Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: () - , () - , () - , () - | |
| Ключевое слово: |
|
| Page views: 15660 |
Print version Full issue in PDF (1.83Mb) |
Проблема контроля доступа к Интернет-ресурсам актуальна и имеет важное прикладное значение по следующим основным причинам: блокирование доступа к нелегальной информации, предотвращение доступа к Интернет-ресурсам в личных целях в учебное или рабочее время, предотвращение утечки конфиденциальной информации через Интернет. Так как основная часть Интернет-ресурсов сегодня является динамической, это делает малопригодными традиционные сигнатурные подходы, основанные на базе данных статических URL или осуществляющих анализ содержимого на основе ключевых слов. Поддержка подобной базы данных в актуальном состоянии в силу постоянного изменения содержимого Интернет-ресурсов существенно снижает точность работы сигнатурных систем. Поэтому необходим некий подход, который позволил бы быстро и точно в режиме реального времени осуществлять анализ содержимого Интернет-ресурсов. Авторами статьи предлагается подход к построению систем фильтрации трафика на основе методов машинного обучения, а именно многоклассовой многотемной классификации гипертекстовых документов. Данный подход имеет ряд существенных преимуществ перед традиционными подходами: независимость от внешних баз данных и экспертов; автоматический процесс обучения; высокая скорость и точность работы; обучаемость и дообучаемость; адаптация к потребностями конкретных организаций. Архитектурное решение Предлагаемый авторами подход требует разработки как самой архитектуры системы, основанной на методах машинного обучения, так и специализированных алгоритмов разбора и анализа Интернет-документов в силу их специфики. Для оценки качества функционирования систем фильтрации Интернет-трафика используются следующие количественные показатели (характеристики): - точность анализа – процент верно отфильтрованных Интернет-ресурсов; - излишнее блокирование или ложно-положительные ошибки – процент хороших ресурсов, ошибочно запрещенных системой фильтрации; - недостаточное блокирование или ложно-отрицательные ошибки – процент плохих ресурсов, ошибочно разрешенных системой фильтрации; - скорость анализа – максимальный объем данных, который система может проанализировать в единицу времени. Проанализировав характеристики и недостатки подобных систем, авторы предлагают следующие требования к современным системам фильтрации Интернет-трафика: · анализ и фильтрация Интернет-информации в режиме реального времени с возможностью адаптироваться к постоянной динамике изменения Интернет-ресурсов; · осуществление фильтрации Интернет-ресурсов с использованием как их содержимого, так и метаданных; · возможность персонифицировать трафик, то есть максимально точно идентифицировать пользователя, от которого поступил запрос на ресурс; · анализ не только входящего, но и исходящего от пользователей трафика; · возможность удаления категорий фильтрации и добавления новых категорий с новыми обучающими примерами; · независимость от языков Интренет-ресурсов. Авторами предложена архитектура и алгоритмы анализа и фильтрации Интернет-трафика на основе методов машинного обучения для многотемной классификации гипертекстовых документов [1,2]. Методы машинного обучения обладают достоинствами самообучаемости, адаптируемости, автономности. Учитывая требования к системам фильтрации трафика, предложена архитектура системы, состоящая из следующих основных компонент. Ядро системы, координирующее работу модулей системы и сохранение в базе знаний информации о пользователях, запросах, запрашиваемых ресурсах, а также результатов анализа и классификации. Кэш-прокси-сервер, предназначенный для кэширования и перенаправления в режиме реального времени запросов и содержимого Интернет ресурсов из локальной сети к ядру системы [3-5]. Модуль принятия решений, осуществляющий разрешение или блокирование доступа к Интернет-ресурсам на основе метаинформации о ресурсе (его URL), результатов классификации (в случае необходимости) и заданных политик фильтрации для конкретного пользователя. Модуль лексического разбора (парсинга) и классификации, осуществляющий преобразование HTML-документов во внутреннее представление и многотемную (multi-label) классификацию в режиме реального времени. Робот, использующийся в системе для скачивания содержимого ресурсов с целью последующего обучения на них и для классификации документов, ссылки на которые были выявлены ранее в процессе анализа других документов. Алгоритмическое решение Задача классификации текстовых и гипертекстовых документов – одна из основных алгоритмических задач, возникающих при реализации системы анализа и фильтрации Интернет-трафика. Для эффективного решения данной задачи важную роль начинают играть методы машинного обучения и интеллектуального анализа данных (data mining), предназначенные для анализа, классификации и выявления скрытых закономерностей в больших объемах разнородных сложно структурированных данных. В данной задаче необходимо решать две базовые подзадачи: · разработать эффективную формальную модель представления текстовых и гипертекстовых документов с учетом как их содержимого, так и ссылочной структуры; · разработать эффективный алгоритм решения задачи многотемной классификации (multi-label classification), то есть классификации в условиях существенно перекрывающихся классов, когда любой объект классификации (документ) может принадлежать более чем одному классу (теме) одновременно, а некоторые классы могут быть вложенными. Модель представления гипертекстовых данных. В настоящем исследовании предложен метод построения модели представления, основанный на выделении частых эпизодов [3]. В этом случае множество частых комбинаций лексем (или N-грамм) формирует новое признаковое пространство, где каждому эпизоду, в который входит одна (или более) лексема (или N-грамма), соответствует одна координата в признаковом пространстве. То есть такой метод является расширением традиционной векторной модели, поскольку часто встречаемые лексемы (или N-граммы) также входят в модель как эпизоды единичного размера. При представлении гипертекстовых документов важно учитывать не только текст, содержащийся в самих документах, но и наличие гиперссылок между документами. Учет гиперссылок позволяет получить более точное (для классификации) представление документа, по сравнению с учетом только локального текста классифицируемого документа. Идея предлагаемого нами подхода для учета гиперссылок состоит в следующем. Сначала обучаем текстовый классификатор при N-граммном представлении документов, учитывая при обучении только их локальный текст. Затем применяем данный классификатор к текстовому представлению каждой гиперссылки, встречающейся в документе. При формировании окончательного представления текущего документа каждую гиперссылку заменяем набором специальных идентификаторов, соответствующих идентификаторам предсказанных классов. Таким образом, предлагаемый подход для учета гиперссылок позволяет учитывать встречающиеся в документах гиперссылки без необходимости получения и анализа содержимого документов-соседей, что очень важно для осуществления анализа документов в режиме реального времени. Метод классификации многотемных (multi-label) документов. В задаче многотемной (multi-label) классификации в обучающей совокупности Решение задачи multi-label классификации на основе ранжирования включает два этапа. Первый этап состоит в обучении алгоритма ранжирования, который упорядочивает все классы по степени их релевантности (например, вероятности принадлежности) для заданного классифицируемого объекта. Второй этап заключается в построении функции multi-label классификации, отделяющей релевантные классы от нерелевантных. В настоящей работе исследуется возможность использования для решения задачи multi-label классификации подхода на основе декомпозиции типа каждый-против-каждого с отсечением наименее релевантных классов. Предлагается, во-первых, новый алгоритм ранжирования, основанный на модифицированном (для случая существенно пересекающихся классов) методе попарных сравнений с помощью набора бинарных классификаторов и вычислений степеней принадлежности к классам с использованием обобщенной модели Брэдли-Терри с «ничьей» [3]; во-вторых, новый алгоритм построения пороговой функции отсечения нерелевантных классов, строящий пороговую функцию не в исходном пространстве характеристик, а в пространстве релевантностей классов, что позволяет упростить вид пороговой функции, значительно сократить вычисления и в большинстве случаев увеличить точность. Следует отметить, что ранее подход на основе попарных сравнений не давал позитивных результатов для задач многотемной классификации, поскольку не удавалось решить проблему декомпозиции – построить точный классификатор, разделяющий два существенно перекрывающихся (не взаимоисключающих) класса. В предложенном алгоритме ранжирования каждая пара возможно перекрывающихся (и даже вложенных) классов j и k разделяется с помощью двух бинарных классификаторов, отделяющих пересекающиеся и непересекающиеся области. Предложенный метод отсечения нерелевантных классов основан на построении линейной решающей функции в пространстве релевантностей классов с использованием результата работы алгоритма ранжирования как нового множества признаков анализируемого электронного документа [4]. Результаты экспериментального исследования Приведем описание экспериментального исследования производительности разрабатываемой системы на эталонных тестовых наборах данных Reuters-2000 (набор многотемных текстовых документов, не содержащих гиперссылки) и BankResearch (набор однотемных гипертекстовых документов). Для чистоты эксперимента нужно продемонстрировать, что и предложенная модель представления, и разработанный алгоритм позволяют улучшить качество классификации сами по себе, а не только в совокупности. Поэтому тестирование модели представления и сравнение ее с существующими популярными моделями проводилось на наборе BankResearch на базе традиционного алгоритма классификации типа основе «k ближайших соседей» [5]. Данный алгоритм был выбран как наиболее чувствительный к модели представления. Тестирование алгоритма многотемной классификации проводилось на наборе Reuters-2000 на базе традиционной модели представления с помощью ключевых слов, а результат сравнивался с ведущими современными алгоритмами многотемной классификации. Для оценки точности работы алгоритмов многотемной классификации использовались следующие общепринятые оценки: Hamming Loss, Coverage и Ranking Loss [5]. Результаты экспериментов представлены в виде сводной таблицы по всем основным критериям точности. В строке размерность пространства приведена размерность пространства признаков построенной модели. Таблица 1 Результаты сравнения различных моделей представления гипертекстовых данных
Значение, следующее за «+/-», показывает стандартное отклонение; наилучшие результаты по каждому критерию выделены жирным шрифтом. Таким образом, предложенная модель представления на основе частых эпизодов с частотной мерой сходства кардинально превосходит традиционные подходы по всем основным критериям. Также можно видеть, что предложенный метод включения информации о гиперссылках в модель представления позволяет получить улучшение точности практически для любой базовой модели. Тестирование всех разработанных алгоритмов multi-label классификации проводилось на эталонном наборе многотемных данных Reuters-2000. Сравнение разработанного метода многотемной классификации проводилось с ведущими существующими методами: Multi-class Multi-label Perceptron (MMP); AdaBoost.HM; ML-KNN и 1-vs-all-SVM. Результаты экспериментов приведены в таблице 2. Таблица 2 Экспериментальные результаты работы алгоритмов классификации на наборе Reuters-2000
Как видно из таблицы, разработанный метод превосходит существующие по всем основным характеристикам, особенно по качеству ранжирования (Coverage и Ranking Loss). В заключение следует отметить, что авторами предложен новый подход к построению систем анализа и фильтрации Интерент-трафика на основе методов интеллектуального анализа данных; предложено архитектурное и алгоритмическое решение для построения таких систем. Алгоритмические задачи, которые необходимо решать при реализации систем фильтрации Интернет-трафика, сводятся к необходимости разработки эффективных моделей представления исходных гипертекстовых данных с учетом их текстового содержания и структуры гиперссылок, а также разработки эффективных методов решения задачи классификации многотемных документов. Проведены эксперименты по оценке точности и скорости разработанных алгоритмов и оценке производительности системы. Все разработанные модели представления и методы многотемной классификации были экспериментально проверены на эталонных тестовых наборах данных, где показали лучшие результаты по сравнению с традиционными моделями и методами. Также на основе экспериментальных результатов можно сделать вывод, что по производительности данный подход применим, поскольку время разбора, анализа и классификации потока гипертекстовых данных сопоставимо (а, как правило, и значительно меньше) со временем загрузки ресурсов из Интернета, то есть не вносит значительных дополнительных задержек в работу пользователя. Список литературы 1. Valentina Glazkova, Vladimir Maslyakov, Igor Mashechkin and Mikhail Petrovskiy. Internet Traffic Filtering System Based on Data Mining Approach // Proceedings of the First Spring Young Researches’ Colloquium on Software Engineering. 2. Машечкин И.В., Петровский М.И., Глазкова В.В., Масляков В.А. Концепция построения систем анализа и фильтрации Интернет-трафика на основе методов интеллектуального анализа данных //Математические методы распознавания образов: 13-я Всерос. конф. / Сб. докл. – М.: МАКС Пресс, 2007. - С. 494-496. 3. Петровский М.И., Глазкова В.В. Алгоритмы машин- ного обучения для задачи анализа и рубрикации электрон- ных документов. // Вычислительные методы и программирование. – 2007. - №8. - С. 57-69. (www.num-meth. srcc.su/zhurnal/tom8r207.html). 4. Glazkova V.V., Petrovskiy M.I. Multi-topic text categorization based on ranking approach // Proc. of SYRCoSE 2007. N 1. M: ИСП РАН, 2007. P. 49-55. 5. M.-L. Zhang, Z.-H. Zhou, “A k-nearest neighbor based algorithm for multi-label classification”, Proc. of IEEE GrC'05, Beijing, China, 2005, pp. 718-721. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 для каждого примера
для каждого примера 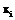 задан не единственный класс, а множество релевантных классов
задан не единственный класс, а множество релевантных классов  , и целью алгоритма машинного обучения является построение классификатора
, и целью алгоритма машинного обучения является построение классификатора 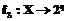 , предсказывающего все релевантные классы, где X – исходное пространство признаков; q – число классов.
, предсказывающего все релевантные классы, где X – исходное пространство признаков; q – число классов.| Permanent link: http://swsys.ru/index.php?id=733&lang=en&page=article |
Print version Full issue in PDF (1.83Mb) |
| The article was published in issue no. № 2, 2008 |
Perhaps, you might be interested in the following articles of similar topics:
- Система программного обеспечения единого технико-программного комплекса для гибких автоматизированных производств механообработки
- Эволюционная модель формирования структур виртуальных предприятий
- Учебный банк: технологии изучения банковских систем и телекоммуникаций
- Сравнительный анализ некоторых алгоритмов распознавания
- Информационная система оптимизации расписания доставки грузов от производителей сырья
Back to the list of articles