Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: Vagin V.N. (vagin@appmat.ru) - National Research University “MPEI”, Moscow, Russia, Ph.D, () - | |
| Keywords: decision support system, , diagnostics, q-learning, , , multi-agent system |
|
| Page views: 12897 |
Print version Full issue in PDF (4.72Mb) |
Водо-водяные энергетические реакторы (ВВЭР) являются самым распространенным типом реакторов в России. Атомная станция, использующая ВВЭР, имеет два контура. Для предотвращения различных аварийных ситуаций в первом контуре атомной станции используется подсистема компенсации объема (давления). Она предназначена для компенсации температурных изменений объема воды, заполняющей первый контур. Подсистема содержит большое количество контролируемых параметров и продукционных правил, регламентирующих ее работу. Значительный объем анализируемых данных требует немалого времени для их ручной обработки и принятия решения в сложившейся ситуации. Этим и обусловлена необходимость использования автоматизированной системы поддержки принятия решений, предназначенной для формирования отчетов о функционировании подсистемы компенсации объема и рекомендаций по управлению подсистемой для оператора атомной станции. В основе таких систем могут лежать различные методы обработки информации [1], в частности, мультиагентный подход, базирующийся на методе подкрепленного обучения агентов. Мультиагентная технология и методы подкрепленного обучения
Архитектура мультиагентной системы (МАС) представлена на рисунке 1. В результате работы системы для оператора атомной станции будет построена последовательность действий в виде гипертекстовой информации. Разработанная МАС взаимодействует с динамическими входными данными, поступающими от подсистемы диагностики. Для обеспечения адаптивности процедуры принятия решений к условиям среды необходимо разработать механизмы, позволяющие МАС обучаться и в дальнейшем использовать успешный опыт формирования управляющих воздействий. В качестве базового принципа обучения был взят метод подкрепленного обучения. Для повышения эффективности этого метода разработана модификация метода Q-обучения, позволяющая существенно сократить количество анализируемых вершин дерева решений. Подкрепленное обучение представляет класс задач, в которых автономный агент, действуя в определенной среде, должен найти оптимальную стратегию взаимодействия с ней. Информация для обучения агента предоставляется в форме «награды», имеющей определенное количественное значение для каждого перехода среды из одного состояния в другое. Задача агента сводится к максимизации суммарного платежа. Базовая модель подкрепленного обучения предполагает, что мир представляется набором состояний S, что агент может выполнять фиксированный набор действий A, и после выполнения действия в заданном состоянии среда предоставляет агенту выплату R:S´A®Â, отражающую целесообразность выполнения действия. Агент делает наблюдения своих взаимодействий с миром в форме кортежей (st, at, rt+1, st+1). Они соответствуют состоянию среды st, выбранному агентом действию at, наблюдаемой выплате rt+1 и результирующему состоянию агента st+1. При взаимодействии со средой агент поль- зуется внутренней стратегией, которая со временем может изменяться и адаптироваться, чтобы в конечном итоге для любого временного промежутка максимизировать так называемый возврат среды, получаемый агентом с текущего момен- та [3, 4]:
Алгоритм функционирования МАС Входными данными для алгоритма являются показания датчиков подсистемы диагностики КО ВВЭР. Алгоритм функционирования разработанной МАС включает следующие основные этапы. 1. МАС считывает значения показаний различных групп датчиков подсистемы компенсации объема ВВЭР. Они проходят первичную обработку агентами наблюдения и диагностики и передаются на следующий уровень МАС. 2. Агенты-координаторы нижнего уровня осуществляют верификацию поступивших данных для каждой группы параметров. Например, группа датчиков, отражающих значение температуры КО, анализируется соответствующим агентом-координатором на согласованность. В случае выявления им рассогласования в показаниях датчиков делаются повторный запрос значений параметров, выбивающихся из общей картины, и анализ кодов ошибок соответствующих датчиков. Также агенты-координаторы нижнего уровня формируют фрагмент левой части правил управления КО ВВЭР, которые впоследствии будут сохранены в базе правил. Затем формирование правил продолжает центральный агент-координатор. 3. Центральный агент-координатор выполняет поиск в базе правила с идентичным фрагментом левой части. Если такое правило найдено, агент извлекает его и передает на исполнение агентам-координаторам нижнего уровня. В противном случае агент выбирает правило с наиболее близким значением фрагмента левой части и использует его в качестве отправной точки при формировании искомого правила. Общий вид правил следующий: &(A=a)&(I=i)®(Pm=pm), (2) где D – набор исходных данных, составленный как конъюнкция простых условий вида <идентификатор измерительного прибора>=<показания прибора>; A=a – конкретное управляющее воздействие; I=i – заданная в правиле интенсивность воздействия; Pm=pm – конкретная получаемая выплата. 3.1. Для формирования нового правила центральный агент-координатор взаимодействует с моделью виртуального КО (рис. 2), чтобы отыскать наиболее удачную последовательность действий, приводящую систему в стабильное состояние, при котором все параметры находятся в допустимых коридорах верхних и нижних уставок. Исходными данными задачи являются показания различных датчиков подсистемы компенсации объема. Центральный агент-координатор располагает набором действий, которые следует выполнять в конкретных ситуациях: при увеличении или уменьшении температуры тэнов в резервуаре компенсации объема, расхода воды, поступающей в КО, расхода отводимого пара из КО. Каждое действие может быть выполнено с различной интенсивностью, имеющей числовое отражение на отрезок от 0 до 100. 3.2. Центральный агент-координатор использует найденное правило с наиболее близким к данной ситуации значением фрагмента левой части правила и выполняет указанные в нем действия применительно к виртуальной модели КО с заданной интенсивностью. 3.3. Виртуальный КО переходит в новое состояние. 3.4. Выполняется построение оценки исходного и полученного состояний системы. 3.5. Если новое состояние ближе к стабильному, чем исходное, модель виртуального КО возвращает положительную выплату центральному агенту-координатору. Иначе агент получает отрицательную выплату. 3.6. Если центральным агентом-координатором получена положительная выплата, он пробует применить то же действие с большей или меньшей интенсивностью, чтобы привести виртуальный КО в еще более стабильное состояние, а также увеличить получаемую выплату. В противном случае агент пробует применить другое действие. 3.7. Действия 3.1–3.6 повторяются, пока агент не найдет оптимальную пару (действие, интенсивность), при использовании которой в заданной ситуации им будет получена максимальная выплата. 3.8. Найденное действие, его интенсивность и полученная в случае его применения выплата объединяются с фрагментом левой части правила (исходными параметрами). Так создается новое правило управления КО ВВЭР, которое сохраняется в базе правил. Построенное правило передается на нижестоящий уровень МАС агентам-координаторам нижнего уровня. 4. Агенты-координаторы нижнего уровня формируют рекомендации по стабилизации состояния КО для оператора атомной станции. Если оператор не принимает никаких действий в течение определенного интервала времени, агент-координатор нижнего уровня передает выбранное действие с заданной интенсивностью на выполнение агентам нижнего уровня. Выходными данными алгоритма являются сформированные рекомендации управляющих воздействий, а также сформированные правила управления КО. Данный алгоритм позволит автоматизировать процесс описания правил работы контролируемого объекта. Эти правила формируются МАС с помощью методов подкрепленного обучения, что позволяет перейти от построения продукционных правил на основе экспертных знаний к динамическому описанию контролируемого объекта. Возможная неполнота описания предметной области может быть восполнена с помощью методов подкрепленного обучения. Использование методов подкрепленного обучения в МАС Рассмотрим алгоритм работы модели виртуального КО, реализующего метод подкрепленного обучения МАС. Модель виртуального КО состоит из блоков (рис. 2). Работа модели заключается в следующем. Блок восприятия текущего состояния системы принимает значения контролируемых параметров, сохраняет их и передает блоку построения оценки, а также блоку формирования нового состояния системы. Блок формирования нового состояния системы принимает данные значения и управляющее воздействие от МАС. Затем выполняется построение нового состояния системы (D1) на основе исходного (D0), характеризующегося значениями контролируемых параметров, и правил поведения КО, изначально заложенных экспертами в его базу правил. Они классифицированы в зависимости от получаемого управляющего воздействия (A), выбранного МАС, а именно: увеличение (уменьшение) температуры тэнов в резервуаре компенсации объема, расхода воды, поступающей в КО, расхода отводимого пара из КО. Например, в случае выбора МАС действия «увеличение температуры тэнов в резервуаре компенсации объема» виртуальный КО изменит новое состояние (D1) следующим образом: будут увеличены (уменьшены) значение температуры воды и значение давления в зависимости от степени интенсивности воздействия (I). Формально данные утверждения i-го датчика температуры воды и j-го датчика давления будут иметь вид: D1,Tw,i=D0,Tw,i+(DmaxTw,i–DminTw,i)*I/100, D1,P,j=D0,P,j+0.5*(DmaxP,j–DminP,j)*I/100, (3) где D0,Tw,i – исходные показания i-го датчика; D1,Tw,i – сформированные показания i-го датчика; DmaxTw,i – значение верхней уставки i-го датчика; DminTw,i – значение нижней уставки i-го датчика; D0,P,j – исходные показания j-го датчика; D1,P,j – сформированные показания j-го датчика; DmaxP,j – значение верхней уставки j-го датчика; DminP,j – значение нижней уставки j-го датчика; 1≤i≤nTw, 1≤j≤nP, nTw – количество датчиков температуры воды; nP – количество датчиков давления; I – интенсивность действия. В результате виртуальным КО будет сформировано новое состояние системы D1, характеризующееся измененными значениями контролируемых параметров, которое наступит, если к КО применить действие (A) с интенсивностью (I). Рассмотренные правила, определяющие поведение виртуального КО, заключаются в изменении характеристик системы в соответствии с действием и его интенсивностью относительно значений верхних и нижних уставок анализируемой характеристики. При этом отправной точкой для формирования нового значения рассматриваемой характеристики является текущее значение выбранного показателя. Полученное состояние передается блоку построения оценки для оценки исходного и нового состояний системы. Для построения каждой оценки блок использует механизмы, позволяющие провести комплексный анализ всех параметров подсистемы компенсации объема. Построение оценки осуществляется в три этапа. Вначале показания каждого датчика системы передаются в соответствующую ему оценочную функцию. В общем виде оценочная функция описывается следующей формулой:
где x – текущее значение контролируемой переменной; M – середина коридора верхней и нижней уставок; Sigma – величина, характеризующая интервал, на котором построенная функция положительна [6]. На основе этого строятся функции, характеризующие оценки для каждого из контролируемых параметров, опираясь на значения их верхних и нижних уставок, при этом M выбирается как середина данного интервала, а Sigma определяется с тем расчетом, чтобы в граничных точках интервала функция равнялась нулю. Данная оценочная функция возвращает максимальную оценку в случае попадания значения параметра в середину интервала нижних и верхних уставок каждого датчика подсистемы диагностики. Если значения контролируемого параметра находятся внутри коридора нижних и верхних уставок, функция положительна, в противном случае – отрицательна. По сути данная функция представляет оценку качества показаний датчика: чем ближе показания к середине коридора уставок, тем выше оценка. После вычисления оценки каждого датчика вычисляется средняя оценка каждой подсистемы датчиков (диагностики давления, уровня воды, температуры воды и пара). Например, средняя оценка подсистемы диагностики температуры воды имеет вид: qТ(T1, T2, T3, T4)=(qТ1(T1)+qТ2(T2)+ +qТ3(T3)+qТ4(T4))/4, где T1, T2, T3, T4 – датчики температуры. Далее вычисляется интегральная функция оценки как среднее арифметическое оценок всех подсистем датчиков. Аналогично вычисляется оценка полученного состояния системы. В результате работы данного блока будут сформированы оценки исходного и построенного состояний. Оценки передаются блоку формирования выплаты, который возвращает МАС выплату, соответствующую выбранному для нее действию. Выплата вычисляется как половина разности оценки построенного и начального состояний системы. Полученная величина передается агенту-координатору. Результатом работы модели является выплата, на основе значения которой агент формирует заключение о правильности выбранного им действия и его интенсивности в рассматриваемом начальном состоянии. Модификация алгоритма Q-обучения в задаче диагностики КО ВВЭР Разработана модификация метода Q-обучения, позволяющая сократить количество анализируемых вершин на каждом шаге построения дерева. Модификация основана на анализе выплаты, получаемой при построении каждого узла дерева, и анализе оценки состояния модели виртуального КО в данном узле дерева. Отбор вершин заключается в том, что на следующем шаге построения дерева в рассмотрении участвуют только вершины, имеющие положительные выплаты и максимальные оценки состояний. На каждом этапе построения уровня дерева решений применяемые агентом действия (A) и их интенсивности (I) разбиваются на классы. К первому классу относятся пары (A, I), при использовании которых агентом была получена положительная выплата. Обозначим такой класс действий Si+, i – иерархический индекс вершины, к которому применяются действия данного класса. Ко второму классу действий относятся пары (A, I), при использовании которых была получена отрицательная выплата. Обозначим это множество действий Si–. Также вводятся соответствующие множества SVi+ и SVi–, содержащие вершины, которые были получены в результате применения действий из Si+ и Si– соответственно. Исходным для алгоритма является начальное состояние контролируемого объекта, представленное массивом показаний датчиков. 1. Рассмотрение начинается с корневой вершины, которая содержит исходное состояние контролируемого объекта. 2. Инициализация переменной k, предназначенной для хранения уровня рассматриваемой вершины, значением 0 (то есть k=0) означает, что рассматривается корневая вершина. 3. Изначально принимаем, что S0+ содержит все возможные пары (A, I), при этом квант выбора интенсивности равен десяти. S0– является пустым множеством. 4. Затем в цикле будут повторяться пункты 5–12 до тех пор, пока не выполнятся условия из пункта 11. Начало цикла. 5. Переход к следующему уровню вершин дерева решений k=k+1. 6. При построении вершин k+1 уровня в рассмотрении будут участвовать только вершины из класса SV0,i1,i2,…,ik+, где 0, i1, i2, …, ik – индексы вершин, находящихся на выбранной ветви дере- ва решений, при этом ik – индекс вершины k-го уровня дерева, на котором формируется разбиение на классы вершин. Рассматриваются только вершины из класса SV0,i1,i2,…,ik+, так как в дан- ных узлах агентом получена положительная вы- плата. К вершинам из SV0,i1,i2,…,ik+ применяются действия и интенсивности из S0,i1,i2,…,ik+. 7. Если они вновь приведут к положительным выплатам, действия из S0,i1,i2,…,ik– применяться не будут. 8. Если выплаты отрицательные, будут применены действия из S0,i1,i2,…,ik– к вершинам SV0,i1,i2,…,ik+. 9. Таким образом, для каждой вершины уровня k+1 формируются свои классы действий (S0,i1,i2,…,ik,ik+1+ и S0,i1,i2,…,ik,ik+1–), с помощью которых будут получены классы вершин следующего уровня в результате применения действий к вершинам из SV0,i1,i2,…,ik+1+. В каждой новой вершине дерева вычисляются оценки всех контролируемых параметров по формулам, общий вид которых представлен зависимостью (4). 10. Вычисляется суммарная выплата согласно формуле (1) для всей ветви с учетом коэффициента γk, где k – номер уровня дерева. 11. Построение уровней дерева продолжается до тех пор, пока хотя бы по одной из ветвей дерева не будет достигнуто стабильное состояние диагностируемого объекта. 12. Стабильное состояние предусматривает возврат всех контролируемых параметров в их коридоры верхних и нижних уставок. Это означает, что все функции оценок для соответствующих контролируемых параметров в данной вершине положительны. Конец цикла. 13. В качестве результата из множества вершин со всеми положительными оценками контролируемых параметров выбирается последовательность действий и их интенсивностей, которая привела к максимальной суммарной выплате. В итоге алгоритм возвращает последовательность действий, приведшую к максимальной суммарной выплате. Применение когнитивной графики в задаче диагностики КО Для решения задачи диагностики КО ВВЭР также применяется когнитивная графика. В этом случае система поддержки принятия решений содержит когнитивный образ, отражающий состояние контролируемого объекта [7]. Основным назначением образа является представление большого количества наблюдаемых параметров задачи в виде нескольких контролируемых характеристик, по которым операторы атомной станции смогут быстро понять состояние системы и сформировать управляющие воздействия для восстановления баланса контролируемого объекта. Для повышения эффективности работы системы была создана формальная модель представления когнитивных образов. Формальное представление контролируемого объекта с точки зрения диагностирующей системы имеет вид: O=(P1, P2, … , PM), где O – контролируемый объект; Pi – параметр диагностической системы, установленной для контроля объекта. Формальное определение когнитивного образа в этом случае выглядит как CI=(X1, X2, … , XN, Sh), где CI – когнитивный образ; Sh – шаблон когнитивного образа в целом; Xi – обобщенная контролируемая характеристика. Описание когнитивного образа с помощью построенной формальной модели позволяет наглядно представлять поведение контролируемого объекта и дает возможность отслеживать ход решения поставленной задачи не только на когнитивном образе, но и на его формальном представлении. В работе рассмотрена архитектура МАС для диагностики КО ВВЭР и представлена модель виртуального КО для реализации методов подкрепленного обучения МАС. Разработанный метод позволяет построить оптимальную стратегию действий для управления подсистемой компенсации объема ВВЭР. Использование виртуальной модели КО обеспечивает организацию обучения МАС на основе методов подкрепленного обучения. В качестве метода подкрепленного обучения выбрана разработанная модификация метода Q-обучения, которая позволяет существенно сократить количество анализируемых вершин дерева решений. В результате работы указанного метода будет подготовлена справка для оператора атомной станции, содержащая анализ текущей ситуации на контролируемом объекте и рекомендации по поддержанию штатной ситуации. Литература 1. Башмаков А.И., Башмаков И.А. Интеллектуальные информационные технологии. М.: Изд-во МГТУ им. Н.Э. Баумана, 2005. 304 с. 2. Рассел С., Норвиг П. Искусственный интеллект: современный подход; пер. с англ. М.: Издат. дом «Вильямс», 2006. 1408 с. 3. Sutton Richard S., Andrew G. Barto. Reinforcement Learning: an Introduction: MIT Press. Cambridge, a Bradford Book. MA. London, England. 1998. 4. Reinforcement Learning FAQ: Frequently Asked Questions about Reinforcement Learning. URL: http://www.cs.ualberta.ca/ ~sutton/RL-FAQ.html (дата обращения: 15.12.2008). 5. Peters Jan, Sethu Vijayakumar, Stefan Schaal. Reinforcement Learning for Humanoid Robotics. IEEE-RAS International Conference on Humanoid Robots. 2003. URL: http://www-clmc.usc.edu/publications/p/peters-ICHR2003.pdf (дата обращения: 16.12.2008). 6. Теория вероятностей и математическая статистика / А.И. Кибзун [и др.]. М.: Физматлит, 2002. 224 с. 7. Поспелов Д.А. Прикладная семиотика и искусственный интеллект // Программные продукты и системы. 1996. № 3. С. 10–13. |
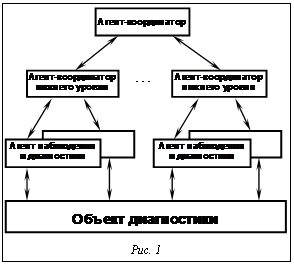 Диагностика компенсатора объема (КО) ВВЭР осуществляется путем анализа контролируемых параметров, таких как температура, давление рабочего тела, уровень воды в КО. Если значения этих параметров попадают в коридор верхних и нижних уставок, состояние КО считается стабильным. В основе разработанной системы поддержки принятия решений лежит использование мультиагентной технологии [2].
Диагностика компенсатора объема (КО) ВВЭР осуществляется путем анализа контролируемых параметров, таких как температура, давление рабочего тела, уровень воды в КО. Если значения этих параметров попадают в коридор верхних и нижних уставок, состояние КО считается стабильным. В основе разработанной системы поддержки принятия решений лежит использование мультиагентной технологии [2]. , / (1)
, / (1) где γ – временной множитель скидки (константа между 0 и 1); ri – выплата на i-м шаге; n=1, 2, …, k – количество ярусов в дереве решений. Множитель скидки отображает, сколько внимания уделяется выплатам, получаемым в данной ситуации. Поскольку процесс принятия решений может быть вероятностным, задача агента – найти стратегию, максимизирующую ожидаемый возврат. Временной множитель скидки отображает, сколько внимания уделяется выплатам, получаемым в данной ситуации. Этот множитель позволяет контролировать глубину поиска решения [5]. Один из самых простых и популярных подходов к решению задач подкрепленного обучения заключается в нахождении и поддержании оценочной функции состояний и действий, которая приближает ожидаемый возврат для текущего состояния после выполнения каждого из действий. Как только оценочная функция получена, определяемая для нее стратегия получается простым выбором действия с максимальной оценкой для данного состояния.
где γ – временной множитель скидки (константа между 0 и 1); ri – выплата на i-м шаге; n=1, 2, …, k – количество ярусов в дереве решений. Множитель скидки отображает, сколько внимания уделяется выплатам, получаемым в данной ситуации. Поскольку процесс принятия решений может быть вероятностным, задача агента – найти стратегию, максимизирующую ожидаемый возврат. Временной множитель скидки отображает, сколько внимания уделяется выплатам, получаемым в данной ситуации. Этот множитель позволяет контролировать глубину поиска решения [5]. Один из самых простых и популярных подходов к решению задач подкрепленного обучения заключается в нахождении и поддержании оценочной функции состояний и действий, которая приближает ожидаемый возврат для текущего состояния после выполнения каждого из действий. Как только оценочная функция получена, определяемая для нее стратегия получается простым выбором действия с максимальной оценкой для данного состояния. , (4)
, (4)| Permanent link: http://swsys.ru/index.php?id=2260&lang=en&page=article |
Print version Full issue in PDF (4.72Mb) |
| The article was published in issue no. № 2, 2009 |
Perhaps, you might be interested in the following articles of similar topics:
- Система поддержки принятия решений в задачах группового выбора
- Общие принципы системной оптимизации технологии контроля качества телерадиопродукции
- Интеллектуальная информационная система для решения задач прогнозирования неисправностей вагонного оборудования на железнодорожном транспорте
- Методика и алгоритмы классификации воздушных объектов системой поддержки принятия решений
- Нечеткая многокритериальная система поддержки принятия решений DecernsFMCDA
Back to the list of articles