Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: (byg@yandex.ru) - , Ph.D, (midli@mail.ru) - , Ph.D | |
| Ключевое слово: |
|
| Page views: 41279 |
Print version Full issue in PDF (1.97Mb) |
С проблемой обработки пропусков в массивах данных приходится сталкиваться при проведении разнообразных социологических, экономических и статистических исследований [1]. Традиционными причинами, приводящими к появлению пропусков, являются невозможность получения или обработки, искажение или сокрытие информации. В результате на вход программ анализа собранных данных поступают неполные сведения. Самым простым решением обработки данных является исключение некомплектных наблюдений, содержащих пропуски, и дальнейший анализ полученных таким образом "полных" данных. Понятно, что такой подход приводит к сильному различию статистических выводов, сделанных при наличии в данных пропусков и при их отсутствии. Поэтому более перспективным является иной путь – заполнение пропусков перед анализом фактических данных. Можно выделить следующие преимущества данного подхода: ясное представление структуры данных; вычисление необходимых итоговых значений; уверенная интерпретация результатов анализа, так как можно опираться на традиционные характеристики и суммарные значения. Сегодня создано множество методов восстановления пропусков, однако единая методология обработки подобных данных отсутствует, несмотря на ее необходимость. Основной задачей данной работы является сравнительный анализ существующих методов восстановления пропущенных значений в массивах (рядах, таблицах) данных, в том числе с практической проверкой восстанавливающей способности наиболее известных алгоритмов. Для решения поставленной задачи использовалось изучение литературных источников и компьютерное моделирование ряда алгоритмов (замена пропуска общим средним, замена пропуска средним из ближайших, метод сплайн-интерполяции, Zet-алгоритм) с анализом их эффективности для реальных массивов данных. Поясним постановку задачи предсказания (восстановления) значений пропущенных элементов на примере обработки таблицы размером m´n, не содержащей пропусков [2]. Пусть в нашем распоряжении имеется набор различных методов (алгоритмов) F = < f1, f2, …, fn, …, ft >, предназначенных для предсказания значений пропущенных элементов. Закроем в таблице известный элемент x11, стоящий на пересечении строки a1 и столбца b1, и предскажем его с помощью всех методов F поочередно. Каждый метод fn предскажет свое значение x11n, при этом относительная ошибка предсказания будет определена как Восстановим в таблице элемент x11, уберем элемент x12 и повторим процедуру, получив при этом относительную ошибку d12n. Проделав это по очереди со всеми элементами таблицы и просуммировав обнаруженные ошибки, получаем величину относительных ошибок Dn для каждого метода. Наилучшим из них естественно считать такой метод fn*, который дает минимальную сумму ошибок Методы из набора F могут отличаться друг от друга лежащими в их основании эвристическими предположениями (гипотезами). Возможность использования методов разной степени сложности связана с тем, насколько простым или сложным является механизм, согласно которому данные оказываются пропущенными. Используя терминологию, предложенную в [1], будем называть пропуски в данных полностью случайными (data are missing completely at random – MCAR), если условная вероятность P (Xj пропущено/прочие X) не зависит ни от Xj, ни от прочих X (то есть эта вероятность постоянна для всех наблюдений, и наблюдаемые Xj являются случайной подвыборкой тех Xj, которые должны были получиться в эксперименте). Пропуски в данных называются случайными (missing at random – MAR), если вероятность P(Xj пропущено/прочие X) не зависит от Xj, но может зависеть от других X. Оказывается, что в этих случаях механизм пропусков несущественен (ignorable), и к данным применимы вариации методов восстановления пропусков. Наконец, если P(Xj пропущено/про- чие X) зависит от самого Xj, то механизм пропусков является существенным (non-ignorable), и для корректного анализа данных необходимо знать этот механизм. Введенные понятия относятся к отдельным переменным, и в пределах одной и той же базы данных можно, в принципе, наблюдать все приведенные варианты. Можно построить тесты, отличающие MAR от MCAR, однако по данным невозможно отличить, являются ли они MAR, или же механизм пропусков существенен. Характеристика известных методов восстановления пропусков по литературным данным. Первый возможный подход к обработке данных с пропусками – это просто исключение некомплектных объектов. Данный метод легко реализуется, но необходимым условием его применения является следование данных требованию MCAR. Кроме того, необходимо, чтобы количество пропусков было небольшим, иначе происходят сильные смещения, кроме того, как показывает практика, данный метод не очень эффективен. Следующим подходом, реализованным в большом числе алгоритмов, является подход с заполнением пропусков. Наряду с очевидными преимуществами данного подхода ему присущи недостатки: "...Опасность этого подхода в том, что он не позволяет отличать ситуации, где задача не очень трудна и может быть корректно решена таким способом, от ситуаций, где обычные оценки по реальным и подставленным данным сильно смещены" [1]. Выделяют следующие два принципиальных недостатка данного подхода. 1. Как правило, параметры для алгоритма заполнения пропусков вычисляются по присутствующим данным, что вносит зависимость между наблюдениями. Конечно, такой искусственной зависимости не возникает, если проводится заполнение константой или случайными значениями, не зависящими от присутствующих наблюдений в выборке, или методом подстановки без подбора. Но на практике эти методы представляют малую ценность. Зависимости можно также избежать, разделяя исходную выборку на две подвыборки и вычисляя подстановки (например средневыборочные значения) для анализируемой подвыборки по значениям наблюдений во второй подвыборке. При таком подходе приходится жертвовать частью информации, чтобы заполнить пропущенные значения. 2. Распределение данных после заполнения будет отличаться от истинного, даже если пренебречь зависимостью, указанной выше. Этот факт особенно нагляден для простых методов заполнения (средневыборочных, по регрессии и т.п.). Различные варианты данных методов заполнения приведут к смеси истинного и вырожденных распределений с вырождением на гиперплоскостях, на которых располагаются предсказываемые значения. Отметим, что анализ подобных полных данных стандартными методами неправомерен и приводит к таким недостаткам, как несостоятельность и смещенность оценок параметров. Однако методы данной группы широко применяются. Приведем особенности наиболее известных методов глобального заполнения (то есть заполнения с использованием данных всей выборки) [1-4]. Заполнение средними (средним по всей выборке или средними по группам) – применение имеет смысл только в случае следования данных условию MAR, данная группа методов легко реализуема; недостатки – искажение распределения данных, уменьшение дисперсии. Методы заполнения с подбором – подобны методам заполнения средними, легко реализуемы, кроме того, при применении данных методов больше разброс дисперсии предсказанных значений пропусков, не искажается распределение. Недостаток – выявление распределения обрабатываемой генеральной совокупности данных по полученной выборке комплектных данных. Заполнение по регрессии. В основу данной группы методов положены хорошо известные алгоритмы регрессионного анализа [5]. Из условий применения данного метода можно выделить требование о следовании данных условию MAR (хотя для частных случаев возможно применение более слабых требований) и требования, относящиеся к выполнению предпосылок регрессионного анализа. Недостатки подобных методов очевидны: качество предсказания (восстановления пропусков) напрямую зависит от успешного выбора взятой за основу регрессионной модели. Метод сплайн-интерполяции – обоснованный математически метод интерполяции, показывающий хорошие результаты. Для успешного применения необходимо, чтобы данные следовали условию MAR. Недостатки метода следуют из самой его идеи. Например, в случае восстановления группы пропусков, следующих подряд друг за другом, результат аппроксимации сплайном данной группы не всегда может дать оценки, приближающиеся с достаточной точностью к значениям, которые могли бы быть на месте пропусков. Методы многократного заполнения. Основное их преимущество в том, что они преодолевают недостаток методов однократного заполнения в смысле большего разброса дисперсии оценки; посылки применимости данного метода полностью определяются используемыми методами формирования множества вариантов восстановления пропуска. МП-оценивание (EM-алгоритм) – относится к категории методов моделирования [1]. Особенность данных методов – построение модели порождения пропусков с последующим получением выводов на основании функции правдоподобия, построенной при условии справедливости данной модели, с оцениванием параметров методами типа максимального правдоподобия. Отметим, что если другие методы восстановления пропусков требуют, чтобы данные отвечали условию MAR (или MCAR как более жесткому), то для данных методов возможно построение моделей, учитывающих конкретную специфику области, как следствие, возможна постановка более слабых условий к данным. Недостаток – необходимость построения модели порождения пропусков. Использование методов факторного анализа [4]. Особенности метода: отсутствие требования априорного заполнения пропусков, необходимость в предварительной нормировке данных, наличие требований факторного анализа. В случае использования нелинейных моделей данных метод имеет очевидное преимущество по сравнению с регрессионными методами. В связи с большим количеством шагов алгоритма данному методу присуща некоторая трудоемкость реализации. Использование методов кластерного анализа [6]. Особенность метода – его применение не опирается на какую-либо вероятностную модель, но при этом оценить его свойства в статистических терминах не представляется возможным. Однако данный метод обладает существенным достоинством, а именно, он позволяет указать предпочтительный порядок восстановления данных и выявить случаи, когда пропуски не могут быть восстановлены по имеющимся данным. Локальные алгоритмы восстановления пропусков [2,3]. Алгоритмы семейства Zet (Wanga), по сути, являются детально проработанной и апробированной технологией верификации экспериментальных данных, основанной на гипотезе их избыточности. Внешне они сходны с методом локального заполнения. Данные алгоритмы хорошо показали себя, но необходимость задания ряда важных параметров приводит к необходимости убедиться в правдоподобности восстановленных значений. Существуют другие альтернативные подходы к восстановлению данных. В качестве примера отметим использование нейросетей [7]. Несмотря на некоторую эквивалентность моделей статистики и нейросетевых парадигм, трудно выявить явные преимущества и недостатки применения нейросетевых технологий для восстановления данных. Практическое исследование восстанавливающей способности выбранных методов заполнения пропущенных значений было программно реализовано в системе Mathcad и частично в Microsoft Excel с тестированием на большом множестве реальных временных рядов с различной структурой пропусков (создаваемых в процессе исследования искусственно). Итоговые результаты по исследовавшимся методам таковы. 1. Метод замены пропущенного значения общим средним из присутствующих элементов. Данный метод был выбран для исследования в связи с тем, что это наиболее известный, простой способ восстановления пропусков, включенный как средство борьбы с ними в большинство статистических пакетов. Эксперименты показали полную несостоятельность данного метода даже на простых рядах данных. 2. Метод замены пропущенного значения средним из ближайших присутствующих элементов переменной. Данный метод является эффективным развитием метода замены пропусков общим средним, и эксперименты показали хорошую точность метода в случае одиночных пропусков на достаточно гладких рядах данных. Благодаря простоте реализации можно даже рекомендовать использование данного метода в приведенных выше условиях, но только в них. Наличие в данных групповых пропусков или сильные флуктуации значений ряда сводят эффективность метода к нулю. Таким образом, этот метод можно использовать только для восстановления одиночных пропусков в рядах данных. 3. Метод восстановления пропущенного значения сплайн-интерполяцией по присутствующим элементам. Все эксперименты показали, что в случае наличия в данных одиночных пропусков настоящий метод показывает лучшие результаты восстановления среди всех методов независимо от сложности поведения ряда, за исключением, конечно, вырожденных случаев, в которых количество пропусков намного превышает количество существующих наблюдений. Однако в случае групповых пропусков результаты применения данного метода оказались неожиданно сильно зависящими от структуры пропусков, особенно в случае большой протяженности группы. Причины подобной особенности этого алгоритма понятны: по сути, метод просто строит наилучшую аппроксимирующую поверхность для существующих наблюдений и не более того. Такие же особенности ряда, как периодичность, наличие линии тренда и т.п., никак не принимаются в расчет при восстановлении группового пропуска. Поэтому при применении данного метода возрастает степень участия исследователя в процессе восстановления пропусков, который должен не просто выполнить программу алгоритма, но и проконтролировать полученные результаты и, если необходимо, даже отменить их. 4. Метод восстановления пропущенного значения на основе использования Zet-алгоритма [2,3]. Данный алгоритм интересен для исследования тем, что при восстановлении учитывает закономерности ряда, может работать как с одномерными рядами данных, так и с таблицами данных, состоящих из множества взаимосвязанных рядов, указывает случаи, в которых имеющихся данных недостаточно для восстановления пропусков. И действительно, эксперименты показали целесообразность применения Zet-алгоритма. Так, в случае одиночных пропусков данный метод имеет несомненное преимущество перед простыми методами восстановления пропусков (общего среднего, среднего из ближайших) и несколько уступает методу сплайн-интерполяции. Однако в случае наличия в данных групповых пропусков качество восстановления пропущенных значений при помощи Zet-алгоритма лучше остальных рассматриваемых методов, причем результаты применения метода стабильны, учитывают закономерности исследуемого ряда, достаточно слабо зависят от структуры пропусков и иногда являются единственно достоверными по сравнению с результатами применения других методов. Особо следует отметить возможности этого метода при восстановлении групповых пропусков в таблицах данных. Ни один из остальных исследуемых методов не способен выполнить такую задачу с приемлемой точностью, в то время как Zet-алгоритм показывает хорошие результаты. Конечно, у данного метода есть ограничения. Например, между данными должна прослеживаться причинно-следственная (вероятностная) связь, а количество существующих наблюдений, по которым восстанавливаются пропуски, не должно быть малым. Если данные сильно зашумлены и искажены, обладают большой долей пропусков, то результат восстановления, естественно, будет некорректен: здесь как нельзя более ясно работает правило "мусор на входе – мусор на выходе". Однако даже в такой ситуации описываемый алгоритм будет искать закономерности в присутствующих данных и осуществлять восстановление пропусков, в отличие от других методов, для которых в подобной ситуации пропуск заполняется совершенно фантастическими значениями. Приведенные результаты отражают поставленную задачу исследований и, более того, позволяют предложить следующую, как представляется, новую и достаточно эффективную методику восстановления пропусков в массивах данных: сначала к одиночным пропускам применяется метод сплайн-интерполяции (хотя иногда достаточно применить метод заполнения средним из ближайших), затем к результирующему набору данных с восстановленными одиночными пропусками и незатронутыми групповыми пропусками применяется Zet-алгоритм. Список литературы 1. Литтл Р.Дж.А., Рубин Д.Б. Статистический анализ данных с пропусками. - М.: Финансы и статистика, 1990. 2. Загоруйко Н.Г. Прикладные методы анализа данных и знаний. - Новосибирск: Изд-во ин-та математики, 1999. 3. Загоруйко Н.Г., Елкина В.Н., Тимеркаев В.С. Алгоритм заполнения пропусков в эмпирических таблицах (алгоритм Zet) // Эмпирическое предсказание и распознавание образов. - Новосибирск, 1975. - Вып. 61: Вычислительные системы. - С. 3-27. 4. Россиев А.А. Моделирование данных при помощи кривых для восстановления пробелов в таблицах. Методы нейроинформатики / Под. ред. А.Н. Горбаня. – Красноярск: КГТУ, 1998. 5. Демиденко Е.З. Линейная и нелинейная регрессия. - М.: Финансы и статистика, 1981. 6. Двоенко С.Д. Неиерархический дивизимный алгоритм кластеризации // Автоматика и телемеханика. - 1999. - № 4. - С. 117-124. 7. Круглов В.В., Борисов В.В. Искусственные нейронные сети. Теория и практика. - М.: Горячая линия – Телеком, 2002. |
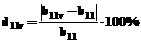 .
. .
.| Permanent link: http://swsys.ru/index.php?id=528&lang=en&page=article |
Print version Full issue in PDF (1.97Mb) |
| The article was published in issue no. № 2, 2005 |
Perhaps, you might be interested in the following articles of similar topics:
- Системы баз данных и знаний, разработанные в Республике Куба
- Метод интегрированного описания топологических отношений в геоинформационных системах
- Реализация временных рассуждений для интеллектуальных систем поддержки принятия решений реального времени
- Параллельная обработка в алгоритмах визуализации с трассировкой лучей
- Правила построения автоматизированных информационных систем экспертной оценки и согласования
Back to the list of articles