Journal influence
Bookmark
Next issue
A contracted representation of strong associative rules in data analysis
Abstract:Modern methods and means of searching for association rules in big data lead to a significant number of rules, many of which are redundant. Redundant association rules are generally of no value, but they can misinform. To solve this problem, the paper proposes an algorithm MClose, which is a modification of the algorithm Close. It is known that Close algorithm might help to construct mini-max basis for strict association rules (association rules with the confidence of 1). Mini-max basis consists of only min-max association rules. Association rules with minimal antecedent and maximal consequent are called min-max association rules. Such rules are interesting for experts. However, mini-max basis may contain redundant association rules. The algorithm MClose immediately eliminates redundant association rules when creating mini-max basis. The resulting basis is called concise strong basis (CSB). Redundant association rules might always be obtained from the CSB without sacrificing their support and confidence, without references to the data set. Algorithm MClose is based on Galois connection. MClose algorithm is also based on derivability, which are similar on Armstrong axioms for functional dependencies. Experiments have shown that running time of algorithm MClose is comparable with the algorithm Close. However, it reduces the number of association rules mini-max basis about twice. We provide a description of the program which presents MClose and Close algorithms.
Аннотация:Современные методы и средства поиска ассоциативных правил в больших массивах данных приводят к значи- тельному множеству правил, многие из которых являются избыточными. Избыточные ассоциативные правила не представляют ценности, но могут вводить в заблуждение. Для решения этой проблемы предложен алгоритм MClose, являющийся модификацией алгоритма Close. Известно, что с помощью алгоритма Close можно построить минимаксный базис для строгих ассоциативных правил (правил с достоверностью 1). Минимаксный базис интересен для экспертов тем, что каждое входящее в него правило имеет минимальную посылку и максимальное следствие. Однако минимаксный базис может содержать избыточные ассоциативные правила. Алгоритм MClose позволяет в процессе построения минимаксного базиса устранять избыточные правила. Результирующий базис назван сжатым строгим базисом. Удаленные ассоциативные правила всегда можно получить из сжатого строгого базиса с сохранением их поддержки и достоверности без обращений к анализируемому массиву данных. Алгоритм MClose основан на соответствиях Галуа и выводимостях, подобных аксиомам Амстронга, которые используются в теории реляционных БД для функциональных зависимостей. Как показали вычислительные эксперименты, алгоритм MClose по времени работы сопоставим с алгоритмом Close. Однако он примерно в два раза уменьшает число ассоциативных правил минимаксного базиса. В работе дано описание программы, в которой представлены алгоритмы MClose и Close.
| Authors: Bykova V.V. (bykvalen@mail.ru) - Siberian Federal University (Professor), Krasnoyarsk, Russia, Ph.D, Kataeva A.V. (kataeva_av@mail.ru) - Krasnoyarsk Regional Clinical Hospital (Engineer-Programmer), Krasnoyarsk, Russia | |
| Keywords: data analysis, galois connection, closed sets, association rules, non-redundancy, concise strong basis |
|
| Page views: 10783 |
PDF version article Full issue in PDF (17.16Mb) Download the cover in PDF (0.28Мб) |
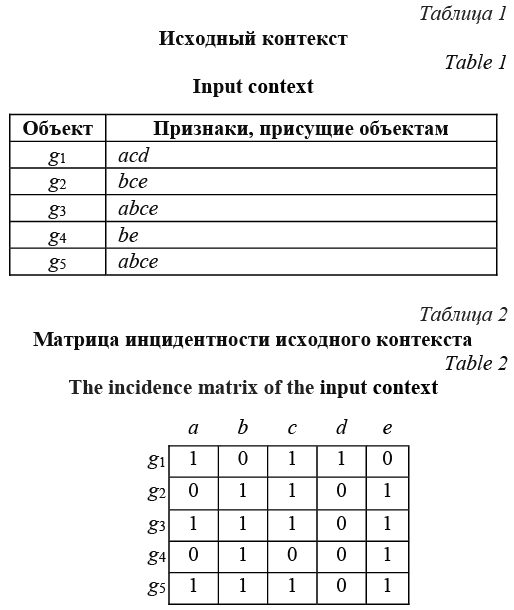
Интеллектуальный анализ данных направлен на исследование больших объемов информации с целью выявления зависимостей между данными. Ассоциативные правила (association rule) - один из хорошо изученных классов зависимостей, которые отражают, какие признаки или события встречаются совместно и насколько часто это происходит. В настоящее время ассоциативные правила нашли широкое применение в медицине, информационной безопасности, анализе компьютерных сетей и маркетинге при решении задач диагностики и прогнозирования [1–3]. При поиске ассоциативных правил анализируемое множество данных обычно описывается бинарным контекстом – матрицей, строки которой соответствуют объектам рассматриваемой предметной области, а столбцы – признакам этих объектов. Единичное значение элемента матрицы трактуется как наличие у объекта соответствующего признака, а нулевое - как его отсутствие. Бинарное представление данных значительно расширяет математический аппарат для их исследования. Современные методы поиска ассоциативных правил базируются преимущественно на анализе формальных понятий и теории вероятностей [4, 5]. Анализ формальных понятий, как прикладная ветвь алгебраической теории решеток, является удобным математическим аппаратом описания методов поиска ассоциативных правил [6–8]. Главная проблема при поиске ассоциативных правил - огромное число правил, возникающих при исследовании больших бинарных контекстов. Это существенно усложняет экспертный анализ выявленных ассоциативных правил. Для решения этой проблемы используются различные меры значимости, такие как поддержка (support) и достоверность (confidence) [9]. С их помощью найденные ассоциативные правила фильтруются, и для анализа предъявляются только те, для которых значения мер значимости превышают заданные пороговые значения. Подобная фильтрация, конечно, уменьшает число правил, но не решает проблему размерности полностью. Не помогает и расширение мер значимости [10]. Часто после фильтрации все равно остается значительное число ассоциативных правил, при этом многие из них избыточные. Ассоциативное правило считается избыточным, если его удаление из множества правил не приводит к потере информации о связях между данными в рассматриваемой предметной области. Существуют различные формальные определения избыточных ассоциативных правил и методы их устранения [11]. Наиболее развиты методы устранения избыточности для строгих ассоциативных правил (strong association rules). Такие правила имеют достоверность 1 и считаются самыми важными. Для этих правил имеются плотная параллель с функциональными зависимостями из теории реляционных БД, а также четкое понятие избыточности [12]. Строгие ассоциативные правила представляют интерес для тех приложений, где требуется высокая степень уверенности в обнаруженных зависимостях между данными, например, в медицине и информационной безопасности [1–3]. Множество ассоциативных правил, не содержащее избыточных (в некотором смысле) правил, принято называть базисом. В настоящее время известен ряд алгоритмов, позволяющих строить различные базисы для строгих ассоциативных правил. Наиболее значимыми являются канонический и минимаксный базисы. Канонический базис (или базис Дюкена–Гига) состоит из минимального числа ассоциативных правил, рекуррентно опи- сываемых в терминах псевдосодержаний [13]. Канонический базис глубоко исследован в анализе формальных понятий, однако все предложенные на сегодняшний день алгоритмы его построения в большей степени представляют теоретический, чем практический интерес [14]. Минимаксный базис состоит из строгих ассоциативных правил, имеющих минимальную посылку и максимальное следствие [15]. Для построения минимаксного базиса существует ряд хорошо апробированных практикой алгоритмов. К ним относится, например, алгоритм Close [11, 16]. Исследования по- казали, что в построенных канонических и минимаксных базисах остается некоторая избыточность, которая может быть устранена на основе выводимостей, подобных аксиомам Амстронга, известным в теории реляционных БД для функциональных зависимостей. В данной статье для строгих ассоциативных правил предложен алгоритм MClose - модификация известного алгоритма Close. Алгоритм MClose позволяет в процессе построения минимаксного базиса устранять избыточность с сохранением поддержки и достоверности без дополнительного обращения к исходному бинарному контексту. Результирующий базис назван сжатым строгим базисом. Введено понятие избыточного ассоциативного правила. Приведены выводимости, доказывающие корректность предлагаемого алгоритма, а также результаты вычислительных экспериментов. Поскольку алгоритм Close основан на анализе формальных понятий, необходимые определения и обозначения этой теории возьмем из работ [6–8]. Основные определения и обозначения анализа формальных понятий Пусть для некоторой предметной области определены два непустых конечных множества G и M, объектов и признаков соответственно. Предполагаем, что все объекты в G и признаки в M различны. Пусть задано отношение I Í G × M инцидентности между множествами G и M. Существование в I пары (g, m), g Î G и m Î M, означает, что объект g имеет признак m и, наоборот, признак m характерен для объекта g. Тройку K = (G, M, I) принято называть контекстом предметной области. Выберем в K = (G, M, I) два любых элемента g Î G и m Î M. Определим для них два отображе- ния j и y: j(g) = {m Î M | (g, m) Î I} – множество признаков, присущих объекту g; y(m) = {g Î G | (g, m) Î I} – множество объектов, обладающих признаком m. Отображения j и y обобщаются на произвольные множества A Í G и B Í M следующим образом: j(A) = Ç g Î A j(g) = {m Î M | "g Î A (g, m) Î I}, y(B) = Ç m Î B y(m) = {g ÎG | "m Î B (g, m) ÎI}. Следовательно, j(A) - множество признаков, общих для всех объектов из A, а y(B) - множество объектов, которые обладают всеми признаками из B. Полагаем, что j(Æ) = M и y(Æ) = G: пустому множеству объектов присущи все признаки из M и каждый объект рассматриваемого контекста K = (G, M, I) обладает пустым множеством признаков. Обычно в анализе формальных понятий для отображений j и y применяется единое обозначение (×)¢, а приведенные выше формулы для j(A), y(B) записываются так: A¢ = Ç g Î A g¢ = {m Î M | "g Î A (g, m) Î I}, (1) B¢ = Ç m Î B m¢ = {g Î G | "m Î B (g, m) Î I}. (2) Если g Î G и m Î M, то обозначения g¢ и m¢ служат сокращенной формой записи множеств j(g) = = {g}¢ и y(m) = {m}¢ соответственно. Отображения «¢» удовлетворяют свойствам, вытекающим из их определения и вполне реалистичного и постулируемого в анализе данных положения: расширение (сокращение) множества признаков уменьшает (увеличивает) число объектов, обладающих этими признаками. Формально эти свойства можно выразить в виде следующих утверждений. Утверждение 1. Для всякого контекста K = (G, M, I) и любых B1, B2 Í M верны свойства: - антимонотонность: если B1 Í B2, то (B2)¢ Í (B1)¢; - экстенсивность: B1 Í (B1)¢¢, где (B1)¢¢ = ((B1)¢)¢ Í M. Множество (B1)¢¢ = j(y(B1)) можно трактовать как набор признаков, которые всегда появляются в объектах контекста K = (G, M, I) вместе с признаками из B1, причем это множество является наибольшим по включению в пределах K = (G, M, I). Очевидно, что (Æ)¢¢ = j(y(Æ)) = G¢, где G¢ - множество признаков, свойственных всем объектам из G. Для подмножеств множества G справедливо утверждение 2, аналогичное утверждению 1. Утверждение 2. Для всякого контекста K = (G, M, I) и любых A1, A2 Í G верны свойства: - антимонотонность: если A1 Í A2, то (A2)¢ Í (A1)¢; - экстенсивность: A1 Í (A1)¢¢, где (A1)¢¢ = ((A1)¢)¢ Í G. Множество (A1)¢¢ = y(j(A1)) можно интерпретировать как наибольшее по включению множество объектов, обладающих всеми признаками, которые имеют объекты из A1. Заметим, что, согласно утверждениям 1 и 2, отображения j и y составляют пару соответствий Галуа между множествами 2G и 2M, частично упорядоченными по включению [6, 7]. Здесь традиционно 2G и 2M – совокупность всех подмножеств рассматриваемых множеств G и M соответственно. Известно, что для соответствий Галуа [7] j и y справедливо равенство j(y(j(A))) = j(A), y(j(y(B))) = y(B), или в единых обозначениях ((A¢)¢)¢ = (A¢¢)¢ = A¢, ((B¢)¢)¢ = (B¢¢)¢ = B¢. Двойное применение отображения «¢» определяет оператор замыкания на 2M в алгебраическом смысле [8]. Ему присущи - рефлексивность: для любого B Í M всегда B Í B¢¢; - монотонность: если B1 Í B2 Í M, то (B1)¢¢ Í (B2)¢¢ Í M; - идемпотентность: для любого B Í M всегда (B¢¢)¢¢ = B¢¢. Справедливость этих свойств вытекает из утверждений 1 и 2. Множество признаков B Í M, для которого B = B¢¢, называется замкнутым относительно оператора «¢¢» в контексте K = (G, M, I). Принято говорить, что множество B¢¢ является замыканием для B Í M в контексте K = (G, M, I). Заметим, что, исходя из (1) и (2), при B¢ ¹ Æ замыкание для B Í M можно вычислить по формуле B¢¢ = Ç g Î G {g¢ | B Í g¢}. (3) Если B¢ = Æ, то всегда B¢¢ = j(y(B)) = j(Æ) = M. Важно отметить, что применение формулы (3) позволяет найти для заданного множества приз- наков замыкание за один просмотр контекста K = (G, M, I). Ассоциативные правила и основные меры их значимости Определим ассоциативное правило, используя приведенные выше понятия и обозначения. Ассоциативным правилом на множестве признаков контекста K = (G, M, I) называется упорядоченная пара r = (X, Y), X, Y Í M. Принято ассоциативное правило r = (X, Y) записывать в виде Х ⇒ Y. В ассоциативном правиле Х ⇒ Y множества Х и Y называют посылкой (или причиной) и заключением (или следствием) соответственно [9]. В анализе ассоциативных правил часто полагают, что посылка и заключение – непустые непересекающиеся множества. С формальных позиций эти ограничения несущественны. Применительно к заданному контексту K = (G, M, I) всякое ассоциативное правило Х ⇒ Y количественно характеризуется с помощью двух числовых функций: d(Х ⇒ Y) - поддержка, γ(Х ⇒ Y) - достоверность [10]. Поддержка и достоверность ассо- циативного правила определяются через понятие поддержки множества признаков. Поддержка d(X) множества признаков X Í M в контексте K = (G, M, I) - отношение числа объектов, которым присущи признаки X, к общему числу объектов, представленных в этом контексте: d(Х) = |Х¢| / |G|. (4) Величину d(Х) можно интерпретировать как частоту встречаемости в контексте K = (G, M, I) объектов, имеющих признаки Х. Из формулы (4) следует, что для любого X Í M значение d(Х) неизменно находится в естественных границах 0 £ d(Х) £ 1. Чем ближе значение d(Х) к 1, тем большее число объектов рассматриваемого контекста обладает всеми признаками из X. В силу антимонотонности отображения «¢» поддержка множества признаков также удовлетворяет свойству антимонотонности: для всякого контекста K = (G, M, I) и любых X, Y Í M при X Í Y верно неравенство d(Y) £ d(X). (5) Согласно (5), поддержка множества признаков не может превышать поддержку любого из его подмножеств. Так, для произвольного X Í M всегда d(M) £ d(Х) £ d(Æ) = 1. Множество признаков X Í M называется частым в контексте K = (G, M, I), если его поддержка больше или равна заданному пороговому значению d0 Î [0, 1]. Если d(Х) ³ d0 и X = X¢¢, то X называется частым замкнутым множеством признаков в K = (G, M, I). Частые множества и частые замкнутые множества признаков традиционно служат основой для поиска ассоциативных правил в заданном контексте. Поддержкой d(Х ⇒ Y) ассоциативного правила Х ⇒ Y относительно контекста K = (G, M, I) называется величина d(Х ⇒ Y) = d(Х È Y) = |(Х È Y)¢| / |G|, (6) указывающая, какая доля объектов этого контекста имеет признаки Х È Y. Достоверность γ(Х ⇒ Y) ассоциативного правила Х ⇒ Y относительно контекста K = (G, M, I) определяется как отношение числа объектов, обладающих всеми признаками из Х È Y, к числу объектов, которым свойственны только признаки Х: γ(Х ⇒Y) = |(Х È Y)¢| / |X¢|. Достоверность ассоциативного правила через функцию поддержки выражается формулой γ(Х ⇒ Y) = d(Х ⇒ Y) / d(Х) = d(Х È Y) / d(Х). (7) Заметим, что достоверность определяется формулой (7) только для тех ассоциативных правил Х ⇒ Y, для которых d(Х) ¹ 0. Если d(Х) = 0 (в контексте нет ни одного объекта, который обладал бы признаками X), то также d(Х È Y) = 0. В этом особом случае полагают γ(Х ⇒ Y) = 1. Исходя из (4)-(7), достоверность ассоциативного правила Х ⇒ Y при произвольных X, Y Í M всегда находится в границах 0 £ g(Х ⇒ Y) £ 1. Чем ближе значение g(Х ⇒ Y) к 1, тем с большей уверенностью можно сказать, что признаки Y появляются в объ- ектах рассматриваемого контекста вместе с признаками X. Ассоциативное правило X Þ Y называется минимаксным, если не существует другого ассоциативного правила X* Þ Y*, такого, что X*Í X, Y Í Y* и d(X* Þ Y*) = d(X Þ Y), γ(X* Þ Y*) = = γ(X Þ Y). В анализе ассоциативных правил часто достоверность ассоциативного правила называют величиной его значимости. Самыми значимыми считаются строгие ассоциативные правила - правила с достоверностью 1. Известен критерий наличия в контексте строгого ассоциативного правила: достоверность ассоциативного правила Х ⇒ Y относительно контекста K = (G, M, I) равна 1 тогда и только тогда, когда Y Í X¢¢. Заметим, что данный критерий тривиальным образом выполняется для Х ⇒ X¢¢. Из определения замыкания и формулы (3) следует, что для всякого контекста K = (G, M, I) и любого множества X Í M поддержка Х¢¢ относительно K = (G, M, I) совпадает с поддержкой X: d(Х¢¢) = d(X). (8) Таким образом, если X Í M является частым множеством в K = (G, M, I), то Х¢¢ также является частым в этом контексте. Следует отметить, что в худшем случае число частых замкнутых множеств признаков контекста K = (G, M, I) совпадает с числом частых множеств признаков и экспоненциально зависит от |M|. Однако на практике обычно число частых замкнутых множеств значительно меньше числа частых множеств. Примеры контекстов с полиномиальным относительно |M| числом частых замкнутых множеств можно найти в [16]. Использование формулы (8) позволяет при поиске ассоциативных правил вместо частых множеств признаков применять частые замкнутые множества и тем самым сокращать пространство поиска ассоциативных правил. В силу (3) и (8) расширение исходного контекста путем добавления в него новых объектов не изменяет замыкания X¢¢ Í M, но может расширить состав объектов, которым присущи все признаки из X¢¢. Это означает, что при такой трансформации исходного контекста возможно лишь увеличение поддержек для ранее найденных замкнутых множеств признаков. Поэтому, если эти множества были частыми, они по-прежнему останутся частыми. Задача поиска ассоциативных правил и известные алгоритмы ее решения Пусть заданы контекст K = (G, M, I) и d0, γ0 – вещественные числа из [0, 1]. Будем говорить, что Х ⇒ Y является (d0, γ0)-ассоциативным правилом в K = (G, M, I), если выполняются два условия: γ0 £ γ(Х ⇒ Y) £ 1, (9) d0 £ d(Х ⇒ Y) £ 1. (10) Требуется найти для заданного контекста K = (G, M, I) множество AR всех (d0, γ0)-ассоциативных правил. Заметим, что искомый набор правил AR параметризирован относительно пороговых значений d0 и γ0. Например, при d0 = 0 условие (10) отражает естественные границы поддержки. Данная ситуация свидетельствует о том, что нет ограничений на частоту появления признаков Х È Y в K = (G, M, I). При γ0 = 1 условие (9) приводит к равенству γ(Х ⇒ Y) = 1. В этом случае будем иметь строгие ассоциативные правила. Решение поставленной задачи предполагает выполнение следующих двух этапов: вначале построение различных подмножеств множества M, вычисление для каждого из них поддержки и проверка условия (10); далее генерация ассоциативных правил с учетом найденных частых наборов и проверка условия (9). Наличие на обоих этапах комбинаторных переборов приводит к значительным вычислительным затратам для нахождения решения данной задачи. Очевидно, что, чем больше пороговые значения, тем быстрее находится соответствующий набор ассоциативных правил и тем меньшее число правил будет содержать этот набор. К со- жалению, в худшем случае время поиска всех (d0, γ0)-ассоциативных правил в заданном контексте K = (G, M, I) экспоненциально зависит от |M|. К настоящему времени разработано большое число алгоритмов поиска ассоциативных правил. Их обзор представлен в работах [15, 16]. Основополагающими среди них являются алгоритмы Apriori и Close. Алгоритм Apriori использует свойство антимонотонности функции поддержки [3, 9]. Он генерирует (d0, γ0)-ассоциативные правила для любых d0 и γ0 исходя из найденных частых множеств признаков. Алгоритм Close представляет класс алгоритмов, генерирующих только (d0, 1)-ассоциативные правила, то есть строгие ассоциативные правила. Этот алгоритм порождает строгие ассоциативные правила из частых замкнутых наборов признаков [15]. Переход от частых множеств к частым замкнутым множествам позволяет сузить пространство поиска. Другим достоинством алгоритма Close и его многочисленных версий является способность формировать минимаксные ассоциативные правила. Пример 1. Рассмотрим контекст K = (G, M, I), представленный в таблицах 1 и 2, где G = {g1, g2, g3, g4, g5} – множество объектов, M = {a, b, c, d, e} – множество признаков, I - матрица инцидентности. Заметим, что именно этот контекст традиционно используется в публикациях по алгоритмам поиска ассоциативных правил для демонстрации и тестирования этих алгоритмов [9]. В таблицах 1, 2 и далее при написании множеств для краткости опущены фигурные скобки, запятые между элемен- тами этих множеств и элементы расположены в лексикографическом порядке. Например, вместо {a, b, c} записано abc, а вместо {a, b} Þ {c} – ab Þ c.
Для рассматриваемого контекста при d0 = 1/5 и γ0 = 1 алгоритм Apriori приводит к семнадцати строгим ассоциативным правилам: AR = {a Þ c, d Þ a, e Þ b, b Þ e, d Þ c, ab Þ c, ae Þ b, ab Þ e, cd Þ a, ad Þ c, d Þ ac, ae Þ c, ce Þ b, bc Þ e, ace Þ b, abe Þ c, abc Þ e}. (11) Полученное множество AR содержит много избыточных правил в том смысле, что, если их исключить, то они выводимы из оставшихся правил. Это следующие ассоциативные правила: {d Þ c, ab Þ c, ae Þ b, ab Þ e, cd Þ a, ad Þ c, d Þ ac, ae Þ c, ce Þ b, bc Þ e, ace Þ b, abe Þ c, abc Þ e}. Некоторые из них удаляются алгоритмом Close в процессе построения множества AR. В результате алгоритм Close извлекает лишь восемь минимаксных строгих ассоциативных правил: AR = {a Þ c, b Þ e, e Þ b, d Þ ac, bc Þ e, ce Þ b, ab Þ ce, ae Þ bc}, (12) что в два раза меньше чем в (11). Алгоритм Close находит минимаксные строгие ассоциативные правила по следующим частым замкнутым наборам признаков: c, ac, be, bce, acd, abce. Все эти правила имеют допустимые поддержки: d(a Þ c) = 3/5, d(b Þ e) = 4/5, d(e Þ b) = 4/5, d(d Þ ac) = 1/5, d(bc Þ e) = 3/5, d(ce Þ b) = 3/5, d(ab Þ ce) = 2/5, d(ae Þ bc) = 2/5. Классический алгоритм Close Суть классического алгоритма Close заключается в пошаговом извлечении генераторов и частых замкнутых наборов признаков [11, 15]. Множество ρ Í M называется генератором замкнутого набора признаков X Í M, X = X¢¢, тогда и только тогда, когда ρ¢¢ = X и не существует другого множества t Í M, такого, что t Ì ρ и t'' = X. Другими словами, генератор замкнутого набора признаков X - наименьшее по мощности множество признаков, имеющее замыкание X. Число признаков, входящих в генератор ρ, называется мощностью этого генератора. Если |r| = k, то r является k-генератором. На вход алгоритма Close подаются исходный контекст K = (G, M, I) и пороговое значение d0. Изначально множество AR считается пустым и k = 1. На первом шаге в качестве k-генераторов рассматриваются все одноэлементные подмножества множества M. Замыкание ρk¢¢ для генератора ρk вычисляется по формуле (3). Поддержка для ρk¢¢ находится по формуле (4). Если d(ρk¢¢) ³ d0, то по частому замкнутому множеству ρk¢¢ строится минимаксное строгое ассоциативное правило ρk Þ ρk¢¢ \ ρk (13) и сохраняется в AR. Согласно (6) и (8), для него d(ρk Þ ρk¢¢ \ ρk) = d(ρk¢¢) ³ d0, γ(ρk Þ ρk¢¢ \ ρk) = 1. То, что ассоциативное правило (13) является минимаксным, следует из определения генератора. Очевидно, что различные генераторы могут порождать одинаковые замыкания. Так, для контекста из примера 1 имеем: b¢¢ = be, e¢¢ = be. Поэтому (12) содержит минимаксные строгие ассоциативные правила b Þ e и e Þ b. После генерации ассоциативного правила по ρk¢¢ создаются кандидаты в (k + 1)-генераторы для следующей итерации. Каждый такой кандидат формируется путем объединения двух k-генераторов, обладающих одинаковыми первыми k – 1 признаками. Далее проверяется, вложен ли найденный кандидат в ρk¢¢. Если вложен, то он исключается из рассмотрения. После нахождения всех (k + 1)-генераторов осуществляется переход к следующей итерации. Алгоритм Close завершает работу, когда исчерпаны все генераторы. Множество ассоциативных правил, полученных в результате работы алгоритма Close, образует минимаксный базис строгих ассоциативных правил контекста K = (G, M, I). Корректность алгоритма Close доказана в работе [15]. Алгоритм Close может быть модифицирован так, чтобы в результирующее множество AR не попадали заведомо избыточные строгие ассоциативные правила. Алгоритм MClose для построения сжатого строгого базиса Верна следующая теорема. Для любого контекста K = (G, M, I) и произвольных X, Y, Z, W Í M справедливы следующие свойства строгих ассоциативных правил: D1. Рефлексивность: Х Þ X. D2. Пополнение посылки: если Х Þ Y, то Х È Z Þ Y. D3. Аддитивность: если Х Þ Y и Х Þ Z , то Х Þ Y È Z. D4. Проективность: если Х Þ Y и Z Í Y, то Х Þ Z. D5. Транзитивность: если Х Þ Y и Y Þ W, то Х Þ W. D6. Псевдотранзитивность: если Х Þ Y и Y È Z Þ W, то Х È Z Þ W. Свойства (или выводимости) D1–D6 позволяют из некоторого множества строгих ассоциативных правил вывести многие другие правила без дополнительного сканирования контекста. С одной стороны, именно выводимости D1–D6 обусловливают экспоненциальное число возможных строгих ассоциативных правил для рассматриваемого контекста и неоднозначность их представления. С другой стороны, они предоставляют возможность построить для множества строгих ассоциативных правил сжатый строгий базис (concise strong basis), компактно описывающий связи между данными изучаемой предметной области. Примечательно, что выводимости, подобные D1–D6, справедливы для функциональных зависимостей, имеющих место в теории реляционных БД, где их принято называть аксиомами Амстронга. Такое совпадение не случайно, поскольку строгие ассоциативные правила можно рассматривать как особый случай функциональных зависимостей [5]. В работе [12] выводимости D1–D6 доказаны применительно к функциональным зависимостям. Однако они могут быть доказаны непосредственно для ассоциативных правил на основе соответствий Галуа. Важно, что выводимости D1, D3, D4, D5 гарантируют сохранение поддержки. Это означает, что результатом применения их (d0, 1)-ассоциативным правилом всегда является (d0, 1)-ассоциативное правило. Поэтому эти выводимости применяются в алгоритме MClose для построения сжатого строгого базиса. Введем определения избыточного ассоциативного правила и сжатого строгого базиса для множества (d0, 1)-ассоциативных правил. Пусть AR - множество строгих ассоциативных правил, каждое из которых справедливо для контекста K = (G, M, I). Будем говорить, что строгое ассоциативное правило Х Þ Y логически следует из множества AR, если оно может быть выведено из AR с помощью выводимостей D1, D3, D4, D5. Тот факт, что строгое ассоциативное правило Х Þ Y логически следует из AR, будем обозначать так: AR ╞ Х Þ Y. Строгое ассоциативное правило Х Þ Y называется избыточным в AR, если AR \ {Х Þ Y} ╞ Х Þ Y. Множество строгих ассоциативных правил неизбыточное, если оно не содержит избыточных стро- гих ассоциативных правил. Множество CSB назы- вается сжатым строгим базисом множества AR, если оно неизбыточное и состоит только из мини- максных строгих ассоциативных правил. Данное определение сжатого строгого базиса указывает способ его нахождения - генерация минимаксных строгих ассоциативных правил (например, с помощью алгоритма Close) и устранение среди них избыточных. Распознавание избыточного строгого ассоциативного правила в AR основано на проверке логического следования AR \ {Х Þ Y} ╞ Х Þ Y. (14) Алгоритм такой проверки использует понятие замыкания множества признаков относительно множества AR и является полиномиальным относительно |M| и |AR|. Замыканием множества Х Í M относительно AR (обозначается X+) называется множество всех признаков m Î M, таких, что верно логическое следование AR ╞ Х Þ m. Заметим, что неизменно X+ Í M. Из выводимостей D1, D3, D4 вытекает справедливость следующего утверждения. Утверждение 3. Логическое следование AR ╞ Х Þ Y имеет место тогда и только тогда, когда Y Í X+. Отсюда всегда AR ╞ Х Þ X+, AR ╞ Х Þ X+ \ Х. В силу утверждения 3, чтобы убедиться в справедливости (14), достаточно вычислить X+ относительно AR \ {Х Þ Y} и проверить включение Y Í X+. Если Y Í X+, то строгое ассоциативное правило Х Þ Y избыточно в AR, иначе – не избыточно. Алгоритм вычисления X+ целиком базируется на выводимостях D1, D3, D4, D5 и сводится к выполнению следующих действий. Сначала полагается X+ = Х. Далее осуществляются просмотр правил из AR и пополнение замыкания по следующему принципу: если для правила Y Þ Z Î AR верно включение Y Í X+, то множество Z добавляется к X+. Этот процесс повторяется до тех пор, пока изменяется X+. Поскольку множества M и AR конечные, то процесс вычисления X+ конечен. Заметим, что процесс исключения избыточных строгих ассоциативных правил не требует доступа к контексту K = (G, M, I) и поэтому время его выполнения незначительно по сравнению со временем получения частых замкнутых множеств признаков. Чтобы исключить добавление заведомо избыточного строгого ассоциативного правила в AR, необходимо всякий раз после построения ρk¢¢ выполнять следующие действия. Если посылка ρk найденного правила не равна ρk¢¢, то необходимо найти замыкание ρk+ относительно вычисленного множества AR. Если ρk+ = ρk¢¢, то минимаксное ассоциативное правило ρk ⇒ ρk¢¢ / ρk является избыточным (по утверждению 3), иначе оно включается в AR. После завершения генерации минимаксных строгих ассоциативных правил обязательно требу- ется дополнительный просмотр результирующего множества AR с целью обнаружения оставшихся избыточных правил. Такие правила вполне возможны: они неизбыточные по отношению к ранее выявленным правилам, однако после пополнения AR новыми правилами могут оказаться избыточными. Таким образом, по построению результи- рующее множество AR состоит из минимаксных строгих ассоциативных правил и является неизбыточным. Заметим, что оперативное удаление из- быточных правил сдерживает рост мощности AR и снижает время выполнения алгоритма. Опишем алгоритм MClose. Алгоритм 1. MClose 1: begin 2: AR ¬ Æ 3: k ¬ 1 4: while rk ¹ Æ 5: Gen-Closure (rk) 6: if d(rk) ³ d0 7: if rk ¹ rk¢¢ 8: rk+ ¬ SX (rk) 9: end if 10: if rk+ ¹ rk¢¢ 11: AR ¬ (ρk Þ ρk¢¢ \ ρk) 12: end if 13: end if 14: Gen-Generator (k + 1) 15: k ¬ k + 1 16: end while 17: Non-Redundancy (AR) 18: end В описании алгоритма MClose процедуры Gen-Closure и Gen-Generator аналогичны одноименным процедурам классического алгоритма Close (см. [11, 15]). Процедура SX осуществляет построение замыкания ρk+. Процедура Non-Redundancy, выполняемая на шаге 17 алгоритма MClose, устраняет в AR избыточные строгие ассоциативные правила после завершения его генерации. Пример 2. Для контекста, представленного в таблицах 1 и 2, при d0 = 1/5 и γ0 = 1 минимаксный базис состоит из восьми правил (12), в котором избыточными являются bc Þ e, ce Þ b, ab Þ ce, ae Þ bc. (15) Сжатый строгий базис, построенный алгоритмом MClose, содержит только четыре минимаксных строгих ассоциативных правила: CSB = {a Þ c, b Þ e, e Þ b, d Þ ac}. Заметим, что на основе CSB можно получить всякое правило из (15) с помощью алгоритма вычисления X+. Так, чтобы найти максимальное следствие для посылки bc, достаточно вычислить bc+ относительно CSB. В результате имеем bc+ = bce. Отсюда CSB ╞ bc Þ e. Поскольку bc+ = bc¢¢= bce и e Î bc¢¢, то ассоциативное правило bc Þ e является строгим. Программная реализация алгоритма MClose и результаты экспериментов Алгоритм MClose программно реализован на языке программирования С++ в среде разработки Embarcadero RAD Studio XE8. Исходными данными для него служат контекст K = (G, M, I) и пороговое значение поддержки. Для ввода исходных данных имеется интерфейс (см. http://www.swsys. ru/uploaded/image/2017_2/2017-2-dop/7.jpg). Для удобства пользователя пороговое значение вводится в виде целого положительного числа d0 × |G|. Результатом работы алгоритма MClose являются все выявленные частые замкнутые множества признаков и сжатый строгий базис (см. http://www. swsys.ru/uploaded/image/2017_2/2017-2-dop/8.jpg). Значения поддержек масштабируются и выводятся в виде целых положительных чисел. В программе существует возможность изменения результирующего множества ассоциативных правил путем добавления и удаления отдельных правил. Это сделано для того, чтобы эксперт мог исключить из рассмотрения ассоциативные правила, которые, на его взгляд, не отвечают реальной действительности, и добавить существенные правила. Допускается сокращение признакового пространства (вкладка «Анализ признаков») с помощью методов, описанных в работе [17]. Предусмотрена функция вычисления следствия для всякой заданной посылки относительно сжатого строгого базиса. Для оценки эффективности алгоритма MClose были также программно реализованы алгоритмы Apriori и Close. Алгоритмы Apriori, Close и MClose сравнивались по числу сгенерированных строгих ассоциативных правил и времени работы. Эксперименты осуществлялись на компьютере с процессором Intel® Core™ i5 CPU & 2.30 GHz и ОЗУ размером 4 ГБ. Эксперименты выполнялись на контекстах различной размерности и плотности, сгенерированных случайным образом. Результаты экспериментов представлены в таблице 3. Таблица 3 Результаты экспериментов Table 3 Results of experiments
Примечание: в колонках под цифрой 1 – число извлеченных строгих ассоциативных правил, под цифрой 2 – время, мс. В таблице 3 для всякого анализируемого контекста K = (G, M, I) указаны |G| - число объектов, |M| - число признаков, s = n /(|G| × |M|) - плотность контекста, где n задает число единичных элементов матрицы инцидентности I. Контекст из 10 000 объектов был сформирован многократным копированием контекста, состоящего из 500 объектов. Из таблицы 3 видно, что алгоритмы Close и MClose эффективнее алгоритма Apriori как по числу извлеченных строгих ассоциативных правил, так и по времени работы. Алгоритм MClose по времени работы сопоставим с алгоритмом Close. Однако алгоритм MClose позволяет более чем в два раза уменьшить мощность минимаксного базиса, формируемого алгоритмом Close. Заключение Современные методы и средства поиска ассоциативных правил в больших массивах данных приводят к значительному числу правил, большинство из которых являются избыточными. Усилия многих исследователей направлены на разработку методов устранения избыточности в представлении ассоциативных правил. Для решения этой проблемы применительно к строгим ассоциативным правилам предложен алгоритм MClose, являющийся модификацией известного алгоритма Close и основанный на свойствах частых замкнутых множеств. Предложенный алгоритм формирует для заданного контекста сжатый строгий базис – не- избыточное множество минимаксных строгих ассоциативных правил с сохранением поддержки. Вычислительные эксперименты показали, что алгоритм MClose существенно сокращает число извлеченных строгих ассоциативных правил без потери информации о связях между данными анализируемой предметной области. Перспективны исследования, направленные на устранение избыточности для ассоциативных правил с любыми поддержками и достоверностями. Литература 1. Батура Т.В. Модели и методы анализа компьютерных социальных сетей // Программные продукты и системы. 2013. № 3. С. 130-137. 2. Платонов В.В., Семенов П.О. Методы сокращения размерности в системах обнаружения сетевых атак // Проблемы информационной безопасности. Компьютерные системы. 2012. № 3. С. 40-45. 3. Ilayaraja M., Meyyappan T. Mining medical data to identify frequent diseases using Apriori algorithm. Pattern Recognition, Informatics and Mobile Engineering (PRIME), IEEE, 2013, pp. 194-199. 4. Городецкий В.И., Самойлов В.В. Ассоциативный и причинный анализ и ассоциативные байесовские сети // Тр. СПИИРАН. 2009. Вып. 9. С. 13–65. 5. Кузнецов С.О. Автоматическое обучение на основе анализа формальных понятий // Автоматика и телемеханика. 2001. № 10. С. 3-27. 6. Биркгоф Г., Барти Т. Современная прикладная алгебра. СПб: Лань, 2005. 400 с. 7. Гуров С.И. Булевы алгебры, упорядоченные множества, решетки: определения, свойства, примеры. М.: ЛИБРОКОМ, 2013. 352 с. 8. Ganter B., Wille R. Formal Concept Analyses: mathematical foundations, Springer Science and Business Media, 2012, 314 p. 9. Zhang C., Zhang S. Association rules mining. Springer, 2002, 240 p. 10. Geng L., Hamilton H.J. Interestingness measures for data mining: a survey. ACM Computing Surveys, 2006, vol. 38, no. 3, article 9. 11. Pasquier N., Bastide Y., Taouil R. & Lakhal L. Generating a condensed representation for association rules. Jour. of Intelligent Information Systems, 2005, vol. 24, no. 1, pp. 29-60. 12. Мейер Д. Теория реляционных баз данных. М.: Мир, 1987. 608 с. 13. Duquenne V., Obiedkov S.A. Attribute-incremental construction of the canonical implication basis. Annals of Mathematics and Artificial Intelligence, 2007, vol. 49, no. 1-4, pp. 77–99. 14. Rudolph S. Some notes on pseudo-closed sets. Proc. ICFCA 2007, LNCS, Springer, 2007, vol. 4390, pp. 151–165. 15. Zaki M.J., Hsiao Ch.-J. Efficient Algorithms for Mining Closed Itemsets and Their Lattice Structure. IEEE Transaction on Knowledge and Data Engineering, 2005, vol. 17, no. 4, pp. 462-478. 16. Uno T., Asai T., Uchida Y., Arimura H. An Efficient Algorithm for Enumerating Closed Patterns in Transaction Databases. Proc. DS’04, LNAI 3245, 2004, pp. 16-31. 17. Быкова В.В., Катаева А.В. Методы и средства анализа информативности признаков при обработке медицинских данных // Программные продукты и системы. 2016. № 2. С. 172-178. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Permanent link: http://swsys.ru/index.php?id=4273&lang=en&page=article |
PDF version article Full issue in PDF (17.16Mb) Download the cover in PDF (0.28Мб) |
| The article was published in issue no. № 2, 2017 [ pp. 187-195 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Интеллектный программно-вычислительный комплекс «АНАПРО» для задачи мониторинга в распределительных электрических сетях
- Разработка базы данных и конвертера для извлечения и анализа специализированных данных, получаемых с медицинского аппарата
- Разработка прецедентного модуля для идентификации сигналов при акустико-эмиссионном мониторинге сложных технических объектов
- Анализ и обработка данных для прогнозирования состояния больных
- Построение ассоциативных правил в задаче медицинской диагностики
Back to the list of articles