Journal influence
Bookmark
Next issue
Persistent ontology storage technologies
The article was published in issue no. № 3, 2011Abstract:The problem of persistent ontology storage is described. RDF-store is described as special information system. Classification of persistent ontology storage using DBMS is done. Main factors effecting RDF-store production are determined. The future work in the field of organizing persistent ontology storage is defined.
Аннотация:Описывается проблема хранения онтологически представленной информации в реляционных БД. Хранилище онтологий рассматривается как особый класс информационных систем. Классифицированы существующие подходы к хранению онтологий в БД. Определены ключевые факторы, влияющие на эффективность хранилищ онтологий, а также возможные направления дальнейших исследований в области организации хранилищ онтологической информации.
| Authors: (mvehorev@gmail.com) - , (mpanteleyev@gmail.com) - , Ph.D | |
| Keywords: RDF Query Engine, SPARQL, RDF-store, RDF-triple store, relational DBMS, persistent ontology storage, ontology |
|
| Page views: 18141 |
Print version Full issue in PDF (5.05Mb) Download the cover in PDF (1.39Мб) |
Концепция и технологии семантического Веб – это динамично развивающиеся направления информационных технологий [1], которые обеспечивают возможность совместного многократного использования знаний различными приложениями, организациями и сообществами, позволяя компьютерам обрабатывать информацию на семантическом уровне. Ключевым элементом информационных систем (ИС), основанных на технологиях семантического Веб, являются онтологические базы знаний. При создании крупных информационных систем по мере роста объемов используемых онтологий их хранение в плоских файлах оказывается непродуктивным. В связи с этим актуальна проблема организации эффективных хранилищ онтологических баз знаний (RDF-хранилищ). Представление онтологий в семантическом Веб Под онтологией, согласно общепринятому определению, понимается явная спецификация концептуализации. Для автоматической обработки разделяемых знаний консорциумом W3C разработаны единые стандарты их представления: RDF (Resource Description Framework) и основанный на нем язык веб-онтологий OWL (Ontology Web Language). Под ресурсом понимается любая сущность, которой сопоставлен универсальный идентификатор URI (Universal Resource Identificator). Основной конструкцией языка RDF является утверждение, задаваемое тройкой <субъект> <предикат> <объект> (RDF-триплет), например: <стол> <цвет> <черный>. Использование URI для задания субъектов и свойств позволяет связывать отдельные утверждения (RDF-триплеты) в сколь угодно сложные семантические сети, имеющие единую интерпретацию в открытой сетевой среде. Простейшая форма хранения онтологий – OWL-файл. При чтении такого файла в оперативной памяти создается модель (набор утверждений), с которой выполняется дальнейшая работа. Однако данный подход имеет недостатки: существенный рост затрат оперативной памяти при работе с большими онтологиями (более 106 триплетов) вследствие полной загрузки OWL-файла, а также значительное увеличение времени загрузки OWL-файлов по мере роста количества используемых онтологий. Это не позволяет использовать данный подход при создании крупных ИС и обусловливает необходимость построения RDF-хранилищ на основе реляционных СУБД. Особенности RDF-хранилищ Под RDF-хранилищем понимается информационная подсистема, предназначенная для хранения RDF-триплетов и выполнения запросов к ним. Основными функциями RDF-хранилища являются: · организация хранения онтологий в реляционной БД с использованием реляционных представлений; · предоставление программного интерфейса для извлечения информации из хранимых онтологий посредством языка структурированных запросов SPARQL или специального API; · поддержка функций администрирования хранимых онтологий: добавление, удаление, модификация и распределение прав доступа. Эффективное RDF-хранилище должно удовлетворять следующим требованиям: · высокая производительность – минимизация времени выполнения запросов; · минимальные затраты памяти (дискового пространства) для хранения онтологий; · универсальность подхода – возможность хранения онтологий любой структуры. При разработке конкретных ИС важны время и сложность развертывания RDF-хранилища, а также его стоимость. Обобщенная архитектура RDF-хранилища В состав RDF-хранилища входят две основные подсистемы: подсистема хранения онтологий на основе реляционной СУБД и подсистема трансляции входных запросов в SQL-запросы (см. рис.).
Прикладные информационные системы могут взаимодействовать с RDF-хранилищем посредством специального API или структурированных SPARQL-запросов. SPARQL – это стандартный язык запросов к RDF-данным. Например, простой SPARQL-запрос для получения имени и номера паспорта некоторой персоны имеет вид: SELECT ?name ?number WHERE{ ?someone rdf:type :Person. ?someone :name ?name. ?someone :passportNumber ?number.} Отношение rdf:type является стандартным отношением языка RDF и означает принадлежность элемента классу. Класс :Person, отношения :name и :passportNumber в данном примере взяты из некоторого пространства имен по умолчанию. Подсистема трансляции входных запросов в общем случае может включать два компонента: · обработчик API-вызовов, предоставляющий библиотеку классов некоторого языка программирования для работы с онтологиями, включая их загрузку из хранилища; · транслятор SPARQL↔SQL, выполняющий преобразования SPARQL-запросов в SQL-запросы и обратные преобразования результатов, возвращенных SQL-запросами в результат SPARQL-запроса. Недостаток специального API состоит в привязке к конкретному языку программирования. Пример такого API – библиотека Jena. Интерфейс SPARQL-запросов является универсальным решением, не зависящим от языка программирования. Поэтому рассмотрим работу с RDF-хранилищем с использованием именно этого интерфейса. Преобразования SPARQL-запросов в набор SQL-запросов будем обозначать SPARQL→{SQL}. Очевидно, что формальная грамматика преобразования SPARQL→{SQL} зависит от принятой в RDF-хранилище схемы РБД. Вопросы оптимизации функционирования транслятора SPARQL↔ ↔SQL рассмотрены, в частности, в [2, 3]. Настоящая статья посвящена определению зависимости производительности RDF-хранилища от принятой схемы РБД. Организация хранения онтологий в БД Можно выделить два базовых подхода к организации хранения онтологий в РБД: 1) использование единственной таблицы для хранения всех RDF-триплетов (подход «вертикальная таблица»); 2) отображение иерархии онтологических сущностей (классов, свойств, экземпляров) в схему РБД. В соответствии с первым подходом все RDF-триплеты хранятся в унифицированной таблице БД, содержащей в общем случае четыре колонки: «граф», «субъект», «объект» и «предикат». Данный подход реализован, в частности, в Jena SDB и 3store. Он характеризуется достаточно высокой временной сложностью выборки RDF-триплетов. Особенностью второго подхода является определение схемы БД в соответствии с конкретной предметной областью, что позволяет оптимизировать выполнение запросов. Реализация данного подхода для больших онтологий предполагает создание большого числа таблиц БД со сложными связями между ними. Известно несколько частных решений, отличающихся способом формирования схемы БД [4, 5]. Анализ факторов, влияющих на эффективность RDF-хранилищ Эффективность RDF-хранилища при использовании SPARQL-запросов определяется двумя основными взаимосвязанными факторами: принятой схемой БД и грамматикой преобразования SPARQL→{SQL}. Исходя из представленной на рисунке обобщенной архитектуры RDF-хранилища, время Тsparql обработки SPARQL-запросов в общем виде определяется формулой Тsparql=Тtrans+Tsql_seq, (1) где Тtrans – время трансляции SPARQL-запроса в последовательность SQL-запросов в соответствии с принятой трансформационной грамматикой; Tsql_seq – время обработки СУБД построенной последовательности SQL-запросов. Введем определения и примем базовые допущения, необходимые для анализа временных затрат на обработку SPARQL-запросов. SQL-запрос в общем случае имеет следующую структуру: SELECT <кортеж выбираемых полей> FROM <кортеж таблиц> WHERE <кортеж условий>. Построение SQL-запроса на основе входного SPARQL-запроса предполагает формирование кортежей выбираемых полей и условий. Без существенной потери общности примем равными время формирования одного элемента кортежа выбираемых полей и одного элемента кортежа условий в запросе. Время формирования кортежа таблиц можно считать постоянным и пренебрежимо малым. Пусть T¢ – среднее время формирования элементов кортежа выбираемых полей и кортежа условий в процессе построения SQL-запроса. Тогда время формирования SQL-запроса линейно зависит от числа элементов в кортежах выбираемых полей и условий. Допустим, что обработка SQL-запроса требует последовательного просмотра всех записей таблицы и сравнения анализируемых условий для каждой из них. Тогда время выборки очередной записи из таблицы можно считать равным времени анализа одного условия. Обозначим T¢¢ среднее время выборки записи из таблицы и анализа условия, необходимое для выполнения SPARQL-запроса к СУБД. Будем считать, что T¢¢ не зависит от конкретной СУБД и является постоянным. Можно также считать, что время анализа записей в таблице БД линейно зависит от количества записей таблицы, а время анализа условий линейно зависит от количества условий, проверяемых для каждой записи в таблице БД. Зависимость времени трансляции SPARQL→ {SQL} от принятой трансформационной грамматики оценивается формулой
где N – количество результирующих запросов SQL, получаемых в результате трансляции; Tsql_def i – время построения i-го SQL-запроса. Зависимость времени формирования очередного SQL-запроса от количества полей, содержащихся в кортеже результата, и количества условий будет следующей:
Исходя из принятых допущений, можно записать:
Подставив (3) и (4) в (2), получим
Аналогично зависимость времени обработки набора SQL-запросов может быть выражена формулой
где k – коэффициент схемы БД, численно равный количеству таблиц БД (Ntbl); N – количество результирующих SQL-запросов, построенных при трансляции; Тsql i – время выполнения i-го SQL-запроса к СУБД. Время, необходимое на выполнение одного SQL-запроса, может быть оценено по формуле
где Trecord – время на анализ записей в таблице; Tfield – время на сопоставление условий запроса с текущими значениями в строке таблицы. Исходя из принятых допущений, можно записать:
где Ntbl_rec – количество записей в таблице БД;
где Ntbl_fld – количество проверяемых условий в SQL-запросе. Подставив (7–9) в (6), получим:
Подставив (5) и (10) в (1), получим:
Формула (11) выражает зависимость времени выполнения SPARQL-запроса от особенностей принятой схемы БД и соответствующей трансформационной грамматики. Рассмотрим влияние схемы БД на трансформационную грамматику для двух вариантов схем – «вертикальная таблицa» и «таблицы свойств классов». Схема БД «вертикальная таблица» предполагает создание единой таблицы для хранения RDF-триплетов, а схема БД «таблицы свойств классов» – отдельных таблиц для хранения экземпляров каждого из классов онтологии. Для сравнения этих вариантов рассмотрим простую онтологию, содержащую четыре класса – classHuman, classMan, classWoman, classChildren. Будем считать, что каждый из них имеет два экземпляра, за исключением родительского класса classHuman. Каждый экземпляр класса обладает свойствами propertyName и propertyAge. Структура хранения данной онтологии на основе схемы «вертикальная таблица» представлена в таблице 1. Таблица 1 table_Triples
Реализация хранения данной онтологии на основе схемы «таблицы свойств классов» предполагает создание таблицы иерархии классов онтологии (табл. 2) и отдельных таблиц для каждого из классов (табл. 3–5). Таблица 2 table_Hierarhy
Таблица 3 table_classMan
Таблица 4 table_classWoman
Таблица 5 table_classChildren
Примеры преобразования SPARQL→{SQL} Рассмотрим возможные варианты трансляции SPARQL-запросов к онтологии в набор SQL-запросов в зависимости от используемой схемы БД на конкретных примерах и оценим влияние принятой схемы БД на сложность преобразования SPARQL→{SQL}. Пример 1. SELECT ?x {WHERE ?x a classMan} // Определение всех экземпляров класса Преобразование SPARQL→{SQL} для схемы БД «вертикальная таблица» включает следующие шаги. 1. Определение всех подклассов класса classMan: SELECT result1(subject) FROM table_Triples WHERE (predicate='subClassOf' AND object='classMan') OR (subject='classMan'); 2. Выбор экземпляров классов, определенных на шаге 1: SELECT result2(subject) FROM table_Triples WHERE predicate='instanceOf' AND object=result1(subject); 3. Выбор значений свойств propertyName экземпляров, полученных на шаге 2: SELECT result3(subject, object) FROM table_Triples WHERE (subject= result2(subject)) AND (predicate='propertyName'); 4. Выбор значений свойств propertyAge экземпляров, полученных на шаге 2: SELECT result4(subject, object) FROM table_Triples WHERE (subject= result2(subject)) AND (predicate='propertyAge'); 5. Объединение результатов, полученных на шагах 3 и 4: JOIN result3,result4 BY subject; Аналогичное преобразование SPARQL→{SQL} для схемы БД «таблицы свойств классов» включает следующие шаги. 1. Выбор имен таблиц для класса classMan и его подклассов: SELECT result1(tableName) FROM table_ Hierarhy WHERE class='classMan' OR subClass= ='classMan'; 2. Выбор значений свойств propertyName, propertyAge из таблиц, определенных на шаге 1: SELECT result2(name, age) FROM result1 (tableName); Пример 2. SELECT ?name WHERE { ?x а classHuman. ?x propertyAge “35”. ?x propertyName ?name} // Определение объектов по значению свойства Преобразование SPARQL→{SQL} для схемы БД «вертикальная таблица» включает следующие шаги. 1. Определение всех подклассов класса classMan: SELECT result1(subject) FROM table_Triples WHERE (predicate='subClassOf' AND object='classHuman') OR (subject='classHuman'); 2. Выбор экземпляров классов, определенных на шаге 1: SELECT result2(subject) FROM table_Triples WHERE predicate='instanceOf' AND object=result1(subject); 3. Выбор среди полученных на шаге 2 экземпляров со значением свойства возраст, равным 35: SELECT result3(subject,object) FROM table_ Triples WHERE (subject= result2(subject)) AND (predicate='propertyAge') AND (object = ‘35’); 4. Определение имени экземпляров, если результат шага 3 не пустой: SELECT result4(object) FROM table_Triples WHERE (subject = result3.subject AND predicate='propertyName'); Аналогичное преобразование SPARQL→{SQL} для схемы БД «таблицы свойств классов» включает следующие шаги. 1. Выбор имен таблиц для класса classMan и его подклассов: SELECT result1(tableName) FROM table_ Hierarhy WHERE class='Human' OR subClass='Human'; 2. Выбор экземпляров со значением поля propertyAge, равным 35, из таблиц, определенных на шаге 1. SELECT result2(name) FROM result1(tableName) WHERE age=35; Пример 3. SELECT ?x WHERE{ ?x subclassOf classHuman} // Определение классов потомком Преобразование SPARQL→{SQL} для схемы БД «вертикальная таблица» содержит такой шаг, как выбор из таблицы триплетов всех подклассов класса classHuman. SELECT result1(subject) FROM table_Triples WHERE (predicate='subClassOf' AND object='classHuman'); Аналогично и преобразование SPARQL→ →{SQL} для схемы БД «таблицы свойств классов»: выбор из таблицы иерархии классов всех подклассов класса classHuman: SELECT result1(subClass) FROM table_Hierarhy WHERE class='Human'; Оценки времени выполнения рассмотренных запросов на основе формул (5) и (10) в сопоставимых условных временных единицах представлены в таблице 6, где ВТ – вертикальная таблица, ТСК – таблица свойств классов. Анализ полученных результатов показывает, что трансляция SPARQL-запросов при втором подходе выполняется приблизительно в три раза быстрее. Время обработки последовательностей SQL-запросов во втором случае в два раза меньше. Таблица 6 Временные затраты на выполнение SPARQL-запросов
Полученные результаты позволяют сделать вывод, что схема БД «вертикальная таблица» требует более сложной трансформационной грамматики и большего времени на выполнение SPARQL-запросов. С другой стороны, схема БД на основе «таблиц свойств классов» упрощает трансформационную грамматику и уменьшает время выполнения SPARQL-запросов. Полученные результаты могут служить основой для выбора эффективного решения при построении RDF-хранилищ в зависимости от специфики хранимых онтологий и их состава. Обратим внимание, что теоретические оценки хорошо согласуются с экспериментальными результатами, представленными в [5–7]. В заключение отметим, что предложенный подход к оценке временных затрат на выполнение SPARQL-запросов позволяет теоретически оценивать эффективность различных подходов к организации RDF-хранилищ и может служить основой для построения более точных теоретических оценок эффективности RDF-хранилищ. Дальнейшие исследования должны быть направлены на изучение организации эффективных RDF-хранилищ, в частности, на определение рациональных схем БД для хранения онтологий и экспериментальную оценку эффективности предлагаемых подходов, на разработку новых архитектурных принципов построения хранилищ, комбинирующих достоинства различных подходов, а также на оптимизацию выполнения SPARQL-запросов к хранилищам, обладающим определенной схемой БД. Литература 1. Пузанков Д.В. [и др.]. Интеллектуальные агенты, многоагентные системы и семантический Web: концепции, технологии, приложения. СПб: Изд-во «Технолит», 2008. 292 с. 2. Chebotko A. [et al.]. Semantics preserving SPARQL-to-SQL translation // Data & Knowledge Engineering. 2009. Vol. 68. Is. 10, pp. 973–1000. 3. Richard Cyganiak. A relational algebra for SPARQL. HP Labs, Bristol, 2005. 4. Velegrakis Yannis. Relational Technologies, Metadata and RDF. Semantic Web Information Management // Springer-Verlag Berlin Heidelberg, 2010, p. 41. 5. Theoharis Yannis, Christophides Vassilis, Karvounarakis Grigoris. Benchmarking Database Representations of RDF/S Stores // Springer-Verlag Berlin Heidelberg, 2005, pp. 685–701. 6. Yuanbo Guo, Zhengxiang Pan, and Jeff Heflin. An Evaluation of Knowledge Base Systems for Large OWL Datasets. Computer Science and Engineering Department, Lehigh University, Bethlehem, USA, 2004. 7. Hondjack Dehainsala, Guy Pierra, Ladjel Bellatreche. OntoDB: An Ontology-Based Database for Data Intensive Applications. Proc. Of Database Systems for Advanced Applications (DASFAA’2007) // Bangkok, Thailand, 2007. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 , (2)
, (2)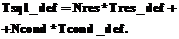 (3)
(3) . (4)
. (4)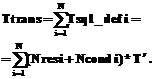 (5)
(5) , (6)
, (6) , (7)
, (7) , (8)
, (8) , (9)
, (9)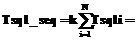
 (10)
(10)

 . (11)
. (11)| Permanent link: http://swsys.ru/index.php?id=2800&lang=en&page=article |
Print version Full issue in PDF (5.05Mb) Download the cover in PDF (1.39Мб) |
| The article was published in issue no. № 3, 2011 |
Perhaps, you might be interested in the following articles of similar topics:
- Онтологии для реализации обратной трассировки при разработке и сопровождении программ
- Мультиагентная система распределения производственных ресурсов в тяжелом машиностроении
- Подсистема воспроизведения иммерсивных виртуальных тренажеров с биологической обратной связью
- Расширение базы знаний с учетом доверия к новому знанию
- Автоматизация оценки знаний студентов в системе электронного обучения ECOLE
Back to the list of articles