Journal influence
Bookmark
Next issue
Data replication in hierarchical information systems with unstable node connectivity
Abstract:A particular feature of many hierarchical information systems (IS) with relational databases (DB) in their nodes as the core is impermanent communication between the nodes. It prevents classical use of a centralized or distributed database and assigns additional special message exchange and data consolidation functions including external sources to special software, which solves system functional tasks. Replication of required fragments of other IS nodes DB in a local DB consolidates with information from external sources. It allows to simplify and increase harmonization of various IS nodes software. The article proposes an approach to original DB structure transformation based on creating separate for different data sources inherited from source tables. The approach is adapted to asynchronous “master/slave” replication of hierarchically related DB. The paper shows the possibility of using flags and procedures managed by triggers to implement various strategies for data consolidation, as well as a simple adaptation of the original software to solve IS functional problems on the converted DB. There is an example of the described approach implementation for widespread and used in many domestic certified software tools of an object-relational database management system PostgreSQL with an asynchronous “master/slave” replication system Slony-I. There is a possibility to overcome limitations of an asynchronous “master/slave” replication system using dblink support modules of session connection to other DB and postgres_fdw foreign-data wrapper, as well as replication system joint using with these modules on the converted DB.
Аннотация:Особенность многих иерархических информационных систем, ядром которых являются размещенные в их узлах реляционные БД, заключается в непостоянстве связи между узлами. Она препятствует классическому использованию централизованной или распределенной БД, возлагая на специальное ПО, решающее функциональные задачи системы, дополнительные функции обмена специализированными сообщениями и консолидации данных, в том числе от внешних для информационных систем источников. Репликация в локальной БД необходимых фрагментов БД других узлов информационных систем, консолидируемая с информацией из внешних источников, позволяет значительно упростить и повысить унификацию специального ПО различных узлов информационных систем. В статье предлагается подход к преобразованию исходной структуры БД, основанный на создании отдельных для различных источников данных таблиц, наследованных от исходных, адаптированный к особенностям асинхронной master/slave-репликации иерархически связанных БД. Показана возможность использования управляемых триггерами флагов и процедур для реализации различных стратегий консолидации данных и простой адаптации исходного специального ПО для решения функциональных задач информационных систем на преобразованной БД. Приводится пример реализации описанного подхода для широко распространенной и используемой во многих отечественных сертифицированных программных средствах объектно-реляционной СУБД PostgreSQL с системой асинхронной master/slave-репликации Slony-I. Отмечается возможность преодоления известных ограничений использования данной системы асинхронной master/slaveрепликации применением модулей dblink поддержки сессионного соединения с другими БД и postgres_fdw обертки внешних данных, а также совместного использования системы репликации с этими модулями на преобразованной БД.
| Authors: Sorokin V.E. (sorokinve@yandex.ru) - Developed in the Research Institute "CENTERPROGRAMMSYSTEM", Tver, Russia, Ph.D | |
| Keywords: external data wrapper, inheritance tables, asynchronous replication, relational database, hierarchical information system |
|
| Page views: 9276 |
Print version Full issue in PDF (9.58Mb) Download the cover in PDF (1.29Мб) |
Иерархические информационные системы (ИС) относятся к одним из наиболее распространенных. Их ядром во многих случаях являются реляционные БД, и для решения возложенных на ИС задач необходим доступ к данным не только своего, но и других узлов. При этом классическими решениями являются система «клиент/сервер» с единой централизованной БД или распределенная по узлам ИС БД. В обоих случаях требуется постоянный надежный доступ к другим узлам ИС, что далеко не всегда обеспечивается. Наглядным примером могут служить иерархические ИС с ситуационными центрами во главе структуры, на которые замыкаются стационарные региональные узлы с подчиненными им мобильными узлами, что характерно для управления территориальными надзорными и ремонтными работами или устранения последствий чрезвычайных ситуаций. При этом основными узлами принятия общих решений, формирования итоговых документов и источником директивной информации являются ситуационные центры, а источником первичной информации – мобильные узлы, связь с которыми может быть непостоянной. В отсутствии актуальной первичной информации для принятия решений, формирования документов и т.п. используется информация из внешних для ИС источников, что дополнительно усложняет консолидацию (непротиворечивое слияние) данных, поступивших из нескольких разных источников. Исторически типичным в таких случаях является решение специальным ПО (СПО) функциональных задач ИС как во взаимодействии с локальной БД, так и при вводимых оператором внешних данных и обмене специализированными сообщениями между СПО, размещенным в различных узлах ИС. Несмотря на то, что значительная часть задач, решаемых в различных узлах ИС, идентична или подобна, обмен сообщениями между СПО существенно препятствует его унификации. Независимая от СПО репликация в локальной БД необходимых фрагментов БД других узлов ИС, консолидируемая с информацией из внешних источников, позволяет значительно упростить и повысить унификацию СПО различных узлов ИС. Одному из практических подходов к репликации фрагментов реляционных БД в иерархических ИС с непостоянной связностью узлов посвящена данная статья. Сравнение возможных способов репликации реляционных БД Теоретически строго полноценной и гарантирующей целостность БД является синхронная репликация, при которой после обновления одной реплики все другие реплики того же фрагмента данных должны быть обновлены в той же транзакции. Как правило, синхронная репликация реализуется с помощью триггерных процедур. Создается дополнительная нагрузка при выполнении всех транзакций, в которых обновляются какие-либо реплики. Однако критическим недостатком, полностью исключающим ее применение в рассматриваемых условиях, является невозможность успешного завершения транзакции, в которой должна обновляться недоступная реплика. В случае асинхронной репликации обновление одной реплики распространяется на другие спустя некоторое время и не в той же транзакции. При этом имеется задержка (время ожидания), в течение которой отдельные реплики могут быть фактически неидентичными. Как правило, асинхронная репликация реализуется посредством чтения журнала транзакций или очереди тех обновлений, которые подлежат распространению. Ее основное преимущество в том, что дополнительные издержки репликации не связаны с транзакциями обновлений, основной недостаток – данные в различных репликах могут оказаться несовместимыми. Ввиду независимости транзакций в различных репликах возможно возникновение конфликтных ситуаций, которые сложно (иногда даже невозможно) предотвратить и трудно исправить, прежде всего в зависимости от порядка применения обновлений одного и того же фрагмента данных различными репликами. В общем случае задачи устранения конфликтных ситуаций и обеспечения согласованности реплик при асинхронной репликации являются весьма сложными. Однако особенности репликации фрагментов БД в иерархических ИС являются тем частным случаем, который позволяет избежать таких проблем, прежде всего за счет достаточности master/slave-репликации, базирующейся на предположении, что изменения вносятся лишь в одну главную (master) копию, а остальные зависимые (slave) просто перезаписываются ее содержимым. Этот способ реализует большинство приложений синхронизации, предоставляя пользователю выбор главной копии. При этом копия может представлять собой как полностью БД, так и определенный набор (множество) ее таблиц. Кроме репликаций с автоматическим распространением обновления одной реплики на остальные, применяется управление копированием без автоматического распространения обновлений. Копии данных создаются и управляются с помощью пакетного или фонового процесса, который отделен во времени от транзакций обновления. Преимуществом такого управления копированием по сравнению с репликацией является большая эффективность ввиду возможности одноразового копирования значительно больших, чем обновляемые в одной транзакции, объемов данных, а недостатком – неидентичность на протяжении большей части времени между моментами синхронизации различных копий данных, что необходимо учитывать в работе с этими данными [1]. Таким образом, приемлемыми способами репликации фрагментов реляционных БД в иерар- хических ИС с непостоянной связностью узлов следует признать асинхронную master/slave-репли- кацию и управление копированием. Поскольку первый из них реализует большинство приложений синхронизации БД и требует, как правило, только настройки, а второй подразумевает определенную (в широком диапазоне в зависимости от способа реализации) долю программирования, подробно рассмотрим использование асинхронной master/slave-репликации, в завершение отметив возможности аналогичной реализации управления копированием. Корректировка исходной структуры БД для слияния внешних и реплицируемых данных В общем случае реляционным БД иерархических ИС присущи черты как оперативных БД, в основном содержащих текущие данные, так и БД поддержки принятия решений и хранилищ данных, содержащих архивы исторически накопленных данных. Для БД различных уровней иерархии ИС важно определение уровня детализации БД, то есть самого низкого уровня обобщения данных, предназначенных для хранения в БД. При информационном взаимодействии узлов смежных уровней иерархии ИС уровень детализации БД не должен понижаться с повышением уровня иерархии. В такой БД содержатся структуры, отражающие иерархию ИС и объектов (сущностей модели данных), информация о которых хранится в БД, в привязке к узлам ИС, формирующим эту информацию. При выполнении процедуры консолидации любая неявная связь между данными из разных источников преобразуется в явную связь, например, путем введения явных значений унифицированных идентификаторов. Информация из внешних для ИС источников используется только при отсутствии связи с узлами ИС, ответственными за ее формирование. Обязательным условием отсутствия неявных связей, гарантирующим консолидацию данных, является идентичность первичных или альтернативных ключей. При полноте такой информации, относящейся к объекту или узлу ИС, соответствующая информация в БД полностью замещается. При ее частичности обязательно должен передаваться перечень значений ключей удаленных данных (совпадающие значения ключей используются для обновления данных, а несовпадающие – для вставки).
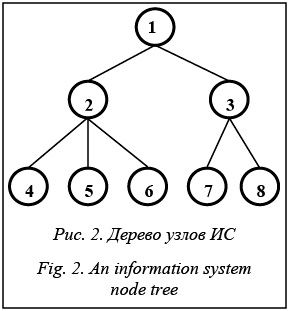
Основными причинами корректировки предложенной исходной структуры БД являются ограничения асинхронной master/slave-репликации и обеспечение совместимости реплицируемой информации с информацией из внешних источников. Прежде всего это единственность (невозможность множественности) master-таблицы при возможной множественности slave-таблиц и ограниченность детализации репликации отдельной таблицей, а не выборкой или проекцией из таблицы. Поэтому отдельные таблицы должны выделяться для данных, относящихся как к master-, так и к slave-информации хотя бы в одном репликационном наборе (множестве таблиц). Таким образом, в преобразованной структуре БД узла ИС вместо каждой таблицы исходной структуры БД должны содержаться несколько идентичных по структуре таблиц в зависимости от связности с другими узлами ИС, а также для информации из внешних источников. Для сохранения наглядности без существенного уменьшения общности ограничим рассмотрение структуры ИС деревом, изображенным на рисунке 2, в вершинах которого указаны условные номера узлов ИС.
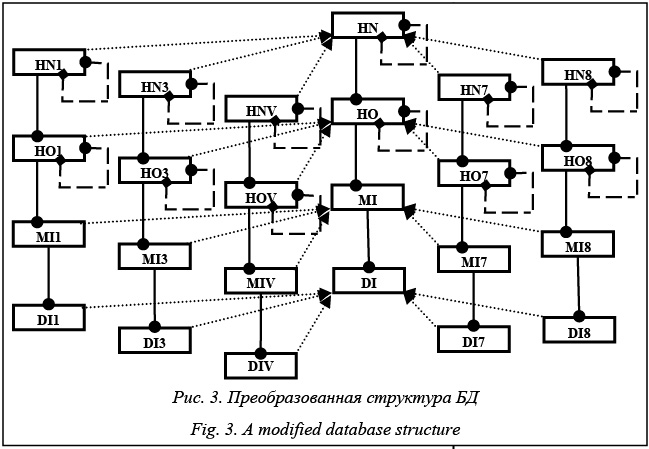
Для обобщенной исходной структуры БД преобразованная таким образом структура БД (рис. 2) на узле с условным номером 3 промежуточного уровня иерархии, связанном с узлом вышестоящего уровня с условным номером 1 и двумя узлами нижестоящего уровня с условными номерами 7 и 8, будет иметь вид, представленный на рисунке 3. В дополнение к внешним ссылкам пунктирными стрелками на рисунке 3 показано наследование таблиц.
При предположении, что в рассматриваемой иерархической ИС информация передается только между смежными по иерархии узлами, причем информация об иерархии узлов – сверху вниз, а остальная информация – снизу вверх по иерархии, таблицы HO3, MI3 и DI3 узла с условным номером 3 будут являться master-копиями в репликации на узел с условным номером 1. Таблица HN3 (при отсутствии фильтрации данных) или таблицы HN7 и HN8 (при наличии фильтрации данных) будут являться master-копиями в репликации на узлы с условными номерами 7 и 8. Таблица HN1 будет являться slave-копией в репликации от узла с условным номером 1. Таблицы HO7, MI7 и DI7 будут являться slave-копиями в репликации от узла с условным номером 7, а таблицы HO8, MI8 и DI8 – от узла с условным номером 8. Таблицы HO1, MI1, DI1 и таблица HN3 или таблицы HN7 и HN8 в зависимости от фильтрации данных на узле с условным номером 3 не используются и могут отсутствовать. Аналогично при описанном подходе к преобразованию структуры БД неиспользуемыми будут таблицы в БД и на других узлах ИС. Однако неиспользуемые таблицы не являются существенным отягощением БД, в связи с чем предлагается унифицированная для всех уз- лов ИС структура БД, яв- ляющаяся объединением структур БД всех узлов ИС и позволяющая в максимально возможной степени унифицировать СПО решения функциональных задач на различных узлах ИС, возложив функции репликации и консолидации данных на систему асинхронной master/ slave-репликации и хранимые (триггерные и вызываемые из триггеров) процедуры СУБД. Дополнительным преимуществом такого подхода является возможность изменения уровней детализации БД различных узлов ИС перенастройкой множеств реплицируемых таблиц и их подписки. Пример реализации описанного подхода с использованием сертифицированных ПС Рассмотрим пример реализации ключевых аспектов описанного подхода к репликации реляционных БД в иерархических ИС с непостоянной связностью узлов средствами конкретных СУБД и системы асинхронной master/slave-репликации управляемых ею БД. Учитывая тенденцию к увеличению независимости от проприетарных импортных программных продуктов, а также требования использования в разрабатываемых ИС отечественных программных средств (ПС), во многих случаях имеющих определенные сертификаты безопасности и разрешения использования, выберем объектно-реляционную СУБД PostgreSQL с системой асинхронной master/slave-репликации Slony-I [2, 3]. Такой выбор обусловлен их соответствием в основном современным стандартам в области реляционных СУБД, подтвержденной широким использованием эффективностью [4], а также свободным распространением в исходных кодах и вхождением в состав многих отечественных сертифицированных ПС, таких как операционные системы МСВС и Astra Linux [5, 6]. Пример будет базироваться на совместимых между собой версиях PostgreSQL и Slony-I, входящих в состав последних версий этих ПС. Без потери общности полагаем, что в примере все таблицы создаются в одной схеме sch в одноименной БД dbexam для всех узлов ИС с условными номерами unb от 1 до 8, имеющими адрес ‘333.22.unb.1’. Для реплицирования везде используются порт по умолчанию и пользователь postgres с паролем pres. Имена таблиц в сопровождающем команды тексте приведены прописными буквами исключительно для наглядности. Первоначально для создания таблиц по наследованию от заданных в PostgreSQL для каждой из таких таблиц выполняется команда типа CREATE TABLE sch.hn1 ([]) INHERITS (sch.hn); В этих командах вместо квадратных скобок перечисляются не наследуемые по умолчанию, но необходимые в наследуемых таблицах ограничения, такие как первичные и внешние ключи, уникальности, а также значения по умолчанию. Например, для поля f1 первичного ключа, поля f2 альтернативного ключа и целочисленного поля f3 со значением по умолчанию, равным условному номеру узла ИС, для создания таблицы HN1 на узле 1 выполняется команда CREATE TABLE sch.hn1 ( f3 integer DEFAULT 1, PRIMARY KEY (f1), UNIQUE (f2) ) INHERITS (sch.hn); Соответственно на узле 3 выполняется команда CREATE TABLE sch.hn1 ( f3 integer DEFAULT 3, PRIMARY KEY (f1), UNIQUE (f2) ) INHERITS (sch.hn); Отметим, что внешние ключи дочерних таблиц должны ссылаться не на родительские, а на соответствующие дочерние таблицы. Так, при существовании в таблице HO наряду с полем f1 первичного ключа поля f4 внешней ссылки на таблицу HN FOREIGN KEY (f4) REFERENCES sch.hn(f1) для создания таблицы HO1 на любом узле выполняется команда CREATE TABLE sch.ho1 ( PRIMARY KEY (f1), FOREIGN KEY (f4) REFERENCES sch.hn1(f1) ) INHERITS (sch.ho); Аналогичные действия выполняются для всех остальных таблиц. В результате в схеме sch БД dbexam на каждом из 8 узлов ИС наряду с 4 исходными таблицами HN, HO, MI и DI будут созданы 36 таблиц HN(1–8, V), HO(1–8, V), MI(1–8, V) и DI(1–8, V), где MI(3–5, V), например, обозначает список таблиц MI3, MI4, MI5 и MIV. Кроме того, должна быть разработана унифицированная триггерная процедура, управляющая на каждом узле корректировкой данных в таблицах, являющихся master-копиями в репликации на внешние узлы при изменении данных в таблицах, являющихся slave-копиями в репликации от внешних узлов и таблицах с информацией из внешних источников данного узла. Данная процедура должна активизироваться соответствующими триггерами и реализовывать выбранную стратегию консолидации и фильтрации для внешнего представления данных, использующую введенные флаги. Учитывая интенсивность и условия выполнения, особое внимание должно уделяться эффективности выполняемых в ней запросов, в которых данные фильтруются по значениям ключей и флагов. В этом случае при больших объемах данных весьма эффективны многоколоночные индексы, включающие поля флагов после ключевых по- лей [7]. Эта процедура является основной специализированной разработкой. Все остальные приведенные действия легко автоматизируются, в связи с чем создание соответствующего диалогового приложения, в котором описываются узлы ИС и перечисляются используемые в репликациях таблицы, не представляет проблемы. Естественно, что добавление в ИС новых узлов потребует добавления соответствующих объектов в БД, причем каждого узла, поскольку отсутствуют репликации изменений, внесенных DDL-командами. Другими наиболее существенными ограничениями последних версий системы Slony-I, которые необходимо учитывать, являются отсутствие репликаций изменений для больших объектов (BLOB) и сделанные командой TRUNCATE, а также изменения пользователей и ролей. По окончании преобразования БД задается имя репликационного кластера, например slony_example, с которым связываются все дальнейшие действия по его настройке, выполняемые с помощью утилиты командной строки Slonik конфигурации системы Slony-I. Разумеется, в каждом узле ИС, кроме СУБД PostgreSQL, должна быть установлена система Slony-I асинхронной master/slave-репликации, а в случае отсутствия в каждой БД должен быть установлен необходимый этой системе процедурный язык PL/pgSQL. Настройка репликационного кластера slony_ example заключается в передаче утилите Slonik скриптов на ее командном языке (из текстового файла или стандартного входа), начинающихся с преамбульной команды указания кластера CLUSTER NAME = slony_example; В начале настройки все узлы репликационного кластера, в данном случае 8 узлов ИС с доступом к их БД, описываются также преамбульной командой описания этих узлов. Например, узел 3 описывается командой NODE 1 ADMIN CONNINFO = 'dbname=dbexam host=333.22.3.1 user=postgres password=pres'; Остальные команды в командном языке утилиты Slonik относятся к конфигурационным или командам действий. Прежде всего командой INIT CLUSTER (id=1, comment = 'Master Node 1'); создается кластер на master-узле. При этом в БД создается схема _slony_example, содержащая все необходимые репликационной системе объекты БД. Затем в созданный кластер добавляются slave-узлы. Например, узел 3 добавляется командой STORE NODE (id=3, comment = 'Slave node 3', event node=1); После этого устанавливаются пути доступа от каждого узла ко всем остальным узлам, которые могут использоваться. Так, для пары узлов 1 и 3 должна быть выполнена пара команд: STORE PATH (server=1, client= 3, conninfo= 'dbname=dbexam host=333.22.1.1 user=postgres password=pres'; STORE PATH (server=3, client= 1, conninfo= 'dbname=dbexam host=333.22.3.1 user=postgres password=pres'; В командах термины server и client относятся не к роли узлов в кластерной конфигурации, а к источникам и получателям сообщений или данных. Далее создаются репликационные наборы таблиц, на которые осуществляется подписка узлов. В данном случае следует создать по два набора для узлов 2 и 3 как промежуточных в иерархии ИС и по одному набору на остальные узлы, так как на каждом узле имеются таблицы, на репликацию ко- торых подписан хотя бы один узел, и подписки в одном направлении иерархии идентичны. Репликационные наборы для узлов 1, 3 и 7 создаются командами CREATE SET (id=1, origin=1); CREATE SET (id=4, origin=3); CREATE SET (id=5, origin=3); CREATE SET (id=9, origin=7); Каждый репликационный набор описывается перечнем входящих в него таблиц (и, возможно, последовательностей) путем добавления их к набору. Таблицам присваиваются уникальные идентификаторы среди всех наборов кластера. Порядок включения таблиц в набор определяет порядок их обработки. В рассматриваемом примере в перечисленные наборы будут добавлены таблицы следующими командами: SET ADD TABLE (set id=1, id=1, fully qualified name='sch.hn1'); SET ADD TABLE (set id=4, id=6, fully qualified name='sch.hn3'); SET ADD TABLE (set id=5, id=7, fully qualified name='sch.ho3'); SET ADD TABLE (set id=5, id=8, fully qualified name='sch.mi3'); SET ADD TABLE (set id=5, id=9, fully qualified name='sch.di3'); SET ADD TABLE (set id=9, id=19, fully qualified name='sch.ho7'); SET ADD TABLE (set id=9, id=20, fully qualified name='sch.mi7'); SET ADD TABLE (set id=9, id=21, fully qualified name='sch.di7'); Наконец, выполняется подписка на созданные наборы таблиц. На представленные наборы в соответствии с логикой примера подписка выполняется следующими командами: SUBSCRIBE SET (id=1, provider=1, receiver=3, forward=no); SUBSCRIBE SET (id=4, provider=3, receiver=7, forward=no); SUBSCRIBE SET (id=5, provider=3, receiver=1, forward=no); SUBSCRIBE SET (id=9, provider=7, receiver=3, forward=no); На этом настройка репликационного кластера завершена. Для его функционирования на всех узлах кластера должен выполняться процесс slon, которому в качестве параметра переданы имя кластера и информация соединения с БД. В принципе, процесс slon и БД, к которой он подсоединяется, могут располагаться на различных узлах, но при непостоянной связности узлов это лишь создает дополнительные проблемы. Предлагается запускать этот процесс на каждом узле ИС как сервис после запуска сервиса СУБД и останавливать, соответственно, перед остановкой сервиса СУБД. Основными условиями нормального функционирования системы Slony-I являются доступность всех узлов, синхронизация их часов, предпочтительно с использованием таких стабильных часовых поясов, как UTC или GMT, и использование общей кодировки БД. Проведенные над созданным описанным способом репликационным кластером со стабильным часовым поясом и общей кодировкой БД эксперименты показали корректное восстановление репликации после многочасовых прерываний связи между узлами. Однако если параметры рассинхронизации часов или непостоянства связности узлов ИС не позволяют настроить систему Slony-I асинхронной master/slave-репликации многочисленными конфигурационными командами утилиты Slonik таким образом, чтобы обеспечивались требуемые показатели функционирования ИС, то необходимо реализовывать собственный механизм управляемого копирования, позволяющий разрешать такие проблемы. В последних версиях СУБД PostgreSQL в качестве основы такого механизма к модулю dblink поддержки сессионного соединения с другими БД добавился модуль postgres_fdw обертки внешних данных, функциональность которого в основном перекрывает функциональность модуля dblink, предоставляя более стандартный синтаксис доступа к удаленным данным и обеспечивая во многих случаях более высокую производительность. Принципиальным недостатком применения этих модулей по сравнению с системой репликации является смещение акцента выполняемых действий с настройки на программирование. При этом необходимо решать не только задачи выявления обновлений данных на сервере и их актуализации на клиенте, но и такие скрытые системой Slony-I задачи, как управление поведением исходных триггеров и правил реплицируемых таблиц и управление блокировками. Несомненным преимуществом управляемого копирования является возможность обращения к отдельным записям таблиц и отказа от описанного в статье преобразования структуры БД. Тем не менее, для разделения функций реплицирования и консолидирования данных предлагается использовать такое преобразование структуры БД, в том числе и при управляемом копировании. Определенный интерес может представлять совместное использование в ИС репликации и управляемого копирования на непересекающихся фрагментах БД, позволяющее в наибольшей мере использовать их преимущества. Например, представляется целесообразным реплицировать интенсивно изменяющиеся небольшие по объему данные и управляемо копировать без какого-либо дублирования консервативные специализированные по доступу большие объемы информации. Наконец, нельзя не упомянуть о докладе на последней Общероссийской конференции по Postgre- SQL в Москве [4] Симона Риггза (Simon Riggs), од- ного из создателей разрабатываемой в открытых кодах новейшей репликационной технологии BDR (BiDirectional Replication – двунаправленная репликация) для ядра PostgreSQL. В докладе утверждалась работоспособность технологии BDR с ядром 9.4 PostgreSQL и описывалось ее становление в качестве основной репликационной технологии для PostgreSQL с последующим отказом от дальнейшего развития системы Slony-I. Однако в качестве полноценной multi-master-репликации эта технология планируется для еще не выпущенного (на момент написания статьи) ядра 9.6 PostgreSQL. Поскольку существует естественное отставание версий ядра PostgreSQL в сертифицированных ПС, применение технологии BDR (с возможной адаптацией под нее предлагаемого в статье подхода) к репликации реляционных БД в иерархических ИС с непостоянной связностью узлов может являться лишь предметом дальнейшего рассмотрения. На основании изложенного можно сделать вывод о том, что предлагаемый подход к репликации реляционных БД в иерархических ИС с непостоянной связностью узлов позволяет существенно отделить проблему поддержания целостности и актуальности данных в таких системах от решаемых на этих данных функциональных задач. Введение дополнительной избыточности в структуру БД за счет наследования специализированных под конкретный источник данных таблиц повышает возможности применения в таких системах асинхронной master/slave-репликации, существенно сокращая объем разрабатываемого СПО, а унификация структуры БД для различных узлов ИС предоставляет дополнительную возможность унификации СПО. Литература 1. Дейт К.Дж. Введение в системы баз данных; [пер. с англ.]. М.: Вильямс, 2005. 8-е изд. 1328 с. 2. PostgreSQL. Documentation. URL: http://www.postgresql.org/docs (дата обращения: 15.06.2015). 3. Slony-I enterprise-level replication system. Documentation. URL: http://slony.info/documentation (дата обращения: 15.06.2015). 4. Докл. Рос. конф. разработчиков и пользователей PostgreSQL междунар. уровня (PgConf.Russia). 2015. URL: http://pgconf.ru/2015 (дата обращения: 17.02.2015). 5. Вопросы по МСВС. URL: http://www.vniins.ru/index. php?s=вопросы%20по%20мсвс&lang=Рус (дата обращения: 15.06.2015). 6. Astra Linux – операционная система специального назначения на базе ядра Linux. URL: http://www.astra-linux.com (дата обращения: 15.06.2015). 7. Сорокин В.Е. Метод искусственного соответствия SQL-запросов индексам реляционных баз данных // Программные продукты и системы. 2013. № 2. С. 47–54. |

| Permanent link: http://swsys.ru/index.php?id=4091&lang=en&page=article |
Print version Full issue in PDF (9.58Mb) Download the cover in PDF (1.29Мб) |
| The article was published in issue no. № 4, 2015 [ pp. 203-209 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Метод автоматизации проектирования распределенной реляционной базы данных
- Реализация логического вывода в продукционной экспертной системе с использованием Rete-сети и реляционной БД
- Универсальная модель данных как средство хранения информации при решении прикладных задач кристаллохимии
- Метод искусственного соответствия SQL-запросов индексам реляционных баз данных
- Представление данных при разработке программного обеспечения по ведению информации о состоянии поисково-спасательных технических средств
Back to the list of articles