, а не апостериорно, и все применяемые алгоритмы имеют жесткое ограничение на ресурсоемкость. К тому же они должны иметь однозначно предсказуемое время выполнения. Для такой постановки задачи были исследованы числовые методы, активно применяющиеся в медицине и экономике. В этих областях задача поиска закономерностей в числовых рядах является одной из центральных: анализ электроэнцефалограмм, геномов в генетике; трендов курсов, уровней продаж в экономике и т.д. Методы анализа последовательностей – временных или иных рядов чисел и символов, испытывают определенные затруднения [4]. Несколько основных моделей, используемых при таком анализе, оказались плохо совместимыми друг с другом по базовым посылкам. Например, для числовых рядов Фурье-анализ требует отсутствия непериодических составляющих, методы Бокса чувствительны к виду одномерных распределений и т.д. Алгоритмы поиска закономерностей в последовательностях символов основываются на переборах, которые можно реализовать только в очень ограниченных вариантах, либо опираются на сильные эвристические допущения. Одним из наиболее перспективных и развивающихся является метод Гусеница, или SSA (Singular spectrum analysis) [2,3]. Метод локальной геометрии для поиска шаблонов в числовых и символьных рядах разработан для применения в медицине [4,5]. Он дал основу для разработки собственного метода, ориентированного для применения в анализе технологических процессов. Применительно к технологическим процессам предлагается следующая последовательность формулировки и решения задачи. 1. Исходный фрагмент генеральной совокупности проходит предварительную обработку. Сначала его сглаживают методом скользящего среднего. Затем каждая точка ряда заменяется на значение знака первой производной в этой точке: отрицательному знаку ставится в соответствие значение 0, положительному – 1. Таким образом, непосредственно значения амплитуд исключаются из рассмотрения, преобразованный в бинарный вид ряд отражает только локальное направление развития процесса. 2. Методом SSA ряд раскладывается в свою траекторную матрицу. 3. Имея в наличии бинарную матрицу, исходную задачу можно переформулировать следующим образом: предполагая, что строки представляют собой абстрактные объекты, а столбцы – бинарные признаки этих объектов, требуется обнаружить среди объектов (строк) наиболее схожие между собой по имеющимся признакам, иными словами, провести классификацию этих объектов (строк). Общие фрагменты объектов, очевидно, и будут искомыми шаблонами. Общие методы классификации абстрактных объектов с системой признаков хорошо проработаны, однако применительно к данной бинарной матрице и особенностям цели обработки разработан собственный алгоритм, обладающий малой ресурсоемкостью и высокой предсказуемостью времени выполнения. Отметим предлагаемый критерий близости объектов: мера близости, то есть расстояние между двумя бинарными объектами определяется как сумма значений разрядов результата их побитового сравнения операцией ИсключающееИЛИ-НЕ. Следует заметить очевидную ориентацию операции определения меры близости на низкоуровневые команды микропроцессоров и микроконтроллеров, выполняющиеся за один такт машинного времени. Саму операцию ИсключающееИЛИ-НЕ над двумя строками-объектами будем называть наложением строк. В начале работы алгоритма задаются величины, критически влияющие на эффективность обнаружения шаблонов и скорость его работы. 1. Длина гусеницы. 2. Минимальный размер шаблона, то есть количество значащих элементов в нем. 3. Максимальная длина пропуска в шаблоне, то есть длина последовательности незначащих элементов в шаблоне. 4. Минимальное число включений шаблона, то есть число включений шаблона в рассматриваемом интервале генеральной совокупности. 5. Максимальная доля шума в шаблоне. Используется при поиске включений шаблона, отношение количества несовпавших значащих элементов к размеру шаблона. 6. Максимальная апериодичность включений шаблона. Под длиной шаблона будем понимать его общую длину – сумму значащих и незначащих элементов. На первом этапе работы алгоритма каждая строка сравнивается с остальными в матрице – определяются меры их близости. В этом процессе для каждой строки формируются следующие данные: сумма мер близости данной строки к каждой из остальных строк; пара ближайших соседей данной строки и значения мер их близости к данной строке. При использовании классических алгоритмов классификации обязательным является построение всей матрицы расстояний (близостей), то есть для каждого объекта строится вектор значений близости ко всем остальным объектам. Предлагается запоминать только два ближайших соседа, потому что минимальное число включений шаблона, при котором его можно считать имеющим место, равно трем. При этом предполагается, что если число включений больше трех, то два ближайших соседа (в смысле меры близости) будут содержать наиболее чистые инстанции шаблона. При большой длине исследуемого интервала генеральной совокупности экономия памяти может быть существенной. По окончании первого этапа сумма мер близости для каждой строки покажет степень их близости к совокупности всех остальных строк. Заметим, при сравнении двух строк с включенным в них потенциальным шаблоном мера близости их обоих в среднем будет отличаться в большую сторону по сравнению с вариантом двух случайных строк. И чем большее число включений шаблона имеет рассматриваемый интервал генеральной совокупности, тем более выгодно будут отличаться строки, содержащие шаблон, от остальных. Это и покажет параметр суммы мер. Второй этап работы алгоритма – собственно детектирование шаблонов в траекторной матрице. Отсортировав строки в порядке уменьшения суммы мер, на первых местах получим строки, в которых вероятность включения шаблонов максимальная. Сортировка является опциональной, необязательной операцией. Вновь перебираем все строки траекторной матрицы. Возьмем текущую строку и двух ее ближайших соседей. Операция ИсключающееИЛИ-НЕ для трех этих строк даст маску. Наложив маску на текущую строку и отбросив незначащие нули справа и слева, получим предполагаемый включенный шаблон. Проверяются его размер и максимальная длина пропуска в шаблоне. Если хотя бы один из параметров не удовлетворяет заданным условиям, то делается вывод, что данная строка не содержит шаблонов. Иначе – проводим шаблон по бинарному эквиваленту текущего ряда. С учетом допустимой доли шума в шаблоне определяем число его включений в текущий ряд и позиции этих включений. Эта операция проводится при помощи уже имеющейся функции определения меры близости. Окно, равное длине шаблона, скользит от начала ряда к концу. Определяется мера близости содержимого окна и шаблона. Разница длины шаблона и меры близости даст меру различия. Отношение меры различия к размеру шаблона даст текущую долю шума. На этом же этапе находится средний период следования шаблона и апериодичность его включений: совокупность интервалов ИНТj между включениями j: Тср(Шi) = Апериодичность включений оценим как отношение среднеквадратичного отклонения к усредненному периоду: А = Если число включений меньше минимально заданного или апериодичность включений больше максимально заданной, делается вывод, что данная строка не содержит шаблонов. Иначе – проверяется наличие данного шаблона или его более полного варианта (то есть он включает в себя данный шаблон) в библиотеке шаблонов. Если найден аналог или более полный вариант с числом включений таким же или большим, то шаблон обнаружен в текущей строке, но уже имеется в библиотеке и неактуален. Если найден более полный вариант, но с меньшим числом включений, то текущий шаблон заменяет более полный в библиотеке, так как число включений имеет больший приоритет (вариант шаблона с большим размером может быть обусловлен его большей зашумленностью). Иначе – шаблон удовлетворяет заданным условиям, считается обнаруженным. В библиотеке производится поиск менее полного варианта шаблона. Если не найден, то текущий шаблон считается актуальным и заносится в библиотеку шаблонов. Если найден: · если число включений его меньше чем у текущего или равно ему, то текущий заменяет его в библиотеке; · иначе – текущий шаблон считается неактуальным и в дальнейшее рассмотрение не берется. Разработан алгоритм детектирования шаблонов в динамических временных рядах. К сожалению, следует отметить чувствительность данного алгоритма к выбору значения длины гусеницы. Если длина потенциального шаблона N, имеющегося в исходном ряде, больше заданной длины гусеницы L, алгоритм детектирует N-L шаблонов с длиной, равной длине гусеницы и одинаковыми прочими параметрами. Такая ситуация легко поддается обнаружению и разрешению, но при малых размерах гусеницы повышается и вероятность ложных срабатываний. Если же длина гусеницы более чем в 1,5 раза превышает длину потенциального шаблона, то при детектировании наличие включения шаблона оказывает слишком малое влияние на меру близости строк, приближаясь к естественному случайному фону. Поэтому использование данного алгоритма в общем случае предполагает варьирование длины гусеницы в некоторых заданных пределах, которые определяются исходя из имеющихся условий применения. Например, если предположить, что переходный процесс, инициированный биением в механизме, длится не более 1 с, частота дискретизации при съеме показателя равна 40 Гц, то длина соответствующего шаблона в генеральной совокупности данных показателя будет не более 40 точек. Максимальную длину гусеницы нужно взять с некоторым запасом, например, 50 точек. Разработан механизм обоснования начальной длины гусеницы, исходящий из особенностей исследуемого процесса, а также методика ее варьирования в зависимости от текущей ситуации. Минимальная длина гусеницы определяется исходя из минимальной длительности дефектного переходного процесса или исходя из вероятности случайного возникновения шаблона с заданным минимальным количеством включений, минимальной длины, в заданном интервале генеральной совокупности. Применительно к технологическим процессам, шаблоны с одинаковым периодом следования несут одну и ту же информацию, поэтому в операцию нахождения включения шаблона в другом шаблоне, используемую при поддержании информативности библиотеки шаблонов, можно ввести условие равенства периодов. Разработана программа «Детектор аномальных признаков в динамических процессах «ДАП», реализующая данный алгоритм. Программное средство имеет свидетельство о государственной регистрации. Список литературы 1. Матвеев Ю.Н., Гаганов П.Г., Азарова Л.В. Детектирование аномальных информативных признаков в стационарных технологических процессах //Программные продукты и системы. - 2004. - №1. – С. 38-41. 2. Голяндина Н.Е. Метод «Гусеница»-SSA: анализ временных рядов: Учеб. пособие.-СПб: Изд-во СПбГУ, 2004.-76 с. 3. Главные компоненты временных рядов: метод «Гусеница»/ Под ред. Д.Л.Данилова и А.А.Жиглявского. – СПб.: Изд-во СПбГУ, 1997. 4. Дюк В.А. Поиск сложных непериодических шаблонов в последовательностях чисел и символов. – Санкт-Петербургский Институт информатики и автоматизации РАН (http://datadiver.nw.ru/prod_art.htm). 5. Дюк В.А. Формирование знаний в системах искусственного интеллекта: геометрический подход //Интернет-журнал Демиург. - 1996. - №2 (http://demiurg-vatt.chat.ru/J2-2.HTM). |
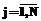 i-го шаблона рассматриваем как числовой ряд и находим его характеристики. Математическое ожидание покажет усредненный период повторения шаблона:
i-го шаблона рассматриваем как числовой ряд и находим его характеристики. Математическое ожидание покажет усредненный период повторения шаблона: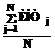 . (1)
. (1) . (2)
. (2)| Permanent link: http://swsys.ru/index.php?id=481&lang=en&page=article |
Print version Full issue in PDF (1.26Mb) |
| The article was published in issue no. № 1, 2006 |
Perhaps, you might be interested in the following articles of similar topics:
- Информационно-вычислительный комплекс по применению мембран в биотехнологии
- Нейроподобная сеть для решения задачи оптимизации антенной решетки
- ДИНАМИКА-2 - программа для решения осесимметричных и плоских задач
- Формирование программ развития больших систем административно-организационного управления
- Эвристические и точные методы программной конвейеризации циклов
Back to the list of articles