Journal influence
Bookmark
Next issue
Unsupervised shopping query segmentation
The article was published in issue no. № 3, 2010Abstract:We describe results of experiments with an unsupervised framework for query segmentation, transforming keyword queries into structured queries which could be used to more accurately search product databases, potentially improve ranking result and query suggestion. The main contribution of our work is an improving method to automatically acquire training data.
Аннотация:Основным результатом данной работы является автоматический алгоритм для сегментации запросов пользователей, который трансформирует запрос с ключевыми словами в структурированный запрос. Получаемые сегментируемые запросы могут использоваться для совершенствования поисковой базы продуктов, улучшения качества ранжирования и предложения новых поисковых запросов. Результаты экспериментов доказывают высокую эффективность разработанной методики.
| Author: (julianakiseleva@gmail.com) - | |
| Keywords: structured queries, attribute extraction from text, query segmentation |
|
| Page views: 13297 |
Print version Full issue in PDF (5.84Mb) Download the cover in PDF (1.43Мб) |
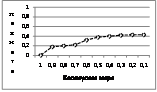
Данная статья посвящена сегментации запросов, потенциально улучшающей качество поиска. Предложенный алгоритм в отличие от описанного в [1] и [2] позволяет создавать обучающее множество абсолютно автоматически. Основная идея сегментации состоит в том, чтобы автоматически и точно для каждого слова из запроса определить соответствующий ему атрибут. Например, sony® ®бренд, vaio®модель, где бренд и модель – это атрибуты. Для автоматического составления обучающего множества используется журнал щелчков пользователей и БД продуктов. На основе похожести слов из запроса и набора слов, которые описывают каждый атрибут в БД продуктов, выбирается наиболее релевантный атрибут для слова. Затем полученное множество размеченных запросов используется для обучения вероятностной модели для сегментации [3]. Результатом данной разработки является метод сегментации запросов, обученный на основе автоматически созданного входного множества. Для оценки результата экспериментов в работе используются следующие основные метрики: точность – отношение числа найденных релевантных документов к общему числу найденных документов в базе; полнота – отношение числа найденных релевантных документов к общему числу релевантных документов в базе. Разработанная система, реализующая алгоритм сегментации, показала, что предложенный алгоритм дает более высокие значения указанных выше метрик по сравнению с полученными ранее результатами, описанными в [1]. Описание системы Эксперименты проводились на основе данных англоязычного интернет-магазина, собранных в течение сентября 2009 года. Рассматривались только запросы на продукты, относящиеся к категории «Компьютеры». Разработанная система состоит из трех алгоритмических составляющих: − автоматическая разметка запросов; − обучение алгоритма сегментации; − применение результатов сегментации к новым запросам. Описываемый улучшенный автоматический метод имеет ряд преимуществ в сравнении с контролируемым и полуконтролируемым методами, применяемыми ранее в работах [1], [4]: · не требует трудозатратного составления обучающего множества вручную, которое часто бывает неточным из-за человеческого фактора; · легко адаптируется к любым изменениям в описании продуктов БД; · для каждого предсказания возвращает меру, которая отражает то, насколько точен полученный результат (в статье эта метрика определяется как степень доверия и принимает значения в диапазоне от 0 до 1; ее можно использовать для получения более точного результата путем фильтрации результатов в зависимости от значения степени доверия). Автоматическая разметка запросов Рассмотрим следующую схему разметки: покупатели вводят запросы в поисковую систему магазинов, например, dell inspiron 15 250gb, sony vaio и другие, затем выбирают продукты, которые кажутся им релевантными их запросу. Все продукты из БД имеют название и описание, состоящее из набора структурированных атрибутов, каждый из которых представлен в виде пары имя атрибута – значение атрибута. Например, название продукта: dell inspiron 2.0ghz intel core duo notebook‟; описание продукта: имя атрибута: тип – значение атрибута Notebook‟; имя: модель – значение: Vaio‟; имя: бренд – значение: Sony‟; имя: скорость процессора – значение: ‟2.0ghz‟ и др. Предполагается, что пользователь выбирает самый релевантный продукт. Это предположение является основополагающим для получения обучающего множества автоматически, используя косинусную меру близости между каждым словом запроса и описанием атрибута продукта, который выбрал покупатель. В качестве размерности пространства используется количество всех уникальных слов в описании атрибута из базы. Для определения веса слова используется модифицированный tfidf (TF – term frequency, IDF – inverse document frequency). Данная инновация состоит в представлении документа как объединение всех слов, описывающих один атрибут, то есть в качестве TF используется частота слова в конкретном описании атрибута для определенного продукта, а IDF=log Обучение алгоритма сегментации Основной целью является обучить алгоритм, сегментирующий пользовательские запросы, с помощью автоматически полученного обучающего множества, как описано выше. То есть каждому слову из запроса должен быть присвоен один, наиболее вероятный атрибут из БД. Модель. В качестве вероятностной модели предсказания используется Conditional Random Field (CRF) model [3, 5]. CRF был обучен отдельно для пяти подкатегорий категории «Компьютеры», таких как «Ноутбуки», «Принтеры», «Карты памяти», «Программное обеспечение» и «Аксессуары для ноутбуков». Обучены отдельно CRF-модели для разных 5 подкатегорий. Атрибуты. Алгоритм предсказывает атрибуты для слов из объединения всех атрибутов, полученных автоматически, то есть для всех атрибутов из базы, которые попали в обучающее множество. Входные параметры для CRF. В качестве входных данных для CRF используются запросы из обучающего множества, в которых для каждого слова определены следующие признаки: · юниграммы – буквы, из которых состоит слово, например, для слова sony юниграммы s, o, n, y; · биграммы – сочетание двух букв из слова, например, для слова dell биграммы de, el, ll; · регулярные выражения, которые определяют тип слова, например, vaio‟ – это слово, 15.4‟ – число, 250gb‟ – смешанное слово; · контекстная информация: предыдущее и следующие слова. Алгоритм сегментации предсказывает атрибут с определенным уровнем доверия. Уровень доверия – это коэффициент, принадлежащий отрезку [0, 1] и отражающий уверенность алгоритма в данном предсказании. Оценка экспериментов Для дальнейшей оценки экспериментов случайным образом были выбраны 100 запросов из всего пользовательского журнала, которые имеют длину больше одного и меньше шести слов. Данная выборка была размечена асессорами вручную и использовалась для расчета точности и полноты алгоритма автоматической разметки запросов и алгоритма сегментации. Для определения порога косинуса, при котором мы получаем наиболее точные результаты, выполняем следующие действия: · сначала отбираем запросы, в которых каждое слово обладает косинусной мерой, большей или равной 0,9; · затем итеративно уменьшаем значение косинусной меры на 0,1 и для каждого подмножества запросов, полученного при различных значениях косинуса, получаем оценки точности и полноты. Рисунки 1 и 2 отражают различные сочетания точности и полноты, соответственно, усредненные для 5 подкатегорий при различных значениях косинусной меры. Из рисунков видно, что наилучшее сочетание метрик происходит при косинусной мере больше 0,3, так как · точность уменьшается на 9 % после значения 0,3; · полнота стабилизируется при значении 0,3 и практически не растет при более меньших значениях.
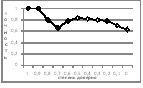
Соответственно, запросы, в которых каждое слово имеет косинусную меру близости больше 0,3, составляют автоматически полученное обучающее множество. Часть запросов попала в обучающее множество после фильтрации с помощью порогового значения косинуса, равного 0,3. Обучающее множество содержит 20 % запросов. Комбинированная статистика запросов среди всех подкатегорий показывает, что при числе запросов 13631 количество запросов в тестовом множестве составило 2714. Рисунки 3 и 4 отражают различные сочетания точности и полноты для сегментации запросов при различных значениях степени доверия для предсказания алгоритма сегментации. Из проведенных экспериментов видно, что наилучшее сочетание метрик происходит при значении степени доверия больше 0,3, так как · при значении степени доверия, меньшей 0,3, происходит резкое уменьшение точности; · полнота при значении степени доверия, меньшей 0,3, стабилизируется.
Сделаем вывод: если полученное предсказание характеризуется степенью доверия, большей 0,3, можно характеризовать его как достоверное. Результаты работы алгоритма сегментации показывают, что точность в обучающем множестве составляет 80 %. Это является высокой оценкой. И сегментация обладает высокими показателями: 75 % – точность и 76 % – полнота. Таким образом, в работе описаны полностью автоматизированный метод для сегментации пользовательских запросов и результаты экспериментов, проведенных на реальных данных, которые показывают, что предложенная техника обладает высокой точностью (75 %) и полнотой (75,7 %) по сравнению с предложенными в [1, 2, 5] методиками. Литература 1. Li X., Li Y., Wang and Acero A. Extracting structured information from user queries with semi-supervised conditional random fields // In Proc. of the 32nd Annual ACM SIGIR Conference on Research and Development in Informational Retrieval. Boston, Massachusetts, USA, 2009, pp. 572–579. 2. Agichtein E. and Ganti V. Mining Reference tables for automatic Text Segmentation // Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. Seattle, WA, USA, 2004, pp. 20–29. 3. Lafferty J., McCallum A. and Pereira F. Conditional random fields: Probabilistic models for segmenting and labeling sequences data // In Processing of the International Conference of Machine Learning. Williamstown, MA, USA, 2001, pp. 282–289. 4. Yu X. and Shi H. Query Segmentation Using Conditional Random Fields // In Processing of the First International Workshop on Keyword Search on structured data. Providence, Rhode Island, USA, 2009, pp. 21–26. 5. Druck G., Mann G. and McCallum A. Learning from labeled features using generalized expectation criteria // In Processing of the 31st Annual International ACM SIGIR conference on Research and Development in Informational Retrieval. Singapore, Singapore, 2008, pp. 595–602. |
 , где |D| – количество документов;
, где |D| – количество документов; 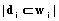 – частота wi в конкретном документе di [1]. Затем для составления обучающего множества определим порог для косинусной меры, обладающий оптимальным соотношением точности и полноты.
– частота wi в конкретном документе di [1]. Затем для составления обучающего множества определим порог для косинусной меры, обладающий оптимальным соотношением точности и полноты.

| Permanent link: http://swsys.ru/index.php?id=2579&lang=en&page=article |
Print version Full issue in PDF (5.84Mb) Download the cover in PDF (1.43Мб) |
| The article was published in issue no. № 3, 2010 |
Back to the list of articles