Journal influence
Bookmark
Next issue
Architecture of intelligent information support system for innovations in science and education
The article was published in issue no. № 4, 2013 [ pp. 203-208 ]Abstract:The search for innovative solutions using different data sources is an important part of many lines of business, science and education. One of the main trends in the development of methodologies and solutions for search innovation is an automated semantic processing large volume of scientific and technical information that allows searching for breakthrough technologies and other innovative ideas. Obviously, there is a need in efficient methods of digital collections creating and filling with the latest ideas and technologies that contain not just their descriptions, but specially selected, classified and associated data. The development of new methods to search for ready-made solutions in the data center database is the essence of the Information Support System for Innovations in Science and Education. The article describes one of the approaches to finding information on innovations and its scope. The software common architecture and pilot components are presented. The relevant software architecture, including its functionality and behavior of the system during a given session is described. The object model for working with documents is presented. The document is any text object that is relevant to the subject matter of processing: query, search result, text document. There is information about the current state of the ongoing project.
Аннотация:Поиск инновационных решений с использованием различных источников данных – важная составляющая многих направлений деловой активности. Одним из основных трендов развития методологии и решений для поиска инноваций является автоматизированная семантическая обработка больших массивов научно-технической информации, позволяющая осуществлять поиск прорывных технологий и других инновационных идей. Очевидно, что нужны эффективные методы создания и наполнения электронных коллекций новейших идей и технологий, содержащих не просто их описания, а специальным образом отобранные, классифицированные и ассоциированные данные. Разработка новых методов поиска готовых решений в базе данных центра обработки данных (data centre) – суть проекта системы информационной поддержки инноваций в науке и образовании. В настоящей статье описываются один из подходов к поиску информации об инновациях и область его применения. Приведена общая архитектура системы с указанием пилотных компонентов. Описана архитектура соответствующего программного обеспечения, включая его функциональность и поведение системы в течение конкретного сеанса работы. Представлена объектная модель для работы с документами, под которыми понимаются любые текстовые объекты, имеющие отношение к предмету обработки: запросы, результаты поиска, текстовые документы. Даются сведения о текущем состоянии реализуемого проекта.
| Authors: Ivanov V.K. (mtivk@mail.ru) - Tver State Technical University, Tver, Russia, Ph.D, Palyukh B.V. (pboris@tstu.tver.ru) - Tver State Technical University, Tver, Russia, Ph.D, A.N. Sotnikov (asotnikov@iscc.ru) - Joint Supercomputer Center of RAS (Professor), Moscow, Russia, Ph.D | |
| Keywords: service, data classification, innovations, search algorithm, software architecture, decision support |
|
| Page views: 12522 |
Print version Full issue in PDF (7.95Mb) Download the cover in PDF (1.45Мб) |
Поиск инновационных решений с использованием различных источников данных является важной составляющей многих направлений деловой активности. Разнообразные исследования в этой области инновационного менеджмента касаются особенностей поиска инноваций в экономике, науке, образовании (см., например, [1–3]). В этой связи несомненную ценность представляют специализированные коллекции научно-технических достижений [4]. Один из основных трендов развития методологии и решений для поиска инноваций – автоматизированная семантическая обработка больших массивов научно-технической информации, позволяющая осуществлять поиск прорывных технологий и других инновационных идей. В качестве примеров приведем несколько известных решений: illumin8, NetBase, Orbit. При всех различиях этих и других подобных систем основной паттерн поиска включает в себя отбор материалов по запросу, выделение ключевых понятий в заданной области и соответствующую группировку материалов, фильтрацию результатов, генерацию аналитических отчетов. Не затрагивая вопросов стратегии внедрения инноваций в конкретных приложениях, отметим ряд принципиальных, на взгляд авторов, особенностей, касающихся реализации непосредственных механизмов автоматизированного поиска инновационных решений: – искомые решения часто находятся на стыке смежных областей – отсюда сложности формулировки точного запроса; – одновременно с информацией о собственно инновациях желательно получить сведения о примерах применения, рисках, особенностях использования, пользователях, авторах, производителях; – наличие альтернатив и необходимость одновременного поиска критериев отбора наиболее эффективных решений; – разрозненность и неоднородность сведений об инновациях; преимущественно внутриотраслевой характер. Очевидно, что полностью задача автоматизированного поиска инновационных решений далеко не решена. Нужны новые эффективные методы создания и наполнения электронных коллекций новейших идей и технологий, содержащих не просто их описания, а специальным образом отобранные, классифицированные и ассоциированные данные. В настоящей статье описываются один из подходов к поиску информации об инновациях и область его применения, представляется архитектура соответствующего ПО, даются сведения о текущем состоянии реализуемого проекта програм- мной системы с функциями семантического поиска и интеллектуального анализа данных для предложения инновационных решений. О цели проекта Предположим, что пользователю необходимо получить максимально исчерпывающую информацию о возможных инновационных решениях задачи в какой-либо предметной области. Естественные первоочередные действия – выполнение поискового запроса/запросов для поиска научно-технической информации: – в ресурсах Интернета (издания общероссийских и отраслевых институтов информации, справочники, статьи и обзоры, материалы конференций, ГОСТы, технические регламенты, нормативно-техническая документация, отчеты о НИР/ОКР, рекламные материалы, статистические данные, экспертные оценки); – в специализированных БД (патентных, описаний изобретений и полезных моделей, промышленных образцов, реферативной и/или библиографической информации, товарных знаков).
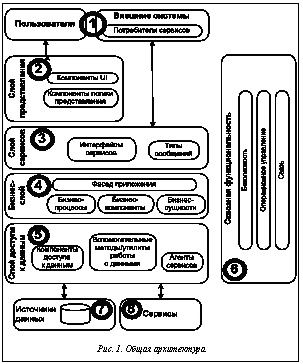
– является ли ранжирование результатов, выполненных поисковой системой, корректным с точки зрения ожиданий пользователя; – все ли результаты, доступные для непосредственной оценки пользователем, соответствуют его ожиданиям; – все ли результаты, соответствующие ожиданиям пользователя, попали в число доступных для непосредственной оценки; – все ли искомые решения найдены вообще; – обнаружатся ли эффективные решения, которые относятся к другим областям применения, но могут успешно использоваться как инновации в данной области. Ответы на эти вопросы может дать выполнение работ по проекту системы информационной поддержки инноваций в науке и образовании. Суть проекта – разработка новых методов поиска готовых решений в базе данных центра обработки данных (data centre) и ее пополнения результатами интеллектуального анализа данных Интернета. Пользователи должны иметь возможность визуально оценить найденные решения в совокупности со связанными объектами. Основной инструмент – приложение для мобильных устройств с переносом большей части ресурсоемких вычислений в облачный сервис. Общая архитектура Согласно руководству Microsoft по проектированию структуры приложений (2-е изд., 2009 г.), типовая архитектура ПО включает слои представления, сервисов, бизнес-логики, доступа к данным, а также сквозную функциональность, ко- торые должны обеспечивать взаимодействие пользователей и внешних систем с источниками данных. На рисунке 1 приведена общая архитектура системы с указанием пилотных компонентов (графические элементы – окружности). Обоснование состава пилотных компонентов – реализация полного цикла обработки с ограниченной функциональностью каждого этапа (слоя). Приведем состав пилотных компонентов с кратким описанием их функциональности: 1) пользовательское приложение; 2) графическая визуализация результатов поиска и работы поисковых алгоритмов, семантика связей между объектами; 3) сервисы для поиска и резюмирования решений научно-технических и образовательных задач, имеющих инновационный потенциал; 4) библиотеки классификационных алгоритмов и алгоритмов определения семантически связанных данных; 5) программная реализация модели векторного пространства документов: объектная модель, библиотеки доступа к документной БД, индексатор данных; 6) подсистема мониторинга – учет и анализ посещаемости и цитируемости ресурсов различными категориями пользователей; 7) ресурсы Интернета, специализированные БД; 8) реестр инновационных решений научно-технических и образовательных задач. Архитектура ПО Общее представление функциональности ПО системы показано на рисунке 2. Применена нотация диаграммы использования UML c действующими лицами, вариантами использования, ассоциациями между ними, а также с зависимостями между вариантами использования. Поведение системы в течение конкретного сеанса работы представлено на диаграмме последовательности UML (рис. 3). Изображена последовательность сообщений между взаимодействующими объектами-классификаторами (компонентами и действующими лицами). Отметим два периода активации пользователя: формулировка запроса (начальный шаг) и визуализация результатов, включая получение вариантов запрошенного инновационного решения и связанных объектов (конечный шаг). Промежуточные шаги отражают алгоритмические аспекты взаимодействия компонентов системы.
На диаграмме последовательности не отображен служебный модуль мониторинга, основными функциями которого являются учет и анализ запрашиваемых ресурсов, агентный мониторинг доступных открытых информационных ресурсов для автономного пополнения хранилища и фоновая индексация документов хранилища. Объектная модель На рисунке 4 изображена объектная модель программного обеспечения в виде диаграммы классов UML. Данная объектная модель предназначена для работы с документами, под которыми здесь понимаются любые текстовые объекты, имеющие отношение к предмету обработки: запросы, результаты поиска, текстовые документы. Представлены основные (но не все) используемые сущности, а также ассоциации и зависимости между ними. Кратко прокомментируем элементы модели.
– documents – коллекция документов для обработки; ассоциированный с ним класс TFIDFmeasure обеспечивает вычисление мер сходства документов корпуса; – finder – поисковые функции в корпусе документов; – reports – определяет виды отчетов из базы данных документов; выходные формы задаются классом reportOutput. Класс document описывает конкретный документ. Ассоциированный с ним класс files опре- деляет представление документа в файловой системе. Класс words, также ассоциированный с классом document, определяет коллекцию слов документа, каждое из которых описывается классом word. Лемматизация слов задается классом stemmer.
– divisionList – коллекция описаний составных частей или разделов документа; – paragraphList – коллекция описаний абзацев документа; – structure – описание структуры документа (взаимосвязей между составными частями документа, включая типы связей и их реализацию). Классы tableOfContent и literatureList описывают специфические части документов: оглавление и список литературы соответственно. Реализация и приоритеты Некоторые обсуждаемые компоненты уже реализованы и проходят апробацию в различных приложениях. Так, прототип хранилища данных, построенного с использованием модели векторного пространства документов, а также некоторые ключевые элементы модулей классификации документов и идентификации связей прошли успешную апробацию при реализации смежных технологий интегральной оценки качества электронных документов [6] и анализа сходства документов в различных контекстах [7]. Среди основных приоритетных задач разработки представляется важным отметить разработку унифицированного программного интерфейса доступа к информационным ресурсам и определение методики уточнения запросов и автоматической фильтрации результатов поиска. Кроме того, важное место занимают задачи количественного определения степени пертинентности найденных документов – претендентов на включение в состав искомых инновационных решений, а также алгоритмизации определения семантического ядра – идентификации связей найденных документов с похожими объектами. Литература 1. Байгулов Р.М., Рожкова Е.В. Управление промышленным предприятием: специфика поиска инновационных бизнес-идей // Современные проблемы науки и образования. 2012. № 2. URL: www.science-education.ru/102-5896 (дата обращения: 09.06.2013). 2. Куракова Н.Г., Зинов В.Г. Создание прорывных инноваций на основе комбинации научных заделов мирового уровня как компетенция инновационного менеджмента // Инновации. 2012. № 10. С. 37–42. 3. Российское образование: тенденции и вызовы / Сб. ст. и аналитических докл. М.: Изд-во «Дело» АНХ, 2009. 400 с. 4. Антопольский А., Каленкова А., Каленов Н., Серебряков В., Сотников А. Принципы разработки интегрированной системы для научных библиотек, архивов и музеев // Информационные ресурсы России. 2012. № 1. С. 2–6. 5. Salton G., Wong A., Yang C.S. A Vector Space Model for Automatic Indexing. Communications of the ACM, 1975, vol. 18, no. 11, pp. 613–620. 6. Иванов В.К. Критерии интегральной оценки электронных документов в системах подготовки принятия решений // Вестн. ТГТУ, 2012. Вып. 22. С. 20–26. 7. Иванов В.К., Миронов В.И. Особенности анализа сходства документов в различных контекстах заимствования при подготовке текстовых материалов // Оценка качества высшего профессионального образования с учетом требований ФГОС и профессиональных стандартов: матер. докл. науч.-практич. конф. Тверь, 2013. С. 20–28. References 1. Baygulov R.M., Rozhkova E.V. Sovremennye problemy nauki i obrazovaniya [Modern problems of Education and Science]. 2012, no. 2, available at: www.science-education.ru/102-5896 (accessed 9 June 2013). 2. Kurakova N.G., Zinov V.G. Innovatsii [Innovations], 2012, no. 10, pp. 37–42. 3. Rossiyskoe obrazovanie: tendentsii i vyzovy, Sb. st. i analiticheskikh dokl. [Russian education, proc.]. Moscow, Delo Publ., 2009, 400 p. 4. Antopolskiy A., Kalenkova A., Kalenov N., Serebrya- kov V., Sotnikov A. Informatsionnye resursy Rossii [Russian information resources]. 2012, no. 1, pp. 2–6. 5. Salton G., Wong A., Yang C.S. Communications of the ACM. 1975, vol. 18, no. 11, pp. 613–620. 6. Ivanov V.K. Vestnik Tver. Gos. Tekh. Univ. [Bulletin of Tver State Tech. Univ.]. 2012, vol. 22, pp. 20–26. 7. Ivanov V.K., Mironov V.I. Otsenka kachestva vysshego professionalnogo obrazovaniya s uchetom trebovaniy FGOS i professionalnykh standartov: materialy dokladov nauch.-prakt. konf. [Quality control of highest vocational education adjusted for requirements of FSES and occupational standards: Proc. of research-to-practice Conf.]. Tver, 2013, pp. 20–28. |
 В результате в распоряжении пользователя будет большое количество данных, в той или иной степени релевантных соответствующим запросам. При этом, как правило, у пользователя нет возможности подробно рассмотреть все имеющиеся результаты. Возникают следующие вопросы:
В результате в распоряжении пользователя будет большое количество данных, в той или иной степени релевантных соответствующим запросам. При этом, как правило, у пользователя нет возможности подробно рассмотреть все имеющиеся результаты. Возникают следующие вопросы:

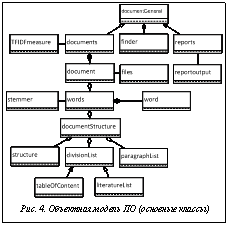 Класс documentStructure определяет структуру документа и порождает классы:
Класс documentStructure определяет структуру документа и порождает классы:| Permanent link: http://swsys.ru/index.php?id=3686&lang=en&page=article |
Print version Full issue in PDF (7.95Mb) Download the cover in PDF (1.45Мб) |
| The article was published in issue no. № 4, 2013 [ pp. 203-208 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Об информационном обеспечении поддержки принятия решений
- Эволюционный алгоритм построения дерева решений
- Организационные проблемы реализации гибких подходов в разработке прикладного программного обеспечения
- Метод поддержки принятия решений по управлению временными аспектами проектов на промышленных предприятиях
- Формирование вариантов развиФормирование вариантов развития энергетики Вьетнама методами комбинаторного моделирования
Back to the list of articles