Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Author: () - | |
| Ключевое слово: |
|
| Page views: 11817 |
Print version Full issue in PDF (1.58Mb) |
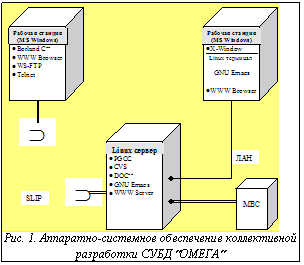
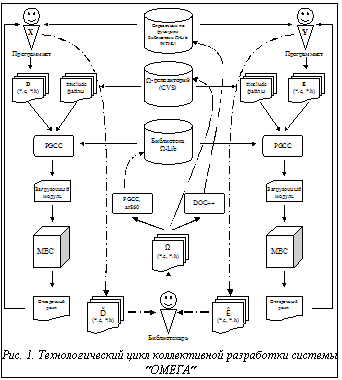
Эффективная разработка больших программных систем сегодня невозможна без использования современных технологий программирования. По определению [1] под технологией программирования понимается совокупность концептуальных, организационных и программных средств, используемых для создания программного обеспечения. В данной работе рассматривается проблема выбора программных средств, используемых для разработки параллельной СУБД ²Омега² [2] для мультипроцессорной вычислительной системы МВС‑100/1000 [3,4]. Инструментарий разработчика может формироваться двумя способами. Первый – выбрать интегрированную среду разработки (технологический комплекс), поддерживающий все основные этапы технологического цикла разработки программного обеспечения. В свое время было создано большое количество подобных технологических комплексов (см. [5‑8]). Основным недостатком данного подхода является то, что разработчики привязываются к определенному программному обеспечению и, соответственно, ограничиваются рамками его функциональных возможностей. При необходимости использовать функцию, отсутствующую в данном технологическом комплексе, приходится либо дорабатывать комплекс, либо переходить на новый. Использование конкретного технологического комплекса также ограничивает выбор разработчиками аппаратной платформы. Подобный подход оказывается эффективным при разработке прикладного программного обеспечения для решения определенного класса задач, например при разработке приложений, работающих с БД [9]. Второй подход заключается в подборе комплекса независимых инструментальных средств, каждое из которых поддерживает определенный этап технологического цикла. Преимуществом данного подхода является высокая гибкость в формировании технологической среды разработчиков. Разработчики даже в рамках одного проекта могут подбирать определенные компоненты технологической среды в соответствии со своими индивидуальными склонностями и навыками. При таком подходе относительно просто заменить технологический компонент, переставший удовлетворять требованиям проекта и разработчиков. Основной проблемой, возникающей при данном подходе, является правильный подбор и интеграция программных продуктов, образующих технологическую среду проекта. Второй подход наиболее часто используется при создании системного программного обеспечения. Данный подход и был использован при формировании средств программной поддержки процесса прототипирования СУБД ²Омега². Архитектура МВС-100/1000 По классификации, описанной в [10], суперкомпьютер МВС-100/1000 разработки НИИ "Квант", ИПМ им. М.В. Келдыша РАН, ВНИИТФ и ИММ УрО РАН представляет собой многопроцессорную систему с кластерной архитектурой. В соответствии с таксономией Флинна [11] архитектуру МВС-100/1000 можно отнести к классу MIMD. МВС‑100/1000 состоит из процессорных модулей. Каждый модуль представляет собой двухпроцессорную ЭВМ, состоящую из вычислительного и коммуникационного процессоров. В качестве вычислительного процессора в МВС‑100 используется суперскалярный процессор i860 фирмы Intel. Коммуникационный процессор адресует всю оперативную память процессорного модуля, вычислительный процессор является частью этой памяти. Синхронизация коммуникационного и вычислительного процессоров реализована аппаратно. Единственными внешними устройствами процессорного модуля являются скоростные каналы – линки, имеющиеся у коммуникационного процессора. Коммуникационный процессор имеет от четырех (МВС‑100) до шести (МВС‑1000) линков. С помощью этих линков процессорные модули соединяются друг с другом и с дисковой подсистемой. Система может включать в себя сотни вычислительных модулей и несколько дисковых подсистем, образующих сеть процессорных элементов. Полученная таким образом сеть связана одним своим линком с управляющей ЭВМ (host-машиной), представляющей собой IBM PC-совместимую рабочую станцию. В качестве операционной системы (ОС) на МВС‑100 используется ОС Router разработки ИПМ им. М.В. Келдыша РАН. В качестве ОС host-машины обычно используется ОС UNIX/Linux. ОС Router представляет собой распределенную ОС класса toolset. Она состоит из процессорного сервера, который запускается на каждом коммуникационном процессоре, и host-сервера (iserver.exe), запускаемого на host-машине. И процессорный сервер, и host-сервер загружаются всякий раз перед загрузкой задачи пользователя. ОС Router обеспечивает следующие основные функции: · загрузку программ пользователя с host-машины на процессорные модули; · обмен данными между программой и host-машиной в виде некоторого подмножества системных функций ввода/вывода UNIX; · обмен сообщениями по линкам между программами, запущенными на различных вычислительных процессорах. Задача пользователя выполняется только на вычислительных процессорах и представляет собой совокупность процессов. На каждом процессорном модуле может выполняться только один пользовательский процесс. Каждый процесс реализуется в виде программы, которая с точки зрения системы программирования является отдельным загрузочным модулем. В тексте программы в явном виде используются функции ОС Router, реализующие обмен сообщениями с другими программами. Средства написания программ на процессорной сети в целом не предоставляются. Технология коллективной разработки системы ²Омега² Структура программных средств поддержки коллективной разработки СУБД ²Омега² включает в себя следующие основные компоненты: систему контроля версий CVS, документатор DOC++ и компилятор C фирмы Portland Group (PGCC) для i860. Все три программных продукта являются разработками независимых фирм. Приведем краткое описание данных систем. Система контроля версий CVS [12] является основным инструментом версионирования и поддержки коллективной разработки проекта. Система функционирует в среде ОС UNIX и представляет собой CASE-пакет разработчика (toolkit), который можно использовать на этапе кодирования и сопровождения. В CVS поддерживаются понятия репозитория и рабочей копии проекта. В репозитории хранятся полные копии всех файлов и каталогов проекта. Каждый участник проекта работает со своей индивидуальной рабочей копией проекта. Создав свою рабочую копию проекта, участник проекта затем должен периодически выполнять ее обновление. Изменения в файлах рабочей копии не будут доступны другим участникам проекта, пока не будет выполнена их синхронизация. Выполняя синхронизацию, CVS заставляет разработчика прокомментировать внесенные изменения. При обновлении и синхронизации рабочей копии проекта CVS осуществляет автоматическое слияние изменений, внесенных другими разработчиками, если эти изменения не затрагивают одни и те же строки файлов. В случае конфликта изменений в рабочей копии файла с содержанием этого файла из репозитория конфликтующие строки помечаются в файле специальными маркерами, и разработчик должен разрешить конфликт вручную, после чего выполнить синхронизацию изменений. Разработчик может просмотреть историю изменения заданного файла проекта, сравнить разные версии одного файла, узнать статус файла: нужно ли выполнить его синхронизацию, нуждается ли файл в обновлении и имеются ли конфликты. Каждая версия файла имеет номер ревизии, который автоматически изменяется при выполнении синхронизации. Номера ревизий могут выглядеть так: 1.1, 1.2, 1.3 или в случае создания ветки проекта 1.2.2.1. и даже 1.3.2.2.4.5. Файлы проекта (или релиз) с различными номерами ревизий можно объединять одним именем. Например, release-1, last_week_ release, release-1_patches. Разработчик может получить копию файла или всего проекта по заданному номеру ревизии или имени релиза. При отладке либо сопровождении предыдущих релизов проекта часто возникает потребность внести в них какие-либо изменения, а затем выполнить слияние этих изменений в текущую разработку. В CVS поддерживаются понятия основного пути (main trunk) и ветки (branch) разработки проекта. Для решения указанной проблемы разработчику необходимо получить копию нужного релиза проекта, создать его ветку, а после внесения необходимых изменений выполнить их слияние и синхронизацию. Система CVS представляется весьма полезным средством для коллективной разработки сложных программных систем. Система документирования DOC++ [13] позволяет подготавливать высококачественную документацию по программной системе непосредственно в процессе работы с исходными текстами программ на языке С. Данный подход позволяет выполнить требование самодокументируемости исходных текстов и при этом избежать дублирования информации в исходных текстах и в документации. Это наиболее эффективный путь обеспечения актуальности документации и ее соответствия исходным текстам. Основная идея документатора состоит во введении специального вида комментариев следующего формата: /** . . . */. Такие комментарии анализируются документатором и переводятся в формат HTML. При этом документатор использует ряд зарезервированных слов, помещаемых в комментарий и начинающихся с символа @. На рисунке 1 приведен пример фрагмента программы на языке C, содержащий спецификацию функции, подготовленную для документатора DOC++. Исходные тексты, подготовленные подобным образом, автоматически компилируются документатором в качественную документацию в формате HTML. Основными преимуществами данного подхода к подготовке документации по проекту являются: постоянная актуальность и адекватность документации, возможность работы с данной документацией на всех аппаратно-программных платформах, имеющих HTML обозреватель (HTML browser), возможность работы с документацией через Internet. /** Данная функция порождает новую нить. При этом вычисляется значение ее Т‑фактора. Передачи управления новой нити при этом не происходит. Фактически th_fork() создает новую запись в таблице нитей менеджера нитей. Если не указана факторфункция, то в качестве факторфункции берется константа (TH_FACTOR_MAX/2). Если в качестве приоритета указано значение TH_MAX_NICE, то данная нить будет выполняться только в том случае, если в данный момент времени в системе отсутствуют готовые к выполнению нити с более высоким приоритетом. @memo Создание новой нити @paramrter proc -указатель на функцию, представляющую тело нити @paramrter param - указатель на список параметров, или NULL @paramrter factorfn - указатель на факторфункцию, или NULL @paramrter type - тип нити: \begin{verbatim} TH_AND - конъюнктивная TH_OR - дизъюнктивная TH_SYS - системная \end{verbatim} @paramrter nice - приоритет нити (целое число от -20 до 20). @return - положительный tid новой нити, или отрицательное значение, указывающее на ошибку: \begin{verbatim} TH_OVERFLOW - переполнение таблицы нитей, TH_ENOMEM - недостаточно памяти для создания новой нити \end{verbatim} @see th_proc_t */ extern th_tid_t th_fork(th_proc_t proc, void* param, th_factorfn_t factorfn, th_type_t type, th_nice_t nice); Рис. 1. Спецификация функции с использованием специальных комментариев DOC++ Компилятор Portland Group C (PGCC) для i860 [14] фирмы Intel является совместимым со стандартом ANSI C и разработан специально для достижения максимальной производительности на суперкомпьютерах, разработанных на базе i860. PGCC компилятор включает глубокую векторизацию, открытую подстановку функций и многоуровневую оптимизацию программного кода. Компилятор включает в себя компоновщик, позволяющий получать загрузочные модули, которые могут быть непосредственно выполнены на i860. Компилятор также включает в себя средства создания библиотек объектных модулей (в виде программы-библиотекаря ar860), которые могут использоваться при компоновке программ. Это особенно важно для организации коллективной разработки сложных программных систем. Версия компилятора PGCC, поставляемая с МВС‑100, разработана для среды DOS и представляет собой кросскомпилятор. К недостаткам данной версии следует отнести отсутствие символьного отладчика и профилировщика. Организация коллективной разработки системы ²Омега² схематически изображена на рисун- ке 2. На данной схеме программист X разрабатывает некоторую подсистему D системы W, а программист Y параллельно разрабатывает некоторую подсистему E системы W. Предполагается, что ранее были разработаны подсистемы A, B и C, которые и составляют текущий прототип системы W. Вся история проекта хранится в W‑репозитории, который поддерживается средствами CVS. Данный репозиторий хранит все исходные тексты подсистем A, B и C и все изменения, которые были в них произведены после включения в репозиторий. С помощью компилятора PGCC и программы-библиотекаря ar860 функции подсистем A, B и C объединены в библиотеку W‑Lib. Разрабатываемые подсистемы D и E образуют следующий уровень иерархии по отношению к подсистемам A, B и C и являются независимыми друг от друга. С помощью системы DOC++ из исходных текстов подсистем A, B и C сгенерирован гипертекстовый Справочник по функциям W‑Lib в формате HTML, который может просматриваться любым WWW обозревателем. Для обращения к функциям подсистем A, B и C программист получает из репозитория тексты соответствующих #include файлов. С помощью компилятора PGCC строятся загрузочные модули тестов подсистем D и E, при этом в качестве параметра компиляции указывается библиотека W‑Lib. Загрузочные модули тестов D и E выполняются на МВС. По полученным отладочным дампам анализируются и локализуются ошибки. В исходные тексты вносятся исправления, и цикл повторяется. После того как все тесты новой подсистемы, скажем D, прошли без ошибок, ее исходные тексты передаются библиотекарю проекта. При этом данные тексты уже содержат спецификации функций подсистемы D в соответствии с синтаксисом DOC++. Библиотекарь выполняет следующую стандартную последовательность действий. Он помещает исходные тексты подсистемы D в свою рабочую копию проекта. После этого библиотекарь собирает и запускает комплексный тест системы W. Если при выполнении теста возникли ошибки, подсистема возвращается программисту на доработку. Если комплексный тест прошел нормально, то средствами CVS библиотекарь помещает исходные тексты подсистемы в Репозиторий проекта. Затем с помощью компилятора PGCC и программы-библиотекаря ar860, создается новый вариант библиотеки W‑Lib, включающий в себя функции подсистем A, B, C и D. И наконец, с помощью системы DOC++ генерируются HTML страницы, содержащие справочную информацию по функциям подсистемы D, которые добавляются в Справочник по функциям W‑Lib. Если при дальнейшей разработке проекта в подсистеме D обнаруживается ошибка, то программист X копирует в свой рабочий каталог библиотеку W‑Lib. Затем с помощью программы-библиотекаря ar860 он удаляет из этой копии библиотеки все модули подсистемы D, получая библиотеку W‑D‑Lib. После этого он возобновляет работу над подсистемой D, только теперь в технологическом цикле вместо W‑Lib он использует W‑D‑Lib. Аппаратно-системное обеспечение коллективной разработки СУБД ²Омега² Структура аппаратно-системного обеспечения коллективной разработки СУБД ²Омега² приведена на рисунке 3. Центральным звеном аппаратно-системного обеспечения является UNIX/Linux сервер, играющий роль host-машины для МВС‑100. Для запуска PGCC, в том числе удаленного, используется DOS-эмулятор. Это позволяет вписать весь технологический цикл разработки в рамки одной ОС – UNIX/Linux. Данное аппаратно-системное обеспечение предусматривает два варианта рабочего места программиста. Первый вариант полностью ориентирован на среду Linux. В качестве редактора используется редактор GNU Emacs, имеющий встроенную поддержку языка С и встроенный интерфейс с системой контроля версий CVS. Фактически Emacs играет роль интегрирующей оболочки, позволяющей редактировать, компилировать и запускать программы на язы-ке С. На рабочих станциях разработчиков устанавливается OC Windows-95 или Windows-NT. Рабочие станции находятся в общей локальной сети с Linux сервером, являющимся host-машиной для МВС‑100. Для работы с Linux сервером на рабочих станциях используются Х‑терминалы. Второй вариант в качестве редактора использует среду Borland C++. Копии исходных текстов находятся на рабочей станции. После редактирования они по FTP пересылаются на Linux сервер. В качестве UNIX терминалов во втором варианте используется Telnet. С помощью DOS эмулятора на сервере Linux запускается PGCC компилятор, после чего задача запускается на выполнение на МВС‑100. Оба варианта интенсивно используют утилиту Make. Второй вариант имеет два важных преимущества. Во-первых, он позволяет работать через Internet. В первом варианте этому препятствует недопустимо низкая для Х‑терминала скорость передачи данных через Internet.
Среда программирования Отладчик. Среда программирования PGCC для МВС‑100 не содержит встроенного отладчика. Поэтому в рамках проекта ²Омега² был разработан простой отладчик, выполняющий трассировку программы и отладочную печать. Отладчик состоит из функций: · Begin_debug() – начать отладочную печать; · Print_debug() – вывести значения переменных; · End_debug() – закончить отладочную печать. Отладчик позволяет задавать номера процессоров, для которых следует выводить отладочные сообщения. В отладочные сообщения автоматически могут включаться номера процессоров. Отладчик поддерживает два режима работы: режим выдачи отладочной информации в виде дампа и режим трассировки, обеспечивающий пошаговое выполнение программы. Разумеется, подобный отладчик не заменит полноценный символьный отладчик, однако его использование, как показывает опыт, позволяет существенно повысить эффективность процесса отладки. Профилировщик. Одной из наиболее важных задач, возникающих при проектировании и создании СУБД, является проблема оптимизации запросов. Наибольшие временные затраты при выполнении запроса в параллельных системах управления базами данных для платформ с кластерной архитектурой приходятся на передачу данных между процессорными узлами и на обмены с дисками. Поэтому для оценки того или иного плана выполнения запроса к БД необходимо знать общий объем данных, вовлекаемых в обмен с дисками и в передачу по линкам. С этой целью в рамках проекта ²Омега² был спроектирован и реализован профилировщик, позволяющий решить эту задачу для многопроцессорной среды МВС-100. Профилировщик имеет следующие основные функции: · Create_tag(int tag) – создать тэг; · Begin_profile(int tag) – начать профилирование по указанному тэгу; · End_profile(int tag) – закончить профилирование по указанному тэгу; · int Link_read(int tag) – выдает количество операций чтения по линкам; · int Link_write(int tag) – выдает количество операций записи по линкам; · int Disk_read(int tag) – выдает количество операций чтения с диска; · int Disk _write(int tag) – выдает количество операций записи на диск. Функция Create_tag( ) создает в таблице профилировщика учетную запись с указанным тэгом. Ключевыми атрибутами записи являются тэг и идентификатор текущей нити управления. Учетная запись, кроме того, содержит поля, в которых будут суммироваться передачи по линкам (сообщения) и обмены с дисками, инициируемые данной нитью управления. Функция Begin_profile( ) обнуляет счетчики сообщений и обменов и включает режим профилирования для указанного тэга. Функция End_profile( ) выключает режим профилирования для указанного тэга. Каждый обмен с диском и каждая передача сообщения, выполняемая некоторой нитью управления [15], увеличивают соответствующие счетчики всех своих профилировочных записей, для которых включен режим профилирования. Тэг по существу является некоторым идентификатором, позволяющим пользователю суммировать результаты профилирования, полученные при выполнении одного запроса на нескольких процессорах. В заключение отметим, что описанные технологии были использованы в рамках рабочей группы ²Омега² для создания прототипа параллельной СУБД для МВС‑100. В ходе выполнения работ была подтверждена высокая эффективность предложенных подходов при коллективной разработке сложных программных систем для МВС-100. Применение описанных подходов позволило повысить производительность труда программиста в среднем на 30%. Предложенная среда разработки позволяет учитывать индивидуальные склонности членов рабочей группы. Она допускает работу на различных программно-аппаратных платформах как в составе локальной сети, так и через Internet. Предложенное расширение среды программирования PGCC путем добавления отладчика и профилировщика позволяет существенно повысить эффективность процесса отладки приложений в многопроцессорной среде и обеспечить возможность профилирования программы с целью оптимизации передачи сообщений по линкам и обменов с дисками. Описанная технология может быть полностью перенесена на МВС‑1000 при минимальных доработках, а технологический цикл и соответствующее программное обеспечение могут быть использованы на МВС‑100/1000 для коллективной разработки больших программных систем различного назначения. Список литературы 1. Сафонов В.О. Языки и методы программирования в системе "Эльбрус". - М.: Наука, 1989. - 392 с. 2. Sokolinsky L., Axenov O., Gutova S. Omega: The Highly Parallel Database System Project // Proceedings of the First East-European Symposium on Advances in Database and Information Systems (ADBIS’97), St.-Petersburg. September 2-5, 1997. Vol. 2. P. 88-90. 3. Zabrodin A.V., Levin V.K., Korneev V.V. "The Massively Parallel Computer System MBC‑100". In: Proceedings of PaCT-95, 1995, pp 342-356 (Lecture Notes in Computer Science, vol. 964). 4. Гольштейн М.Л. Мультипроцессорная вычислительная система на базе транспьютерной идеологии // Алгоритмы и программные средства параллельных вычислений: Сб. науч. тр. - Екатеринбург: УрО РАН, 1995. - C. 61-68. 5. Вельбицкий И.В. Технология программирования. - Киев: Технiка, 1984. - 250 с. 6. Мельников И.А., Раабе А.С., Тамм Б.Г. Инструментарий машинной поддержки цикла жизни программного обеспечения: (Обзор западных средств) // Прикладная информатика. - 1988. - Вып. - 14. - C. 16-40. 7. Соколинский Л.Б. Программная поддержка ТИП-технологии программирования на МВК "Эльбрус" // I Региональн. конф.: Технология программирования, инструментальное и системное программное обеспечение ЭВМ: Тез. докл. -Пермь: ПГУ. - 1989. - C. 32-33. 8. Фуксман А.А. Технологические аспекты создания программных систем. - М.: Статистика. - 1979. - C. 184. 9. Позин Б. А. Современные средства программной инженерии для создания открытых прикладных информационных систем // СУБД. 1995. - № 1. - C. 139-144. 10. Pfister G. Sizing Up Parallel Architectures //DataBase Programming & Design OnLine. May 1998. (http://www.dbpd.com/ 9805feat.html). 11. Flynn M.J., Rudd K.W. Parallel architectures // ACM Computing Surveys. March 1996. Vol. 28. No. 1. P. 67-70. 12. Berliner B. CVS II: Parallelizing Software Development. http://www.hu.freebsd.org/hu/doc/psd/28.cvs/paper.html 13. Wunderling R., Zöckler M. DOC++. A Documentation System for C/C++ and Java. http://www.zib.de/Visual/software/ doc++ 14. PGI Supercompilers and Advanced Development Tools For the Intel i860. http://www.pgroup.com/i860_home.html 15. Соколинский Л.Б. Организация легковесных процессов в параллельной СУБД ²Омега² для МВС-100 // Всерос. науч. конф.: Фундаментальные и прикладные аспекты разработки больших распределенных программных комплексов: Тез. докл. – М.: МГУ. - 1998. - С. 132-138. |
 Во-вторых, для аппаратно независимых частей программной системы, среда Borlan C++ может использоваться также для компилирования, запуска и (что особенно важно) для отладки программ, так как содержит мощный встроенный отладчик, отсутствующий в PGCC (в комплектации МВС‑100).
Во-вторых, для аппаратно независимых частей программной системы, среда Borlan C++ может использоваться также для компилирования, запуска и (что особенно важно) для отладки программ, так как содержит мощный встроенный отладчик, отсутствующий в PGCC (в комплектации МВС‑100).| Permanent link: http://swsys.ru/index.php?id=928&lang=en&page=article |
Print version Full issue in PDF (1.58Mb) |
| The article was published in issue no. № 2, 1999 |
Perhaps, you might be interested in the following articles of similar topics:
- Автоматизированное рабочее место расчета стоимости эксплуатации кораблей
- Основы интеллектуальной информационной технологии обеспечения безопасности производства
- Сравнительная характеристика текстовых редакторов
- Реализация теней с помощью библиотеки OpenGL
- Средства защиты информации в системе АРСОТ
Back to the list of articles