Journal influence
Bookmark
Next issue
A model for design of ensembles of intelligent information technologies for detecting information security incidents
The article was published in issue no. № 1, 2014 [ pp. 20-25 ]Abstract:The development of effective methods to detect information security incidents is an urgent problem. The im-portance of this problem is determined by current trends in communication in information systems and by security require-ments for such systems. One of the trends is using intelligent information technologies as basic tools for solving this problem. These intelligent information technologies also include artificial neural networks proved their efficiency when solving such problems as classification, modeling and forecasting. Due to the common trends of information systems, the so -called en-semble approaches became more popular for solving data mining problems. They allow processing the information in parallel by several neural networks to obtain more effective solutions. The authors propose to use a three-step evolutionary approach to detect information security incidents. The results of experimental studies of the proposed approach on a KDDCup'99 data set are presented. The paper also considers using individual neural networks in the case of individual classifiers distribution – the so-called ensemble-distributed approach. The authors propose a method for determining cases when the problem to be solved by individual neural network and when the entire ensemble of neural networks is used. Ensemble-distributed method efficiency is tested on the problem of detecting information security incidents. The ways for further studies of the proposed methods are marked.
Аннотация:Разработка эффективных методов обнаружения инцидентов информационной безопасности является актуальной задачей, значимость которой определяется современными тенденциями развития обмена данными в информационных системах и требованиями к их защищенности. Одно из направлений развития этих методов – использование ин-теллектуальных информационных технологий в качестве базового инструмента решения данной задачи. К подобным интеллектуальным технологиям, в частности, относятся искусственные нейронные сети, доказавшие свою эффективность при решении таких задач анализа данных, как классификация, моделирование и прогнозирование. В последнее время, следуя современным тенденциям развития информационных технологий, большую актуальность приобретают так называемые коллективные подходы, позволяющие обрабатывать информацию параллельно сразу несколькими нейронными сетями для получения более эффективных решений. В данной работе для обнаружения инцидентов информационной безопасности предлагается использовать трехступенчатый эволюционный подход, приводятся результаты его экспериментальных исследований на наборе данных KDDCup’99. Рассмотрен также вариант применения коллективов нейронных сетей в случаях распределенной работы индивидуальных классификато-ров – коллективно-распределенный подход. В рамках описываемого подхода предлагается метод определения ситуаций, в которых задача решается индивидуальной нейронной сетью и используется весь пул нейронных сетей. Коллективно-распределенный метод апробирован на задаче обнаружений инцидентов информационной безопасности, проведены исследования влияния перераспределения вычислительной нагрузки на эффективность получаемых решений. Обозначены направления для дальнейшего исследования предлагаемых методов, в том числе в рамках рассматриваемой задачи обнаружения инцидентов информационной безопасности.
| Authors: Bukhtoyarov V.V. (vladber@list.ru) - Academician M.F. Reshetnev Siberian State Aerospace University, Krasnoyarsk, Russia, Ph.D, Zhukov V.G. (vadimzhukov@mail.ru) - Academician M.F. Reshetnev Siberian State Aerospace University, Krasnoyarsk, Russia, Ph.D | |
| Keywords: classification, intrusion detection, problem of allocation, neural network |
|
| Page views: 11702 |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
Система обнаружения вторжений (СОВ) как автоматизированная информационная система обнаружения инцидентов информационной безопасности на сегодняшний день является неотъ- емлемой частью комплексного решения задачи обеспечения информационной безопасности автоматизированных систем с развитой сетевой инфраструктурой. Под СОВ, согласно определению ФСТЭК России, будем понимать программные и программно-аппаратные технические средства, реализующие функции автоматизированного обнаружения в информационных системах действий, направленных на преднамеренный несанкционированный доступ к информации, а также специальных воздействий на информацию в целях ее добывания, уничтожения, искажения или блокирования. В требованиях к средствам защиты данного класса (Профили защиты СОВ, представленные как методические документы ФСТЭК России) указано, что СОВ должна выполнять анализ собранных данных с целью обнаружения вторжений с одновременным использованием как сигнатурных, так и эвристических методов. Среди существующих и активно применяющихся методов наиболее наукоемкими и перспективными для разработки алгоритмического обеспечения эвристических методов анализа данных СОВ являются методы, основанные на интеллектуальных информационных технологиях (ИИТ) – искусственные нейронные сети, нечеткие и нейронечеткие системы, эволюционные алгоритмы, иммунные и многоагентные системы. Анализ практического использования таких ИИТ в составе СОВ, в других задачах информационной безопасности и интеллектуального анализа данных в целом позволяет утверждать, что повышение эффективности использования ИИТ возможно за счет совместного использования в рамках одной системы сразу нескольких ИИТ. Повышение качества решения задач (в смысле выбранных критериев эффективности, например, количества ошибок первого и второго рода) достигается за счет ряда факторов, среди которых можно выделить следующие. · Получение синергетического эффекта от использования сразу нескольких ИИТ (общепринятыми считаются термины «коллектив ИИТ» или «ансамбль ИИТ»). Причем в рамках одного коллектива ИИТ могут быть использованы как однотипные технологии (например, коллектив нейронных сетей), так и ИИТ различных типов. Разработка соответствующих методов для СОВ, отвечающих современным требованиям в плане скорости выработки решений и их качества, остается актуальной научной и исследовательской задачей. · Согласованность схемы распределенного анализа данных и интеграции решений, полученных отдельными ИИТ, и вычислительной архитектуры современных информационных и автоматизированных систем, в которых они реализуются. Коллективный метод обнаружения инцидентов информационной безопасности Несмотря на большое количество исследований в области применения коллективов ИИТ, в частности в СОВ, актуальными с точки зрения повышения эффективности остаются вопросы формирования структуры отдельных ИИТ, настройки их параметров и выбор методов формирования общего решения в коллективах ИИТ.
Далее описаны этапы предлагаемого трехэтапного эволюционного метода формирования коллективного классификатора. Этап 1. Независимо формируется множество классификаторов – пул нейронных сетей, решения которых затем будут участвовать в формировании общего решения. Данный этап является общим для всех коллективных подходов. Для его выполнения в случае использования в качестве классификаторов первого уровня нейронных сетей предлагается применить вероятностный метод для автоматизированного формирования структуры нейронных сетей [2]. В общем же случае может быть использован любой доступный эффективный способ формирования отдельных классификаторов выбранного типа [3, 4]. Этап 2. Независимо друг от друга формируется набор из m классификаторов второго уровня, где m совпадает с числом классов в рассматриваемой задаче. Входами классификаторов этого уровня являются значения, получаемые на выходе классификаторов первого уровня. При этом для каждого j-го классификатора второго уровня, Таким образом, на втором этапе выполняется декомпозиция задачи: каждый классификатор второго уровня формирует в пространстве поверхность, «отсекающую» объекты одного класса от объектов, относящихся к любому другому классу. Для решения этой задачи авторами предлагается использовать метод, основанный на применении гибридного генетического программирования [5] для комбинирования решений отдельных нейронных сетей. Этап 3. Осуществляется агрегация решений классификаторов второго уровня с целью выработки общего решения – значения класса для входного набора. Выбор правила для формирования решения является предметом дальнейших исследований. В рамках предлагаемого подхода авторы использовали следующее простое и при этом очевидное правило: классифицируемый объект относится к тому классу, для которого соответствующий классификатор второго уровня выдал максимальное значение выходного сигнала. Коллективно-распределенный подход к обнаружению инцидентов информационной безопасности При рассмотрении ряда задач, в частности, обнаружения инцидентов информационной безопасности в распределенных системах, актуальным становится вопрос о возможности хотя бы частично решить задачу без проведения расчетов с использованием всех ИИТ, формирующих коллектив, ограничившись лишь применением отдельной технологии (например, построенного с ее помощью классификатора). Такое частичное перераспределение нагрузки в ряде случаев позволило бы сократить время на выработку решения и, возможно, привело бы к снижению нагрузки на пе- редачу информации между отдельными узлами соответствующей вычислительной системы. Для использования подобной схемы должны быть разработаны методы, позволяющие определить, в каких случаях происходит обращение к коллективному классификатору, а в каких используется индивидуальный. Для решения этой задачи предложено использовать коллективно-распределенный подход. В основе предлагаемого подхода лежит следующая модель формирования решения. На первом этапе реализуется решение задачи отдельным индивидуальным представителем ИИТ, входящим в коллектив, но без обращения к коллективу в целом. При этом, помимо собственно расчета решения, вычисляется оценка, которую можно охарактеризовать как степень уверенности (степень доверия) x в том, что полученное решение является верным. Рассчитанное значение x сравнивается с предварительно определенным пороговым значением D. Далее по результатам этого сравнения принимается решение о том, следует ли обратиться к коллективному классификатору для принятия коллективного решения: если x£D, то происходит обращение к коллективному классификатору для выработки общего решения; если x>D, решение рассчитывается индивидуальным представителем ИИТ без обращения к коллективному классификатору. Важным вопросом является определение способа расчета значения степени уверенности x. В данной работе использовалась двухфакторная оценка x, в основе которой лежит учет следующих двух параметров. · Параметр xi – степень уверенности i-го индивидуального классификатора в своем решении (индивидуальная степень уверенности). Очевидно, что для различных типов ИИТ способ определения такой оценки может варьироваться и в некоторых случаях быть затруднительным (например для деревьев решений). Так как в работе рассматриваются коллективы искусственных нейронных сетей, в качестве оценки индивидуальной степени уверенности было предложено использовать уровень сигнала на выходе нейрона, соответствующего классу, к которому индивидуальный классификатор отнес рассматриваемый паттерн. Были рассмотрены два варианта оценки индивидуальной степени уверенности: – оценка формируется без учета значений уровня сигнала на остальных нейронах выходного слоя, то есть
где Si,j – значение сигнала на j-м нейроне выходного слоя i-й нейронной сети (индивидуального классификатора); данный вариант оценки степени индивидуальной уверенности не учитывает возможность формирования достаточно близких по уровню сигналов сразу на нескольких нейронах выходного слоя нейронной сети классификатора; – в качестве альтернативного подхода был предложен второй вариант оценки xi, предполагающий оценку относительного уровня сигнала на выходе нейрона, соответствующего классу, к которому индивидуальный классификатор отнес рассматриваемый паттерн:
Очевидно, что формула (2) эквивалентна формуле (1) при условии, что на всех нейронах выходного слоя, за исключением того, который определяет класс для паттерна, уровень сигнала равен нулю, а на нейроне, определяющем класс, уровень сигнала равен единице. Так как выходные значения нейронов нормированы, значения индивидуальной степени уверенности xi лежат в интервале (0;1]. · Параметр ri – степень доверия i-му индивидуальному классификатору, определяющая его эффективность. В данной работе степень доверия рассматривалась как величина, прямо пропорциональная доле верно классифицированных примеров в тестовой выборке:
где Niв – число примеров из тестовой выборки, верно классифицированных i-м классификатором; Nтв – общее число примеров в тестовой выборке. При таком способе расчета величина ri лежит в интервале [0;1]. Могут быть рассмотрены и другие подходы для оценки степени доверия индивидуальному классификатору, но это направление для дальнейших исследований. Итоговая величина степени доверия рассчитывалась по формуле x=xi×ri. (4) Значения степени доверия лежат в интервале [0; 1]. Предлагаемый подход определения степени доверия не предполагает необходимости проведения дополнительных вычислений, связанных с получением значений в точках выборки для индивидуальных и коллективного классификаторов. Значения ri рассчитываются при формировании коллектива и связаны с подсчетом значения ошибки индивидуальных классификаторов, зна- чения xi при использовании в качестве индиви- дуальных классификаторов нейронных сетей автоматически формируются на выходном слое каждой сети. Таким образом, затраты на дополнительные расчеты можно считать несущественными, что подтверждается оценкой времени работы предлагаемого подхода на тестовых задачах. Для изучения применимости и эффективности представленной выше схемы на тестовых задачах были проведены статистические исследования, в ходе которых рассчитаны оценки, позволяющие эмпирически проверить то, что для задачи обнаружения инцидентов информационной безопасности использование предложенного метода позволяет сократить общее количество обращений к коллективному классификатору, часть примеров решается самостоятельно индивидуальными классификаторами. Очевидно, что на частоту обращения к коллективному классификатору влияет пороговая величина D, с которой сравнивается степень уверенности, рассчитанная по формуле (4). Изменяя эту величину, можно регулировать частоту обращения: чем больше значение D, тем чаще при равных прочих условиях будет происходить обращение к коллективу классификаторов, и наоборот. Выбор способа определения оптимального значения D с точки зрения минимизации ошибки моделирования является предметом дальнейших исследований. При определении порогового значения также могут в некотором виде учитываться и требования к интенсивности информационного обмена между распределенными индивидуальными классификаторами и коллективным классификатором. В данной работе результаты получены при значении D, определенном в ходе предварительного исследования эффективности подхода на рассматриваемых задачах. Статистические исследования эволюционного подхода к формированию коллективов нейронных сетей Для сравнения эффективности предлагаемого подхода с другими известными алгоритмами, применяемыми для решения подобных задач, был проведен ряд дополнительных экспериментов с целью определения эффективности альтернативных подходов на задаче, в основе которой лежит набор данных KDD Cup’99 [6]. Для этого исходный набор данных был разбит на бутстрэп-под- выборки. Для обучения нейронных сетей и настройки их параметров выборка была разбита в следующем соотношении: 67 % записей использовались как обучающая выборка, оставшиеся 33 % – как экзаменующая. Общее количество проведенных запусков для оценки эффективности подходов составило 50. В качестве альтернативных подходов были рассмотрены и реализованы следующие методы: одиночная нейронная сеть с архитектурой многослойный персептрон [7], деревья решений, построенные методом С4.5 [8], байесовский классификатор, алгоритм классификации на основе гиперсфер [9]. Результаты экспериментов приведены в таблице 1. Для оценки статистической значимости результатов были использованы метод ANOVA и критерий Вилкоксона. Использование обоих методов подтвердило статистическую значимость преимущества предлагаемого подхода по критерию минимизации ошибок первого рода. Таблица 1 Результаты статистических исследований эффективности алгоритмов
Традиционный коллективный подход на рассмотренных задачах оказался в среднем не менее эффективным, чем конкурирующие подходы. Для исследования коллективно-распределенного метода обнаружения инцидентов информационной безопасности была проведена серия экспериментов, каждый из которых включал в себя следующие действия. 1. Формирование коллектива нейронных сетей. 2. Подбор порогового значения D, обеспечивающего ошибку коллективно-распределенного классификатора, сходную с ошибкой, полученной при использовании традиционного коллективного метода. При этом пороговое значение 3. Определение распределения вычислительной нагрузки между отдельными классификаторами и коллективным классификатором. Вычислялись относительная частота решения задачи индивидуальным классификатором и соответствующая величина для коллективного классифи- катора. Данные, накопленные в ходе подбора порогового значения D, также позволили оценить промежуточные значения распределения вычислительной нагрузки, соответствующие некоторому ухудшению результатов решения задачи. Результаты серии экспериментов приведены в таблице 2. Предлагаемый коллективно-распределенный подход на рассматриваемой задаче показал статистически неотличимые результаты при условии использования подбора граничного значения D и перераспределения нагрузки в пользу индивидуальных классификаторов на уровне 9 %. Таблица 2 Результаты исследования эффективности коллективно-распределенного подхода
Очевидно, что вопрос настройки (а не подбо- ра) оптимальной величины порогового значения требует дальнейших исследований, в частности, перспективными видятся использование индивидуального порогового значения для каждого отдельного классификатора и применение формализованных алгоритмов определения таких пороговых значений. Необходимо также более детально исследовать общую динамику зависимости ошибки классификации от изменения порогового значения и соответствующее перераспределение вычислительной нагрузки между индивидуальными классификаторами и коллективным. В заключение отметим, что применение эволюционного подхода к формированию коллективов ИИТ на базе искусственных нейронных сетей как эвристического метода анализа СОВ позволяет эффективно решать задачу обнаружения инцидентов информационной безопасности в автоматизированных системах. В целом предлагаемый подход требует дальнейшего развития в плане создания соответствующей среды, позволяющей моделировать функционирование СОВ, основанной на использовании коллективов ИИТ. Кроме того, перспективным для исследования является определение частоты и интенсивности дообучения отдельных ИИТ для вычисления оптимального соотношения вызываемой этим процессом дополнительной нагрузки на сетевую инфраструктуру и вычислительной мощности. Важными представляются исследования на предмет определения оптимального соотношения различных ИИТ в коллективах различного размера, лежащих в основе реально функционирующих СОВ. Литература 1. Kuncheva L.I. Combining Pattern Classifiers. Methods and Algorithms. John Wiley & Sons Publ., NJ, 2004, 300 p. 2. Bukhtoyarov V., Semenkina O. Comprehensive evolutionary approach for neural network ensemble automatic design. Proc. 2010 IEEE World Congress on Computational Intelligence. Barcelona, 2010, pp. 1640–1645. 3. Жуков В.Г. Модель эволюции дифференцированных адаптивных эволюционных систем // Информационные технологии, системный анализ и управление: сб. тр. VIII Всерос. науч. конф. молодых ученых. Таганрог: ЮФУ, 2010. С. 347–355. 4. Жуков В.Г. Автоматизация процесса построения и оптимизации математических моделей эволюционными алгоритмами на основе экспериментальных данных // Вестн. СибГАУ. 2011. Вып. 4 (37). С. 34–39. 5. Жуков В.Г. Дифференцированный адаптивный алгоритм генетического программирования // В мире научных открытий. Красноярск: Науч.-информ. издат. центр. 2012. Вып. 11.5 (35). С. 276–295. 6. Tavallaee M., Bagheri E., Lu Wei, Ghorbani A.A. A detailed analysis of the KDD CUP 99 data set. Proc. of the 2nd IEEE Symp. on Computational Intelligence for Security and Defence Applications, 2009. 7. Haykin S. Neural networks: a comprehensive foundation. Prentice Hall PTR, 1994. 8. Quinlan J.R. C4.5: programs for machine learning. Morgan Kaufmann Publ., 1993, vol. 1, 302 p. 9. Ong Y.S., Lim M.H., Zhu N., Wong K.W. Classification of adaptive memetic algorithms: a comparative study. Systems, Man, and Cybernetics, Part B: Cybernetics, IEEE Transactions on. 2006, vol. 36, no. 1, pp. 141–152. References 1. Kuncheva L.I. Combining Pattern Classifiers. Methods and Algorithms. John Wiley & Sons Publ., Hoboken, NJ, 2004, 300 p. 2. Bukhtoyarov V., Semenkina O. Comprehensive evolutionary approach for neural network ensemble automatic design. Proc. of 2010 IEEE World Congress on Computational Intelligence. Barcelona, 2010, pp. 1640–1645. 3. Zhukov V.G. An evolution model for differentiated adaptive evolutionary systems. Sbornik trudov VIII Vserossiyskoy nauch. konf. molodykh uchenykh “Informatsionnye tekhnologii, sistemnyy analiz i upravlenie” [Proc. of the 8th All-Russian confe. of young scientists “Information technologies, system analysis and control”]. Taganrog, Southern Fed. Univ. Publ., 2010, pp. 347–355 (in Russ.). 4. Zhukov V.G. An automation of the process of composition and optimization of mathematical models using evolutionary algorithms based on experimental data. Vestnik SibGAU [Bulletin of SibSAU]. Krasnojarsk, Siberian State Aerospace Univ. Publ., 2011, vol. 37, iss. 4, pp. 34–39 (in Russ.). 5. Zhukov V.G. A differentiated adaptive algorithm of genetic programming. V mire nauchnykh otkrytiy [In the World of Scientific Discoveries]. Krasnojarsk, Publ. House Science and Innovation Center, 2012, vol. 5, iss. 11, pp. 276–295 (in Russ.). 6. Tavallaee M., Bagheri E., Lu Wei, Ghorbani A.A. A detailed analysis of the KDD CUP 99 data set. Proc. of the 2nd IEEE Symp. on Computational Intelligence for Security and Defence Applications, 2009. 7. Haykin S. Neural networks: a comprehensive foundation. Prentice Hall PTR, 1994, 716 p. 8. Quinlan J.R. C4.5: programs for machine learning. Morgan Kaufmann Publ., San Francisco, CA, 1993, vol. 1, 302 p. 9. Ong, Y.S., Lim M.H., Zhu N., Wong K.W. Classification of adaptive memetic algorithms: A comparative study. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cyber- netics. 2006, vol. 36, iss. 1, pp. 141–152. | ||||||||||||||||||||||||||||||||||||||||||||

 , обучение выполняется по следующему правилу: целевым значением на выходе классификатора для всех примеров, соответствующих классу с номером j, является единица; для всех остальных примеров целевым значением выхода классификатора j является ноль.
, обучение выполняется по следующему правилу: целевым значением на выходе классификатора для всех примеров, соответствующих классу с номером j, является единица; для всех остальных примеров целевым значением выхода классификатора j является ноль. , (1)
, (1) . (2)
. (2) , (3)
, (3)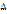 было не индивидуальным, а общим для всего коллектива нейронных сетей, но полученные значения различались в каждом эксперименте (для каждого коллектива) – это не позволило в целом оценить влияние конкретных значений D на качество решения задачи.
было не индивидуальным, а общим для всего коллектива нейронных сетей, но полученные значения различались в каждом эксперименте (для каждого коллектива) – это не позволило в целом оценить влияние конкретных значений D на качество решения задачи.| Permanent link: http://swsys.ru/index.php?id=3752&lang=en&page=article |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
| The article was published in issue no. № 1, 2014 [ pp. 20-25 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Разработка базы данных и конвертера для извлечения и анализа специализированных данных, получаемых с медицинского аппарата
- Многофункциональный имитатор нейронных сетей
- Комплекс программного обеспечения для оптимизации надежности однородных нейронных структур
- Разработка программного комплекса адаптивного нейропрогнозирования
- Метод адаптивной классификации изображений с использованием обучения с подкреплением
Back to the list of articles