Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Author: () - | |
| Keywords: owl, ontology, , |
|
| Page views: 15918 |
Print version Full issue in PDF (8.40Mb) |
Концепция семантического Web была выдвинута Тимом Бернерс-Ли, одним из основоположников Worl Wide Web и председателем WWW-консорциума (W3C), на международной конференции XML-2000, прошедшей в 2000 г. в Вашингтоне. Основная идея этого проекта заключается в организации такого представления данных в глобальной сети, чтобы допускалась не только их визуализация (как это происходит в формате HTML), но и эффективная автоматическая обработка программами разных производителей. Путем подобных преобразований концепции уже традиционного Web предполагается превращение его в систему семантического уровня. По замыслу создателей, семантический Web должен обеспечить понимание информации компьютерами, выделение ими наиболее подходящих по тем или иным критериям данных и (уже после этого) предоставление информации пользователям. В пользу серьезности научного направления семантического Web говорят поддерживаемые консорциумом W3C стандарты, на которых базируется данная концепция. Кроме того, регулярно издается научный журнал, посвященный вопросам теории и практического применения семантического Web − Web Semantics: Science, Services and Agents on the World Wide Web. В данной работе оцениваются возможности применения технологии семантического Web в интеллектуальных хранилищах данных. Структура семантического Web В статье [1] подводятся итоги шестилетних исследований в области семантического Web и определяются основные перспективные направления. Центральным понятием в данной статье является Semantic Web Mining, включающее в себя семантический Web (Semantic Web) и Web Mining (аналог Data Mining в интеллектуальных системах обработки данных), которое можно перевести на русский язык как интеллектуальный анализ Web-контента. С позиций проводимого исследования будет интересно рассмотреть структуру и содержание понятия семантического Web. Основной целью семантического Web является обеспечение возможности выражения смысла ресурсов, которые могут быть найдены в Интернете [2]. Для достижения этой цели применяются несколько слоев описательных структур (рис. 1). Слои, изображенные на рисунке, выполняют следующие функции: · слой XML (eXtensible Markup Language) представляет структуру данных; · слой RDF (Resource Definition Framework) представляет смысловое описание данных; · слой онтологий (Ontology) служит для представления общепринятых соглашений о смысловом описании структур данных; · логический слой (Logic) позволяет выполнять интеллектуальный вывод; · слой доказательств (Proof) выполняет функцию поддержки взаимодействия между программными агентами на нужном доверительном уровне, обеспечивая понимание того, каким образом была извлечена необходимая информация. В работе [2] подчеркивается, что эффективность применения технологии семантического Web значительно возрастет при увеличении объема машинно-распознаваемого Web-контента и числа программных сервисов, способных обрабатывать данный контекст в автоматическом режиме. Рассмотрим более подробно структуру семантического Web [1]. XML обеспечивает синтаксис для структурированных документов, но не налагает никаких семантических ограничений на содержание этих документов. Для определения структуры документов XML, а также дополнения их конкретными типами данных применяются XML-схемы. RDF может быть представлен как первый слой, где информация становится машинно-понимаемой. В соответствии с рекомендациями консорциума W3C, RDF − основа для формирования метаданных, служащая для обеспечения интероперабельности между приложениями, которые обмениваются информацией в Web.
Рис. 1. Слои архитектуры семантического Web Документы RDF состоят из сущностей трех типов: ресурсы, свойства и утверждения. В качестве ресурсов могут выступать Web-страницы, части или наборы Web-страниц или любые объекты реального мира. В RDF ресурсы всегда адресуются с помощью URI (Uniform Resource Identifier − унифицированный идентификатор ресурсов). Свойствами являются атрибуты, характеристики или отношения, описывающие ресурсы. Ресурс вместе со свойством и соответствующим значением свойства образуют RDF-утверждение. Значением свойства могут быть литерал, ресурс или другое утверждение. Утверждения в документах RDF могут представляться в виде триплета объект–атрибут–значение. Лежащая в основе модель данных RDF может быть представлена ориентированным графом. RDF-схема определяет язык описания классов, отношений между ними и между свойствами, а также ограничений по доменам и диапазонам значений для свойств. Следующий слой – словарь онтологий. Онтология – это «явная формализация разделяемого понимания концептуализации» [1]. Исследователи дают различные определения онтологии, но большинство из них сходятся во мнении, что онтология включает в себя множество концептов (понятий), их иерархию и отношения между ними. Многие исследователи также включают в данное понятие набор аксиом. Разработка языка описания структурированных онтологий OWL стала одним из наиболее важных звеньев работ по семантическому Web, проводимых консорциумом W3C. В конце 2001 г. для этой цели в составе W3C была учреждена специальная рабочая группа. 10 февраля 2004 г. W3C-консорциум присвоил языку OWL статус рекомендованной к реализации технологии. В рамках OWL онтология − это совокупность утверждений, задающих отношения между понятиями и определяющих логические правила для рассуждений о них. Компьютеры могут понимать смысл семантических данных на Web-страницах, следуя по гиперссылкам, ведущим на онтологические ресурсы. Онтология может включать описания классов, свойств и их примеры (индивиды). Формальная семантика OWL описывает, как получить логические выводы на основе онтологий, то есть получить факты, которые не представлены буквально, а следуют из семантики онтологии. Эти выводы могут базироваться на анализе одного документа или множества до- кументов, распределенных в сети. Последнее обеспечивается возможностью онтологий быть связанными, включая прямой импорт информации из других онтологий. Чтобы написать онтологию, которая может однозначно интерпретироваться и использоваться программными агентами, за- действуются синтаксис и формальная семан- тика OWL. В настоящее время не существует единственно правильного формального представления структуры онтологии. Рассмотрим представление, которое было сформировано в рамках проекта Karlsruhe Ontology framework (KAON) [1]. Определение 1. Ядро онтологии с аксиомами есть структура · двух непересекающихся множеств C и R, элементы которых – идентификаторы понятий и идентификаторы отношений соответственно; · частичного порядка · функции · частичного порядка · множества A логических аксиом. Следующий слой, логический, позволяет, используя множество аксиом, выводить новое знание из информации, заданной в явном виде. Слой доказательств должен обеспечить проверку степени достоверности утверждений, выведенных в семантическом Web. В настоящее время исследования в данном направлении только начинаются. Семантический Web в интеллектуальных хранилищах данных Применение технологии семантического Web не ограничивается только анализом содержимого Web-страниц, и более точный поиск информационных ресурсов в Internet − не единственная ее цель. В подтверждение этого авторы обзорной работы [1] определяют смежные области исследований и приложений. Одной из множества таких областей можно назвать базы данных. В последние годы во многие коммерческие СУБД была включена функция сохранения XML-данных. Фактически это было выполнено для обеспечения возможности работы со слабоструктурированной информацией. Множество проблем в области баз данных может найти свое решение с помощью онтологического инжиниринга, например, проблемы, связанные с интеграцией гетерогенных, распределенных источников данных. Технология хранилищ данных предназначена для сбора и консолидации данных из разрозненных и несогласованных источников в согласованный предметно-ориентированный, интегрированный и зависимый от времени набор данных [3]. Определение 2. Под интеллектуальным хранилищем данных будем понимать хранилище, удовлетворяющее следующим требованиям: 1) сбор и консолидация данных из разрозненных источников должны выполняться системой автоматически; 2) обобщенное описание информационных ресурсов должно соответствовать контексту принятия решений; 3) должна обеспечиваться семантическая однородность запроса и ответа (выдаваемые ответы на запросы должны соответствовать тому контексту, в котором были сформулированы данные запросы); 4) формируемые хранилищем данных ответы на запросы должны основываться на информации, не только явно представленной в хранилище, но и на логически выводимой из имеющегося набора данных и знаний предметной области принятия решений; 5) должна обеспечиваться возможность хранения и поиска информации с учетом неполноты. Рассмотрим возможности семантического Web с точки зрения перечисленных требований. Выполнение первого требования может быть связано с применением так называемых слабосвязанных информационных систем, то есть таких, в которых некоторую часть можно изменять, не затрагивая остальные [4]. Одной из архитектур, позволяющих строить такие слабосвязанные системы, является сервис-ориентированная архитектура, базирующаяся на стеке стандартов WSDL, SOAP, XML и UDDI. Все это дает возможность обеспечить техническую интероперабельность компонентов интеллектуального хранилища данных [5], которая означает их совместимость на техническом уровне, включая протоколы передачи данных и форматы их представления (слой XML-архитектуры семантического Web). Для обеспечения же семантической интероперабельности должно быть определено семантически однородное терминологическое пространство для всех компонентов, входящих в интеллектуальное хранилище данных. Такое пространство может быть определено в виде онтологии и представлено с использованием языка OWL (слои RDF+RDFS и Ontology Vocabulary).
Рис. 2. Уровни представления информации Как правило, принятие решений происходит на основе некоторой агрегированной, или обобщенной, информации относительно исходных данных. В хранилищах данных такой информационный уровень может быть представлен в виде классификационных схем, по которым происходят навигация и поиск информационных ресурсов. Выполнение второго требования связано с выполнением функций автоматического формирования классификационной схемы информационных ресурсов и ее адаптации к изменениям структуры понятий предметной области (онтологии) во времени. При этом онтология представляет контекст принятия решений (рис. 2). Таким образом, при формировании классификационной схемы Выполнение третьего требования предполагает решение проблемы сопоставления различных словесных форм одних и тех же понятий, а также проблемы сопоставления одинаковых словесных форм различных понятий. В рамках применения концепции семантического Web требование семантической однородности может быть выполнено с использованием возможности связывания информации из различных источников (свойство выражения эквивалентности owl:sameAs и свойство связывания информационных ресурсов вместе owl:InverseFunctionalProperty). Дополнительно может быть использована возможность языка OWL импортировать утверждения из одной онтологии в другую. Выполнение четвертого требования к интеллектуальным хранилищам данных основывается на использовании механизмов логического вывода (слой Logic архитектуры семантического Web). Формальная семантика OWL описывает метод получения логических следствий, то есть фактов, которые не представлены в онтологии буквально, но следуют из ее семантики. Наконец, выполнение пятого требования никоим образом напрямую не связано с особен- ностями технологии семантического Web. Для реализации данного требования необходимо привлекать соответствующие модели и методы обработки информации (нечеткие множества Заде, грубые множества Павлака и др.). В данной статье показана возможность применения концепции семантического Web при построении интеллектуальных хранилищ данных. Однако, чтобы слияние указанных технологий было эффективным, необходимо решить следующие задачи: построение модели сопоставления разных онтологий предметной области, соответствующих различным контекстам принятия решений; построение модели управляемой кластеризации, позволяющей сформировать обобщенное описание информационных ресурсов, соответствующее контексту принятия решений; построение модели обратной связи «информационные ресурсы→контекст принятия решений»; исследование неполноты описания информационных ресурсов на всех уровнях – от данных до онтологии. Список литературы 1. Stumme G., Hotho A., Berendt B. Semantic Web Mining. State of the art and future directions. Web Semantics: Science, Services and Agents on the World Wide Web, № 4, 2006, pp. 124–143. 2. Stojanovic L. at al. The role of ontologies in autonomic computing systems. IBM Systems Journal Vol. 43, № 3, 2004, pp. 598–616. 3. Инмон Б. DW 2.0: хранилища данных следующего поколения. // Там же. – № 5. – 2007. 4. Черняк Л. Поход за Чашей Грааля информационных технологий. // Открытые системы. – № 1. – 2006. 5. Фейгин Д. Концепция SOA. // Там же. – № 6. – 2004. |

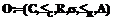 , состоящая из:
, состоящая из: на C, называемого иерархией понятий, или таксономией;
на C, называемого иерархией понятий, или таксономией; , называемой сигнатурой;
, называемой сигнатурой; на R, называемого иерархией отношений;
на R, называемого иерархией отношений;
 следует принимать во внимание состояние не только набора данных
следует принимать во внимание состояние не только набора данных 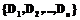 , но и онтологии предметной области
, но и онтологии предметной области  во время t. Язык описания онтологий OWL содержит элементы контроля версионности (свойство owl:priorVersion, owl:backwardCompatibleWith и др.), которые могут использоваться для реализации второго требования к интеллектуальным хранилищам данных.
во время t. Язык описания онтологий OWL содержит элементы контроля версионности (свойство owl:priorVersion, owl:backwardCompatibleWith и др.), которые могут использоваться для реализации второго требования к интеллектуальным хранилищам данных.| Permanent link: http://swsys.ru/index.php?id=1615&lang=en&page=article |
Print version Full issue in PDF (8.40Mb) |
| The article was published in issue no. № 4, 2008 |
Perhaps, you might be interested in the following articles of similar topics:
- Применение онтологий в задачах эксплуатации кораблей
- Спецификации как онтологии
- Информационная поддержка распределенной разработки программного обеспечения на основе онтологии
- Основные этапы создания интеллектуальных обучающих систем
- Построение онтологии на основе нереляционной базы данных для интеллектуальной системы поддержки принятия решений медицинского назначения
Back to the list of articles