Journal influence
Bookmark
Next issue
Abstract:
Аннотация:
| Authors: Dli M.I. (midli@mail.ru) - (Smolensk Branch of the Moscow Power Engineering Institute, Smolensk, Russia, Ph.D | |
| Page views: 22815 |
Print version Full issue in PDF (1.25Mb) |
Задача экстраполяции или прогнозирования случайного процесса часто встречается при исследовании различных систем и объектов. Теоретически данная задача исследована достаточно полно как в непрерывном, так и в дискретном вариантах, при этом соответствующие алгоритмы экстраполяции отображаются либо в форме фильтров Винера и Калмана-Бьюси [I], либо в форме разностных уравнений авторегрессии – скользящего среднего [2]. Однако известные результаты относятся в основном к ситуации, когда рассматриваемый случайный процесс считается удовлетворяющим линейному стохастическому дифференциальному или разностному уравнению. Учет нелинейности, как правило, присутствующей в реальных процессах, привел к дальнейшему развитию алгоритмов экстраполяции: в виде нелинейного фильтра Калмана-Бьюси, в виде линейной комбинации моделей авторегрессии – скользящего среднего [3] и в рамках нейросетевого подхода [3, 4]. Отметим, что каждый из отмеченных алгоритмов обладает определенными недостатками, ограничивающими их практическое применение: так, при использовании алгоритма Калмана – это значительный объем требуемой априорной информации о процессе, а при использовании нейросетевого подхода – сложность реализации в реальном масштабе времени на базе существующих нейросетевых программных пакетов [4] и т.п. В настоящей статье рассмотрен другой, как представляется, свободный от большинства указанных недостатков алгоритм экстраполяции случайного процесса, основанный на методе локальной аппроксимации [5], допускающий легкую программную реализацию. Предположим, что рассматриваемый случайный процесс удовлетворяет нелинейному стохастическому разностному уравнению xt+1=f(xt, xt-1, xt-2,…et), (1) где xt – значения процесса в дискретные моменты времени t; et – значения порождающего процесса типа дискретного белого шума; f(×) – функция, вообще говоря, неизвестного вида. Предположим далее, что математическое ожидание и дисперсия процесса хt существуют, конечны и постоянны: mx = const, Ã2x= const, а также, что f(×) является однозначной функцией всех своих аргументов. Данные предположения, по сути, определяют весь объем необходимой априорной информации. Требуется на основании данных предварительного идентифицирующего (обучающего) эксперимента, текущем хt и нескольких предыдущих xt-1, xt-2,... значениях процесса найти экстраполируемое значение Идея предлагаемого алгоритма экстраполяции может быть представлена следующим образом. Пусть множество упорядоченных наборов значений процесса вида {хk+1, хk,xk-1,...,хk-n}, близких к набору текущих измеренных значений {xt, хt-1,...,хt-n}, например, в смысле расстояния dk= (где w1– wn – некоторые неотрицательные весовые коэффициенты) достаточно точно аппроксимируется линейной моделью авторегрессии порядка n, то есть xk+1 = c0 xk+c1 xk-1+...+cn xk-n+ek, (3) где c0¸cn – коэффициенты модели; ek – порождающий дискретный белый шум с постоянными математическим ожиданием и дисперсией. В предположении, что такой же модели соответствуют текущие значения процесса, экстраполируемое значение можно определять по формуле
Коэффициенты c0¸cn данной (локальной) модели находятся с использованием "М ближайших соседей", то есть с использованием данных М ближайших в смысле расстояния (2) приведенных наборов значений (число М полагается заданным М>n+1), на базе стандартной процедуры метода наименьших квадратов [2]. Введем обозначения: СT = (c0, c1,...,cn) – вектор коэффициентов модели (3),
YT=
где Х – матрица размера М ´ (n + 1), строками которой являются XiT. В соответствии с изложенным целесообразно выделить этапы обучения и использования алгоритма. На этапе обучения при заданных n, w1 ¸ wn, М с использованием обучающей выборки формируется база данных алгоритма, которую можно отобразить матрицей U со строками вида áхk+1, xk, ..., xk-nñ. На этапе использования (в том числе в режиме реального времени) по текущему хt и предыдущим значениям xt-1, xt-2, ..., xt-n значениям процесса с применением расстояния (2) в базе данных находятся М отмеченных "ближайших соседей", и далее по выражениям (5), (4) осуществляется прогноз (экстраполяция). Остановимся подробнее на этапе обучения. Он может быть описан следующим образом. 1. Проведение "затравочного" эксперимента с регистрацией значений хk и формирование начальной матрицы U с числом строк, большим М. 2. Ввод очередного значения xk+1. Расчет по соотношениям (2), (5), (4) прогнозируемого значения 3. Проверка выполнения неравенства
где r – заданная константа, определяющая точность прогноза. 4. В случае выполнения неравенства матрица U дополняется строкой áхk+1, хk, хk-1, ..., xk-nñ. При невыполнении (6) матрица U не изменяется. 5. Переход к пункту 2. Общее количество значений процесса хt, используемых для формирования U, может быть как фиксированным, так и переменным. Например, условием останова процедуры обучения может быть невыполнение неравенства (6) N0 раз подряд, где N0 =50¸100. На этапе использования в соответствии с изложенным выполняется только 2-й пункт описанной процедуры. Остановимся на рекомендациях по выбору параметров n, w1¸wn, М, r. Так же, как и при использовании классического аппарата моделей авторегрессии (скользящего среднего), здесь невозможно теоретически сразу указать оптимальный порядок n авторегрессионной модели (3), поэтому последующие рекомендации носят эмпирический характер. Так, исходя из принципа экономии [2], можно рекомендовать построение модели, начиная с n=1; величину М целесообразно выбирать равной (n+3)¸(n+5); весовые коэффициенты w1¸wn – равными единице или убывающими в геометрической прогрессии; значение r должно соответствовать приемлемой погрешности прогноза. Если при указанном выборе число строк матрицы U (базы данных модели) оказывается очень большим, сопоставимым с объемом обучающей выборки, следует увеличить n, а возможно, и r. В ряде имитационных экспериментов по изучению описанного алгоритма погрешность уменьшилась на 30¸40 % при удачном подборе весовых коэффициентов w1¸wn. Заметим, что обычно нескольких таких уточняющих итераций (по подбору n, w1¸wn, М, r) оказывается достаточным для формирования по итогам обучающего этапа матрицы U умеренного размера, при котором прогностические свойства алгоритма соответствуют допустимым.
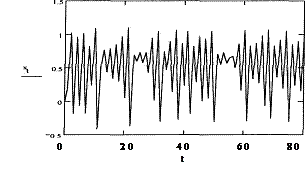
Особенности применения предложенного подхода рассмотрим на следующем примере. Исследуемый дискретный случайный процесс (известный как процесс Хенона [4]) соответствовал нелинейному разностному уравнению хt+1=1+0.3хt–1.4х2t+et, (7) где в данном случае et – дискретный белый шум, имеющий равномерное распределение в интервале (-0.1,0.1). При случайном начальном условии, равномерно распределенном в интервале (0,1), формируемые в соответствии с (7) значения хt образовали процесс достаточно хаотического, случайного вида, показанного на рисунке 1 (заметим, что соответствующее имитационное моделирование и программная реализация алгоритма экстраполяции выполнены с помощью системы MathCAD 7.0 Pro [6]). Предварительное изучение процесса позволило определить его математическое ожидание (mx=0.49), дисперсию ( Этап обучения описанного алгоритма при объеме обучающей выборки N=400 и параметрах n=1, w1=0.8, М=5, r=0.2 позволил сформировать матрицу U (базу данных модели), содержащую 28 строк вида áхk+1,xk,хk-1ñ. Диагностическая проверка прогнозирующих свойств алгоритма (по другой выборке того же объема) дала оценку дисперсии прогноза Для сравнения: прогноз а) с помощью тривиального статистического прогноза по одной точке, то есть по соотношению [7]:
Имитационное моделирование привело к оценке дисперсии прогноза
б) с помощью адаптивного алгоритма экспоненциального сглаживания 1-го порядка [9], при котором экстраполируемые значения рассчитывались по соотношениям
(оптимальное значение g подобрано экспериментально). В данном случае оценка дисперсии прогноза оказалась равной 0.29; в) с помощью "наилучшей" модели авторегрессии. Методом подбора было установлено, что "наилучшей" (глобальной) моделью авторегрессии для рассматриваемого процесса является модель вида
при этом Как видно из приведенных результатов, прогноз по предложенному алгоритму осуществляется существенно более точно по сравнению с рассмотренными другими.
Список литературы 1. Сейдж Э., Меле Дж. Теория оценивания и ее применение в связи и управлении. -М.: Связь, 1976. 2. Бокс Дж., Дженкинс Г. Анализ временных рядов: прогноз и управление. - М.: Мир. - 1974. - Вып.1. 3. Бэстенс Д.-Э., Ван ден Берг В.-М., Вуд Д. Нейронные сети и финансовые рынки: принятие решений в торговых операциях. - М.: ТВП, 1997. 4. Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере. - Новосибирск: Наука, 1996. 5. Youji liguni, Isao Kawamoto, Norihiko Adachi. A nonlinear adaptive estimation method based on local appoximation // IEEE Trans. On Signal Proctssing. -1997. - Vol. 45. -№7. -Р.1831-1841. 6. Дьяконов В.П. Справочник по MathCAD PLUS 7.0 PRO. – М.: "CK Пресс", 1998. 7. Ефимов А.Н. Предсказание случайных процессов. - М.: Знание, 1976. 8. Ицкович Э.Л. Контроль производства с помощью вычислительных машин. -М.: Энергия, 1975. 9. Чуев Ю.В., Михайлов Ю.Б., Кузьмин В.И. Прогнозирование количественных характеристик процессов. - М.: Советское радио, 1975. |
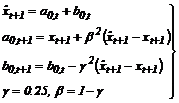 (9)
(9) Представляется, что приведенный подход к экстраполяции случайного процесса, основанный на методе локальной аппроксимации, является вполне конкурентоспособным по отношению к другим известным подходам. Его основные достоинства: возможность получения высокого качества прогноза, минимальные априорные предположения о характере рассматриваемого процесса, простота программной реализации, допускающая работу в реальном масштабе времени, позволяют рекомендовать его к использованию в задачах экстраполяции, когда заметно проявление нелинейных свойств случайного процесса. Заметим, что если "истинная" модель такого процесса линейна, то метод локальной аппроксимации по точностным свойствам аналогичен подходу с использованием моделей авторегрессии.
Представляется, что приведенный подход к экстраполяции случайного процесса, основанный на методе локальной аппроксимации, является вполне конкурентоспособным по отношению к другим известным подходам. Его основные достоинства: возможность получения высокого качества прогноза, минимальные априорные предположения о характере рассматриваемого процесса, простота программной реализации, допускающая работу в реальном масштабе времени, позволяют рекомендовать его к использованию в задачах экстраполяции, когда заметно проявление нелинейных свойств случайного процесса. Заметим, что если "истинная" модель такого процесса линейна, то метод локальной аппроксимации по точностным свойствам аналогичен подходу с использованием моделей авторегрессии.| Permanent link: http://swsys.ru/index.php?id=920&lang=en&page=article |
Print version Full issue in PDF (1.25Mb) |
| The article was published in issue no. № 1, 1999 |
Back to the list of articles