Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Author: () - | |
| Ключевое слово: |
|
| Page views: 9724 |
Print version Full issue in PDF (1.13Mb) |
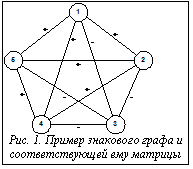
В последние десять-пятнадцать лет наблюдается лавинообразный рост объема информации, необходимой для эффективной деятельности в различных областях науки и бизнеса. Широкий тематический спектр решаемых задач, большие объемы доступной информации, необходимость интеграции – все это выдвигает на первый план проблему создания интеллектуальных средств поддержки их деятельности, обеспечивающих формализацию, накопление и непротиворечивость их знаний. При всем богатстве и разнообразии существующих инструментальных средств работы с информацией они, к сожалению, часто оказываются неэффективными в ситуациях, когда необходима реструктуризация базы знаний аналитика в соответствии с динамично изменяющимися условиями и характером решаемых задач. Одним из распространенных способов представления знаний самого общего характера являются неструктурированные текстовые документы. При этом для эффективного использования содержащейся в них информации требуется не только построение индексированной базы данных, но и выявление структуры полученного массива знаний, взаимосвязей между его элементами, выделение подмножеств документов с близким содержанием. Все это в дальнейшем позволяет существенно упростить и ускорить процедуры информационного поиска в базе знаний. Данная область исследований развивается достаточно активно, разработано множество подходов и методик, с той или иной степенью качества при различных условиях решающих подобную задачу. Среди них следует отметить всевозможные детерминированные алгоритмы на базе сопоставления ключевых слов, появившиеся еще в конце 60-х годов, векторные методы и их расширения, такие как латентное семантическое индексирование, анализ структурной согласованности, экспертные оценки и другие. Общим недостатком каждой из перечисленных методик является их ориентация на решение довольно узкого класса задач и отсутствие обратной связи, позволяющей контролировать качество результатов. В работе предлагается комплексная схема, которая объединяет один из наиболее эффективных алгоритмов определения сходства документов с механизмом приведения множества документов в консонансное состояние на базе критерия структурной согласованности и с последующей экспертной оценкой качества полученных результатов. Анализ различных подходов к решению задачи определения сходства документов. Детерминированные методы. В основу большинства алгоритмов данного типа положена идея построения так называемого профиля документа, который представляет собой список его ключевых слов, определяемый по частоте их встречаемости. Полученные в результате частотного анализа профили документов сопоставляются друг с другом, на основе чего делается заключение о близости их содержания [1]. Главным достоинством детерминированных методов является простота реализации в автоматизированных системах. По этой причине в свое время они получили довольно широкое распространение, однако, как показали исследования [2], зачастую качество получаемых результатов было неприемлемым. Вследствие этого детерминированные методы для нас представляют в основном исторический интерес. Векторные методы. Другая группа алгоритмов, которые во многом являются развитием детерминированного подхода, – векторные методы. В них документальная база данных представляется как матрица "слова-документы", ячейки которой представляют собой частоту встречаемости каждого слова в каждом документе. Таким образом, документы в данной модели рассматриваются как векторы в многомерном пространстве, “размерности” которого – это слова, составляющие их тексты. Степень сходства двух документов вычисляется как скалярное произведение (иногда взвешенное) соответствующих столбцов в матрице "слова-документы" (табл. 1). Таблица 1 Матрица “слова-документы” – основа векторных методов
Важнейшее предположение такой пространственной модели – независимость (ортогональность) слов, составляющих документы, в пределе всех слов языка. Это условие допустимо только в нулевом приближении, а в общем случае, разумеется, оно не отражает реальные семантические и морфологические взаимосвязи между словарными единицами. В каждой предметной области используется определенный набор терминов, которые, очевидно, нельзя считать независимыми друг от друга, и соответствующие им векторы частот коррелируют между собой. Кроме того, существует проблема словоформ, которая особенно остро стоит в русском языке, где их количество в среднем составляет от 20 до 40 на слово. Латентное семантическое индексирование. Как и следовало ожидать, при попытках применить векторные модели сравнения документов в чистом виде исследователи столкнулись с относительно низким качеством результатов, не гово LSI представляет собой расширение стандартного векторного метода, описанного выше. Основная идея алгоритма – статистическая оценка и учет скрытых (латентных) ассоциаций между словами в документах. В данной работе будет использована реализация LSI, описанная в [3], где для выделения таких взаимосвязей применялось разложение по сингулярным числам матрицы (Singular Value Decomposition, или SVD). Эта техника, близкая к разложению по собственным векторам и методам факторного анализа, выделяет множество из k факторов (как правило, от 100 до 500), линейная комбинация которых аппроксимирует исходную матрицу “слова-документы”. Вместо представления документов как дискретных векторов в пространстве независимых слов, LSI рассматривает и ключевые слова, и документы как непрерывные векторы в базисе из k ортогональных индексирующих размерностей, полученных в ходе SVD-анализа. Различные исследователи определяют показатель сходства между этими векторами либо через их скалярное произведение, либо через косинус угла между ними. В данной работе используется первый подход, так как он учитывает вклад слов, встречающихся в документах более одного раза. Настоящий метод, несмотря на повышенную сложность, обладает рядом неоспоримых достоинств. Так как количество полученных размерностей гораздо меньше первоначального числа терминов, последние перестают быть независимыми. Например, как показано в [3], если два на первый взгляд никак не связанных между собой слова используются в нескольких сходных по содержанию документах, они будут иметь близкие векторы (в смысле величины их скалярного произведения) в k-мерном пространстве факторов. Метод их улавливает скрытую, латентную структуру, более глубокую, чем просто статистика встречаемости слов. Кроме того, ввиду небольшого числа индексирующих размерностей существенно сокращается вычислительная сложность алгоритма, что позволяет использовать его на практике. Анализ структурной согласованности документарной базы знаний. Изложенный метод дает возможность определения попарного сходства документов, однако при этом вовсе не обязательно соблюдается согласованность системы в целом (например, не гарантируется, что два документа, имеющие высокий показатель сходства с каким-либо третьим, близки по содержанию друг к другу). Для более глубокого анализа полученной структуры сходства используется теория структурной согласованности множеств [5-8], в которой важную роль играет не семантический аспект содержания документов, а рассматривается совокупная непротиворечивость показателей сходства с точки зрения специального критерия согласованности. В данной модели документы и их попарные соотношения сходства представляются в виде полного знакового неориентированного графа и симметричной матрицы связности (рис. 1). Знак каждой связи определяется пороговой величиной – он положителен, если показатель сходства между соответствующими документами больше порогового, и отрицателен в обратной ситуации. Порог является одним из параметров задачи и контролирует допустимый первоначальный уровень рассогласования системы показателей сходства. Действительно, при нулевом пороге вся система будет в тривиальном согласованном состоянии (все связи положительны), а если превышается любой из имеющихся показателей сходства, то будет иметь место тривиальное рассогласованное состояние (все связи отрицательны). Очевидно, что, подбирая порог, можно добиться любого соотношения числа положительных и отрицательных связей. С точки зрения структурной согласованности выделяются консонансное (согласованное), диссонансное (рассогласованное) и ассонансное (не имеющее определенной структуры) состояния множества документов по тернарному критерию Хайдера, а также расширенное понятие поликонсонанса степени N, соответствующего более слабому критерию консонансности. Полученный граф, описывающий структурную согласованность документов, может находиться в любом из перечисленных состояний. Как было отмечено, его состояние зависит от выбранного порогового значения показателей сходства. В [7] рассматривается задача приведения ассонансного множества в согласованное состояние (поликонсонанс заданной степени) за минимальное число шагов. В качестве элементарной операции выбрано одновременное изменение знаков всех связей у одной отдельно взятой вершины – так называемый повершинный переброс. В общем случае не всегда удается привести ассонансное множество в консонанс, однако можно указать так называемые сильные диссонансные связи, изменение знаков которых на противоположные в результате переводит множество в согласованное состояние. Степень рассогласованности совокупности документов в данной модели может рассматриваться как расстояние до ближайшего консонансного множества. Оно выражается в виде суммы количества повершинных перебросов, необходимых для перевода исходного множества в ближайшее к нему ассонансное множество с сильными диссонансными связями, и количества этих связей. Несмотря на общий переборный характер решения данной задачи, существует ряд практических алгоритмов для нахождения ближайшего консонансного прообраза исходного множества. Один из наиболее эффективных из них описан и применен к задаче диссеминации текстовых документов в [9]. Там же приведено описание его программной реализации в виде автоматизированной интерактивной системы Intelledger. Привлечение экспертов для оценки качества результата. Очевидно, что результаты работы предлагаемого метода зависят от ряда факторов (выбранного количества индексирующих размерностей, порогового значения, определяющего знаковую структуру множества документов и пр.). В самом методе LSI отсутствует оценка правильности полученных показателей сходства, то есть нет обратной связи, которая позволила бы проанализировать качество результатов. Та же проблема характерна и для предлагаемой методики выбора порога и приведения множества документов в согласованное состояние. Выходом из такой ситуации может быть привлечение для оценки качества работы предложенного алгоритма независимого эксперта. Сопоставляя содержимое документов, он дает свою оценку правильности знаков матрицы связности, используя семибалльную шкалу. В этом случае мнением эксперта будет симметричная матрица “документы-документы”, содержащая полученные от него рейтинги качества. Следует отметить, что данный подход может оказаться достаточно трудоемким, так как эксперту необходимо давать оценку степени своего согласия со знаками связи для каждой пары документов. Тем не менее, на определенном этапе настройки алгоритм LSI с последующей процедурой приведения множества документов в консонанс будут давать удовлетворительные результаты, и необходимости в дальнейшем привлечении экспертов не будет. Исходя из этого, изложенная методика должна применяться для первоначальной настройки параметров алгоритма на ограниченном тестовом подмножестве документов, что сделает ее вполне приемлемой с точки зрения трудоемкости. Как правило, для снижения риска получения ошибочных результатов привлекается несколько экспертов, и одна из основных задач в этом случае – выведение совокупной оценки на базе их мнений. В силу субъективной природы экспертных оценок в них всегда присутствует некоторая степень неопределенности, зависящая от квалификации эксперта, которую необходимо учитывать. Для этого к экспертизе привлекается еще одна сторона, которая в [10] названа ЛПР (лицо, принимающее решение), основная роль которого заключается в определении степени доверия к мнению каждого эксперта. Так как ЛПР никогда не имеет абсолютно точного представления об их квалификации, он не может полностью полагаться на мнение того или иного эксперта и рассматривает даваемые им оценки как случайные величины, дисперсии которых отражают величину их возможного отклонения от истинного значения. Следует подчеркнуть, что это отклонение субъективно оценивается ЛПР и характеризует степень его доверия к мнению того или иного эксперта. Таким образом, ЛПР моделирует поведение экспертов через свое отношение к достоверности получаемых от них оценок, затем комбинирует их, используя байесовский подход и, наконец, выводит совокупную оценку из условия максимума апостериорного распределения искомой величины. Данный подход применен к рассматриваемой задаче определения качества работы алгоритма LSI и последующего приведения множества документов в согласованное состояние. Рейтинги качества, предоставляемые экспертами для каждой пары документов из тестового подмножества, рассматриваются как случайные величины. Степень доверия ЛПР к мнению экспертов описывается функцией правдоподобия, которая для простоты определяется нормальным распределением с математическим ожиданием, равным неизвестному истинному значению показателя сходства, и дисперсией, определяемой весом эксперта. Искомая совокупная оценка рейтинга качества рассчитывается из условия максимума плотности вероятности ее распределения, полученного по теореме Байеса. Пример использования методики. Для тестирования предложенной методики было отобрано 7 статей с ленты новостей информационного агентства Росбизнесконсалтинг (www.rbc.ru). В основном были представлены политические и экономические новости, причем некоторые из статей являлись продолжением других, то есть имели схожий набор ключевых слов. Документы подбирались таким образом, чтобы среди них были как далекие, так и весьма близкие по содержанию. Выбранные документы были поданы на вход алгоритма LSI, реализованного в рамках системы Intelledger, в которой задано 10 индексирующих размерностей. В результате работы алгоритма была получена матрица показателей сходства документов, которая была преобразована в матрицу связности с использованием порогового значения, равного 2 (таблица 2): Таблица 2
В соответствии с алгоритмом уменьшения рассогласованности, изложенным в [9], данная матрица с помощью процедуры последовательных повершинных перебросов документов D1, D4, и D3 была приведена к виду таблицы 3. Таблица 3
Как видно из таблицы 3, полученная матрица связности имеет ассонансную структуру, близкую к консонансу типа (4:3). При этом имеется две сильные диссонансные связи – между документами D1 и D6 и между D3 и D6. Таким образом, расстояние от исходной матрицы связности, полученной в результате вычислительного эксперимента, до консонансного множества равно 5 (три повершинных переброса плюс две сильные диссонансные связи), что соответствует сравнительно высокой степени структурной согласованности множества документов. Для оценки качества результатов было смоделировано участие пяти независимых экспертов. На основе сопоставления содержания документов с оценками их сходства, представленными в таблице 3, они делали свои заключения относительно правильности результата работы алгоритма в виде рейтингов, отражающих степень их согласия со знаками связей. При этом использовалась семибалльная шкала (оценки от 0 до 6). В таблице 4 приведены оценки качества определения сходства документов, сделанные первым экспертом. Таблица 4
Мнения остальных экспертов также были представлены в виде матриц, аналогичных по структуре, представленной в таблице 4. Далее мнения экспертов относительно результатов работы алгоритма LSI были использованы для вычисления совокупных рейтингов качества. Помимо самих экспертных оценок, параметрами данной подзадачи являются веса мнений экспертов, характеризующие степень доверия к ним со стороны ЛПР. В примере были выбраны веса, нормированные в диапазоне [0;1] (таблица 5). Таблица 5
На базе байесовского подхода, изложенного в [7], в рамках которого была выбрана аддитивная модель ошибок экспертов и равномерное априорное распределение оценок экспертов, были рассчитаны следующие совокупные рейтинги качества результатов (таблица 6). Таблица 6
Как видно из таблицы 6, качество работы алгоритма LSI выше всего для третьего, пятого и шестого документов – большинство совокупных рейтингов относительно высоки. В то же время результаты экспертизы для второго и седьмого документов показывают относительно низкое качество определения его показателей сходства с другими документами. На базе этих выводов могут быть приняты различные решения по изменению параметров задачи – количества индексирующих размерностей в алгоритме LSI или порога сходства, определяющего знаковую структуру матрицы связности. В данной работе проанализированы существующие подходы и алгоритмы построения согласованной документарной базы знаний на примере сообщений и лент новостей из Интернета. В качестве основного средства определения сходства документов выбран алгоритм LSI, который сочетает в среднем более высокое качество, чем простейшие детерминированные методы, и более низкую по сравнению с ними вычислительную сложность. После расчета попарных показателей сходства полученная система была приведена в консонансное состояние согласно критерию структурной согласованности множеств. Был проанализирован основной недостаток данного алгоритма, который заключается в отсутствии какой бы то ни было процедуры оценки эффективности его работы и принятия решения о коррекции параметров. Для преодоления этого недостатка разработана комплексная методика, базирующаяся на анализе экспертных оценок качества полученных результатов с учетом степени доверия к мнениям экспертов, для чего была использована теорема Байеса для непрерывно распределенных случайных величин. Такой подход имеет ряд преимуществ. Он обеспечивает алгоритму LSI необходимую обратную связь и позволяет динамически его настраивать, причем этот процесс может быть итеративным и давать все более высокое качество результатов. При этом ЛПР не обязательно должно быть специалистом в предметной области, к которой относятся поступающие на вход документы, а это значит, что процесс анализа результатов экспертизы можно формализовать и автоматизировать. Список литературы 1. Salton G., Buckley C. “Introduction to Modern Information Retrieval“, McGraw Hill, New York, 1983. 2. Packer K. H., Soergel D. “The importance of SDI for current awareness in fields with severe scatter of information“, Journal of the American Society for Information Science, 1979. V. 30 (3), pp. 125-135. 3. Deerwester S., Dumais S.T., Furnas G.W., Landauer T.K., Harshmann R. “Indexing by Latent Semantic Analysis“, Journal of the American Society for Information Science, 1990. V. 41 (6), pp. 127-144. 4. Foltz P.W., Dumais S.T. “Personalized Information Delivery: An Analysis of Information Filtering Methods“, Communications of the ACM, 1992. V. 35 (12), pp. 51-60. 5. Дулин С.К. Анализ структуры рассогласованных множеств // Изв. АН СССР. Техническая кибернетика. - 1985. - № 5. 6. Дулин С.К. Состояние системы, оцениваемое по структурному признаку. - М.: ВЦ АН СССР, 1987. 7. Дулин С.К. Согласование структур в условиях расширенного понятия консонанса // Изв. АН СССР. Техническая кибернетика. - 1987. - № 5. 8. Дулин С.К., Киселев И.А. Управление структурной согласованностью в базе знаний // Изв. АН СССР. Техническая кибернетика. - 1991. - № 5. 9. Дулин С.К., Дулина Н.Г., Киселев И.А. Тематический мониторинг информационных сообщений. - М.: ВЦ РАН, 2000. 10.Дулин С.К., Самохвалов Р.В. Об одном подходе к оценке “риска в риске”// Изв. РАН. Теория и системы управления. - 1996. - № 5. |
 ря уже о проблемах производительности, обусловленных большими размерами матрицы “слова-документы”. Для улучшения ситуации был разработан ряд методов, которые учитывали взаимосвязи между терминами. Одним из таких методов является латентное семантическое индексирование (Latent Semantic Indexing – LSI [3,4]).
ря уже о проблемах производительности, обусловленных большими размерами матрицы “слова-документы”. Для улучшения ситуации был разработан ряд методов, которые учитывали взаимосвязи между терминами. Одним из таких методов является латентное семантическое индексирование (Latent Semantic Indexing – LSI [3,4]).| Permanent link: http://swsys.ru/index.php?id=696&lang=en&page=article |
Print version Full issue in PDF (1.13Mb) |
| The article was published in issue no. № 2, 2002 |
Perhaps, you might be interested in the following articles of similar topics:
- Интеллектуальные хранилища данных в системах государственного управления
- Методы поисковой адаптации на основе механизмов генетики, самообучения и самоорганизации
- Система поддержки принятия решений по планированию профессиональной структуры подготовки специалистов
- Кросс-система автоматизации разработки программного обеспечения на базе языка высокого уровня Рада
- Общедоступные математические САПР для персональных компьютеров класса IBM PC
Back to the list of articles