Journal influence
Bookmark
Next issue
Natural language user interface of a dialogue system
Abstract:Many people interact with software every day. Due to computer systems expansion to all fields of people’s activity the problem of transition from visual and command interfaces to natural language user interfaces is becoming more and more relevant. The article describes computational linguistics and natural language processing methods. It considers all phases of natural language processing such as morphological, syntactic and semantic analysis. Limited language is represented as a subset of natural language. This language allows avoiding linguistic uncertainty and decreases natural language elements processing time. Translation system is a part of a dialogue system. Methods of natural language manipulation are applied in machine translation software systems, search engines, data exchange, automatic abstracting and expert systems. The paper represents a formal definition of a dialogue system as a Markov decision process. The authors developed a prototype of natural language user interface for a structured data source. It converts natural language user’s query into SQL query to database. User interface interacts with a database that contains information about existent program libraries and frameworks. Consequently, using natural language processing methods makes it possible to develop natural language user interface providing a capability to interact with a dialogue system.
Аннотация:Множество людей ежедневно взаимодействуют с различными программными системами. В результате внедрения компьютерных систем во все сферы человеческой жизни все больше проявляется проблема перехода от визуальных и командных интерфейсов к естественно-языковым. В статье рассмотрены методы компьютерной лингвистики и обработки естественного языка. Представлено полное описание всех стадий обработки естественного языка, таких как морфологический, синтаксический и семантический анализ. Рассмотрен ограниченный язык как подмножество естественного языка, на котором текст хорошо воспринимается носителем естественного языка без дополнительных усилий. Подобное решение позволяет сократить время анализа естественно-языковых элементов в диалоговой системе, а также помогает избежать неоднозначностей на лингвистическом уровне. Методы для работы с естественным языком могут применяться в программных системах машинного перевода, поисковых системах, системах автоматического реферирования и в экспертных системах. Представлено формальное описание диалоговой системы в контексте марковского процесса принятия решений. Разработан прототип естественно-языкового пользовательского интерфейса, который производит преобразования пользовательского запроса на естественном языке в SQL-запрос к БД. Интерфейс взаимодействует с БД, содержащей информацию о существующих программных библиотеках и фреймворках. Таким образом, использование методов обработки естественного языка позволяет разработать естественно-языковой пользовательский интерфейс для взаимодействия с диалоговой системой.
| Authors: Posevkin R.V. (rus_posevkin@mail.ru) - The National Research University of Information Technologies, Mechanics and Optics, St. Petersburg, Russia, Bessmertny I.A. (bia@cs.ifmo.ru) - The National Research University of Information Technologies, Mechanics and Optics (Professor), St. Petersburg, Russia, Ph.D | |
| Keywords: dialogue system, natural language processing, user interface, database |
|
| Page views: 15414 |
Print version Full issue in PDF (6.81Mb) Download the cover in PDF (0.36Мб) |
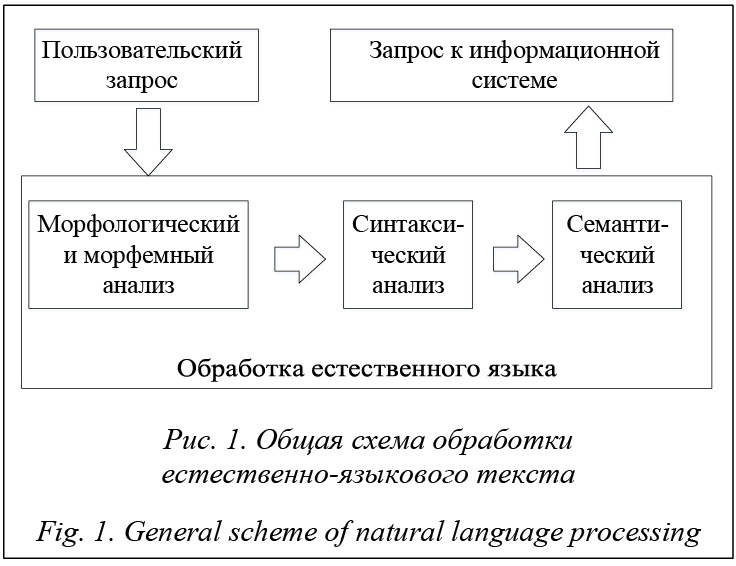
Существует большое количество программных систем, каждая из которых обладает характерными именно для нее принципами взаимодействия. В результате свободное использование системы затрудняется и увеличивается время, необходимое на обучение пользователя работе с ней. Одним из вариантов решения проблемы взаимодействия с компьютерной системой является использование естественного языка, более привычного для пользователя. Такое решение имеет следующие преимущества: - минимальная подготовка пользователя для работы с системой; - высокая скорость и простота формирования произвольных запросов к системе. Простота при работе с естественно-языковым пользовательским интерфейсом достигается путем применения пользователем языка, используемого в ежедневной коммуникации [1]. Для естественно-языкового пользовательского интерфейса диалоговых систем возможно использование ограниченной лексики и грамматики языка. При этом не происходит серьезного ухудшения функциональности и производительности вопросно-ответной системы. Ограниченный естественный язык – это подмножество естественного языка, на котором текст воспринимается носителем естественного языка без дополнительных усилий. При этом не требуется изучение ограниченной версии языка для составления текстов. Данный язык обладает сокра- щенным набором лексики и грамматики, что позволяет сократить время анализа естественно-языковых элементов в диалоговой системе, а также избежать неоднозначностей на лингвистическом уровне [2]. Цикл работы естественно-языкового пользовательского интерфейса начинается с ввода пользователем текста сообщения на естественном языке. На основе введенного текста строится его формальное описание. При этом все предшествующие результаты анализа используются при анализе последующих запросов, что позволяет системе сохранять нить диалога с пользователем и разрешать неоднозначные и спорные моменты, связанные с различным использованием одних и тех же слов в разных предметных областях [3]. В процессе обработки естественно-языкового текста последовательно выполняется морфологический, синтаксический и семантический анализ. Общая схема работы системы представлена на рисунке 1.
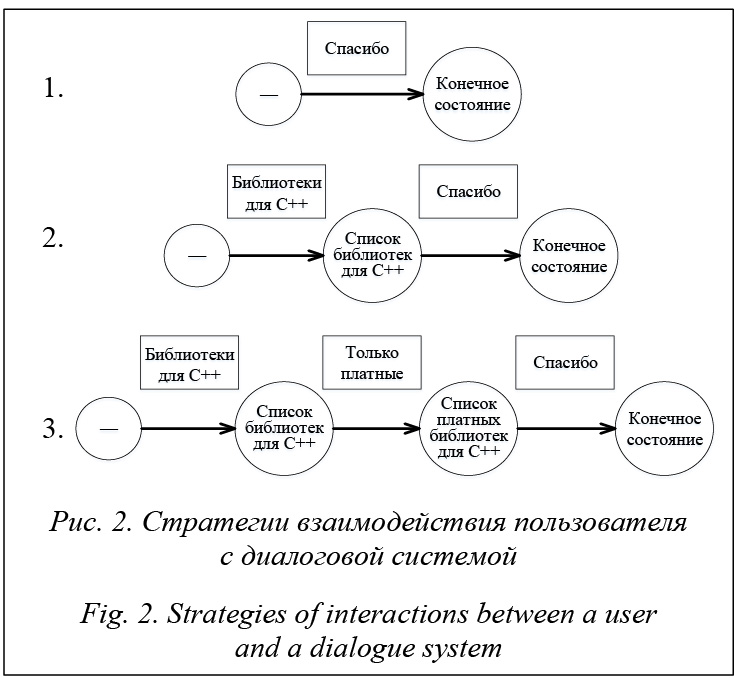
На первом этапе обработки пользовательского запроса осуществляется морфологический и морфемный анализ. Для каждого слова предложения в формальной записи строятся отношения, задающие соответствия для значений грамматических категорий [4]. В результате морфологического анализа определяются морфологические характеристики каждого слова, такие как падеж, склонение, часть речи и т.д. Количество и наличие морфологических характеристик слов и допустимых значений зависят от конкретного языка. Однако некоторые характеристики, например часть речи, существуют во многих языках. Для проведения морфологического анализа текста существуют следующие подходы: четкая морфология, нечеткая морфология, вероятностный подход. При обработке естественно-языковых текстов на русском языке наиболее часто применяется подход, основанный на четкой морфологии и базирующийся на словаре Зализняка. В этом словаре описаны основные словоформы для слов русского языка. Каждой такой словоформе сопоставляется определенный код. Существует система правил, в соответствии с которой для слова можно построить все остальные формы [5]. В качестве исходных данных используются начальная словоформа и соответствующий ей код. В случае использования четкого подхода в процессе морфологического анализа необходимо иметь в наличии словарь всех словоформ и слов для данного языка. Словарь на входе принимает форму слова, а на выходе представляет морфологические характеристики конкретной словоформы. Возможно построение словаря на основе словаря Зализняка по следующему алгоритму. Сначала перебираются все слова, содержащиеся в словаре. Для каждого из этих слов выделяются все допустимые словоформы и сохраняются в формируемом словаре. В процессе морфологического анализа конкретного слова достаточно найти его в словаре. В результате будут получены точные значения всех морфологических характеристик анализируемого слова. При морфемном анализе для каждого слова выделяются морфемы: приставка, корень, суффикс, окончание. В словаре морфем русского языка для каждого слова указано разделение на составные части. При этом в словаре не указываются типы каждой из составных частей. Таким образом, достоверно неизвестно, какая из частей является суффиксом, а какая корнем. Совокупность всех возможных корней слов русского языка представляет собой открытое множество. В то же время множество всех приставок, суффиксов и окончаний ограничено. Также известен порядок следования морфем в составе слова на русском языке: приставки, затем корни, суффиксы и окончания. Таким образом, с помощью словаря морфем русского языка можно построить словарь, содержащий информацию как о разбиении слова на составные части, так и о типе каждой из морфем. В результате для проведения морфемного анализа слова достаточно использовать разработанный словарь. В случае отсутствия слова в словаре возможен непосредственный анализ на основе стандартного строения слов русского языка (приставка – корень – суффикс – окончание) и множества всех приставок, суффиксов и окончаний [6]. На этапе синтаксического анализа выделяются отношения синтаксических связей внутри предложения. Далее определяются главные и второстепенные члены предложения, тип предложения. Синтаксический анализ выполняется поэтапно: при описании формальной структуры предложения используется полученная на этапе морфологического анализа информация. На данном этапе используются синтаксические и лексические правила анализируемого языка. Далее следует наиболее сложная часть обработки естественно-языкового текста – этап семантического анализа, который можно рассматривать как обработку семантической сети. В свою очередь, семантическая сеть представляет собой результат анализа естественно-языкового текста на предыдущих этапах и присутствующих в системе знаний о предметной области и языке программной системы. На данном этапе анализируются соотношения лингвистической конструкции и хранимых в памяти системы конструкций, предназначенных для выявления отношений соответствия. В процессе построения семантической модели слова учитывается его многозначность. Смысл слова рассматривается как множество различных значений. Вся совокупность этих значений в целом или каждое из них реализуется в определенном контексте. Результатом семантического анализа является конструкция запроса к информационной системе. Система преобразования естественно-языкового текста в запрос к БД является частью диалоговой системы. Рассмотрим диалоговую систему в контексте марковского процесса принятия решений. Данный процесс представлен в виде диалога, конечная цель которого – получение пользователем списка библиотек за наименьшее количество возможных итераций. В рассматриваемом примере пользователь формирует запрос с использованием значений «язык программирования» и «тип лицен- зий» в качестве фильтра. Марковский процесс принятия решений описывается в терминах пространства состояний, набора действий и стратегии. Состояния диалоговой системы затрагивают все ресурсы, с которыми взаимодействует пользователь [7]. Полный набор состояний диалоговой системы может включать в себя: - одно начальное состояние; - различные комбинации списков библиотек, формируемых в зависимости от начальных значений и используемого фильтра; - специальное состояние, обозначающее окончание работы текущей диалоговой сессии. В данном примере рассматриваются такие состояния диалоговой системы, как список библиотек, выбранных с применением фильтров «язык программирования» и «тип лицензии». В качестве возможных действий с диалоговой системой рассматриваются взаимодействие пользователя с системой (например, ввод пользователем запроса к системе, предоставление системой ответа на пользовательский запрос, уведомления), взаимодействие системы с внешними ресурсами (например, отправка запроса к БД), внутренняя обработка данных [8]. В предлагаемом примере возможен следующий набор действий с диалоговой системой. 1. Пользовательский запрос к системе на получение списка программных библиотек для определенного языка программирования. 2. Пользовательский запрос к системе на получение списка программных библиотек, распространяемых в соответствии с запрашиваемым типом лицензии. 3. Пошаговые запросы, когда пользователь запрашивает список программных библиотек для конкретного языка программирования, а затем отбирает из них только библиотеки с определенным типом лицензии (или в обратном порядке). 4. Финальное действие, завершающее текущую сессию диалога с программной системой. Когда действие a производится над системой в состоянии s, система переходит в состояние s’. В подобной ситуации вероятность перехода описывается формулой PT (s(t+1) = s’ | s(t) = s, a(t) = a). (1) Диалоговая сессия представляет собой длину пути при переходе пользователя из начального в конечное состояние диалоговой системы. При этом диалоговая стратегия отображает, какое действие будет совершено для перехода в каждое последующее состояние программной системы. Производительность системы можно измерить с помощью целевой функции C, где веса Ci представляют собой расстояние до достижения конечной цели. Таким образом, эффективность взаимодействия пользователя с диалоговой системой рассчитывается по формуле C = ∑ Ci. (2) В целом веса в марковском процессе принятия решений описываются условным распределением PC (c(t) = c | s(t) = s, a(t) = a). (3) Совокупность из четырех состояний системы, набора вариантов взаимодействий с системой, вероятностей перехода и распределения весов определяют марковский процесс принятия решений. Для рассматриваемого примера целевая функция представлена как C = Wi × <# interactions> + We × ×<# errors> + Wf × <# incomplete values>. (4) Целевая функция включает в себя три компонента: первый – ожидаемая продолжительность диалога, второй – предполагаемое количество ошибок в полученных данных, третий – предполагаемое расстояние до получения пользователем целевого результата от диалоговой системы. В зависимости от соответствия целевой функции диалоговой модели возникает связь веса c с совершаемым взаимодействием a пользователя с системой, находящейся в состоянии s. Вес включает в себя любое из первых трех действий с диалоговой системой: Wi + We × number of errors. Рассмотрим понятие веса ошибок для определения значений с применением фильтров по отдельности (для действий 1 и 2) – это p1, и совместно (для действия 3) – это p2, при этом p2 > p1. Тогда ожидаемый вес для взаимодействий 1 и 2 будет представлен как Wi +We × p1, для действия 3 – Wi + + 2 × We × p2. Для действия 4 (закрытие диалоговой сессии) вес зависит от состояния диалоговой системы, в котором произошло взаимодействие. Так, для начального состояния вес будет выражен как Wi + 2 × Wf. Для случаев, когда был применен только один из фильтров («язык программирования» или «тип лицензии»), вес определяется как Wi + Wf. В случае применения обоих фильтров вес представлен как Wi.
В стратегии 2 пользователь запрашивает список библиотек с использованием одного из фильтров, а затем закрывает диалоговую сессию. В данном случае C2 = 2 × Wi + 2× p2 × We. В стратегии 3 пользователь запрашивает список программных библиотек с использованием как фильтра «язык программирования», так и «тип лицензии» и после этого закрывает диалоговую сессию. В текущей ситуации целевая функция имеет следующий вид: C3 = 3 × Wi + 2 × p1 × We. Стратегия 3 оптимальна, когда верно выражение p2 − p1 > > Wi / 2 × We. Существуют различные методы вычисления оптимальной стратегии с учетом корректных параметров модели (вероятности перехода и распределения весов), среди которых алгоритм итераций по критерию или итерации по стратегиям. Данные подходы основаны на динамическом программировании, которое может быть использовано благодаря марковскому характеру представленной модели [9]. Подходы основаны на следующем определении: оптимальное значение V(s) состояния диалоговой системы s представляет собой минимальный ожидаемый вес, формируемый начиная с момента, когда система перешла из состояния s, и до тех пор, пока не достигла финального (конечного) состояния. Оптимальное значение функции уникально и может быть определено как решение системы уравнений:
где áC(s, a)ñ – ожидаемый вес для взаимодействия a в состоянии s [10]. В рамках исследований разработан прототип программной системы, реализующей естественно-языковой пользовательский интерфейс к структурированному источнику данных. В качестве исходных данных представлена БД MySQL, которая содержит информацию о су- ществующих программных библиотеках и фреймворках. Тестовая БД содержит в себе таблицу, имеющую следующие поля: уникальный идентификатор, имя, ссылка на официальный сайт или репозиторий, дата создания, автор, тип лицензии, тип записи (библиотека или фреймворк), размер, список зависимостей, язык программирования, наличие активного сообщества разработчиков. Значением, получаемым на выходе програм- мной системы, является SQL-запрос к БД. Одно из необходимых условий для работы системы – наличие структуры данных, описывающей содержимое БД. В частности, необходимо описание таблицы и входящих в нее полей. Сложные предложения на естественном языке не используются в пользовательском запросе к базе в рамках естественно-языкового пользовательского интерфейса. Несмотря на то, что требуется создание лингвистического анализатора в виде преобразователя, состоящего из двух видов абстракции – морфологической и синтаксической [11], каждый из уровней абстракции должен иметь в наличии компонентную модель с набором правил и библиотек и определенный образ запросов в виде морфологических и синтаксических структур. Также не требуется фаза семантического анализа за счет того, что известна предметная область. Таким образом, лингвистический анализатор можно назвать лингвистическим преобразователем (транслятором). Добиться приемлемого уровня обработки ес- тественного языка возможно без использования полного грамматического анализа. Достаточно извлечь наиболее информативные части предло- жения, такие как ключевые слова, фразы и фрагменты. Следующим шагом является создание морфологических и синтаксических моделей с использованием морфологических и синтаксических методов анализа. Например, пользовательский запрос на естественном языке «Показать библиотеки для С++» будет преобразован в SQL-запрос к БД SELECT Name, Url FROM Data WHERE Type=’library’ AND Language=’cpp’ . Таким образом, естественно-языковой пользовательский запрос на русском языке преобразуется в SQL-запрос, который в дальнейшем может быть отправлен к БД. В результате разработанная программная система реализует естественно-языковой пользовательский интерфейс к БД. Подобная система может применяться в областях, где требуется обеспечить доступ пользователя к информации из определенной предметной области. Например, возможна реализация естественно-языкового интерфейса для аналитической программной системы. Введя запрос на естественном языке, пользователь получает отчет, выборку по данным за определенный временной период. В результате, применяя методы обработки естественно-языкового текста, можно создать программный интерфейс, обеспечивающий взаимодействие пользователя с программной системой на естественном языке. Литература 1. Bessmertny I. On constructing intellectual systems in ternary logic. Programming and Computer Software, 2014, vol. 40, no. 1, pp. 43–46. 2. Deshpande A.K., Devale P.R. Natural language query processing using probabilistic context free grammar. Intern. Journ. of Advances in Engineering & Technology. 2012, vol. 3, no. 2, pp. 568–573. 3. Житко В.А. Пользовательский интерфейс интеллектуальных вопросно-ответных систем // NB: Кибернетика и программирование. 2012. № 1. С. 23–30. 4. Крайванова В.А. Модель естественно-языкового интерфейса для систем управления сложными техническими объектами и оценка эффективности алгоритмов на ее основе // Управление большими системами. М.: Изд-во ИПУ РАН, 2009. Вып. 26. С. 158–178. 5. Damljanovic D., Agatonovic M., and Cunningham H. FREyA: An interactive way of querying Linked Data using natural language. Proc. 8th Intern. conf. on the Semantic Web: ESWC 2011. Springer Berlin Heidelberg, 2012, pp. 125–138. 6. Селезнев К. Обработка текстов на естественном языке // Открытые системы. 2003. № 12; URL: http://www.osp.ru/os/ 2003/12/183694/ (дата обращения: 27.02.2016). 7. Li F., Jagadish H.V. NaLIR: An interactive natural language interface for querying relational databases. Proc. 2014 ACM SIGMOD Intern. conf. on Management of data, ACM, 2014, pp. 709–712. 8. Dezhao S., Schilder F., Smiley C., Brew C., Zielund T., Bretz H., Martin R., Dale C., Pomerville S., Duprey J., Miller T., and Harrison J. TR Discover: a natural language interface for querying and analyzing interlinked datasets. Proc. 14th Intern. conf. on the Semantic Web: ISWC 2015, Springer Intern. Publ., 2015, pp. 21–37. 9. Kesavan S., Giudice N.A. Indoor scene knowledge acquisition using a natural language interface. SKALID 2012 – Spatial Knowledge Acquisition with Limited Information Displays, 2012, pp. 1–6. 10. Levin E., Pieraccini R., Eckert W. Learning dialogue stra- tegies within the Markov decision process framework. Automatic Speech Recognition and Understanding IEEE Proc., 1997, pp. 72–79. 11. Елисеева О.Е. Естественно-языковой интерфейс интеллектуальных систем: учеб. пособие. Минск: Изд-во БГУИР, 2009. С. 84–85. |
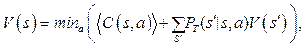 (5)
(5)| Permanent link: http://swsys.ru/index.php?id=4170&lang=en&page=article |
Print version Full issue in PDF (6.81Mb) Download the cover in PDF (0.36Мб) |
| The article was published in issue no. № 3, 2016 [ pp. 5-9 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Метод автоматизированного формирования семантической модели базы данных диалоговой системы
- Компоненты и функциональность программного средства моделирования структуры импортозамещения
- Контекстное ранжирование ответов по относительным метрикам в диалоговых системах помощи пользователям
- Алгоритмическое обеспечение адаптивной системы тестирования знаний
- Оптимизирующие стратегии визуализации данных в тактическом тренажере
Back to the list of articles