Journal influence
Bookmark
Next issue
Knoware of an adaptive knowledge testing system
Abstract:The article considers the problem of realizing knoware for an adaptive knowledge testing system. The process of testing knowledge is represented as a dynamic one. An organizer forms a homogeneous group of examinees at each cycle of the system. The system selects the best test at each step based on a convergent procedure of stochastic approximation. The best test depends on probabilistic characteristics of examinees contingent and allows increasing estimation accuracy of person parameters. To identify factors that prevent obtaining objective evaluation, such as conversations and copying, the authors introduce an interaction rate. The article analyzes the influense of examinees’ interaction on the accuracy of test marks. To improve the estimation accuracy of person parameters the system overestimates probabilistic characteristics of a group of examinees at each cycle. Person and item parameters are aligned on a common scale at each cycle. The system implements evaluating item parameters using the maximum likelihood method, the conditional maximum likelihood method and the marginal maximum likelihood method. The maximum likelihood method, the weighted likelihood method and the Bayesian approach can be used for evaluating person parameters. The system evaluates a 1-parameter dichotomous Rasch model and 2-parameter, 3-parameter, 4-parameter dichotomous extensions, RSM and PCM polytomous models and appropriate linearized models. To evaluate matching between observed data and the expected values the authors use a statistics of the likelihood test, statistics of the Hosmer-Lemeshow test, coefficients of determination, ROC-analysis. The article contains a flow chart of the algorithm for each cycle and a database schematic diagram.
Аннотация:В статье рассмотрена задача создания алгоритмического обеспечения адаптивной системы тестирования знаний. Тестирование знаний рассматривается как динамический процесс. На каждом такте работы системы организатор тестирования формирует однородную группу испытуемых; система подбирает наилучший тест исходя из сходящейся процедуры стохастической аппроксимации. Этот тест зависит от вероятностных характеристик контингента испытуемых и позволяет увеличить точность оценивания их подготовленности. Для выявления факторов, мешающих получению объективных оценок, таких как разговоры и списывание, введен коэффициент взаимодействия. Исследовано влияние взаимодействия тестируемых на точность оценивания их подготовленности. Для повышения точности оценивания подготовленности система на каждом такте переоценивает вероятностные характеристики группы испытуемых. Полученные оценки подготовленности испытуемых выравниваются на единой шкале. В системе реализован расчет трудности заданий с помощью метода максимального правдоподобия, метода условного максимального правдоподобия и метода маргинального максимального правдоподобия. Для оценки подготовленности могут использоваться методы максимального правдоподобия и взвешенного максимального правдоподобия и байесовский подход. Оценки подготовленности и трудности реализованы для дихотомической модели Раша и ее 2-, 3- и 4-параметрических расширений, для политомических моделей RSM, PCM и их линеаризованных моделей. Для проверки адекватности результатов тестирования используются статистика отношения правдоподобия, статистика Хосмера–Лемешоу, коэффициенты детерминации, ROC-анализ. Для предложенной системы приведены блок-схема алгоритма работы на каждом такте и принципиальная схема БД.
| Authors: Bessarabov N.A. (nikitabes@mail.ru) - Moscow Institute of Physics and Technology, Dolgoprudny, Russia, Bondarenko A.V. (bond@fgosniias.ru) - Moscow Institute of Physics and Technology (Professor), Dolgoprudny, Russia, Ph.D, Kondratenko T.N. (tanya@fgosniias.ru) - State Research Institute of Automatic Systems (Head of Laboratory), Moscow, Russia, Timofeev D.S. (timofeev@fgosniias.ru) - State Research Institute of Automatic Systems (Head of Sector), Moscow, Russia | |
| Keywords: algorithm of work, Rush's model, logit, tests design, stochastic approximation, test results accuracy, distribution of test’s easiness, algorithmic support, adaptive system, database, mathematical theory test |
|
| Page views: 10168 |
Print version Full issue in PDF (8.31Mb) Download the cover in PDF (1.24Мб) |
В настоящее время теория латентных параметров находит применение в педагогике, психологии, в маркетинге для исследования пожеланий потребителей, поведения поставщиков, направлений проведения досуга, эффективности рекламы, спортивной информации, при анкетировании в здравоохранении, обосновании программ реабилитации и т.п. [1]. Насчитывается несколько сотен коммерческих и свободно распространяемых програм- мных продуктов, обеспечивающих оценивание латентных параметров. Значительное число исследований посвящено изучению моделей Раша, составляющих основу IRT [1, 2], и их расширений, а также методам оценивания латентных параметров [3–6]. Тестирование применяют для измерения латентного параметра, например знаний испытуемых. Оно состоит из этапов составления тестовых заданий, непосредственно проведения тестирования и последующей обработки результатов, которая дает оценку латентного параметра тестируемых – уровня подготовленности тестируемых и трудности заданий, надежности, валидности, дискриминационных возможностей и других параметров теста [1]. Обработка результатов тестирования представляет собой решение статической задачи: собира- ется массив данных, оцениваются трудность заданий и уровень подготовленности испытуемых. Процесс тестирования знаний по своей сути является динамическим. В начальном состоянии система имеет лишь экспертные оценки трудности заданий и параметров групп тестируемых. По мере проведения тестирования в различные интервалы времени происходит корректировка тестов: какие-то задания оставляют прежними, какие-то заменяют с учетом их трудности для применения на последующих сеансах тестирования. Важную роль в совершенствовании системы тестирования знаний играет обратная связь: результат функционирования системы тестирования влияет на параметры, от которых зависит функ- ционирование этой системы. Поэтому актуальна разработка алгоритмического и программного обеспечения, в котором система тестирования рассматривается как динамическая с обратной связью. Постановка задачи Организатор тестирования проектирует базу заданий для многих вариантов тестов, задает и корректирует образовательный стандарт для различных классов испытуемых. Математическая модель динамической системы тестирования состоит в том, что в каждый момент проведения тестирования t исследуют однородную группу испытуемых с индексом класса g в количестве n(t, g) человек, которым предлагают тест, состоящий из k(t, g) заданий с трудностями δj1, …, δjk. По результатам тестирования составляется матрица ответов A= ={aij(t, g)}, где i=1, …, n(t, g) и j=1, …, k(t, g), которая показывает подготовленность испытуемых θi1, …, θin и трудность заданий δj1, …, δjk. Среди заданий теста в момент времени t могут быть d(t, g) ≤ k(t, g) узловых заданий, применявшихся ранее с трудностями δl1, …, δld, где индексы {l1, …, ld} включены в множество индексов {j1, …, jk}. Впервые используемые задания имеют начальные трудности, равные значениям, полученным из экспертных оценок. Узловые задания (ранее применявшиеся) имеют трудности, оцененные на последний момент времени применения каждого из них. Кроме трудностей δl1, …, δld, из БД извлекаются дополнительные атрибуты cl1, …, cld и θl1, …, θld (значения достаточной статистики и соответствующей подготовленности) – вычисленные в момент последнего применения соответствующего задания параметры, необходимые для рекуррентных вычислений в момент времени t. Если в момент времени t принято решение уменьшить число заданий в тесте, тест считается прежним, когда в матрице ответов по этим заданиям элементы соответствующих столбцов были равны только 0 или 1. В противном случае считается, что это новый тест. Увеличение количества заданий за счет добавления заданий по теме теста или замена заданий на задания с аналогичными трудностями не приводит к изменению теста. Все множество испытуемых, для которых создают тесты, естественно разбить на классы, соответствующие тематике тестов и их назначению. Предположим, что подготовленности испытуемых в логитах в каждом классе характеризуются гауссовым распределением N(Mg, σg). Параметры класса в начальный момент определяются экспертными оценками и уточняются по мере обработки результатов тестирования для соответствующего класса g. Организатор тестирования формирует однородную группу n испытуемых из некоторого класса g и предлагает без ограничения общности один тест с определенным числом заданий k различной трудности, обеспечивающих объективное тестирование. Если группе предлагаются несколько равноценных вариантов теста, группой в данный момент считается то множество тестируемых, которое решает один и тот же вариант теста, а после оценки результатов тестирования все подготовленности выравниваются на единой шкале. Математическая модель решения задачи Для оценки трудности заданий и подготовлен- ности испытуемых применяется метод максималь- ного правдоподобия (JML) [3–5]. Кроме того, в системе для оценки трудности заданий могут применяться методы условного максимального правдоподобия (CML) и маргинального максимального правдоподобия (MML), а для оценки подготовленности испытуемых, помимо метода максимального правдоподобия, могут применяться байесовские оценки. В предложенной системе, помимо дихотомической модели Раша, реализованы следующие расширения этой модели: 2- и 3-параметрические модели (модели Бирнбаума), а также 4-параметрическая модель. Кроме того, реализованы такие политомические расширения модели Раша, как модель RSM и модель PCM. Помимо этого, реализованы линеаризованные политомические модели LLTM, LRSM и LPCM. В качестве критериев проверки гипотезы об адекватности модели Раша [6] применяют статистику отношения правдоподобия, статистику Хосмера–Лемешоу, коэффициенты детерминации, ROC-анализ. Число заданий в тесте определяет разрешающую способность теста (РСТ), равную разнице подготовленностей двух испытуемых в логитах, у которых разница в количестве правильных ответов равна 1. Разрешающая способность теста, состоящего из k заданий, зависит только от числа заданий теста и числа испытуемых и принимает значения из интервала Определим понятие наилучшего теста как совокупность заданий с такими трудностями δj1, …, δjk, при которых тест обладает наивысшей разрешающей способностью в данном классе испытуемых N(Mg, σg), его среднеквадратичная ошибка для каждого испытуемого максимально приближена к РСТ среди всех возможных тестов с таким же количеством заданий k. Каждый испытуемый в группе данного класса g должен получить хотя бы одно задание, соответствующее его подготовленности. Чем больше по численности подгруппа испытуемых с близким уровнем подготовленности, тем больше должно быть заданий, соответствующих их подготовленностям. Эти характеристики наилучшего теста показывает его наивысшую дифференцирующую способность при данном количестве заданий k и данной группе данного класса g испытуемых. Критерием оптимальности распределения заданий в тесте в данной группе g по их трудностям естественно принять математическое ожидание квадрата разницы среднеквадратического отклоне- ния ошибки способностей тестируемых от наилучшей точности теста при данном количестве заданий в тесте [7]:
Поэтому система тестирования должна в рекуррентной форме формировать оптимальный набор трудности заданий в текущий момент времени для заданного числа заданий, получая на вход минимально достижимое значение ошибки и вычисленное по итогам прошлого такта значение ошибки. Статистическая обработка результатов тестирования происходит на основе метода максимального правдоподобия. Уравнения правдоподобия имеют вид
На первом такте работы системы набор трудностей заданий теста формируется на основании теоретических предпосылок о гауссовом распределении подготовленности испытуемых. В дальнейшем в соответствии с рекуррентной процедурой стохастической аппроксимации на каждом такте времени t происходит уточнение трудности заданий и параметров нормального распределения подготовленности группы. Функция правдоподобия содержит плотности с теми заданиями, которые встречались на предыдущих тактах времени t. В условии типа равенства трудности заданий варьируемы, а подготовленности принимаются константами, равными последним оценкам, полученным на каком-либо раннем такте времени. При этом узловыми могут оказаться задания из любого числа ранее решаемых тестов в любые предыдущие моменты времени. Это обеспечивает единую шкалу трудности заданий и подготовленности тестируемых. Для введения в систему процесса адаптации параметры класса испытуемых на каждом такте времени t для соответствующего класса g пересчитываются. На этапе формирования теста в каждый момент времени t проверяются следующие условия: 1) σ2(θ, δ1, …, δk(t)) > smin, где smin – предельная дисперсия оценки подготовленности; 2) изменились ли параметры (математическое ожидание и дисперсия) распределения уровня подготовленности тестируемых. При выполнении хотя бы одного из этих условий решается задача оптимизации и тем самым вычисляется оптимальный набор трудностей заданий теста {δj}, где j=1, …, k(t). В каждый такт времени t задача оптимизации решается с начальным условием в виде оптимального набора трудностей заданий теста для такта работы t–1. В качестве начального распределения уровня трудности заданий взято равномерное распределение. Кроме того, перед началом работы системы должен быть подготовлен ряд заданий теста и определена их трудность. Трудность этих заданий может быть определена либо посредством апробации их на стратифицированной нормативной выборке тестируемых, либо на основании экспертной оценки. Стоит отметить, что тестируемые возмущаются некоторой случайной ненаблюдаемой помехой ξ(t): она описывает возможное знание испытуемыми конкретных вопросов теста, возможность угадывания и списывания, психологическое волнение, а также другие случайные факторы. Для учета факторов, мешающих получению объективных оценок подготовленности тестируемых, таких как списывание, подсказки и прочее общение с другими участниками тестирования, применяются результаты исследований по квалиметрии групповой деятельности операторов [8]. Если ввести коэффициент взаимодействия испытуемых Kвз, равный 0 при отсутствии взаимодействия и равный 1 для абсолютного взаимодействия испытуемых, действующих согласованно, как один человек, то при коэффициенте взаимодействия, стремящемся к 1, для соответствующей группы потребуем, чтобы среднеквадратичное отклонение оценок подготовленности тестируемых стремилось к бесконечности. Введенный коэффициент влияет на результаты таким образом: пусть тестируется группа из класса с распределением подготовленности N(Mg, σg), тогда при Kвз = 0 параметры распределения Mg, σg остаются прежними. При 0 Если на каждом такте t коэффициент взаимодействия удовлетворяет условию 0≤Kвз<1 и ранг матрицы ответов не равен 1, а критерий минимизации J(δj1, …, δjk) имеет вид
взаимодействие в группе и прочие случайные факторы приводят к тому, что градиент критерия измеряется со случайной помехой ÑJ(δ1, …, δk)+ + Алгоритм адаптивной системы тестирования
В начале работы очередного такта системы организатор тестирования формирует однородную группу испытуемых. После этого система считывает организационные параметры тестирования: требования к заданиям теста, количеству заданий, содержанию заданий, времени выполнения заданий и т.д. С учетом среднеквадратичной ошибки подготовленностей, полученной на предыдущем такте t–1 работы системы, выполняется шаг стохастической аппроксимации и вычисляются оптимальные значения трудностей заданий теста, на основании которых конструируется оптимальный тест для сформированной однородной группы испытуемых. Тест из сформированных оптимальных заданий предъявляется группе испытуемых и в соответствии с установленным регламентом под наблюдением организатора тестирования в диалоговом сеансе происходит фиксация ответов группы испы- туемых с записью окончательных ответов на задания теста в таблицу БД. По итогам тестирования определяется правильность ответов тестируемых на предъявленные вопросы и формируется матрица ответов. Статистическая обработка полученной матрицы ответов происходит в соответствии с описанными выше алгоритмами, вычисляются подготовленности испытуемых и новые значения трудностей заданий теста. Для сформированной группы испытуемых вычисляются параметры адаптации – интегральные характеристики группы, и в случае их отличия от используемых на данном такте происходит их пе- ренастройка для следующего такта работы си- стемы. Кроме того, вычисляются разница между определенной проектировщиком разрешающей способностью теста и вычисленной ошибкой в результате статистической обработки результатов тестирования, а также качество ответов группы испытуемых с оценкой возможного знания испытуемыми конкретных вопросов теста, угадывания, массового списывания. При отсутствии оснований для аннулирования результатов тестирования группы испытуемых осуществляются определение баллов по метри- ческой шкале и пересчет полученных показателей тестирования в логитах путем линейного преобразования в необходимую метрическую шкалу в баллах. Результаты тестирования предъявляются испытуемым и записываются в таблицу БД.
В таблице dbo.Persons содержатся идентификатор каждого тестируемого и его персональная информация. В таблице dbo.PersonStats хранится информация о том, на каком такте работы системы и в какой группе проходил тестирование испытуемый, а также какую оценку уровня знаний он получил. Таблица dbo.Groups содержит информацию о группах тестируемых и ее свойствах, таких как математическое ожидание уровня знаний и стандартное отклонение. Таблица тактов dbo.Tacts содержит идентификатор очередного такта работы системы и время его начала. При старте очередного такта система формирует для группы тестируемых новый тест и записывает эту информацию в таблицу тестов dbo.Tests. Ответ каждого тестируемого заносится в таблицу dbo.TestResults. Таблица заданий dbo.Questions содержит идентификатор задания, его текст и тип задания, который может быть дихотомическим или политомическим, а также вид задания: задание в отрытой форме, с одним или несколькими правильными ответами, на установление соответствия, на установление правильного порядка. Ответы на все тестовые задания хранятся в таблице ответов dbo.Answers. В каждой строчке хранится либо правильный ответ на вопрос (если запись относится к вопросу в открытой форме), либо вариант ответа. Таблица заданий с вариантами ответов dbo.ClosedQuestions содержит информацию о вариантах ответов на задания и признак правильного или неправильного ответа. Таблица заданий на установление соответствия dbo.MatchingQuestions хранит данные о каждом соответствии для задания. В таблице заданий на установление порядка dbo.OrderingQuestions содержится информация о порядковом номере каждого варианта ответа для задания. Таблица заданий в открытой форме dbo.OpenQuestions хранит данные об ответе на каждую категорию задания, а также балл за эту категорию. Таблица статистики заданий dbo.QuestionStats содержит последнее вычисленное значение трудности категории задания и значение накопленной достаточной статистики, обозначенной в алгоритмах символом c, при последнем вычислении трудности данной категории задания. В заключение отметим, что в данной работе представлено алгоритмическое обеспечение адап- тивной системы тестирования знаний, в которой в определенные моменты времени происходят подготовка и корректировка тестов, тестирование и обработка результатов. В начальном состоянии система имеет лишь экспертные оценки трудности заданий и параметров групп тестируемых. После каждого такта работы системы, помимо вычисления уровня подготовленности тестируемых, в зависимости от состояния системы происходят корректировка состава теста с целью минимизации ошибки оценивания результатов тестирования и уточнение трудности заданий. При этом существенную роль в совершенствовании системы тестирования играет обратная связь, на основе которой вырабатывается управляющее воздействие – набор трудности заданий очередного теста. Оценки трудности и подготовленности в предложенной системе базируются на основе сходящейся процедуры стохастической аппроксимации. Указанные свойства адаптивной системы тестирования знаний гарантируют повышение точности тестирования с течением времени и выравнивание оценок тестируемых на единой шкале. Литература 1. Bond T.G., Fox C.M. Applying the Rasch Model: Fundamental measurement in the human sciences. 3nd Edn. Lawrence Erlbaum, 2015, 406 p. 2. Rasch G. Probabilistic models for some intelligence and attainment tests. Copenhagen, Denmark, Danish Institute for Educational Research Publ., 1960, 199 p. 3. Mair P., Hatzinger R. Extended Rasch Modeling: The eRm Package for the Application of IRT Models in R. Journ. of Statistical Software, 2007, vol. 20, iss. 9, pp. 1–20; DOI: 10.18637/jss.v020.i09. 4. Anderson C.J., Li Z., Vermunt J.K. Estimation of Models in a Rasch Family for Polytomous Items and Multiple Latent Variables. Journ. of Statistical Software, 2007, vol. 20, iss. 6, pp. 1–36; DOI: 10.18637/jss.v020.i06. 5. Johnson M.S. Marginal Maximum Likelihood Estimation of Item Response Models in R. Journ. of Statistical Software, 2007, vol. 20, iss. 10, pp. 1–24; DOI: 10.18637/jss.v020.i10. 6. Mair P., Bentler P.M. IRT Goodness-of-Fit Using Approaches from Logistic Regression. Department of Statistics, UC Los Angeles, 2011, 13 p. 7. Бессарабов Н.А., Бондаренко А.В., Кондратенко Т.Н., Тимофеев Д.С. Алгоритм конструирования критериально-ориентированного теста // Вестн. компьютер. и информ. технологий. 2014. № 7. С. 42–48. 8. Багрецов С.А., Бондаренко А.В., Обносов Б.В. Квалиметрия групповой деятельности операторов сложных систем управления. М.: Физматлит, 2006. 384 с. 9. Поляк Б.Т., Цыпкин Я.З. Оптимальные псевдоградиентные алгоритмы адаптации // Автоматика и телемеханика. 1980. № 8. С. 74–84. 10. Поляк Б.Т. Сходимость и скорость сходимости итеративных стохастических алгоритмов. I. Общий случай // Автоматика и телемеханика. 1976. № 12. С. 83–94. |
 который и определяет нижний предел дифференцирующей способности теста. Эта величина напрямую не зависит от трудности заданий. К этому пределу и нужно стремиться при проектировании теста. При этом дисперсия ошибки оценивания подготовленности определяется трудностями заданий теста.
который и определяет нижний предел дифференцирующей способности теста. Эта величина напрямую не зависит от трудности заданий. К этому пределу и нужно стремиться при проектировании теста. При этом дисперсия ошибки оценивания подготовленности определяется трудностями заданий теста.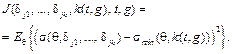
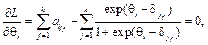 где i=1, …, n,
где i=1, …, n,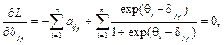 где f=1, …, k, с условиями типа равенства, учитывающими информацию, полученную в предыдущие моменты времени:
где f=1, …, k, с условиями типа равенства, учитывающими информацию, полученную в предыдущие моменты времени: 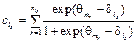 , где s=1, …, d,
, где s=1, …, d,  ,
, 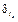 и
и  – вышеописанные атрибуты ранее вычисленных трудностей.
– вышеописанные атрибуты ранее вычисленных трудностей.
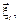 где
где 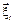 – независимые случайные величины с ограниченной дисперсией, то процедура стохастической аппроксимации для поиска оптимального вектора
– независимые случайные величины с ограниченной дисперсией, то процедура стохастической аппроксимации для поиска оптимального вектора  :
:  , где множители γt удовлетворяют условиям
, где множители γt удовлетворяют условиям  сходится при t→∞ в любой группе g почти, наверное, к оптимальному
сходится при t→∞ в любой группе g почти, наверное, к оптимальному 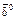 [9, 10]. Кроме того, при t→∞ в любой группе g вектор
[9, 10]. Кроме того, при t→∞ в любой группе g вектор 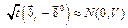 асимптотически нормален, где матрица
асимптотически нормален, где матрица 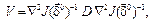 D – матрица дисперсий шума
D – матрица дисперсий шума 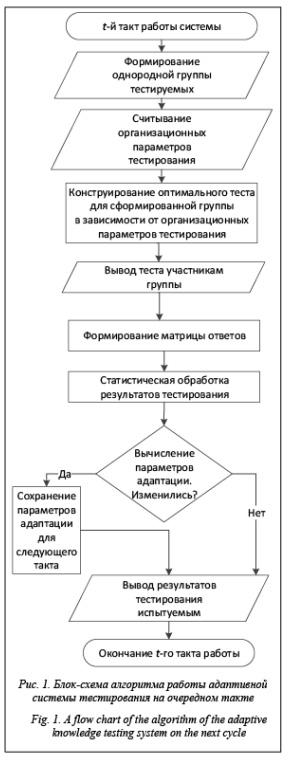

| Permanent link: http://swsys.ru/index.php?id=4112&lang=en&page=article |
Print version Full issue in PDF (8.31Mb) Download the cover in PDF (1.24Мб) |
| The article was published in issue no. № 1, 2016 [ pp. 68-74 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Оптимизация системы тестов при квалификационном тестировании специалистов
- Инструментарий для определения лингво-статистической близости языков с использованием модели тюркской морфемы
- Алгоритмическое и программное обеспечение символьных вычислений для логического дифференциального и интегрального исчислений
- Сравнительный анализ СУБД для туристической социальной сети
- Временной анализ обработки конфликтных транзакций в Oracle Enterprise Manager и Errmanager
Back to the list of articles