Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Author: () - | |
| Ключевое слово: |
|
| Page views: 9143 |
Print version Full issue in PDF (1.13Mb) |
Современные взгляды на проблему вступления человечества в новую информационную эру в основном концентрируются в области использования средств вычислительной техники для решения задач, связанных с обработкой информации. Особую актуальность сегодня приобретает перевод информации в компьютерные форматы [1], а также вопросы, связанные с организацией такого перевода за приемлемые сроки, то есть организация программно-аппаратных средств, человеческих ресурсов, объединенных общим понятием сканцентр, направленных на решение актуальнейшей проблемы массового перевода бумажных документов в электронные. При функционировании сканцентра для перевода существующих документов в компьютерные форматы проводится комплекс мероприятий, позволяющий получить полный аналог традиционного документа в компьютерном виде. Основными этапами этого комплекса являются сканирование, распознавание и верификация с достаточно большой трудоемкостью. Как показано в [1], сканцентр включает быстрый документный сканер, станции сканирования, распознавания, верификации, объединенные в сеть, соответствующее программное обеспечение и специально подготовленный персонал. Обработка документов в сканцентре происходит параллельно-конвейерным способом, при котором документ может проходить следующие этапы обработки: сканирование, сегментация, распознавание, верификация, экспорт. Этапы обработки документов в сканцентре подробно рассмотрены в [2]. Кроме того, штатные средства организации параллельной обработки заявок имеют существенный недостаток, который выражается в том, что заявка, поступившая на обработку, не может быть снята до окончания обработки. Этот факт приводит к невозможности удовлетворительной организации приоритетного обслуживания и оптимизации балансировки вычислительных мощностей [2]. ЗАМЕЧАНИЕ 1. Некоторые этапы требуют ручной обработки [2], и скорость прохождения этих этапов зависит от состояния человека-оператора. Такие этапы требуют совершенно специфичной организации обработки и могут быть организованы параллельно с этапами автоматической обработки. Здесь подразумевается, что станция может одновременно выполнять задания с этапа автоматической обработки и позволять оператору проводить ручную обработку. Таким образом, имеет смысл рассматривать оптимизацию обработки заданий на этапах, которые должны проводиться в автоматическом режиме {Q,R,E}. ЗАМЕЧАНИЕ 2. Некоторые заявки могут поступать в сканцентр и должны быть обработаны не по полному циклу, а, например, начиная с этапа сегментации [2]. Таким образом, организация и оптимизация параллельно-конвейерного вычислительного процесса подразумевает решение следующих локальных подзадач: - организация обработки заданий на каждом этапе – определение очередности выборки заданий из очереди готовых к обработке на этапе с учетом приоритетов заданий; - организация обработки заданий между этапами – определение балансировки вычислительных мощностей между этапами обработки с учетом критериев оптимизации. Для реализации параллельно-конвейерной обработки на нескольких станциях, определения очередности выбора листов на распознавание и для балансировки вычислительных мощностей вводится маршрутизатор. Работа маршрутизатора в пределах обработки заявок на данном этапе заключается в определении очередности обработки листов заявок, с тем чтобы обеспечить равномерное продвижение заявок с равным приоритетом и более быструю обработку высокоприоритетных заявок [2]. Известные методы построения диспетчеров [3] предлагают использовать алгоритмы с приоритетами абсолютными, относительными и др. Как показано в [4], такого рода алгоритмы могут приводить к случаям, когда при наличии в очереди высокоприоритетных заявок, заявки с более низкими приоритетами не обслуживаются. Работа вероятностного диспетчера описана в [2,3]. При реализации такого диспетчера не возникает ситуаций, в которых некоторые низкоприоритетные заявки не обслуживаются из-за наличия высокоприоритетных. Для них только уменьшается скорость обработки, то есть они получают меньшую долю общей производительности сканцентра. Однако обработка для них не прекращается, а несколько затормаживается. Такой способ обработки не создает угрозы «мертвых» очередей [2]. Рассмотрим теперь работу диспетчера по организации обработки заданий между этапами – оптимизация балансировки вычислительных мощностей между этапами обработки. В качестве подходов к решению этой задачи могут быть рассмотрены следующие варианты. 1. «Полный цикл» – все станции начинают работу с первого ожидающего этапа, на котором есть необработанные задания, и продвигаются к следующему, полностью завершив работу на текущем этапе. Если поступают новые задания, они ожидают полного цикла обработки предыдущих заданий. 2. «Частичное деление» – станции делятся в некоторой пропорции между ожидающими этапами и далее продолжают обработку по следующим схемам: - станции, назначенные на некоторый этап, закрепляются за заданиями на этом этапе и доводят их обработку до конца (закрепление станций за заданиями), при этом вновь поступившие на этап задания ожидают, пока некоторая группа станции освободится; - при переходе задания с этапа на этап балансировка станций перерассчитывается и может быть изменена, если где-то начинает скапливаться достаточно большое число заданий на обработку – закрепление станции за этапами.
Понятно, что после начала обработки в произвольные моменты времени могут поступать на обработку новые задания, задания могут переходить с этапа на этап (в этом проявляется конвейеризация), станции могут быть добавлены для обработки на какой-либо этап с другого этапа или вновь поступившими. Таким образом, возникает необходимость в создании алгоритма прогнозирования, который позволял бы с учетом времени начала работы станции на этапе достаточно быстро (накладные расходы на диспетчеризацию должны быть минимальны) вычислять предполагаемое время окончания обработки на данном этапе при данных начальных условиях. Рассмотрим алгоритм прогнозирования. При назначении/удалении дополнительных станций на какой-либо этап обработки (а также при поступлении новых заданий), в момент назначения/поступления требуется рассчитать, сколько времени потребует обработка заданий на этом этапе с учетом вновь поступивших станций/заданий. Необходимо рассмотреть следующие варианты протекания процесса обслуживания на этапе: · на этапе еще не работает ни одной станции; · на этапе уже работают станции, возможно начавшие работу в неравные моменты времени; · во время обработки заданий на этапе могут быть добавлены или удалены не только станции, но и задания. Положим для определенности, что длительность обработки на данном этапе равна Необходимо определить, сколько будет продолжаться обработка пакета заданий на этапе step, если, начиная с момента времени t=5, для работы на этапе step будет выделено еще
· рассчитать, сколько листов уже сделано к моменту времени t=5, сколько находится в обработке, сколько осталось сделать; · рассчитать, когда закончится обработка последнего листа. Поскольку на данном этапе могут уже работать некоторые станции, начавшие работу в разные моменты времени, расчет необходимо выполнять по каждой задействованной станции, для которой имеются сведения о моменте начала обработки в абсолютных величинах Для одной станции количество сделанных листов может быть рассчитано по (1),
где
где Тогда вычислить количество нераспределенных листов можно по (3):
где суммирование производится для всех станций, занятых в обработке к моменту времени t=5. При назначении новых станций на обработку заданий на данном этапе необходимо учитывать, что обработка заданий не может прерываться. Однако для расчета времени окончания обработки последнего листа предположим, что возможно отложить обработку недоработанных листов, провести обслуживание, начиная с новых заданий, а недообработанные части дообработать по завершении всех листов. То есть условно изменить расписание обслуживания и привести его к виду, изображенному на рисунке 2. Очевидно, что в этом случае общая картина останется без изменений и станет возможным проведение расчета времени окончания обработки последнего листа задания. Понятно, что все оставшиеся листы –
Соответственно, первая добавка к времени окончания обработки последнего листа будет вычислена как Для вычисления второй добавки рассмотрим листы, не попавшие в «нарезанные» блоки. Число этих листов 1. 2. 3. Таким образом, значение второй добавки вычисляется согласно (5).
где ЗАМЕЧАНИЕ 3. Удаление Si-й станции с этапа обработки означает, что листы, обработанные этой станцией, перешли на следующий этап обработки или покинули систему. Таким образом, величина Предварительное исследование алгоритмов балансировки вычислительных мощностей показало оптимизацию до 46% для некоторых классов начальных распределений заданий. Эти результаты свидетельствуют о том, что организация параллельно-конвейерного вычислительного процесса в сканцентре, основанная на научном подходе и детальном анализе предметной области, позволяет достичь решения задачи массового перевода информации с бумажных носителей в компьютерные форматы за приемлемое время [2]. Сегодня пока остаются открытыми вопросы, связанные с определением оптимального алгоритма балансировки для каждого из классов начальных распределений заданий, а также порогов динамического перераспределения, и требуют дальнейших исследований. Настоящие результаты получены в Международной лаборатории ELDIC. Список литературы 1. Вишняков Ю.М., Цур А., Хашковский В.В. Скантехнологии. Параллельная обработка заданий в интрасети. //Изв. ТРТУ. Темат. выпуск: Матер. Всерос. науч.-техн. конф. с междунар. участ.: Компьютерные технологии в управленческой и инженерной деятельности. - Таганрог: ТРТУ, 2001. - №3 (21) – С.216-217. 2. Вишняков Ю.М., Хашковский В.В. Параллельно-конвейерная обработка документов в сканцентре. //ИСАПР. - Таганрог, ТРТУ, 2001. 3. Клейнрок Л. Вычислительные системы с очередями. - М.: Мир, 1979. 4. Маматов Ю.А. Организация работы мультипроцессорных СЦВМ с многоуровневой памятью //Дис. на соискание ученой степени д-ра техн. наук. |
 Решение этой задачи требует использования оптимального по времени окончания обработки алгоритма балансировки и опирается на алгоритмы прогнозирования. Допустим, в момент времени t0=0 имеется M станций и три задания, состоящие из Z1, Z2, Z3 листов, которые должны быть обработаны, начиная с этапов Q, Q, R соответственно. В этом случае распределение станций по этапам для начала обработки будем называть балансировкой вычислительных мощностей.
Решение этой задачи требует использования оптимального по времени окончания обработки алгоритма балансировки и опирается на алгоритмы прогнозирования. Допустим, в момент времени t0=0 имеется M станций и три задания, состоящие из Z1, Z2, Z3 листов, которые должны быть обработаны, начиная с этапов Q, Q, R соответственно. В этом случае распределение станций по этапам для начала обработки будем называть балансировкой вычислительных мощностей.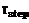 , где
, где 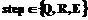 для всех заданий. Для обработки на данном этапе назначено
для всех заданий. Для обработки на данном этапе назначено 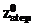 листов – общее количество листов, назначенных на этап обработки. Также известно, что на этапе работают M=2 станции S1 и S2, начиная с моментов времени
листов – общее количество листов, назначенных на этап обработки. Также известно, что на этапе работают M=2 станции S1 и S2, начиная с моментов времени  и
и 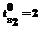 соответственно.
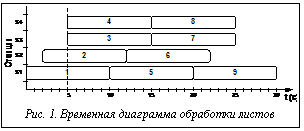
соответственно.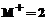 станции – S3 и S4. Проиллюстрируем на рисунке 1 временную диаграмму обработки листов №1 – №9, исходя из алгоритма произвольного назначения заданий на освобождающиеся станции (алгоритм FCFS – First-Come-First-Served).
станции – S3 и S4. Проиллюстрируем на рисунке 1 временную диаграмму обработки листов №1 – №9, исходя из алгоритма произвольного назначения заданий на освобождающиеся станции (алгоритм FCFS – First-Come-First-Served).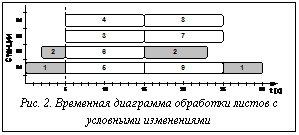 Решение данной задачи разбивается на два шага:
Решение данной задачи разбивается на два шага: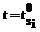 – время начала работы станции Si.
– время начала работы станции Si.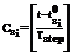 , (1)
, (1)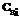 – количество сделанных листов станцией Si, [x] – целая часть x, а также можно вычислить, сколько времени осталось до окончания обработки текущего листа на станции по (2):
– количество сделанных листов станцией Si, [x] – целая часть x, а также можно вычислить, сколько времени осталось до окончания обработки текущего листа на станции по (2):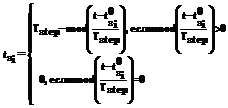 , (2)
, (2)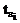 – время до окончания обработки на Si;
– время до окончания обработки на Si;  – остаток целочисленного деления X на Y.
– остаток целочисленного деления X на Y.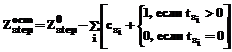 , (3)
, (3)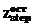 , обработка которых еще не начиналась, могут быть «нарезаны» на некоторое количество блоков, состоящих из количества листов, кратного количеству станций, занятых в обработке с момента времени t=5. Тогда время окончания обработки последнего листа может быть вычислено по частям. Количество блоков, состоящих из количества листов, кратного количеству станций, равно:
, обработка которых еще не начиналась, могут быть «нарезаны» на некоторое количество блоков, состоящих из количества листов, кратного количеству станций, занятых в обработке с момента времени t=5. Тогда время окончания обработки последнего листа может быть вычислено по частям. Количество блоков, состоящих из количества листов, кратного количеству станций, равно: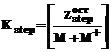 . (4)
. (4) .
.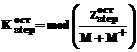 . В зависимости от количества станций, занятых на обработку на данном этапе, может быть получено следующее распределение:
. В зависимости от количества станций, занятых на обработку на данном этапе, может быть получено следующее распределение: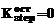 ;
;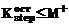 ;
;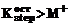 .
.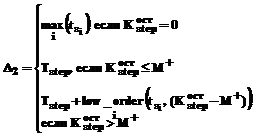 ,
,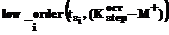 возвращает
возвращает 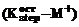 -й элемент в отсортированном по неубыванию массиве
-й элемент в отсортированном по неубыванию массиве 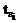 .
.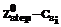 .
.| Permanent link: http://swsys.ru/index.php?id=704&lang=en&page=article |
Print version Full issue in PDF (1.13Mb) |
| The article was published in issue no. № 2, 2002 |
Perhaps, you might be interested in the following articles of similar topics:
- Зарубежные базы данных по программным средствам вычислительной техники
- Разработка загрузчика программного обеспечения встроенной системы управления
- Алгоритмы и процедуры построения билинейных моделей непрерывных производств
- Реализация теней с помощью библиотеки OpenGL
- Опыт разработки и эксплуатации системы управления базами данных (DBS/R)
Back to the list of articles