Journal influence
Bookmark
Next issue
The language for description of problem domain model in the software packages
The article was published in issue no. № 1, 2011Abstract:The questions of the parallel computing are discussed. In particular, the software packages with automated synthesis of parallel programs, the tools for description of problem domain and the tools for definitions of nonprocedural problem are considered.
Аннотация:Обсуждаются вопросы, связанные с организацией параллельных вычислений. В частности, рассматриваются средства описания предметной области и непроцедурных постановок задач в пакетах прикладных программ с авто-матическим синтезом параллельных программ.
| Authors: Oparin G.A. (oparin@icc.ru) - Institute of System Dynamics and Control Theory SB of the Russian Academy of Sciences, Irkutsk, Russia, Feoktistov A.G. (agf@icc.ru) - Matrosov Institute for System Dynamics and Control Theory of Siberian Branch of Russian Academy of Sciences, Irkutsk, Russia, (oparin@icc.ru) - , Ph.D | |
| Keywords: input language, software package, parallel computing |
|
| Page views: 18765 |
Print version Full issue in PDF (5.09Mb) Download the cover in PDF (1.32Мб) |
Активное внедрение параллельной вычислительной техники (в особенности кластерных архитектур) в практику проведения расчетных работ обоснованно требует повышения степени автоматизации этого процесса и тем самым вновь актуализирует применение пакетного подхода к организации прикладных исследований. Неотъемлемой частью пакетного подхода являются методы и средства описания предметной области решаемой задачи, определяющие уровень общения специалиста-предметника с параллельной вычислительной системой. Анализ известных систем параллельного программирования показывает, что крайне мало внимания уделяется построению прикладных программных систем на основе повторного использования программных блоков, особенно их большого количества. Эффективность создаваемых приложений во многом зависит от степени владения низкоуровневым системным ПО (MPI, OpenMP, Globus Toolkit и т.д.), что является уделом узкого круга программистов высокой квалификации. Данная статья – это логическое продолжение исследований, связанных с разработкой инструментального комплекса (ИК) ORLANDO Tools [1]. Высокоуровневые языковые средства описания модели предметной области в пакетах прикладных программ описываются с помощью указанного выше инструментария. Детально рассматриваются основные конструкции входного языка пакета, позволяющие в декларативной форме определять параллельные структуры данных и неявно описывать параллелизм программных блоков по управлению. В описании модели предметной области пакета прикладных программ выделяются три концептуально обособленных слоя знаний – вычислительный, схемный и продукционный, над кото- рыми формируются постановки задач, а также следующие типы объектов (понятий или концептов): модуль, параметр, операция, продукция и постановка задачи. Описание модели, которое включает спецификации объектов предметной области, а также постановок задач и запросов на их решение, осуществляется на специализированном декларативном языке ORLANDO. Все информационно-логические связи выявляются и учитываются в дальнейшем на этапах формирования и анализа модели предметной области при автоматическом синтезе параллельной программы. Рассмотрим основные конструкции языка ORLANDO (части конструкций, заключенные в квадратные скобки, могут быть опущены). Описание модуля. Модуль – это спецификация подпрограммы-функции на языке C++ или FORTRAN. Данная спецификация включает информацию о языке программирования и программных файлах, входных (выходных) переменных и их формате, а также содержит инструкции компилятору. Целевые параллельные программы (исполняемые файлы) синтезируются на основе этой информации посредством процедур трансляции и компиляции. Для описания модуля служит конструкция MODULE <язык программирования> <имя модуля> FUNCTION <функция> INCLUDE <заголовочный файл> FILES <дополнительные файлы> LIBS <файлы библиотек> COMPILER <опции компилятора>; Здесь <имя модуля> – содержательный идентификатор модуля; <функция> – описание сигнатуры функции; <язык программирования> – язык, на котором написана функция. Кроме того, в состав конструкции входят директивы: INCLUDE – для указания заголовочного файла, в котором объявлена данная функция; FILES – для перечисления дополнительных файлов, необходимых при компиляции или исполнении программы; LIBS – для задания библиотек, требуемых при компиляции программы; COMPILER – для назначения дополнительных опций компилятора. Модули составляют функциональное наполнение пакета прикладных программ – слой вычислительных знаний. На его основе формируются слои схемных и продукционных знаний о предметной области пакета. Описание параметра. Параметр может быть представлен скаляром, вектором или матрицей значений одного из допустимых типов данных, которыми являются byte, bool, int, long, float, double. Для описания параметра служит конструкция [PARAMETER] <тип> <имя параметра 1> [BOUNDS (<имя параметра 2>, [<имя параметра 3>])]; Здесь <тип> – один из допустимых типов параметра; <имя параметра> – содержательный идентификатор параметра, отражающий его назначение в конкретной предметной области; BOUNDS – ключевое слово, предназначенное для задания верхних границ изменения индексов элементов векторов и матриц. Описание операции. Операция – это объект предметной области, определяющий отношение вычислимости между двумя подмножествами параметров предметной области: возможность вычисления искомых значений параметров первого подмножества, когда известны значения параметров второго подмножества, с помощью указанной прикладной программы (модуля). Для описания операции служит конструкция OPERATION <имя операции> BY <имя модуля> (<список параметров>); Здесь <имя операции> – содержательный идентификатор операции; <имя модуля> – идентификатор модуля, реализующего данную опе- рацию; <список параметров> = ([IN|OUT] <имя параметра>[,…]) – список имен параметров, обрабатываемых данной операцией. Принадлежность параметра к подмножеству заданных (искомых) параметров уточняется с помощью ключевого слова IN (OUT). На основе описаний параметров, операций и модулей планировщик ИК ORLANDO Tools формирует информационно-логические связи между ними (слой схемных знаний) и тем самым определяет возможные сочетания и правила параллельного применения модулей в процессе решения задачи. Предполагается, что в общем случае описание предметной области избыточно – одни и те же параметры могут быть вычислены путем применения разных операций. Приведем пример описания схемных знаний на языке ORLANDO.
Двудольный ориентированный граф, изображенный на рисунке, также отражает неявный параллелизм операций предметной области (операции f1 и f2 могут быть выполнены одновременно), заложенный в ее описании. Описание параметра-списка. С целью обеспечения возможности реализации в модели предметной области пакета параллелизма по данным в языке ORLANDO введен структурный тип данных параметр-список, создаваемый на основе параметра любого допустимого типа (скалярного, векторного или матричного) и включающий множество вариантов значений этого параметра. Такая параллельная структура данных реализует способ организации данных, позволяющий выполнять независимую параллельную обработку элементов этой структуры в рамках конкретной вычислительной системы. Число элементов параметра-списка задается параметром-скаляром целого типа. Основное отличие параметра-списка от параметра-массива заключается в способе обработки их элементов. Параметр-массив целиком передается в модуль, реализующий операцию, выполняемую над этим параметром, в то время как параметр-список может обрабатываться поэлементно, в общем случае одновременно, множеством экземпляров модуля в разных узлах параллельной вычислительной системы. Под поэлементной обработкой параметров-списков подразумевается следующее: пусть x¢ и y¢ – параметры-списки, созданные на основе параметров x и y; IPNi и OUTPi – соответственно множества входных и выходных параметров модуля mi, предназначенного для поэлементной обработки этих параметров-списков, xÎINPi, yÎOUTPi. Интерпретация модуля mi выполняется следующим образом: 1) происходит параллельный запуск r экземпляров (r – размерность списков x¢, y¢) модуля mi, j-му экземпляру модуля mij передается j-й элемент списка x¢; 2) результат присваивается j-му элементу списка y¢. В процессе вычислений параметры-списки могут обрабатываться и как неделимые структуры данных. В этом случае обработка параметра-списка осуществляется аналогично обработке параметра-массива. Для описания параметра-списка служит конструкция PARALLEL <имя параметра-списка> OF <имя параметра> SIZE (<размерность>); Здесь <имя параметра-списка> – содержательный идентификатор параметра-списка; <имя параметра> – идентификатор исходного параметра, на основе которого создается параметр-список; <размерность> – идентификатор параметра, значение которого будет определять количество элементов параметра-списка. Описание постановки задачи. Постановка задачи – это запрос к предметной области: зная модель предметной области M, по заданным значениям параметров x1, x2, …, xn вычислить значения параметров y1, y2, …, ym. Для описания постановки задачи используется конструкция TASK <имя задачи> (<список параметров>); Здесь <имя задачи> – содержательный идентификатор постановки задачи; <список параметров> – список имен параметров. Принадлежность параметра к подмножеству заданных (искомых) параметров указывается с помощью ключевого слова IN (OUT). Модель M (описание модулей, параметров и операций предметной области) в постановке задачи явно не указывается. Пусть на модели предметной области, приведенной на рисунке, сформулирована следующая постановка задачи: TASK my_task (IN x1, IN x2, OUT x5); Для нее планировщиком ИК ORLANDO Tools будут найдены два плана решения задачи: 1) (f1║f2)®f3; 2) f2®f4. В приведенных планах решения задачи последовательное и параллельное выполнения операций обозначены символами ║ и ® соответственно. Выбрать план решения задачи может либо непосредственно сам пользователель пакета, либо планировщик ИК в соответствии с заданными пользователем критериями оценки эффективности вычислений, такими как общее время решения задачи, длина плана, и другими характеристиками вычислительного процесса. Приведем конструкции языка ORLANDO, предназначенные для построения запросов на решение поставленной задачи. Описание базы расчетных данных. Ввод/вывод данных в ИК ORLANDO Tools осуществляется через базу расчетных данных. Специализированный табличный редактор инструментального комплекса поддерживает импорт/экспорт данных в/из MS Excel. Для описания базы расчетных данных пользователя служит конструкция DATABASE <имя базы данных> [<путь к базе данных>]; Здесь <имя базы данных> – содержательный идентификатор базы расчетных данных; <путь к базе данных> – полный путь к БД. По умолчанию базы расчетных данных создаются в специальной системной директории пакета прикладных программ. Инициализация параметров скаляров. Для инициализации можно использовать команду [INITIAL] <имя параметра> = <значение>; Описание задания. Задание – это запрос на решение задачи по ее непроцедурной постановке с указанием используемой базы данных. Для описания задания служит конструкция SOLVE <имя задания> OF <постановка задачи> FROM <имя базы данных> <версия>; Здесь <имя задания> – содержательный идентификатор задания; <постановка задачи> – идентификатор постановки задачи, по которой следует провести расчеты; <имя базы данных> и <версия> – соответственно идентификатор БД и версия значений параметров в ней, которые будут использоваться для проведения расчетов. Все рассмотренные спецификации могут быть снабжены комментариями, содержащими информацию о назначении описываемого объекта, семантике значений его атрибутов и других до- полнительных характеристиках. Комментарии оформляются по правилам языка С++. Проверка корректности и целостности описания предметной области выполняется на этапах трансляции этого описания с языка ORLANDO на язык C++ и планирования вычислений. При разработке языка ORLANDO преследовалась цель создания компактного, но вместе с тем достаточно выразительного языка программирования, позволяющего пользователю лаконично, в декларативном стиле описывать предметные области сложной (в том числе и переменной) структуры, легко поддающиеся машинному анализу с целью выявления параллелизма в алгоритме решения задачи. Дальнейшее развитие языка ORLANDO связано с реализацией новых конструкций, которые позволили бы описывать для параллельной вычислительной системы знания продукционного слоя, а также автоматически строить циклические и ветвящиеся планы решения задачи для предметных областей с переменной структурой [2]. Литература 1. Опарин Г.А., Феоктистов А.Г., Новопашин А.П., Горский С.А. Инструментальный комплекс ORLANDO TOOLS // Программные продукты и системы. 2007. № 4. С. 63–65. 2. Опарин Г.А., Феоктистов Д.Г. Новые языковые средства пакетов прикладных программ в метасистеме САТУРН // Пакеты прикладных программ. Функциональное наполнение. Новосибирск: Наука, 1985. С. 20–28. |
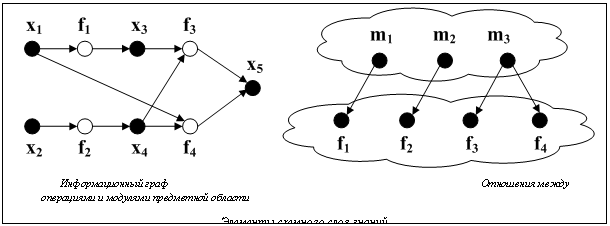 На рисунке изображены двудольный ориентированный граф, отражающий информационно-логические связи параметров и операций приведенного фрагмента описания предметной области, а также отношения между операциями и модулями, реализующими эти операции. Отметим, что в данном примере операции f3 и f4 реализованы одним и тем же модулем m3. Такая возможность позволяет отразить семантику используемых данных, необходимую при планировании вычислений (параметр x3 качественно отличается от параметра x1 вследствие применения к нему операции f1 и тем самым обусловливает выбор другого алгоритма решения задачи).
На рисунке изображены двудольный ориентированный граф, отражающий информационно-логические связи параметров и операций приведенного фрагмента описания предметной области, а также отношения между операциями и модулями, реализующими эти операции. Отметим, что в данном примере операции f3 и f4 реализованы одним и тем же модулем m3. Такая возможность позволяет отразить семантику используемых данных, необходимую при планировании вычислений (параметр x3 качественно отличается от параметра x1 вследствие применения к нему операции f1 и тем самым обусловливает выбор другого алгоритма решения задачи).| Permanent link: http://swsys.ru/index.php?page=article&id=2708&lang=&lang=en&like=1 |
Print version Full issue in PDF (5.09Mb) Download the cover in PDF (1.32Мб) |
| The article was published in issue no. № 1, 2011 |
Perhaps, you might be interested in the following articles of similar topics:
- Облачный сервис «Параллельный Matlab»
- Исследование эффективности библиотеки MaLLBa на примере задач максимальной выполнимости
- Входной язык объектно-ориентированной базы знаний GRID-системы
- Неоднозначная семантика и некорректности при работе с потоками на C#
- Построение адаптивной регулярной сетки трехмерной сцены в реальном режиме времени
Back to the list of articles