Journal influence
Bookmark
Next issue
Distributed case-based reasoning system architecture for intelligent systems
The article was published in issue no. № 1, 2011Abstract:This article discusses various issues of distributed case-based reasoning software development for intelligent systems. We propose architecture based on intelligent agents, seizing the opportunity to work with experience in related subject areas. The main advantages of systems based on the proposed architecture are described.
Аннотация:В статье рассматриваются вопросы построения программной системы распределенного вывода на основе преце-дентов для интеллектуальных систем. Предложена архитектура на базе интеллектуальных агентов, реализующая возможность использования накопленного опыта в смежных предметных областях. Перечислены основные преиму-щества применения систем на базе предложенной архитектуры.
| Authors: (BredikhinKN@gmail.com) - , Varshavskiy P.R. (VarshavskyPR@mpei.ru) - National Research University “MPEI”, Moscow, Russia, Ph.D | |
| Keywords: distributed case-based reasoning, plausible reasoning, multi-agent systems |
|
| Comments: 1 Page views: 18623 |
Print version Full issue in PDF (5.09Mb) Download the cover in PDF (1.32Мб) |
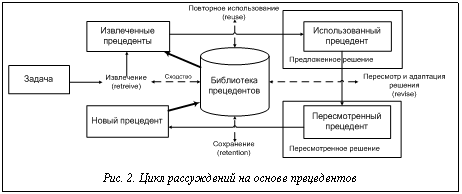
В области проектирования и реализации программных систем искусственного интеллекта весьма актуальными являются задачи моделирования правдоподобных рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений [1], в том числе задачи организации представления и хранения данных и знаний (прецедентов), а также разработки эффективных методов работы с распределенными данными. До недавнего времени основным направлением в области распределенного вывода на базе прецедентов (Case-Based Reasoning, CBR) было распределение ресурсов системы (как вычислительных, так и ресурсов данных в виде накопленного опыта) с целью повышения общей производительности CBR-системы. Распределенный характер библиотек прецедентов (БП) может быть обусловлен требованиями безопасности, предъявляемыми к системе (пользователи, обладающие информацией о некоторых прецедентах, ни с кем не хотят ею делиться). Сами источники прецедентов могут быть распределены территориально и динамически дополнять локальные БП новыми прецедентами. Кроме того, увеличение числа случаев успешного внедрения CBR-систем для решения различных практических задач дает новые возможности использования существующих БП, содержащих накопленный опыт в смежных предметных областях. В самом начале эксплуатации CBR-системы, когда происходит накопление знаний, ее текущая БП содержит мало прецедентов, что, в свою очередь, снижает эффективность самой системы. Для пополнения текущей БП системы может использоваться перспективная возможность привлечения внешних БП, сформированных при решении схожих задач. Более того, даже в CBR-системе с уже накопленным опытом в виде прецедентов внешние библиотеки могут оказаться полезными при решении задач, не характерных для системы в обычных условиях, так как внешние БП содержат дополнительные специализированные знания. В рамках программной реализации средств распределенного вывода на основе прецедентов предлагается архитектура на базе интеллектуальных агентов, изображенная на рисунке 1 [2]. Предлагаемая архитектура включает в себя три обязательных блока и один опциональный: · блок пользовательского интерфейса (User Interface Block), объединяющий в себе компоненты взаимодействия с пользователем (ЛПР, экспертом) и внешними системами; · блок управления (Management Block), содержащий компоненты, предназначенные для координации и поддержки работы основных компонентов программной системы; · блок анализа данных (Analysis Block), включающий в себя компоненты, связанные непосредственно с реализацией методов вывода на основе прецедентов; · блок сбора данных (Data Block) для работы с источниками данных (опциональный). С помощью компонентов блока пользовательского интерфейса система взаимодействует с пользователем и с внешними системами. Диалог с пользователем осуществляется через web-браузер с помощью web-интерфейса, реализующего набор шаблонов запросов к системе, и контролируется специальным пользовательским агентом. В задачи пользовательского агента входят простейшие функции анализа пользовательских запросов, передача их агенту-аналитику в блок анализа данных, загрузка онтологии предметной области для создания web-формы запроса и ведение истории запросов. Кроме того, данный агент выступает посредником между пользователем и остальными функциональными блоками системы. В частности, при работе с редактором БП пользовательский агент служит посредником между пользователем и блоком сбора данных. При работе с редактором онтологий или с конфигуратором системы данный агент взаимодействует с блоком управления. Часть указанных функций пользовательский агент выполняет в ходе работы с внешними сис- темами (при этом каждая внешняя система представляется в виде виртуального пользователя с отдельным профилем). Взаимодействие с внешними системами организуется с помощью единой web-службы (Web Service).
Помимо агента онтологий, в состав блока управления входят web-служба учета агентов и агент управления с реестром программных модулей. Web-служба учета агентов объединяет в себе функции системы управления агентами (Agent Management System) и каталога внешних интерфейсов агентов (Directory Facilitator), описываемых в стандарте FIPA (Foundation for Intelligent Physical Agents) по базовой архитектуре мультиагентных систем [3]. Данная web-служба публикует информацию об адресах и именах всех агентов, зарегистрированных в системе, а также о доступных сервисах (внешних интерфейсах), предоставляемых данными агентами. Агент управления отвечает за создание и поддержание функционирования рабочей группы анализа данных. По запросу агента-аналитика на базе заданной пользователем конфигурации агент управления создает новые CBR-агенты, загружая в них необходимые программные модули, сценарии и онтологию предметной области, взаимодействуя с агентом онтологий. Если на момент запроса в системе уже есть зарегистрированные CBR-агенты, отвечающие требованиям текущей задачи, агент управления проверяет их на наличие свободных ресурсов и по возможности включает в новую рабочую группу. В состав блока анализа данных входят агенты-аналитики и CBR-агенты. Агент-аналитик получает от пользовательского агента структурированный запрос на поиск решения, в соответствии с выбранной онтологией формирует требования к рабочей группе анализа данных и передает соответствующий запрос на создание рабочей группы агенту управления. После создания рабочей группы агент-аналитик посылает CBR-агентам, входящим в эту группу, запрос на поиск решения. Выбор агентом-аналитиком библиотек, из которых будут извлекаться прецеденты, производится с помощью диспетчера прецедентов. Данный выбор может основываться как на накопленном опыте решения определенных типов задач (в виде модели компетенций, сформированной в ходе эксплуатации системы), так и на заданной пользователем конфигурации и требованиях, предъявляемых к искомому решению. Например, если извлечение прецедентов из некоторой БП осуществляется быстрее, чем из других, такие библиотеки будут более востребованы при жестких ограничениях на время принятия решения, что харак- терно для интеллектуальных систем реального времени. Если же эта БП содержит много зашумленных и неточных данных, она будет менее востребована при ограничениях на качество искомого решения. CBR-агенты занимаются поиском решения на базе локальной БП с использованием стандарт- ных алгоритмов вывода на основе прецедентов и CBR-цикла (рис. 2) [1]. Если CBR-агенты не смогли найти решение, удовлетворительное по точности (согласно выбранной метрике и заданному пороговому значению), они сообщают об этом агенту-аналитику, передавая ему информацию о решении, ближайшем к заданному пороговому значению. В свою очередь, агент-аналитик передает информацию о данном решении пользовательскому агенту и по дополнительному запросу пытается найти удовлетворительное по точности решение, используя накопленный опыт в смежных предметных областях. С этой целью он делает запрос агенту управления на включение в рабочую группу дополнительных CBR-агентов для работы с БП, связанными со смежными предметными областями (с соответствующими загруженными в них онтологиями). Заново сформированная рабочая группа производит повторный поиск решения с использованием новых данных. Найденные в рамках отдельных предметных областей локальные решения отсылаются другим CBR-агентам на проверку. Так как в данном случае CBR-агенты могут работать с различными предметными областями, возникает необходимость адаптации локальных решений, полученных от разных агентов, для приведения их к общей форме. Решения, полученные с помощью специальных алгоритмов адаптации на основе онтологий, проверяются на БП, с которыми работают эти CBR-агенты. В результате проверки агенты отсылают обратно свою оценку данного решения для последующего голосования. Имея совокупность голосов за решение Sk, полученных от разных агентов, можно определить итоговую функцию голосования за него множеством агентов At:
где Vote(Sk, Aj) – значение функции голосования агента Aj за решение Sk. В результате итоговое решение задачи P будет определяться как решение, набравшее в сумме наибольшее количество голосов:
где N – общее количество найденных решений. После определения распределения голосов отдельных агентов между возможными решениями данная информация передается агенту-аналитику, а тот, в свою очередь, передает ее пользовательскому агенту для вывода через пользовательский интерфейс пользователю. Блок сбора данных является опциональным и, как правило, может понадобиться при жестких ограничениях на ресурсы источников данных. В состав данного блока входят только агенты сбора данных, которые являются посредниками между CBR-агентами и источниками данных, а также отвечают за обновление данных в ходе редактирования БП. В случае отсутствия блока сбора данных CBR-агенты могут работать с библиотеками напрямую. В рамках одной CBR-системы одновременно могут действовать несколько рабочих групп анализа данных, решающих разные задачи параллельно или же одну сложную задачу, декомпозированную на несколько подзадач. Основные достоинства предложенной архитектуры: - повышение производительности и точности поиска решения за счет организации параллельной работы с несколькими БП одновременно; - масштабируемость и надежность CBR-системы, достигаемая за счет иерархической структуры компонентов блоков управления и анализа данных, а также возможности динамически создавать в рамках системы новые рабочие группы анализа данных при наличии соответствующих вычислительных и информационных ресурсов; - возможность применения существующих методов и алгоритмов - широкие возможности по использованию накопленного опыта в смежных предметных областях путем подключения к CBR-системе существующих БП с минимальным вмешательством со стороны пользователя (эксперта). Основные компоненты предложенного архитектурного решения были программно реализованы средствами Microsoft .NET Framework 3.5 под MS Windows и протестированы на кластере Московского энергетического института с использованием БД из хранилища UCI Machine Learning Repository [4]. Литература 1. Варшавский П.Р., Еремеев А.П. Моделирование рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений // Искусственный интеллект и принятие решений. 2009. № 2. С. 45–47. 2. Тарасов В.Б. От многоагентных систем к интеллектуальным организациям: философия, психология, информатика. М.: Эдиториал УРСС, 2002. 3. FIPA: The Foundation for Intelligent Physical Agents. Abstract Architecture Specification, 2004. URL: www.fipa.org (дата обращения: 10.10.2010). 4. Бредихин К.Н., Варшавский П.Р. Распределенный вывод на основе прецедентов в интеллектуальных системах поддержки принятия решений // Теория и практика системного анализа: тр. I Всерос. науч. конф. молодых ученых. Рыбинск: РГАТА им. П.А. Соловьева, 2010. Т. 1. С. 57–62. |

 ,
, ,
, вывода на основе прецедентов для получения локальных результатов [1], так как необходимость в разработке дополнительных методов возникает только на этапе слияния локальных решений с целью получения конечного результата;
вывода на основе прецедентов для получения локальных результатов [1], так как необходимость в разработке дополнительных методов возникает только на этапе слияния локальных решений с целью получения конечного результата;| Permanent link: http://swsys.ru/index.php?id=2712&lang=en&page=article |
Print version Full issue in PDF (5.09Mb) Download the cover in PDF (1.32Мб) |
| The article was published in issue no. № 1, 2011 | Print version with comments |
Perhaps, you might be interested in the following articles of similar topics:
- Метод минимизации межузловых взаимодействий в одноранговых проблемно-ориентированных распределенных системах
- VMASTER – среда для разработки и верификации вероятностных мультиагентных систем
- Формальная модель многоагентных систем для федеративного обучения
- Искусственные миры: пространственная организация
- Облачная платформа IACPaaS для разработки оболочек интеллектуальных сервисов: состояние и перспективы развития
Back to the list of articles
Comments
author: Александр [2011-03-13 16:13:26]Я полагаю что эту статью дополнит статья которая имеет название "Методы изобретательства, с помощью которых три программиста легко могут составить такие программы для компьютера, посредством которых компьютер может изобрести много изобретений без помощи человека" эта статья изложена на в иитернете.
Оценка пользователя: баллов