Journal influence
Bookmark
Next issue
Research overfitting of recognizing procedures on the basis of full decision trees
The article was published in issue no. № 4, 2011 [ pp. 141 – 147 ]Abstract:Paper continues the series of works devoted to development of classification algorithms on the basis of full decision trees. This construction decision trees allows counting all the attributes that match the criteria bifurcation. Investigate questions of reducing overfitting a full decision trees with bifurcation entropy criterion. The results of testing on real problems are adduced.
Аннотация:Статья посвящена разработке алгоритмов классификации на основе полных решающих деревьев. Данная конст-рукция решающего дерева позволяет учитывать все признаки, удовлетворяющие критерию ветвления. Исследуются вопросы снижения переобучения полных решающих деревьев с энтропийным критерием ветвления. Приведены ре-зультаты тестирования на реальных задачах.
| Author: (ingvar1485@rambler.ru) - | |
| Keywords: overfitting, full decision tree, pattern recognition problems on precedents |
|
| Page views: 8770 |
Print version Full issue in PDF (5.83Mb) Download the cover in PDF (1.28Мб) |
При решении задачи распознавания по прецедентам многие методы подвержены переобучению (переподгонка, overfitting, overtraining) – ситуация, когда качество работы алгоритма на новых объектах, не вошедших в состав обучения, оказывается существенно хуже, чем на обучающей выборке. Данная проблема может быть связана с такими явлениями, как - минимизация эмпирического риска не гарантирует, что вероятность ошибки на тестовых данных будет мала; - переобучение появляется именно вследствие минимизации эмпирического риска; - переобучение связано с избыточной сложностью используемой модели; всегда существует оптимальное значение сложности модели, при котором переобучение минимально [1]. Деревья решений являются одним из известных инструментов, используемых в задаче распознавания, которые также подвержены переобучению. Процедура построения классического дерева решений представляет собой итерационный процесс. На каждом шаге выбирается признак, удовлетворяющий некоторому критерию ветвления, и строится вершина дерева. Однако, если при построении дерева несколько признаков удовлетворяют критерию ветвления в равной или почти в равной мере, выбор одного из них происходит случайным образом. При этом в зависимости от выбранного признака построенные деревья могут существенно отличаться как по составу используемых признаков, так и по своим распознающим качествам. В работе [2] при возникновении ситуации, когда два или более признака удовлетворяют критерию ветвления в равной или почти в равной мере, предлагается проводить ветвление по каждому из этих признаков независимо. Полученная в результате конструкция названа полным решающим деревом (ПРД). Таким образом, в отличие от классического дерева решений, в ПРД на каждом шаге строится так называемая полная вершина, которой соответствует набор признаков X, и ветвление происходит по каждому из признаков. В [2] данный подход успешно продемонстрирован на примере усовершенствования алгоритма построения допустимых разбиений для случая бинарной информации без пропусков в признаковых описаниях объектов. В [3] для случаев вещественнозначной информации, наличия пропусков в признаковых описаниях объектов и неравномерного распределения объектов по классам описан алгоритм классификации, использующий при построении ПРД энтропийный критерий ветвления. В данной работе исследуется эффект переобучения ПРД на примере алгоритма AGI.Bias [3], так как ПРД является усложненной моделью классических деревьев решений. Предлагается методика снижения эффекта переобучения ПРД с использованием числовых характеристик построенного дерева для задачи, а именно, средней глубины дерева и среднего числа обучающих объектов, описание которых попадает в лист дерева. Основные определения Рассматривается задача распознавания по прецедентам с системой признаков {x1, …, xn}, с непересекающимися классами K1, …, Kl, l³2, и множеством обучающих объектов T={S1, …, Sm}, где Sr=(ar1, …, arn), rÎ{1, …, m}; arjÎ{Â, «*»}, j=1,.., n. В случае arj=«*» считается, что значение признака xj для объекта Sr не определено. Пусть далее S – распознаваемый объект, (b1, …, bn) – описание объекта S и bjÎ{Â, «*»}, j=1, …, n. Опишем структуру ПРД. Обозначим через Определение 1. Обычной вершиной в ПРД называется внутренняя вершина дерева, для которой выполняются следующие условия: 1) данной вершине соответствует ровно один признак xÎX( 2) в данную вершину входит одна дуга и выходят две дуги, помеченные 0 и 1; 3) при спуске по каждой дуге, выходящей из данной вершины, происходит удаление некоторых объектов из 4) каждая дуга, выходящая из данной вершины, входит либо в висячую, либо в полную вершину ПРД. Определение 2. Полной вершиной в ПРД называется внутренняя вершина дерева, для которой выполняются условия: 1) данной вершине соответствует набор различных признаков: 2) в данную вершину входит одна дуга и выходят q дуг с метками t1, …, tq, q³1; 3) каждая дуга с меткой tu, u=1, …, q, выходящая из данной вершины, входит в обычную вершину, соответствующую признаку Определение 3. Глубиной ветви в ПРД называется число обычных вершин, содержащихся в этой ветви. Определение 4. Ребром в ПРД называется дуга, выходящая из обычной вершины и входящая в полную или висячую вершину дерева, а также дуга, выходящая из полной и входящая в обычную вершину. Определение 5. Глубиной ПРД называется максимальная глубина среди всех построенных ветвей дерева. На каждом шаге построения ПРД формируется в точности одна полная вершина. Далее из полной вершины X строится ровно q дуг. Каждая из этих дуг входит в обычную вершину, соответствующую признаку x, xÎX. Далее по каждой дуге, выходящей из обычной вершины дерева, соответствующей признаку x, осуществляется спуск и происходит переход к следующему шагу построения ПРД до тех пор, пока не выполнятся условия останова [4]. В случае вещественнозначной информации для ветвления из обычной вершины, соответствующей признаку x, осуществляется бинарная перекодировка текущих значений признака x посредством выбора оптимального порога d(x) [4]. Рассматриваемая вершина помечается парой (x, d(x)). Спуск из вершины (x, d(x)) происходит по двум ветвям, при этом левая ветвь помечается 0, а правая 1. При спуске из вершины (x, d(x)) по левой (правой) ветви удаляются те объекты из Висячая вершина v называется голосующей для S, если S(v)=Nv. Заметим, что в отличие от классического дерева решений в ПРД описание рассматриваемого объекта S может совпадать с порождающими наборами для разных висячих вершин, то есть возможно, что S(v1)= Пусть Q(S) – множество всех голосующих висячих вершин ПРД для распознаваемого объекта S. Для каждого iÎ{1, ..., l} вычисляется оценка принадлежности объекта S классу Ki, имеющая вид Объект S зачисляется в класс Ki, если
G(S, Ki)¹G(S, Kj) при i¹j, i=1, …, l. Если классов с максимальной оценкой несколько, среди них выбирается только один, а именно тот, который имеет наибольшее число объектов в обучающей выборке, иначе происходит отказ алгоритма от классификации объекта S. В алгоритме AGI.Bias вектор оценок Переобученность алгоритма AGI.Bias Исследование проблемы переобученности ПРД осуществлялось на задачах распознавания по прецедентам в случае вещественнозначной информации с пропусками в признаковых описаниях объектов и неравномерным распределением объектов по классам. Численный эксперимент осуществлялся на десяти реальных задачах из коллекции, собранной в отделе математических проблем распознавания и методов комбинаторного анализа ВЦ им. А.А. Дородницына РАН (г. Москва). Следует отметить, что для снижения эффекта переобучения в классических деревьях применяются методы, которые условно можно разделить на две группы. Первая группа методов используется в процессе синтеза дерева и заключается в раннем прерывании синтеза – создание висячей вершины при выполнении определенных условий. К таким условиям могут относиться: невозможность дальнейшего спуска из обычной вершины, если текущее множество объектов содержит меньше допустимого числа объектов (всего 2–3); превышение допустимой глубины ветви (строить ветви, содержащие не более 7 признаков); информативность выбранного признака для ветвления ниже допустимой и другие условия. Вторая группа методов используется после синтеза дерева. К таким методам относятся отсечение, слияние ветвей или замена листа поддеревом при выполнении определенных условий. При использовании ПРД для решения задачи распознавания, особенно для задачи с большим числом обучающих объектов или признаков, де- рево получается ветвистым, с большим числом висячих вершин. Поэтому для снижения эффекта переобучения применяются методы из первой группы, а именно, ограничение на глубину ветви и на минимальное число объектов в висячей вершине. Так как значения этих величин для каждой задачи неизвестны и эмпирическое вычисление оптимальных значений требует немало времени, хотелось бы иметь механизм (метод) для их определения. Поэтому предлагается использовать свойства синтезированного дерева для конкретной задачи. К таким свойствам относятся средняя глубина дерева D и среднее число обучающих объектов O, описание которых попадает в висячую вершину. Данные свойства являются важными характеристиками и могут существенно повлиять на снижение эффекта переобучения. Таким образом, предлагаемый метод снижения эффекта переобучения состоит из двух процедур. Первая заключается в синтезе дерева с вычислением D и O, вторая – в использовании характеристик D и O при построении дерева для классификации объекта. Исследуем переобученность на примере алгоритма AGI.Bias. Метод анализа данного алгоритма на переобученность похож на метод, используемый в системе «Полигон» (http://poligon.machinelearning.ru/). Процедура заключается в случайном разбиении исходной выборки на обучение и контроль в процентном соотношении. Первый шаг: на обучение попадает 10 % всех объектов исходной выборки, на контроль – 90 %; при переходе к следующему шагу на обучение попадает 15 % объектов исходной выборки, на контроль – 85 %, то есть приращение при переходе на следующий шаг составляет 5 %. Последний шаг: на обучение попадает 90 % всех объектов исходной выборки, на контроль – 10 %. Процедура разбиения исходной выборки на две части повторяется по 10 раз для каждого шага. При этом необходимо сохранять одинаковое соотношение числа объектов из разных классов в обучаемой и контрольной частях, равное соотношению числа объектов из разных классов в исходной выборке, то есть использовать стратификацию классов. Отличие изложенной процедуры от процедуры в системе «Полигон» в том, что в системе при переходе к следующему шагу приращение составляет 10 %. В данной работе в том же сравнении используется другой функционал качества Исследование состоит из нескольких этапов. Этап I. Исследование влияния значения характеристики D на переобученность. Для этого использовались следующие комбинации алгоритма AGI.Bias с характеристикой D: без использования характеристики D; c использованием только характеристики D; c использованием характеристики D–1; c использованием характеристики D–2. Модификация алгоритма AGI.Bias c использованием характеристики D–2 означает, что при классификации объекта одним из условий, когда будет построен лист дерева, является превышение глубины текущей ветви дерева значения «средняя глубина–2». Этап II. Исследование влияния значения характеристики O на переобученность. Для этого использовались следующие комбинации алгоритма AGI.Bias с характеристикой O: без использования характеристики O; c использованием характеристики O; c использованием характеристики O+1; c использованием характеристики O+2. Модификация алгоритма AGI.Bias c использованием характеристики O+2 означает, что при классификации объекта одно из условий, когда будет построен лист дерева, – число обучающих объектов в текущем множестве станет меньше величины «среднее число обучающих объектов в листе+2». Этап III. Исследование комбинации значений характеристик O и D. Для этого использовались следующие комбинации характеристик O и D: без использования характеристик O и D; c использованием характеристик D и O; c использованием характеристик D–1 и O+1; c использованием характеристик D–2 и O+2. Для каждой задачи и каждой модификации алгоритма AGI.Bias вычислялась величина На каждом этапе также строилась кривая обучения – зависимость средней частоты величины «1 – частота ошибок» на контроле от длины обучающей выборки. Для этого на каждом шаге вычислялась величина
Кроме того, был проведен анализ качества модификаций алгоритма AGI.Bias с помощью метода скользящего контроля (leave-one-out). Результаты приведены в таблице 2. Для каждой задачи и каждой модификации алгоритма в соответствующей ячейке приведены значения величины Q. Анализ результатов показал, что наибольшее влияние на снижение переобученности алгоритма AGI.Bias оказывает характеристика D. При этом в случае модификации алгоритма AGI.Bias с величиной D, начиная с момента, когда на обучение попадало более 70 % объектов из исходной выборки, возникали случаи недообученности. При использовании характеристики D–2 они происходили в среднем в 2-3 повторах на каждом из последующих шагов. Характеристика O незначительно влияет на переобученность в рассмотренных модификациях, в среднем снижение в случае O+2 составляло 2–2,5 % от исходного алгоритма. При использовании комбинаций характеристик D и O наблюдалось, что влияние характеристики O на показатели переобученности тоже незначительно.
Помимо того, проведено сравнение алгоритма AGI.Bias и лучшей его модификации AGI.Bias D–2 O+2 с известными методами построения классического решающего дерева (алгоритм С5.0 (http://www.rulequest.com/see5-info.html) – улучшенная, коммерческая версия алгоритма C4.5 [5], и алгоритм SimpleCART), с лесом решающих де- ревьев (RandomForest) и методом, использующим бустинг над решающими деревьями (LADTree). Алгоритмы SimpleCART, RandomForest и LADTree взяты из системы WEKA (http://www.cs.waikato.ac.nz/~ml/weka/). Результаты представлены также для алгоритма С5.0 с применением встроенной процедуры отсечения в программу (С5.0 prune). Аналогично рассматривались результаты алгоритма SimpleCART с применением метода отсечения (SimpleCART prune), встроенного в алгоритм SimpleCART из комплекса WEKA. Результаты тестирования представлены в таблице 3. Для каждой задачи и каждой модификации алгоритма в соответствующей ячейке приведены значения величины Q.
Сравнение алгоритмов показало, что применение разработанной методики позволило понизить переобученность и в большинстве случаев повысить качество распознавания объектов для алгоритма AGI.Bias. Сравнение модифицированного алгоритма (табл. 3) показало его преимущество перед известными методами построения классических решающих деревьев (С5.0 и SimpleCART), а также перед современными методами, использующими решающие деревья (RandomForest, LADTree). Обобщая, отметим, что в работе проведено исследование переобученности ПРД на примере алгоритма AGI.Bias. Предложена процедура снижения переобученности с использованием свойств построенного ПРД. Первая часть процедуры заключается в синтезе дерева для конкретной задачи с вычислением D – средней глубины дерева и O – среднего числа обучающих объектов, описания которых попадают в висячую вершину дерева. Вторая часть процедуры – использование характеристик D и (или) O в процессе построения дерева при классификации объекта. Наилучшее соотношение «снижение переобученности/качество классификации» показали модификации алгоритма построения ПРД с комбинациями D O и D–2 O+2. Модификация D–2 O+2 алгоритма означает, что в процессе построения дерева при классификации объекта одним из условий, когда будет построен лист дерева, является условие, при котором глубина текущей ветви дерева превышает значение «средняя глубина–2» или число обучающих объектов в текущем множестве станет меньше величины «среднее число обучающих объектов в листе+2». Тестирование модифицированного алгоритма с другими известными методами построения решающего дерева показало его преимущество на большинстве реальных задач, рассмотренных в работе. Литература 1. Воронцов К.В. Комбинаторная теория надежности обучения по прецедентам: дис. … док. физ.-мат. наук. М.: ВЦ РАН, 2010. 271 с. 2. Djukova E.V., Peskov N.V. А classification algorithm based on the complete decision tree // J. Pattern Recognition and Image Analysis, 2007. Vol. 17. № 3, pp. 363–367. 3. Генрихов И.Е., Дюкова Е.В. Полные решающие деревья в задачах классификации по прецедентам // Математические методы распознавания образов: Докл. 15-й Всерос. конф. М.: МАКС Пресс, 2011. С. 84–88. 4. Genrikhov I.E. Synthesis and analysis of recognizing procedures on the basis of full decision trees // J. Pattern Recognition and Image Analysis. 2011. Vol. 21. № 1, pp. 45–51. 5. Quinlan J. R. C4.5: Programs for Machine Learning. Morgan Kaufmann. San Mateo, CA. 1993. |
 рассматриваемое на текущем шаге (итерации) подмножество обучающих объектов, через X(
рассматриваемое на текущем шаге (итерации) подмножество обучающих объектов, через X( , XÍX(
, XÍX( .
. , для которых значение признака x больше (не больше) d(x). Обозначим через
, для которых значение признака x больше (не больше) d(x). Обозначим через 
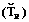 подмножество обучающих объектов для левой (правой) ветви. Пусть v – вершина, порожденная ветвью дерева с обычными вершинами
подмножество обучающих объектов для левой (правой) ветви. Пусть v – вершина, порожденная ветвью дерева с обычными вершинами  , и пусть дуга, выходящая из вершины
, и пусть дуга, выходящая из вершины  , имеет метку si, iÎ{1, …, r}. Набор Nv=(a1, …, an), где
, имеет метку si, iÎ{1, …, r}. Набор Nv=(a1, …, an), где  при i=1, …, r и aj=«*» при jÎ{1, …, n}\{j1, …, jr}, назовем порождающим для вершины v. Если вершина v не является висячей, то ей ставится в соответствие порождающий набор Nv. Если v – висячая вершина, то поставим ей в соответствие пару
при i=1, …, r и aj=«*» при jÎ{1, …, n}\{j1, …, jr}, назовем порождающим для вершины v. Если вершина v не является висячей, то ей ставится в соответствие порождающий набор Nv. Если v – висячая вершина, то поставим ей в соответствие пару  , где Nv – порождающий набор для вершины v;
, где Nv – порождающий набор для вершины v;  – вектор оценок за классы. Описанием объекта S=(b1, …, bn) в вершине v будем называть вектор S(v)=(b1, …, bn), в котором
– вектор оценок за классы. Описанием объекта S=(b1, …, bn) в вершине v будем называть вектор S(v)=(b1, …, bn), в котором  , если
, если  , иначе
, иначе  при i=1, …, r и bj=«*» при jÎ{1, …, n}\{j1, …, jr}. В случае бинарной информации ветвление из обычной вершины, помеченной x, осуществляется стандартным способом.
при i=1, …, r и bj=«*» при jÎ{1, …, n}\{j1, …, jr}. В случае бинарной информации ветвление из обычной вершины, помеченной x, осуществляется стандартным способом. и S(v2)=
и S(v2)= при v1¹v2.
при v1¹v2. , i=1, …, l.
, i=1, …, l. , i=1, …, l,
, i=1, …, l, для висячей вершины v вычисляется следующим образом. Пусть
для висячей вершины v вычисляется следующим образом. Пусть  – число обучающих объектов класса Ki, описания которых равны Nv, mi – число обучающих объектов класса Ki, и пусть
– число обучающих объектов класса Ki, описания которых равны Nv, mi – число обучающих объектов класса Ki, и пусть  . Тогда в алгоритме AGI.Bias полагается
. Тогда в алгоритме AGI.Bias полагается  , i=1, …, l. Таким образом, в алгоритме AGI.Bias оценка за класс Ki для висячей вершины v нормируется с учетом числа всех объектов класса Ki в обучающей выборке.
, i=1, …, l. Таким образом, в алгоритме AGI.Bias оценка за класс Ki для висячей вершины v нормируется с учетом числа всех объектов класса Ki в обучающей выборке. где qi – процент правильно классифицируемых объектов класса Ki. На каждом шаге разбиения вычислялась величина
где qi – процент правильно классифицируемых объектов класса Ki. На каждом шаге разбиения вычислялась величина 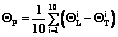 , где
, где  – значение функционала Q на объектах из обучения для i повтора на текущем шаге разбиения;
– значение функционала Q на объектах из обучения для i повтора на текущем шаге разбиения;  – значение функционала Q на объектах из контроля для i повтора на текущем шаге разбиения.
– значение функционала Q на объектах из контроля для i повтора на текущем шаге разбиения. , где
, где  – значение величины
– значение величины  на i-м шаге разбиения. Результаты представлены в таблице 1. AGI.Bias D O означает, что использовалась модификация алгоритма AGI.Bias с использованием характеристик D и O.
на i-м шаге разбиения. Результаты представлены в таблице 1. AGI.Bias D O означает, что использовалась модификация алгоритма AGI.Bias с использованием характеристик D и O. . При использовании методов для снижения переобученности появляется вероятность того, что модифицированный алгоритм будет совершать больше ошибок, чем стандартный. Поэтому важно выбрать такую комбинацию используемых характеристик O и (или) D, которая даст хорошее снижение переобученности, и при этом качество классификации не будет сильно снижено.
. При использовании методов для снижения переобученности появляется вероятность того, что модифицированный алгоритм будет совершать больше ошибок, чем стандартный. Поэтому важно выбрать такую комбинацию используемых характеристик O и (или) D, которая даст хорошее снижение переобученности, и при этом качество классификации не будет сильно снижено.




| Permanent link: http://swsys.ru/index.php?id=2935&lang=en&page=article |
Print version Full issue in PDF (5.83Mb) Download the cover in PDF (1.28Мб) |
| The article was published in issue no. № 4, 2011 [ pp. 141 – 147 ] |
Back to the list of articles