Journal influence
Bookmark
Next issue
The modified query processing model in distributed databases
The article was published in issue no. № 1, 2014 [ pp. 70-76 ]Abstract:The authors research the methods to remove inconsistencies between the need to support a current status of distributed database components with real-time replication and limited bandwidth capacity of telecommunication subsystem. The actuality of efficiency increasing of distributed database under conditions of limited telecommunication subsystem ca-pacity is explained. Existing approaches to mathematical modeling of information exchange in distributed databases in a rep-lication mode are presented. They are based on the finite automata theory, the theory of probability and the queueing theo-ry.Local and remote query processing procedures are shown in detail as well as different characteristics of distributed data-base replica fragment. The model using the characteristics of replica's fragment is proposed. The characteristics are listed. The possibility of queuing theory and renewal theory usage in query processing modeling in distributed databases is consid-ered. The adequacy estimation for developed model in the case of using in mining enterprises is given. The scope of proposed model is shown.
Аннотация:Работа посвящена изысканию способов снятия противоречия между необходимостью поддержания фрагментов распределенной базы данных в актуальном состоянии путем репликации в режиме реального времени и ограниченным ресурсом пропускной способности телекоммуникационной подсистемы, обусловливающей применимость отложенной репликации. Рассматриваются существующие подходы к математическому моделированию информационного обмена в распределенных базах данных при репликации, основанные на аппарате теории конечных автоматов, теории вероятностей и теории массового обслуживания. Подробно описан процесс обслуживания запросов в рамках обработки по локальному и удаленному циклам. Представлено описание различных характеристик фрагментов реплики распределенной базы данных. Предложена модель, отличающаяся применением дифференцированного подхода к обслуживанию фрагментов реплики. Обоснована применимость математического аппарата теории восстановления в рамках альтернирующих процессов и теории массового обслуживания в рамках эгоистических распределительных алгоритмов для построения математической модели обслуживания запросов в распределенной базе данных. Представлена оценка адекватности заявленной модели на примере распределенной базы данных предприятия горнопромышленного комплекса. Описана область применимости полученной модели.
| Authors: Tarakanov O.V. (dunaev-ktn@yandex.ru) - Academy of the Federal Guard Service of the Russian Federation, Orel, Russia, Ph.D, Dunaev V.A. (dunaev-ktn@yandex.ru) - Academy of the Federal Guard Service of the Russian Federation, Orel, Russia | |
| Keywords: queuing theory, replica, priority, reactivity distributed database, mathematical model, replication, information exchange, distributed database |
|
| Page views: 11624 |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
Типовую распределенную БД (РБД) можно представить совокупностью N серверов, объединенных телекоммуникационной подсистемой (ТКС), и совокупностью M групп рабочих станций (РС), соединенных с серверами средствами ТКС. Каждая группа РС имеет прямое соединение только с одним сервером РБД (локальным относительно группы РС). ТКС предназначена для организации логических каналов между точками логического подключения серверов РБД. Одной из наиболее ресурсоемких и в то же время достаточно распространенных технологий хранения и обработки данных является технология РБД. Узлы РБД порождают высокую нагрузку на ТКС при выполнении удаленных запросов и репликации данных. Часто информационный обмен выполняется с нарушением заявленных требований к характеристикам РБД. По оценкам зарубежных аналитических агентств, ежегодный рост телетрафика во всем мире составляет около 30 %, а сети магистральных операторов загружены в среднем на 60–80 %, и многим требуется значительное расширение. По прогнозам, в любой момент в телекоммуникационной отрасли может наступить глобальный кризис в связи с недостаточной пропускной способностью каналов [1]. Для оценки эффективности процесса обработки запросов в РБД выделяются ее существенные свойства и по ним оцениваются результаты выполнения запросов. Оценивание соответствия результатов функционирования РБД требованиям проводится по частным показателям эффективности для каждого свойства. Проведение оценки относительно полного вектора показателей затруднено (отсутствие обоснованного критериального и сверточного аппаратов), поэтому на практике, как правило, ограничиваются отысканием значений показателей эффективности по наиболее значимому свойству [2]. В исследованиях [2–4], посвященных вопросам функционирования РБД, обосновывается выбор системы свойств РБД: – целостность РБД – способность данных в РБД сохранять однозначность и информационное содержание; – полнота РБД – возможность выборки из РБД необходимого количества информации; – достоверность – степень соответствия данных из РБД реальному состоянию объектов предметной области; – реактивность – способность в среднем выполнять запросы за время, не превышающее декларативное; – защищенность – способность РБД сохранять информацию в неизменном виде при воздействиях различного характера. Поскольку РБД разрабатываются и внедряются с целью повышения оперативности решения задач в информационных системах, доминирующим свойством РБД признают реактивность [2]. Объектом настоящего исследования является процесс информационного обмена между узлами данных РБД в режиме репликации, который рассматривается на предмет влияния механизмов репликации на реактивность РБД. Требования к качеству обслуживания запросов в РБД Согласно приказу Минкомсвязи России № 221 от 2 сентября 2011 года, рекомендованное время доступа к системе электронного документооборота федеральных органов исполнительной власти не должно превышать трех секунд. В работе [5] приводится обоснование наиболее удобного для пользователей с эргономической точки зрения временного интервала отклика информационных систем: две–четыре секунды. Данные рекомендации распространяются на распределенные системы. Таким образом, рекомендованным временем отклика РБД на запросы можно принять время в диапазоне от двух до трех секунд. При функционировании РБД основная нагрузка на ТКС создается реплицируемыми данными и удаленным взаимодействием при обслуживании запросов. Однако с учетом алгоритмов оптимального размещения данных по удаленным (относительно группы РС) серверам РБД доля удаленных запросов среди всего множества запросов пользователей минимальна. Основная нагрузка на ТКС создается процессом репликации. В случаях, когда интенсивность обновления данных в распределенной системе велика, а доступная пропускная способность относительно мала, возможны ситуации возникновения дефицита пропускной способности сети и ухудшения реактивности РБД. Обоснование выбора вида модели для решения задачи повышения эффективности функционирования РБД Существует множество подходов к моделированию процессов в РБД, однако они имеют недостатки, сужающие область их применения. Так, в [6] для построения математических моделей информационных процессов в РБД применяется математический аппарат теории конечных автоматов. При этом модель процесса информационного обмена в РБД представляется конечным авто- матом, который в любой момент времени t находится в некотором состоянии S(t)={s1, s2, s3}, где состояние s1 – данные отправляются, состояние s2 – данные принимаются, состояние s3 – система ожидает сеанса связи. При наступлении определенных событий (к примеру, поступление запроса на обновление данных) состояние РБД изменяется. Свойства информационного процесса в зависимости от состояний конечного автомата определяются системой
где D – автомат является отправителем; R – автомат является получателем; O – автомат не является ни отправителем, ни получателем. Основное достоинство модели – простота описания объекта моделирования. При этом в модели отсутствует возможность учета вероятностно-временных характеристик процессов, протекающих в РБД. Другой подход для математического описания функционирования РБД рассмотрен в работе [7] в рамках теории вероятностей и теории массового обслуживания. РБД представляется как совокупность некоторого множества независимых файлов с заданными на них подмножествами запросов на обновление и получение данных. При этом объемы порождаемых в ТКС данных зависят от узлов-источников. В каждую единицу времени по ТКС пересылается некоторый объем данных, связанный с распределением копий файлов по РБД:
где n – количество узлов РБД; m – количество файлов РБД; lij – интенсивность запросов к i-му файлу в j-м узле; Vij – объем пересылаемых данных при запросе к i-му файлу в j-м узле; l – суммарная интенсивность запросов по всем узлам и файлам РБД (аддитивная свертка). Данная модель описывает транзакционные особенности запросов и не учитывает влияние на реактивность РБД характеристик ТКС и особенностей репликации данных. Наиболее полно процесс обработки запросов в РБД исследован в [8]. Так, обработка запросов в РБД описывается в рамках обслуживания заявок в стохастической сети массового обслуживания (СеМО). При этом системы массового обслуживания (СМО), составляющие СеМО, интерпретируются типовыми элементами РБД: фрагментами сети доступа (СМО 1-го типа), серверами РБД (СМО 2-го типа), каналами передачи данных (СМО 3-го типа), коммуникационным оборудованием (СМО 4-го типа). В качестве источников заявок выступают поисковые запросы к локальным серверам РБД от групп РС. Модель обработки запросов к РБД описывается функционалом t=F(V, T, S, L), (3) где t – время выполнения запроса в РБД; V – объемные характеристики РБД; Т – характеристики технических средств в РБД; S – характеристи- ки структуры РБД; L – характеристики информационных потоков сети. При этом объемные характеристики РБД V (размеры запросов, размеры откликов, количество копий данных, размер копий данных и др.), характеристики технических средств в РБД Т (производительность серверов, доступная пропускная способность каналов передачи данных, размеры буферов в коммуникационном оборудовании, доступное количество памяти на серверах и др.) учитываются при моделировании СМО всех четырех типов (рис. 1). Характеристики структуры РБД S (топология сети для РБД, количество серверов РБД, распределение пользователей по рабочим станциям и по серверам РБД и др.) используются при построении СеМО в целом, определяя очередность обслуживания заявок для СМО. Характеристики информационных потоков в сети L (интенсивности поступления поисковых запросов и запросов на обновление и др.) описывают параметры источников заявок в СеМО. При этом особенности различных режимов репликации и влияние процесса репликации на реактивность РБД в такой модели остаются без внимания несмотря на то, что процесс репликации порождает существенную нагрузку на ТКС РБД и существенно влияет на реактивность РБД. Формальное описание процесса обслуживания запросов пользователей к РБД
На рисунках 1 и 2 представлен процесс обслуживания запросов к РБД во временной области, состоящий из двух циклов обслуживания – локального и удаленного. Локальный цикл обслуживания включает этапы 1–3, где этап 1 определяется промежутком времени, затрачиваемым на передачу запроса к локальному серверу РБД по сети доступа, этап 2 характеризуется временем обработки запроса на локальном сервере РБД, этап 3 определяется временем передачи ответа локального сервера по сети доступа. Удаленный цикл обслуживания, помимо этапов локального цикла, включает этапы 4–8, где этап 4 характеризуется временем ожидания освобождения канала для передачи запроса на удаленный сервер, этап 5 определяется промежутком времени на передачу удаленного запроса по ТКС, этап 6 определяется временем обработки запроса удаленным сервером РБД, этап 7 характеризуется промежутком времени, затрачиваемым на удаленную пересылку ответа на запрос, этап 8 представляет собой обновление данных на локальном узле. В процессе функционирования РБД по мере поступления заявок на обновление данных копии данных (реплики) теряют свою актуальность. Если запрос на выборку данных попадает в промежуток времени, когда данные в локальном узле РБД неактуальны (состояние «2»), то он передается на удаленный сервер с актуальными данными. После этого происходит передача копии актуального фрагмента реплики с удаленного сервера РБД на локальный с ее последующей фиксацией. На практике процесс репликации организуется в режиме реального времени или в отложенном режиме. В режиме реального времени серве- ры РБД порождают существенную нагрузку на ТКС РБД и в итоге ухудшают реактивность РБД. При организации репликации средствами отложенной репликации нагрузка на ТКС минимальна, однако вероятность попадания запросов в неактуальные данные относительно велика, что также негативно влияет на реактивность РБД, так как для получения актуальных данных запрос часто обслуживается по удаленному циклу. Таким образом, длительность обслуживания запросов к РБД напрямую зависит от выбранного режима репликации. Важно отметить, что различные фрагменты реплики отличаются значениями характеристик: – интенсивность поисковых запросов к r-му фрагменту реплики на n-м узле lr,n, где rÎ{1, ..., R}, а nÎ{1, ..., N}; – интенсивность поступления заявок на обновление – размер r-го фрагмента реплики Cr, где rÎ{1, …, R}.
Обоснование выбора методологического аппарата для моделирования информационных процессов в РБД с учетом влияния репликации Исследование существующих математических моделей обслуживания запросов в РБД выявило отсутствие учета в моделях влияния процессов репликации на реактивность РБД. Требуется обосновать выбор методологического аппарата, позволяющего модифицировать модель обработки запросов в РБД [8] с учетом влияния процессов репликации на ее реактивность. В результате обследования ряда РБД обнаружена аналогия между репликацией и процессами в системах коллективного пользования с множественным доступом [9]. С другой стороны, процесс информационного обмена в РБД с учетом влияния репликации на реактивность РБД удобно представить на основе математического аппарата теории восстановления в рамках альтернирующих процессов [10]. Сформулированы три гипотезы, требующие проверки. Гипотеза H0 – применимость класса алгоритмов случайного множественного доступа к среде передачи данных для построения модели обработки запросов в РБД с учетом влияния процесса репликации на ее реактивность. Гипотеза H1 – применимость аппарата теории восстановления в рамках альтернирующих процессов для построения модели обработки запросов в РБД с учетом влияния процесса репликации на ее реактивность. Альтернативная гипотеза H2 – несостоятельность H0 и H1. В процессе репликации РБД фрагменты реплик конкурируют за общий ресурс ТКС, что соответствует конкуренции пользователей за общий ресурс в рамках класса алгоритмов случайного множественного доступа к среде передачи данных. При этом дифференцировать обслуживание различных фрагментов реплики удобно введением приоритетов обслуживания требований на репликацию (рис. 3). В простейшем случае модель обслуживания фрагментов реплики в РБД основывается на характеристиках: A(t) – функция распределения промежутков времени между поступающими требованиями на передачу реплик; B(x) – функция распределения требуемого времени обслуживания реплик; qp – квант времени, предоставляемый для обслуживания требования в зависимости от его приоритета. В существующих РБД все фрагменты реплик имеют одинаковый приоритет обслуживания. Применение данной модели позволяет определять плотность распределения вероятности обслуживания реплик в рамках заданных требований P(x£xtr) и среднее время ответа системы T(x). К примеру, для системы M/G/1 среднее время ответа РБД при поступлении запроса на репликацию определяется выражением:
где W0 – среднее время ожидания требований в очереди; r – коэффициент использования обслуживающего прибора; x – заданное время обслуживания требований [9]. Данная модель не учитывает возможности ТКС по пропускной способности. Для этого необходимо дополнить рассматриваемую модель блоком очередей, который позволит вносить необходимые задержки в обслуживание запросов в соответствии с доступными ресурсами. Такие задержки позволят обслуживать запросы с более высоким приоритетом, не перегружая ТКС. Достигается это за счет того, что в блоке обслуживания одновременно находится только часть требований с высшим приоритетом. При этом требования в блоке очередей имеют динамический приоритет, который со временем возрастает, что исключает монополизацию ТКС обслуживанием однотипных запросов (рис. 4). Такие модели строятся на основе класса эгоистичных распределительных алгоритмов [9], а выражение для определения среднего времени ответа системы принимает вид
Основная сложность при этом – выбор значений приоритетов требований с учетом влияния на реактивность РБД в условиях ограниченной доступной пропускной способности ТКС. Данная задача решается в рамках теории восстановления. При этом фрагменты реплик могут находиться в двух состояниях: состояние «1» – данные актуальны, состояние «2» – данные неактуальны. Состояние «1» определяется режимами и условиями проведения репликации. Состояние «2» зависит от потока заявок на обновление данных в узлах РБД. Состояния «1» и «2» статистически независимы, что позволяет применять модели альтернирующих процессов теории восстановления для анализа информационного обмена при репликации в РБД. Применение таких моделей дает возможность оценить вероятность пребывания фрагментов реплики в различных состояниях pi(t) в заданные моменты времени t. К примеру, для случая, когда периоды пребывания фрагментов реплики в состояниях «1» и «2» распределены по показательному закону с параметрами r1 и r2 соответственно, вероятность нахождения фрагмента реплики в состоянии «1» в заданный момент времени t определяется на основе выражения [10]
Очевидно, что, чем меньше вероятность нахождения фрагмента реплики в состоянии «1», тем выше вероятность попадания поискового запроса в неактуальные данные и, как следствие, тем выше вероятность выполнения запроса по удаленному циклу. В результате можно утверждать об истинности гипотез H0 и H1.
Оценка результатов моделирования проводилась для РБД горнопромышленного комплекса ООО «ШахтИнвестКузбасс» (г. Кемерово). Анализ показал, что применение модифицированной модели обработки запросов в РБД имеет ряд практических преимуществ по сравнению с существующими моделями. Так, применение модифицированной модели обработки запросов в РБД на этапах проектирования, внедрения и функционирования позволяет учитывать возможности ТКС по пропускной способности и принимать обоснованные решения по выбору параметров репликации для повышения реактивности РБД. Адекватность предложенной модели предметной области подтверждается – корректным использованием известного математического аппарата теории восстановления в рамках альтернирующих процессов и теории массового обслуживания в рамках эгоистических распределительных алгоритмов; – строгим учетом существенных факторов, влияющих на обработку запросов в РБД; – непротиворечивостью результатов, полученных на основе разработанной модели. Результаты моделирования для РБД горнопромышленного комплекса приведены на рисунке 5, где h=[0, 1] – параметр, определяющий размеры реплицируемых данных в зависимости от выбранного режима репликации и доступной пропускной способности ТКС. При h=0 данные не реплицируются, а при h=1 РБД реплицируется полностью. Из рисунка 5 видно, что применение заявленной модифицированной модели позволяет определить параметры репликации РБД при заданных ограничениях на пропускную способность ТКС, обеспечивающие минимизацию среднего времени отклика РБД и повышение реактивности РБД в целом. Практическое применение данной модели для улучшения реактивности РБД возможно на основе алгоритма выбора значений параметров репликации данных в РБД, реализованного программно, что подтверждается свидетельством о госрегистрации программ для ЭВМ № 2013611771 от 04.02.2013 г. (авторы: О.Ю. Миронов, В.А. Дунаев, Н.В. Покусин, Д.О. Кривошея).
Научная новизна полученного результата в том, что заявленная модифицированная модель обработки запросов в РБД, базирующаяся на методах теории восстановления и множественного доступа, отличается новым дифференцированным подходом к обслуживанию требований на репликацию на основе приоритетов, позволяющим учитывать влияние процессов репликации на реактивность РБД. Данное исследование направлено на разработку новых алгоритмов, способствующих улучшению реактивности РБД. Литература 1. Соколов И.А., Босов А.В., Будзко В.И. Информатика: состояние, проблемы, перспективы. М.: ИПИ РАН, 2009. 46 с. 2. Иванов А.Ю. Обеспечение выполнения требований к информационным системам МЧС России на основе структурной адаптации распределенных баз данных // Вестн. Санкт-Петербургского ин-та ГПС МЧС России. 2005. № 3 (10). С. 41–46. 3. Таненбаум Э. Распределенные системы. Принципы и парадигмы. СПб: Питер, 2003. 877 с. 4. Кульба В.В. Теоретические основы проектирования оптимальных структур распределенных баз данных. М.: СИНТЕГ, 1990. 660 с. 5. Губинский А.И., Евграфова В.Г. Информационно-управляющие человеко-машинные системы. Исследование, проектирование, испытания: справочник. М.: Машиностроение, 1993. 528 с. 6. Апанасевич Д.А. Модели данных и структурная модель системы асинхронной репликации с выделением объектов // Вестн. Воронежского гос. тех. ун-та. 2008. № 6. С. 78–79. 7. Коннолли Т., Бегг К., Страчан А. Базы данных. Проектирование, реализация и сопровождение. 3-е изд.; [пер. с англ.]. М.: Вильямс, 2003. 1440 с. 8. Иванов А.Ю. Модель для оценки оперативности реализации запросов к распределенным базам данных // Проблемы управления рисками в техносфере. 2008. № 4 (8). C. 176–183. 9. Клейнрок Л. Вычислительные системы с очередями. М.: Мир, 1979. 600 с. 10. Кокс Д., Смит В. Теория восстановлений; [пер. с англ.; под ред. Ю.К. Бедяева]. М.: Сов. радио, 1967. 298 с. References 1. Sokolov I.A., Bosov A.V., Budzko V.I. Informatika: sostoyanie, problemy, perspektivy [Computer science: status, problems, prospects]. Moscow, IPI RAN Publ., 2009, 46 p. 2. Ivanov A.Yu. Information systems enforcement for EMERCOM of Russia based on structure customizing distributed databases. Vestnik Sankt-Peterburgskogo Universiteta GPS MChS Rossii [Bulletin of St. Petersburg University of State Fire Service of EMERCOM of Russia]. St. Petersburg, 2005, no. 3 (10), pp. 41–46 (in Russ.). 3. Tanenbaum E. Raspredelyonnye sistemy. Printsipy i paradigmy [Distributed systems. Principles and Paradigms]. St. Petersburg, Piter Publ., 2003, 877 p. 4. Kulba V.V. Teoreticheskie osnovy proektirovaniya optimalnykh struktur raspredelyonnykh baz dannykh [Theoretical basics of designing optimal structures for distributed databases]. Moscow, SINTEG Publ., 1990, 660 p. 5. Gubinskiy A.I., Evgrafova V.G. Informatsionno-upravlyayushchie cheloveko-mashinnye sistemy. Issledovanie, proektirovanie, ispytaniya [Information and control man-machine systems. Research, design, testing]. Moscow, Mashinostroenie Publ., 1993, 528 p. 6. Apanasevich D.A. Data models and structure model for an asynchronous replication system with objects selection. Vestn. Voronezhskogo gos. tekh. un-ta [Bulletin of Voronezh State Technical Univ.]. Voronezh, 2008, no. 6, pp. 78–79 (in Russ.). 7. Connolly T., Begg K., Strachan A. Database Systems: a practical approach to design, implementation and management. Addison Wesley Publ., 2nd ed., 1999. 8. Ivanov A.Yu. A model for query efficiency estimation in distributed databases. Problemy upravleniya riskami v tekhnosfere [Problems of risk management in the technosphere]. St. Petersburg univ. of State Fire Service of EMERCOM of Russia Publ., 2008, no. 4, pp. 176–183. 9. Kleinrock L. Queueing Systems. Wiley Interscience Publ., 1975, vol. I: Theory, 448 p. 10. Cox D.R., Smith W. Queues. Methuen, London, 1961, 180 p. |
 (1)
(1) , (2)
, (2) Для построения математической модели, учитывающей влияние процесса репликации на реактивность РБД, рассмотрим фрагмент РБД, содержащий два сервера, имеющих логическое соединение между собой.
Для построения математической модели, учитывающей влияние процесса репликации на реактивность РБД, рассмотрим фрагмент РБД, содержащий два сервера, имеющих логическое соединение между собой. во всей РБД, где rÎ{1, ..., R};
во всей РБД, где rÎ{1, ..., R}; Эти отличия оказывают непосредственное влияние на величину задержки, вносимой в реактивность РБД при обслуживании запросов к различным фрагментам реплики. В связи с этим необходим дифференцированный подход к обслуживанию различных фрагментов реплики, позволяющий обслуживать в первую очередь фрагменты, вносящие наибольшую составляющую в реактивность РБД.
Эти отличия оказывают непосредственное влияние на величину задержки, вносимой в реактивность РБД при обслуживании запросов к различным фрагментам реплики. В связи с этим необходим дифференцированный подход к обслуживанию различных фрагментов реплики, позволяющий обслуживать в первую очередь фрагменты, вносящие наибольшую составляющую в реактивность РБД. , (4)
, (4) , (5)
, (5) где l – интенсивность входящего потока в блок очереди; l¢ – интенсивность входящего потока в блок обслуживания; r – коэффициент использования блока очереди; r¢ – коэффициент исполь- зования блока обслуживания;
где l – интенсивность входящего потока в блок очереди; l¢ – интенсивность входящего потока в блок обслуживания; r – коэффициент использования блока очереди; r¢ – коэффициент исполь- зования блока обслуживания;  – второй момент распределения времени обслуживания требования;
– второй момент распределения времени обслуживания требования; 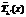 – условное среднее время ответа для блока обслуживания.
– условное среднее время ответа для блока обслуживания. . (6)
. (6) Результаты применения модифицированной модели обработки запросов в РБД
Результаты применения модифицированной модели обработки запросов в РБД На основании изложенного можно сделать следующие выводы. Существует задача минимизации среднего времени ответа РБД на запросы за счет выбора параметров обслуживания фрагментов реплики (приоритеты, параметры очереди в блоке обслуживания) в зависимости от доступной пропускной способности сети. Решение данной задачи возможно с помощью математических моделей процессов обслуживания запросов в РБД. Построение моделей целесообразно на основе математического аппарата теории восстановления в рамках альтернирующих процессов и аппарата теории массового обслуживания в рамках множественного доступа для эгоистических распределительных алгоритмов. Таким образом, заявленная модифицированная модель обработки запросов в РБД пригодна для решения задачи повышения эффективности репликации в РБД по свойству реактивности.
На основании изложенного можно сделать следующие выводы. Существует задача минимизации среднего времени ответа РБД на запросы за счет выбора параметров обслуживания фрагментов реплики (приоритеты, параметры очереди в блоке обслуживания) в зависимости от доступной пропускной способности сети. Решение данной задачи возможно с помощью математических моделей процессов обслуживания запросов в РБД. Построение моделей целесообразно на основе математического аппарата теории восстановления в рамках альтернирующих процессов и аппарата теории массового обслуживания в рамках множественного доступа для эгоистических распределительных алгоритмов. Таким образом, заявленная модифицированная модель обработки запросов в РБД пригодна для решения задачи повышения эффективности репликации в РБД по свойству реактивности.| Permanent link: http://swsys.ru/index.php?id=3761&lang=en&page=article |
Print version Full issue in PDF (7.83Mb) Download the cover in PDF (1.01Мб) |
| The article was published in issue no. № 1, 2014 [ pp. 70-76 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Организация информационного обмена в сложных распределенных системах
- Вопросы создания АСУ космическими полетами беспилотных аппаратов в околоземном пространстве
- Разработка численной схемы стекловаренной печи
- Комплекс программ для определения параметров электрических дуг трехфазного переменного тока, горящих на горизонтальную поверхность
- Алгоритм и программная реализация синтеза модели объекта испытаний на основе решения уравнения непараметрической идентификации
Back to the list of articles