Journal influence
Bookmark
Next issue
Double-layer vector perceptron for binary pattern recognition
Abstract:A new model of neural network, Double-Layer Vector Perceptron (DLVP), to solve nearest neighbor search problem, is proposed. The problem of single-layer perceptron, when error of the even one output neuron leads to fail of all network, is solved. DLVP is improved single-layer perceptron with additional layer, which accumulates information. As result, it is possible to right recognize even if all middle layer neurons are fail, i.e. neural networks with ‘weak’ neurons can be built. The model was compared with a single-layer vector perceptron. This comparison showed that though its operation requires slightly more computations (by 5 %) and more effective computer memory, double-layer vector perceptron excels at a much lower error rate (four orders of magnitude lower). We obtained the estimate of DLVP storage capacity and analyzed its properties. During this analysis we found out that the model has one more useful property, which single -layer vector perceptron does not have, i.e. using the proposed model we can effectively solve k nearest neighbors search problem.
Аннотация:Для решения задачи поиска ближайшего соседа в конфигурационном пространстве предложена новая модель нейронной сети – двухслойный векторный персептрон (Double-Layer Vector Perceptron, сокращенно DLVP). Она позволила решить проблему однослойного персептрона, заключающуюся в том, что ошибка даже одного выходного нейрона приводит к ошибочному распознаванию сети в целом. Предложенная модель является развитием однослойного векторного персептрона: добавлен дополнительный слой, аккумулирующий информацию. В результате стало возможным корректное распознавание даже в том случае, когда все нейроны внутреннего слоя ошибаются, то есть строить нейронные сети на «слабых» нейронах. Было проведено сравнение данной модели с однослойным персептроном. Разработанная модель значительно превосходит однослойный векторный персептрон в качестве распознавания (понижение ошибки распознавания на четыре порядка и более) ценой незначительного увеличения вычисли-тельной сложности (на 5 %) и требований оперативной памяти. Был проведен анализ свойств и получена теоретическая оценка емкости памяти предложенной модели. В ходе анализа выяснилось, что эта модель обладает еще одним полезным свойством, которого нет у однослойной модели, а именно: с ее помощью можно решать задачу поиска k ближайших соседей.
| Authors: Kryzhanovsky V.M. (vladimir.krizhanovsky@gmail.com) - Center of Optical Neural Technologies, SRISA RAS, Moscow, Russia, Ph.D, Malsagov M.Yu. (magomed.malsagov@gmail.com) - Center of Optical Neural Technologies, SRISA RAS, Moscow, Russia, Ph.D, Zhelavskaya I.S. (irina.zhelavskaya@skolkovotech.ru) - Skolkovo Institute of Science and Technology, Moscow, Russia | |
| Keywords: neural network, vector neural networks, potts model, binary pattern recognition |
|
| Page views: 15610 |
Print version Full issue in PDF (6.61Mb) Download the cover in PDF (0.95Мб) |
Первой и наиболее известной векторной нейронной сетью (НС) является модель Поттса [1–5]. Эта модель по-прежнему исследуется учеными из таких различных областей, как физика, медицина, сегментация изображений и НС. Позже была предложена модель параметрической НС [6], всесторонне исследованная небольшим коллективом Института оптико-нейронных технологий РАН (сейчас ЦОНТ НИИСИ РАН). Похожая модель (CMM) была независимо разработана и продолжает исследоваться в Йоркском университете, Канада [7]. В работе [5] представлена модель векторной НС с мерой близости между состояниями нейронов. Эта модель обобщила все перечисленные модели. Исследователями рассматривались как полносвязные, так и персептронные архитектуры. Были изучены различные правила обучения векторных сетей [9]. Полученные результаты говорят об их высокой эффективности.
Для практических приложений, требующих реализации ассоциативной памяти, более всего подходят персептроны (в нашем случае речь идет о векторных персептронах). Однако они имеют существенный недостаток: достаточно даже одному выходному нейрону переключиться в неправильное состояние, чтобы входной вектор был идентифицирован неверно. Для борьбы с этим приходится повышать надежность каждого нейрона путем повышения избыточности НС либо уменьшения загрузки сети. Иначе можно сказать, что векторный персептрон состоит из «надежных» нейронов, которым нельзя ошибаться, а это противоречит всей идеологии НС. Альтернативный подход заключается в применении «слабых» нейронов (weak-neurons). При равных затратах оперативной памяти совокупность «слабых» нейронов оказывается эффективнее небольшого числа «надежных» нейронов. Смысл в том, чтобы оснастить векторный персептрон дополнительным слоем из одного нейрона, количество состояний которого равно количеству запомненных образов. Его задача заключается в накоплении информации от предыдущего слоя и непосредственной идентификации входного образа. К предложенной идее близка идея, изложенная в работах [10, 11]. Данная статья содержит формальное описание модели, качественное описание, в котором сделана попытка на простом примере показать суть предлагаемого нововведения, и экспериментальные результаты. Авторы решают задачу поиска ближайшего соседа, которая заключается в следующем. Пусть имеется набор M биполярных паттернов размерности N: XmÎRN, xmiÎ{±1}, mÎ Биполярный вектор X подается на входы сети. Необходимо найти эталонный образ Xm, расстояние до которого от входного паттерна X будет наименьшим в смысле расстояния Хэмминга. Формальное описание модели Рассмотрим двухслойную архитектуру (рис. 1). Входной слой состоит из N скалярных нейронов, каждый из которых может принимать два состояния, xi = ±1, i = 1, 2, …, N. Первый (внутренний) слой состоит из n векторных нейронов, каждый из которых имеет 2q фиктивных состояния, описываемых орт-векторами q-мерного пространства, yiÎ{±e1, ±e2, …, ±eq}, где ek = (0, …, 0, 1, 0, …, 0) – единичный вектор, содержащий 1 в k-й позиции. Фиктивность состояний заключается в том, что на этапе обучения нейроны второго слоя имеют q дискретных состояний, а в процессе работы нейроны рассматриваются как простые сумматоры. Это сделано с целью упрощения описания модели. Второй (выходной) слой состоит из одного векторного нейрона, который может принимать M состояний, он описывается орт-вектором M-мерного пространства (M – число паттернов в обучающем множестве) OÎ{o1, o2, …, oM}. Состояние персептрона описывается тремя векторами: 1) входной слой описывается N-мерным бинарным вектором X = (x1, x2, …, xN), где xi = ±1; 2) первый (внутренний) слой – n-мерным q-арным вектором Y = (y1, y2, …, yn), где yiÎ{±e1, ±e2, …, ±eq}, ek = (0, …, 0, 1, 0, …, 0) – q-мерный единичный вектор, содержащий 1 в k-й позиции; 3) второй (выходной) слой – M-арным вектором OÎ{o1, o2, …, oM}, где or = (0, …, 0, 1, 0, …, 0) – M-мерный единичный вектор, содержащий 1 в r-й позиции. Каждому эталонному образу Xm в однозначное соответствие ставится вектор Ym, а каждому вектору Ym, в свою очередь, в однозначное соот- ветствие ставится вектор om. Каждая компонента вектора Ym генерируется так, чтобы, с одной стороны, вектор Ym был уникальным, а с другой – возможные состояния {e1, e2, …, eq} были распределены между эталонами строго поровну, то есть XmÛ YmÛ om. (1) Обучение. Коэффициенты синаптических связей векторного персептрона вычисляются по обобщенному правилу Хебба:
где Wji – q-мерный вектор, описывающий связи между i-м нейроном входного слоя и j-м нейроном внутреннего слоя; Jj – матрица размерности M×q, описывающая связи между j-м нейроном внутреннего слоя и единственным выходным нейроном, Идентификация. Пусть на входы сети был подан некоторый вектор X. Вычислим отклик сети O. Для этого сначала вычислим локальные поля нейронов внутреннего слоя:
Так как нейроны второго слоя на этапе распознавания выступают в роли простых сумматоров, далее сформированный сигнал hj без изменений распространяется к выходному нейрону. Поэтому локальное поле на выходном нейроне имеет вид:
Выход сети O вычисляется следующим об- разом. Определяется номер r максимальной компоненты локального поля H. Тогда выход персептрона представляет собой O = or, другими сло- вами, на вход персептрона подан искаженный вариант r-го эталонного образа. Причем, чем больше (H, or), тем более статистически верным является полученный ответ. Более того, если выстроить номера компонент в порядке возрастания их значений, то полученный список будет отражать близость по Хеммингу входного вектора X к соответствующим векторам. Качественное описание модели Каждому векторному нейрону соответствует свое уникальное разбиение всего множества эталонных образов на q подмножеств. В качестве упрощенного примера на рисунке 2 показаны два разбиения множества из M=12 паттернов на q=4 подмножества. Для каждого разбиения можно вычислить q вероятностей (компоненты вектора локальных полей hkj) того, что входной образ принадлежит каждому из этих q подмножеств. Каждый векторный нейрон – это своего рода ре- шатель, выбирающий подмножество, имеющее максимальную вероятность (на рисунке 2 подмножества № 1 в первом разбиении и № 1 во втором). Пересечение подмножеств, выбранных всеми решателями, определяет выход однослойного персептрона. При этом при оценке этих вероятностей могут совершаться ошибки, связанные со статистической природой проводимых вычислений. Следовательно, решение, основанное только на выборе подмножеств по максимальной вероятности, может быть ошибочным. Достаточно неправильно определить подмножество-победитель хотя бы в одном разбиении, чтобы конечное решение было ошибочным. Базовой идеей предлагаемой модели является учет этого недостатка. Предлагается не принимать промежуточные решения, основываясь только на вероятностях отдельного разбиения (отсекая тем самым возможные решения), а осуществлять накопление такой информации по всем разбиениям. Для этого необходимо трактовать полученные для j-го разбиения вероятности
При идентификации по схеме однослойного персептрона в первом разбиении подмножеством-победителем является первое подмножество, которое действительно содержит входной паттерн, а во втором – тоже подмножество № 1 (табл. 1), однако оно не содержит входной паттерн. Таблица 1 Значения вероятностей принадлежности входного паттерна к подмножеству для первого и второго разбиений Table 1 Probability that the input pattern belongs to a particular subset
Вероятность – шанс того, что входной паттерн принадлежит подмножеству. Результатом пересечения этих подмножеств будет пустое множество, то есть сеть не может идентифицировать входной паттерн. Таким образом, ошибка на одном нейроне влечет за собой ошибку всей системы. В то же время видно, что во втором разбиении вероятность принадлежности входного паттерна к подмножеству № 1 отличается от соответствующей вероятности для подмножества № 2 всего на 0,01 (1 %) (табл. 1). То есть почти с равной вероятностью входной паттерн может принадлежать как первому, так и второму подмножеству. В предложенной модели этот факт учитывается, и решение принимается уже на основании значений вероятностей из обоих разбиений для каждого паттерна (табл. 2). В качестве ответа выбирается образ, которому соответствует максимальное суммарное значение вероятности. В результате получаем, что сеть правильно идентифицировала, какой паттерн был подан на вход системы. Таблица 2 Значения вероятностей того, что данный образ является входным, полученные по обоим разбиениям, и суммарное значение вероятности Table 2 Recognition probabilities computed for two partitions and their sum for each pattern
Детали алгоритма Представим оценки вычислительной сложности и требований к оперативной памяти одно- и духслойного персептронов. Из таблицы 3 видно, что количество вычислительных ресурсов (CPU, RAM), требуемых для работы предложенной модели, всего на 4–5 % больше, чем для однослойного персептрона. Столь небольшие дополнительные затраты на второй слой с лихвой окупаются повышением емкости памяти и надежности. Таблица 3 Детали алгоритма Table 3 Details of the algorithm
* – отношение взято для M = 100, N = 100, q = 300, n = 2. Емкость памяти Итак, авторами была представлена новая модель НС, которая получилась в результате добавления дополнительного слоя в однослойную сеть. На примерах был показан смысл дополнительного слоя. Далее необходимо исследовать свойства модели и сопоставить характеристики однослойного и двухслойного персептронов. Выполнить это можно несколькими способами. 1. Взять ряд БД, содержащих реальные данные из различных областей, и исследовать, насколько успешно на них работают предложенная модель и исходный однослойный персептрон. В результате будут определены типы данных (типы задач), на которых описанные выше НС работают хорошо, а на каких – плохо. Полученные таким путем результаты будут очень важны, так как позволят понять, какое место занимают эти алгоритмы среди уже имеющихся. Недостаток данного подхода в том, что для понимания причин, приводящих к улучшению или ухудшению работы, необходим глубокий анализ данных, а эта задача сама по себе нетривиальна. 2. Другой подход заключается в том, чтобы создать искусственные наборы данных – эталонных векторов (паттернов) и тестировать на них исследуемые модели. В этом случае появляется возможность преднамеренно создавать ситуации, в которых ярко проявляются интересующие свойства моделей. Важным достоинством такого подхода является возможность проведения аналитических расчетов статистических характеристик сигналов (математического ожидания, дисперсии, корреляций и т.п.), вычисления вероятности выполнения каких-либо условий или появления событий. Полученные в результате оценки позволяют глубже понимать происходящие внутри НС процессы. Очевидно, что для всестороннего исследования необходимо пройти по обоим путям. В настоящей работе авторы идут по второму пути: в качестве эталонных образов выступают векторы, компоненты которых сгенерированы независимо и с одинаковой вероятностью равны +1 и –1. Выбор такого алгоритма генерации эталонных векторов связан с тем, что, во-первых, это наиболее простой случай для аналитических вычислений, во-вторых, полученные оценки емкости будут ограничением сверху, то есть мы оценим максимально достижимую емкость памяти НС, которую нельзя будет превзойти. Так, например, известно, что НС хуже справляются с распознаванием похожих эталонных образов (способны запомнить заведомо меньшее количество образов), то есть с данными, имеющими корреляции между эталонными векторами. При этом вероятность правильного распознавания сильно зависит от величин корреляций в каждом конкретном случае. Поэтому различные модели ассоциативной памяти можно сравнивать только по оценке сверху емкости памяти, полученной в наиболее простом случае. Например, известный результат по емкости ассоциативной памяти для сети Хопфилда, равный 0,14N, получен в тех же предположениях. Необходимо дать определение термину «емкость памяти». Емкость ассоциативной памяти – это величина Mmax, определяющая количество эталонных образов, на которых можно обучить НС так, чтобы она была способна безошибочно распознавать все запомненные образы. При этом подразумевается, что добавление хотя бы одного эталонного образа (Mmax+1) приводит к тому, что какой-то из них перестает распознаваться (в этом случае вероятность ошибки распознавания будет равна 1/(Mmax+1)). Это классическое определение можно сформулировать иначе. Емкость ассоциативной памяти Mmax – это такое количество эталонных образов, при распознавании которых вероятность ошибочного распознавания предъявленного эталонного образа P равна 1/Mmax. При этом принято, что НС тестируется на запомненных эталонных образах без внесения в них каких-либо искажений. Авторы видят необходимость в обобщении этого определения, заключающегося в том, что поиск величины Mmax выполняется при условии, что на вход сети подаются эталонные векторы, имеющие заданную долю искаженных компонент a≥0 (уровень шума), а вероятность ошибочного распознавания P не превышает некоторого заданного порога Pmax (величина Pmax может быть любой, в том числе 1/Mmax). Для принятых условий авторам удалось оценить емкость памяти обеих моделей. Полученные оценки хорошо согласуются с экспериментом, лишь в 1,1–3 раза отличаясь по величине от экспериментально полученных результатов. Емкость памяти двухслойного персептрона
Емкость памяти однослойного персептрона
Проанализируем емкость памяти обеих моделей. Из (5) и (6) можно сделать следующие выводы: – емкость памяти обеих моделей растет линейно от N, q; – с ростом доли искаженных компонент a во входном векторе емкость памяти моделей убывает квадратично; – повышение требований к надежности распознавания, то есть уменьшение допустимой вероятности ошибки Pmax, приводит к логарифмическому убыванию емкости памяти сети; – самое главное: емкость памяти двухслойной сети больше памяти однослойной сети в n раз. Экспериментальное изучение модели Изучим экспериментально свойства предложенной модели. Покажем, что добавление второго слоя повышает вероятность правильного распознавания НС входных векторов. Для этого проведем экспериментальное сравнение двух моделей одно- и двухслойной сети. В этих экспериментах будем варьировать внешние параметры задачи N, M, a. Детально рассмотрим поведение модели в зависимости от внутренних параметров модели n и q. Увеличение обоих этих параметров повышает вероятность правильного распознавания. Однако эти параметры оказывают разное влияние на модель. Увеличение q приводит к снижению количества информации на долю одной межсвязи, а увеличение n позволяет накопить больше статистической информации. Исследуем емкость памяти модели. Проверим согласованность полученных оценок с экспериментальными. Рассмотрим еще одну возможность, которую предоставляет предлагаемая модель, – возможность решения задачи поиска K ближайших соседей. Сравнение с однослойным персептроном. На рисунках 3–5 по оси ординат отложена вероятность ошибки P, то есть того, что искаженный эталонный вектор будет идентифицирован неверно. На всех рисунках данные, соответствующие однослойному персептрону, обозначены тонкой линией с ромбовидными маркерами (кривые, лежащие выше всех), остальные кривые соответствуют двухслойному персептрону для различных значений параметров n и q. Если количество образов M, их размерность N и параметр шума a (вероятность того, что компонента входного бинарного вектора искажена) определяются решаемой задачей, то количество q-арных нейронов и количество их состояний n внутреннего слоя могут варьироваться, чтобы добиться удовлетворительной надежности. Сначала рассмотрим, как меняется ошибка при фиксированных параметрах n и q от M и N (рис. 3 и 4). Как и ожидалось, увеличение размерности запомненных векторов N либо понижение их количества M приводит к экспоненциальному понижению ошибки P. К тому введение дополнительного слоя позволяет понизить вероятность ошибки более чем на один порядок (до двух и более). Выигрыш тем существеннее, чем меньше ошибка на исходной однослойной сети. Помехоустойчивость двухслойной сети тоже лучше: кривая с маркерами, соответствующая однослойной сети, лежит гораздо выше (рис. 5). Анализ свойств модели. На рисунке 6 отображены несколько зависимостей ошибки двухслойной сети P от уровня шума a для различных комбинаций внутренних параметров n и q, при этом произведение nq = const. Верхняя пунктирная кривая соответствует n = 40 и q = 10, ниже идет кривая для n = 8 и q = 50, далее для n = 4 и q = 100, и комбинация параметров n = 2 и q = 200 (жирная линия) показывает наименьшую ошибку. Получается, что с точки зрения надежности во втором слое лучше использовать небольшое количество надежных (избыточных) нейронов. Однако такие сети неустойчивы к разрушениям самой нейросети. Представленные на рисунке 6 результаты (пунктирная линия) доказывают, что надежные и устойчивые к разрушениям нейросистемы могут создаваться и из ненадежных элементов, имеющих значительный разброс параметров. Сеть с параметрами n = 40 и q = 10 отличается от сети с параметрами n = 2 и q = 200 принципами, обеспечивающими правильное распознавание. В первом случае ключевую роль играет второй слой, накапливающий информацию от большого количества ненадежных элементов (вероятность правильного распознавания однослойного персептрона с такими параметрами равна нулю). Во втором случае второй слой лишь изредка (рис. 6, тонкая кривая с маркерами) корректирует ошибки первого слоя. Рисунок 7 демонстрирует зависимость ошибки P от внутренних параметров n и q. Жирная линия соответствует ошибке двухслойной сети с параметрами n = 2 и q = 200–500, а треугольные маркеры – n = 2–5 и q = 200, то есть обе сети имеют одинаковые вычислительную сложность и требования к оперативной памяти.
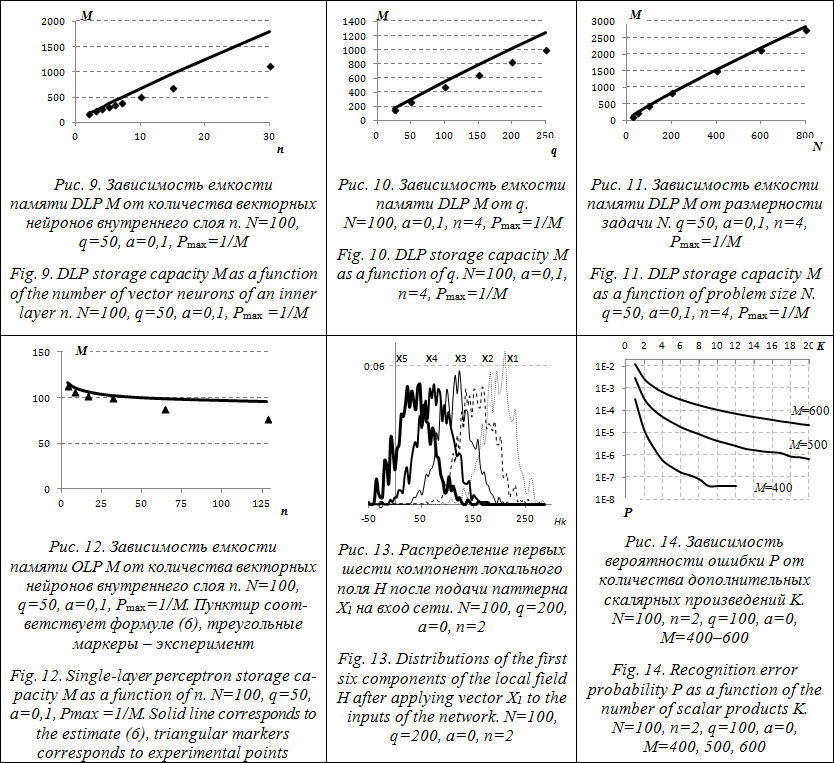
– увеличение обоих параметров ведет к экспоненциальному понижению ошибки P; – обе сети имеют одинаковую ошибку P в области nq ≤ 800 (достаточно неожиданный результат), что опять же говорит в пользу вывода, сделанного выше. Представим результаты экспериментального измерения емкости памяти DLP и посмотрим, насколько хорошо полученная оценка емкости памяти (5) согласуется с результатами. На рисунках 8–11 сплошная линия соответствует значениям формулы (5), маркеры отображают экспериментальные результаты. Эксперимент проводился следующим образом: при фиксированных параметрах (N, n, q и a) необходимо было найти такое количество эталонных образов M, при котором вероятность ошибочного распознавания входного вектора P будет равна 1/M, то есть численно решалось уравнение Из представленных графиков видно, что формула (5) отлично согласуется с экспериментом. Полученные кривые подтвержают правильность выводов, сделанных ранее. Стоит особенно подчеркнуть, что емкость памяти DLP линейно растет с увеличением n, в то время как емкость памяти однослойного персептрона (рис. 12) убывает пропорционально ln(n) (см. формулу (6)). Задача поиска K ближайших соседей. Алгоритм обладает еще одним полезным свойством, которого нет у однослойной модели. Если расположить паттерны в порядке убывания значений соответствующих им компонент локальных полей H (Сумма в табл. 2), то полученный список будет отражать близость по Хеммингу входного вектора к соответствующим векторам, а паттерн, занимающий первое место, будет ответом системы.
1) сгенерируем случайный вектор X1; 2) вектор X2 получим случайным искажением 5 % компонент вектора X1; 3) вектор X3 получим случайным искажением 10 % компонент вектора X1; 4) вектор X4 получим случайным искажением 20 % компонент вектора X1; 5) вектор X5 получим случайным искажением 30 % компонент вектора X1; 6) вектор X6 получим случайным искажением 40 % компонент вектора X1. Далее подадим паттерн X1 на вход сети и посмотрим на значения компонент локального поля H. Компоненты локальных полей, соответствующие этим шести паттернам, будут больше значений полей, соответствующих остальным паттернам. При этом максимальное локальное поле будет соответствовать паттерну X1 (так как на вход был подан этот же паттерн). Второй по величине будет компонента локального поля, соответствующая X2, и т.д. И действительно, результаты эксперимента, представленные на рисунке 13, а именно распределение первых шести компонент локального поля H после подачи паттерна X1 на вход сети, полностью подтверждают вышесказанное. Видим, что пики распределений упорядочены в порядке близости паттернов к паттерну X1. Такое свойство фактически позволяет решать задачу поиска К ближайших соседей, когда необходимо найти К эталонных образов, наиболее похожих на входной вектор. Это свойство можно использовать и для того, чтобы повысить надежность распознавания при решении поставленной задачи поиска первого ближайшего соседа. Для этого необходимо отобрать К эталонных образов, имеющих наибольшие значения компонент локального поля H. Далее вычислить скалярные произведения входного вектора с этими эталонными векторами и уже по результату выбрать победителя по максимальному значению. В результате ценой нескольких дополнительных скалярных произведений можно существенно понизить вероятность ошибочного распознавания P. На рисунке 14 продемонстрирована очень высокая эффективность этого улучшения. Видим, что, например, вычисление двух дополнительных скалярных произведений (K=2) приводит к понижению ошибки распознавания P почти на порядок, а при K=20 – на 3 порядка. Выигрыш тем больше, чем изначально (при K=1) меньше вероятность ошибки. В настоящей статье показано, что эффективность однослойной модели векторного персептрона можно увеличить, добавив дополнительный слой. Продемонстрирована исключительно высокая эффективность предложенной модели. Наглядно показано, что целенаправленное конструирование НС в противоположность слепому увеличению избыточности может дать великолепные результаты. Литература 1. Wu F.Y. The Potts model. Review of Modern Physics, 1982, no. 54, pp. 235–268. 2. Kanter I. Potts-glass models of neural networks. Physical Review A, 1988, vol. 37 (7), pp. 2739–2742. 3. Cook J. The mean-field theory of a Q-state neural network model. Journ. of Physics A, 1989, vol. 22, pp. 2000–2012. 4. Vogt H., Zippelius A. Invariant recognition in Potts glass neural networks. Journ. of Physics A, 1992, vol. 25, pp. 2209–2226. 5. Bolle D., Dupont P., Huyghebaert J. Thermodynamics properties of the q-state Potts-glass neural network. Phys. Rew. A, 1992, vol. 45, pp. 4194–4197. 6. Kryzhanovsky B.V., Mikaelyan A.L. On the Recognition Ability of a Neural Network on Neurons with Parametric Transformation of Frequencies. Doklady Mathematics, 2002, vol. 65, no. 2, pp. 286–288. 7. Austin J., Turner A., Turner M., and Lees K. Chemical Structure Matching Using Correlation Matrix Memories. 9th Intern. Conf. on Artificial Neural Networks, Edinburgh, Edison, 1999, vol. 1, 2, pp. 619–624. 8. Крыжановский В.М. Исследование векторных нейронных сетей с бинаризованными синаптическими коэффициентами для задач обработки информации и принятия решения: дис…канд. физ.-мат. наук. М., НИИСИ РАН, 2010. 168 с. 9. Kryzhanovsky V., Zhelavskaya I., and Fonarev A. Vector Perceptron Learning Algorithm Using Linear Programming. Villa, et al. (Eds.). Springer, Berlin, Heidelberg, LNCS, 2012, vol. 7553, pp. 197–204. 10. Podolak I.T., Biel S. Hierarchical classifier. Wyrzykows- ki R. (Ed.). Parallel Processing and Applied Mathematics, LNCS, 2006, vol. 3911, pp. 591–598. 11. Podolak I.T. Hierarchical classifier with overlapping class groups. Expert Systems with Applications, 2008, vol. 34 (1), pp. 673–682. References | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 . Если последнее требование не исполняется, вероятность ошибки возрастает на несколько порядков. Таким образом, строим НС, запоминающую ассоциацию
. Если последнее требование не исполняется, вероятность ошибки возрастает на несколько порядков. Таким образом, строим НС, запоминающую ассоциацию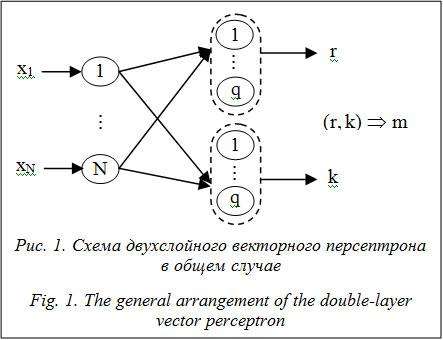
 и
и 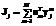 , (2)
, (2) ,
,  .
. (3)
(3) . (4)
. (4)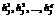 иным способом. Если раньше мы рассматривали hkj как индикатор k-го подмножества в j-м разбиении (некий статистический показатель того, что любой паттерн из k-го подмножества j-го разбиения тождественен входному образу), то сейчас мы будем говорить, что каждому элементу (паттерну) k-го подмножества в j-м разбиении ставится в соответствие этот самый индикатор hkj. Таким образом, каждому паттерну ставится в соответствие набор из n вероятностей или статистических показате- лей n (где n – число различных способов разбиения всего множества паттернов), а их сумма представляет собой совокупный (интегральный) индикатор данного паттерна. Решение о том, какой паттерн был подан на вход, принимается на основании этих интегральных индикаторов, что позволяет использовать информацию о всех подмножествах во всех разбиениях. (Отметим, что под вероятностью здесь подразумевается некая статистическая величина, а именно компонента локального поля hkj. Ее значение тем больше, чем вероятнее входной паттерн является одним из образов, принадлежащих подмножеству, соответствующему этому локальному полю.)
иным способом. Если раньше мы рассматривали hkj как индикатор k-го подмножества в j-м разбиении (некий статистический показатель того, что любой паттерн из k-го подмножества j-го разбиения тождественен входному образу), то сейчас мы будем говорить, что каждому элементу (паттерну) k-го подмножества в j-м разбиении ставится в соответствие этот самый индикатор hkj. Таким образом, каждому паттерну ставится в соответствие набор из n вероятностей или статистических показате- лей n (где n – число различных способов разбиения всего множества паттернов), а их сумма представляет собой совокупный (интегральный) индикатор данного паттерна. Решение о том, какой паттерн был подан на вход, принимается на основании этих интегральных индикаторов, что позволяет использовать информацию о всех подмножествах во всех разбиениях. (Отметим, что под вероятностью здесь подразумевается некая статистическая величина, а именно компонента локального поля hkj. Ее значение тем больше, чем вероятнее входной паттерн является одним из образов, принадлежащих подмножеству, соответствующему этому локальному полю.)
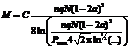 , С= 2,5. (5)
, С= 2,5. (5) . (6)
. (6)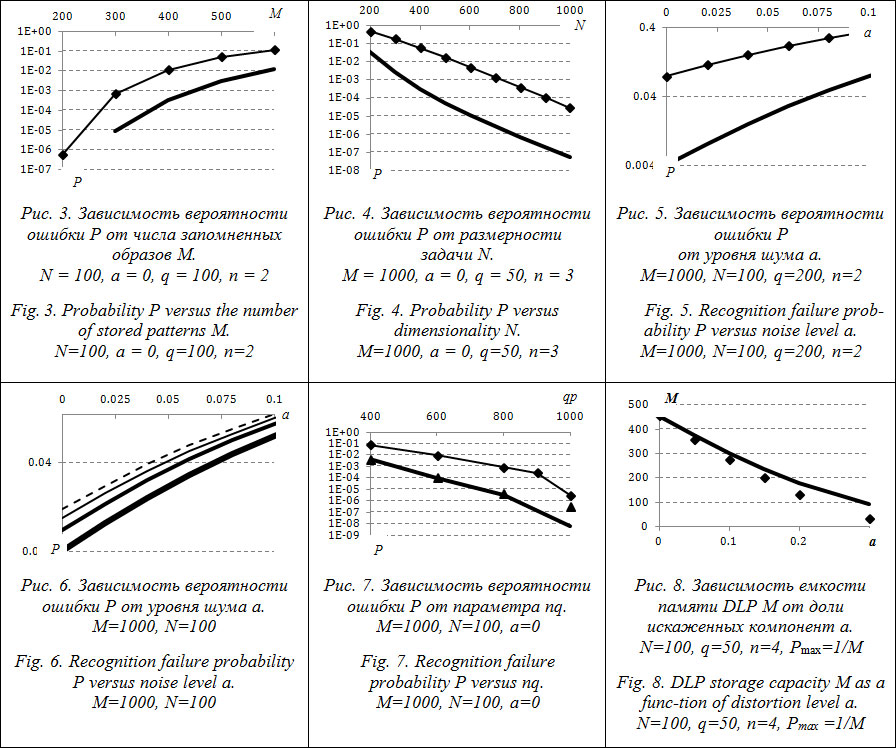
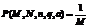 .
.
| Permanent link: http://swsys.ru/index.php?id=3900&lang=en&page=article |
Print version Full issue in PDF (6.61Mb) Download the cover in PDF (0.95Мб) |
| The article was published in issue no. № 4, 2014 [ pp. 70-77 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Многофункциональный имитатор нейронных сетей
- Комплекс программного обеспечения для оптимизации надежности однородных нейронных структур
- Разработка базы данных и конвертера для извлечения и анализа специализированных данных, получаемых с медицинского аппарата
- Метод адаптивной классификации изображений с использованием обучения с подкреплением
- Решение задачи прогнозирования с использованием нейронных сетей прямого распространения на примере построения прогноза роста курса акций
Back to the list of articles