Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Author: () - | |
| Ключевое слово: |
|
| Page views: 17697 |
Print version Full issue in PDF (1.07Mb) |
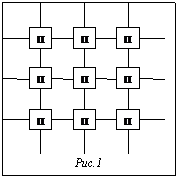
В настоящее время известны два основных способа повышения производительности вычислительных систем (ВС): использование более быстродействующей элементной базы или увеличение числа обрабатывающих информацию устройств (процессоров) в ВС. Поскольку первый путь повышения производительности ВС упирается в технологические, тепловые и иные ограничения, более универсальным представляется второй путь, связанный с увеличением числа процессоров в ВС. Известны и исследованы различные архитектуры построения многопроцессорных ВС (МВС) [1-3], современные высокопроизводительные МВС включают сотни обрабатывающих устройств, создаются проекты МВС, включающих тысячи и десятки тысяч таких устройств [4]. В качестве причин, лимитирующих производительность таких масштабных МВС, чаще всего рассматривают проблемы, связанные с ограничениями на распараллеливаемость алгоритмов реальных задач и сложность координации работы многих обрабатывающих устройств в составе МВС на уровне ОС. Представляется, что по мере роста быстродействия элементной базы в числе причин, ограничивающих производительность МВС, появляются и становятся весьма существенными причины, связанные с задержками распространения сигналов между процессорами. В работе [3] проведен сравнительный анализ двух наиболее распространенных структур МВС: ВС с общей памятью, где запросы процессоров в общую многомодульную память организуются через централизованный коммутатор, и ВС с распределенной памятью, где каждый процессор имеет собственный модуль памяти и модуль коммутации межпроцессорных связей, выполненный на основе транспьютера. Изучалась зависимость производительности МВС от числа используемых процессоров и их быстродействия, объема и быстродействия кэш и оперативной памяти, структуры МВС. Отмечено, что МВС с распределенной памятью, фрагмент структуры которой в варианте «вычислительная плоскость» (каждый процессор Пij соединен с четырьмя ближайшими соседями) приведен на рисунке 1, является более универсальной при наращивании числа процессоров в МВС и для большей части алгоритмов обеспечивает большую скорость роста производительности МВС с ростом числа процессоров.
Предположим, что алгоритм выполнения задания предполагает, что на n операций вычисления в процессоре в среднем приходится одна операция межпроцессорного обмена, требующая выполнения подпрограммы из m операций. Будем считать, что процессор выполнен на основе RISC-микропроцессора, у которого подавляющее большинство операций выполняется за один такт длительностью T0. Тогда фрагмент задания, включающий N операций, выполнение которого может быть распараллелено на k частей, будет выполняться в МВС из k процессоров за время Тf:
где Td – задержка межпроцессорного обмена; (N×T0) – длительность выполнения фрагмента задания; деление на k указывает, что задание распределяется на k процессоров. Приводя выражение для Тf к длительности выполнения одной операции (разделив его на N) и учитывая, что в большинстве практических случаев m много меньше n, имеем:
Значение удельного такта работы МВС T можно рассматривать в качестве показателя длительности выполнения операции в МВС различной размерности k, то есть различающихся по числу используемых процессоров. В зависимости от k различаться будет также длительность задержки межпроцессорного обмена Td . Предположим, что физически МВС располагается на одном плоском конструктиве и один обрабатывающий узел (процессор, кэш, модуль памяти и коммутатор обмена) занимает площадь 100*50 мм, представляя собой набор нескольких микросхем в корпусах. Известна эмпирическая формула, позволяющая оценить среднюю длину связей на печатной плате с корпусами микросхем, где средняя длина связей оценивается как одна треть от полупериметра платы. Оценивая площадь платы пропорционально числу обрабатывающих узлов МВС и считая, что ее форма близка к квадрату, можно получить среднюю длину связи L на конструктиве в виде:
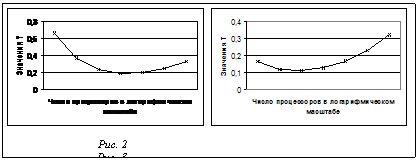
где S – площадь, занимаемая одним обрабатывающим узлом. Можно учесть, что в МВС не каждый обрабатывающий узел связан с каждым. В структуре МВС типа вычислительная плоскость (рис.1) процессор обменивается данными с четырьмя соседними, а значит, средняя длина связи фиксирована и не зависит от k. Однако для того чтобы обеспечить передачу данных в этой структуре, требуется осуществить несколько циклов межпроцессорной связи, а среднее их число вновь будет пропорционально корню квадратному из k. Учитывая, что скорость распространения сигналов в печатных проводниках составляет величину порядка t-10 нс на метр, можно провести некоторые оценки Td в зависимости от k, приняв Td = Lt. На рисунках 2 и 3 представлены зависимости значений удельного такта работы МВС Т (в наносекундах) от числа процессоров k в МВС (k изменяется от 16 до 1024, использована логарифмическая шкала по основанию логарифма 2) для двух значений рабочей частоты процессора (на рис. 2 рабочая частота составляет 100МГц, а на рис. 3 – 500 МГц (n=100). Как следует из результатов, представленных на рисунках 2 и 3, при меньших рабочих частотах оптимальное по быстродействию число процессоров в МВС составляет 128-256 (рис. 2), а при возрастании рабочих частот смещается в область меньшего числа процессоров – 32-64 (рис. 3). Увеличение значения удельного такта T при росте числа процессоров связано с повышением влияния на величину Т возрастающей длительности межпроцессорных обменов Td. В целом приведенные результаты демонстрируют существенную зависимость быстродействия МВС от длительности задержек в межпроцессорных обменах. Конечно, использованная в работе грубая модель компоновки средств МВС на одном конструктиве требует уточнений. Возможно рассматривать конструктив в виде панели, в которую устанавливаются платы расширения с обрабатывающими узлами, либо конструктив на основе многокристальных модулей, однако это не изменит ситуации принципиально, поскольку везде требуется учитывать длительность задержки межпроцессорных обменов. Особенно эти задержки возрастают в случае, когда реализуется алгоритм, требующий большого числа межпроцессорных обменов. Тогда к реализуемому алгоритму уместно применить требование по организации локальных обменов, то есть межпроцессорные обмены должны проводиться между соседними (расположенными на конструктиве рядом друг с другом) процессорами. Предлагаемый подход позволяет создавать методику оценки числа процессоров в МВС по критерию максимального быстродействия. Список литературы 1. Водяхо А.И., Горнец Н.Н., Пузанков Д.В. Высокопроизводительные системы обработки данных. - М.: Высш. шк., 1997. –304с. 2. Головкин Б.А. Вычислительные системы с большим числом процессоров. - М.: Радио и связь, 1995. –318с. 3. Тювин Ю.Д., Коваленко С.М., Савостин Д.И. Выбор структуры многопроцессорной вычислительной системы для реализации мультимедийных приложений / В кн.: Управление и проектирование на базе интеллектуальных технологий. - М., МИРЭА, 1999. 4. Суперкомпьютеры перешагивают планку терафлопсной производительности.//Computer Weekly. - 1998.-№41. - С.3. |
 Однако в указанной работе не ставился вопрос о выборе числа процессоров в МВС по критерию быстродействия с учетом задержек при межпроцессорной передаче данных. Рассмотрим указанную проблему, учитывая, что выполнение любого задания включает затраты времени на вычисления в процессоре и межпроцессорный обмен, а затраты времени на межпроцессорный обмен зависят от длины связи между процессорами и будут увеличиваться по мере того, как увеличивается число процессоров в МВС и физические размеры конструктивов, в которых выполнена МВС.
Однако в указанной работе не ставился вопрос о выборе числа процессоров в МВС по критерию быстродействия с учетом задержек при межпроцессорной передаче данных. Рассмотрим указанную проблему, учитывая, что выполнение любого задания включает затраты времени на вычисления в процессоре и межпроцессорный обмен, а затраты времени на межпроцессорный обмен зависят от длины связи между процессорами и будут увеличиваться по мере того, как увеличивается число процессоров в МВС и физические размеры конструктивов, в которых выполнена МВС.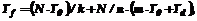
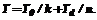
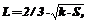
| Permanent link: http://swsys.ru/index.php?id=942&lang=en&page=article |
Print version Full issue in PDF (1.07Mb) |
| The article was published in issue no. № 3, 1999 |
Perhaps, you might be interested in the following articles of similar topics:
- Инженерная программа трехмерного моделирования магнитных систем LittleMag
- Зарубежные базы данных по программным средствам вычислительной техники
- Формулировка задачи планирования линейных и циклических участков кода
- Кросс-система автоматизации разработки программного обеспечения на базе языка высокого уровня Рада
- Интегрированная система «микросреда»
Back to the list of articles