Journal influence
Bookmark
Next issue
Parallel automatic text categorization system
The article was published in issue no. № 1, 2012 [ pp. 31 - 36 ]Abstract:The paper describes structure and algorithm of parallel automatic text categorization system based on Support Vector Machines (SVM). Units, implementing main stages of system are discussed, particular attention is paid to classifier training process. The results of experiments based on text collection Reuters-21578 proving the effectiveness of the introduced parallel system are given.
Аннотация:Описаны структура и алгоритм работы параллельной системы автоматической текстовой классификации на ос-нове метода опорных векторов. Рассмотрены блоки, реализующие основные этапы работы системы, особое внима-ние уделено процессу обучения классификатора. Приведены результаты экспериментов на коллекции текстов Reuters-21578, подтверждающие эффективность разработанной параллельной системы.
| Authors: (Kotelnikov.EV@gmail.com) - , Russia, Ph.D, (peskisheva.t@mail.ru) - | |
| Keywords: automatic text processing, parallel system, SVM, support vector machines, text categorization |
|
| Page views: 12602 |
Print version Full issue in PDF (5.33Mb) Download the cover in PDF (1.08Мб) |
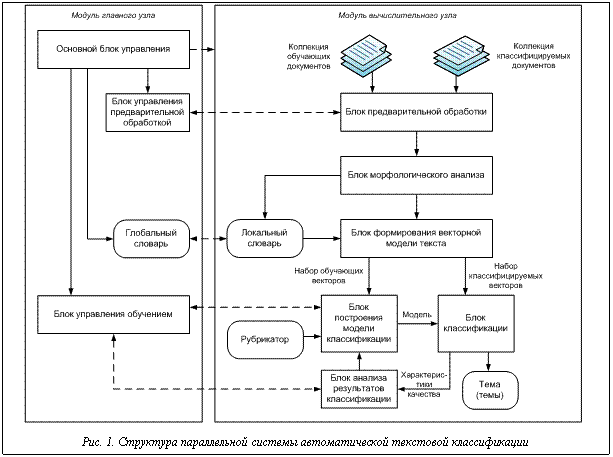
Для автоматической обработки значительных объемов текстовой информации применяются различные программные системы, предназначенные для поиска, аннотирования, машинного перевода, извлечения фактов и др. Одним из основных этапов автоматической обработки текстов является тематическая классификация, цель которой – отнесение текстовых документов к одной или нескольким заданным категориям по определенным признакам. Качественная автоматическая классификации делает процесс анализа текстовой информации менее трудоемким и более эффективным по времени выполнения и релевантности полученных результатов. Как показывают исследования [1], наилучшие результаты в решении задачи автоматической текстовой классификации демонстрирует метод опорных векторов (Support Vector Machines – SVM), предложенный В.Н. Вапником [2], для решения задач распознавания образов двух классов. Классификация с применением SVM сводится к обучению и распознаванию. Наиболее трудоемким является процесс обучения, для которого используется коллекция обучающих документов с известными рубриками. По этим документам формируются обучающие векторы. В задаче тематической текстовой классификации каждый вектор соответствует текстовому документу и представляет собой набор весов ключевых слов (терминов), входящих в данный документ. Вес дает числовую оценку значимости данного термина для определения тематики текста [1]. На сформированных векторах обучается SVM-классификатор. Для оценки качества обучения используется специальная тестовая коллекция (ее можно выделить из обучающей и не использовать для обучения), на которой классификатор тестируется, а полученные ответы сравниваются с требуемыми (рубрики тестовых документов известны). В процессе рас-познавания система автоматически определяет рубрики новых, ранее не предъявляемых ей документов. Существующие системы и модули текстовой классификации, в том числе использующие SVM, демонстрируют приемлемую скорость и точность обработки лишь на небольших и средних по объему данных. В случае значительного роста объема обрабатываемой информации, а также увеличения числа рубрик, по которым необходимо классифицировать документы, их производительность существенно снижается. Отдельной проблемой является организация эффективного подбора параметров классификатора. Решение этих проблем возможно с помощью использования параллельных реализаций методов классификации для многопроцессорных вычислительных систем и комплексов. В данной работе предлагаются структура и алгоритм функционирования параллельной системы автоматической текстовой классификации на основе метода опорных векторов, позволяющей эффективно осуществлять обучение тематического классификатора и распознавание тематических рубрик текстовых документов. Структура системы
В блоке предварительной обработки текстовый документ преобразуется из исходного вида в формат, принятый в системе: происходят очистка текста от знаков форматирования, выделение отдельных слов (tokenization, или графематический анализ), приведение всех слов к единому регистру, удаление слов, не несущих смысловую нагрузку (стоп-слов). Соответствующий управляющий блок модуля главного узла назначает документы коллекции вычислительным узлам на основе алгоритма распределения документов. В блоке морфологического анализа определяются нормальная форма и грамматические характеристики слов. Морфологический анализ в описываемой системе выполняется программой mystem (http://company.yandex.ru/technology/mystem). На основе различных слов всех документов формируется локальный словарь узла, который передается на главный узел и участвует в создании глобального словаря. Блок формирования векторной модели предназначен для представления каждого текста в виде вектора признаков на основе информации, полученной с выхода блока морфологического анализа и из локального словаря. Признак – это вес термина в тексте, размерность вектора признаков равна числу терминов в глобальном словаре. Взвешивание производится в соответствии с подходом TF.IDF [1], где вес термина вычисляется как произведение локального и глобального весов. Локальный вес зависит от частоты употребления термина в данном документе, а глобальный – от распределения термина по документам всей коллекции.
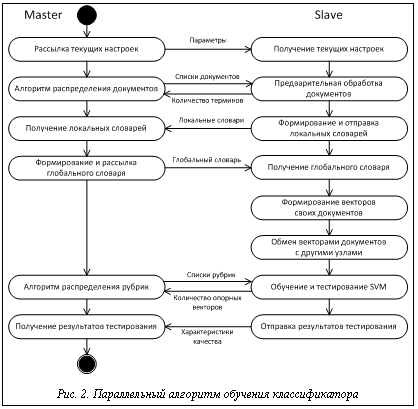
Блок классификации автоматически определяет рубрику документа с использованием модели классификации. Выходом этого блока для каждого документа (вектора) является множество тем, к которым относится данный документ. Для коллекции документов, помимо множества тем, выходом также будут являться характеристики качества классификации – точность, полнота, F1-мера [1]. На основе характеристик качества в блоке анализа качества классификации принимается решение о продолжении процесса обучения с другими параметрами или о его завершении. Блок управления обучением в модуле главного узла контролирует процесс подбора параметров классификатора и управляет назначением рубрик вычислительным узлам на основе алгоритма распределения рубрик. В представленную структуру заложены два уровня параллелизма – на уровне модулей и на уровне блоков. Параллелизм на уровне модулей предполагает размещение модулей на разных узлах вычислительной системы и их совместную параллельную работу, например, на основе технологии MPI. Параллелизм на уровне блоков заключается в возможности организации параллельного функционирования каждого из блоков, так, на рисунке 1, например, на основе технологии OpenMP. Алгоритм обучения классификатора Самым трудоемким этапом работы системы текстовой классификации является обучение классификатора. Это связано с высокой временнóй сложностью как формирования векторных моделей документов, так и обучения SVM. Ситуацию осложняет необходимость подбора оптимальных параметров классификатора. Параллельная реализация процесса обучения позволит повысить эффективность работы всей системы. На рисунке 2 предложена схема работы параллельного алгоритма обучения для параллельной системы автоматической текстовой классификации. Алгоритм обучения использует принцип master–slave, суть которого в следующем. Главный узел (master) передает подчиненным вычислительным узлам (slave) задания, которые они должны выполнить. Вычислительные узлы независимо друг от друга выполняют свои задания, затем полученные результаты возвращают главному узлу. До начала работы алгоритма на всех вычислительных узлах должны находиться файлы, содержащие обучающие и тестовые документы. В начале алгоритма основной блок управления главного узла рассылает на все подчиненные узлы текущие настройки работы, в частности, диапазоны значений для подбора оптимальных параметров классификатора. Затем блок управления предварительной обработкой на основе алгоритма распределения документов рассылает на вычислительные узлы списки документов. Указанный алгоритм работает по так называемой жадной схеме. В общем случае работа жадного алгоритма (greedy algorithm) заключается в принятии оптимальных решений на каждом этапе, допуская, что конечное решение также окажется оптимальным. На практике при решении задачи сбалансированного распределения нагрузки жадный алгоритм почти всегда дает решение, в достаточной степени близкое к оптимальному. Распределение документов может быть основано на информации о размере документов и о количестве терминов в каждом документе. При этом первый вид информации доступен сразу же, а второй позволяет более адекватно определить время обработки документа, то есть возможна ситуация, когда время обработки объемного документа с малым количеством терминов меньше времени обработки небольшого документа с большим количеством терминов. Первоначально в алгоритме распределения документов известен только размер каждого документа, на основании этой информации и происходит распределение. После первой итерации цикла подбора оптимальных параметров становится известно количество терминов в каждом документе, пересылаемое вычислительными узлами на главный узел, и алгоритм распределения корректируется в соответствии с этой новой информацией. На следующем этапе вычислительные узлы осуществляют предварительную обработку и морфологический анализ своих документов, формируют и отправляют на главный узел локальные словари, в которых присутствуют термины только из своих документов. Главный узел объединяет локальные словари в глобальный и рассылает его подчиненным узлам. На основе общего глобального словаря вычислительные узлы формируют векторы своих документов и, поскольку обучение и тестирование классификатора должны происходить на всех векторах, обмениваются друг с другом сформированными векторами. Блок управления обучением главного узла распределяет список всех рубрик по узлам. Распределение также происходит с применением жадного алгоритма [3], на первой итерации цикла подбора оптимальных параметров используется количество обучающих документов для каждой рубрики, на последующих – информация о количестве опорных векторов, полученная от вычислительных узлов после процесса обучения SVM. Количество опорных векторов является характеристикой, более адекватно определяющей время обучения, чем размер обучающих документов. Обучение и тестирование SVM происходят на вычислительных узлах в блоках построения модели классификатора и классификации. Характеристики качества классификации передаются главному узлу, а он на их основе принимает решение о продолжении или завершении процесса обучения. Временнáя сложность алгоритма Выполним оценку временнóй сложности алгоритма в случае, когда коллекция является сбалансированной, то есть отсутствуют серьезные различия между документами по размеру и между рубриками по количеству обучающих документов. Для этого выделим этапы с наиболее высокой скоростью роста – формирование векторов документов, обмен векторами и обучение SVM. Введем следующие обозначения: N – общее количество документов в коллекции; Ntrain – количество обучающих документов; M – число вычислительных узлов; D – размер глобального словаря. Формирование векторов документов имеет сложность Временнáя сложность обмена векторами описывается следующим выражением:
поскольку каждый узел должен передать свою порцию данных всем другим узлам. Временнáя сложность алгоритма обучения SVM сильно зависит от расположения входных данных в пространстве признаков; на практике можно использовать квадратичную зависимость:
Таким образом, временнáя сложность разработанного параллельного алгоритма обучения A описывается следующим выражением:
Из выражения (3) видно, что при увеличении количества вычислительных узлов обмен данными (второе слагаемое) будет занимать все большее время, а это повлияет на характеристики ускорения и эффективности. Чтобы оценить этот объем, нужно определить размер векторов, которыми узлы обмениваются между собой. Суммарный объем векторов обычно равен 1–2 объемам текстовой коллекции, по которой они формируются. Для коллекции Reuters-21578 объем векторов составляет 8 Мб; с учетом того, что каждый узел пересылает свою часть векторов каждому узлу, суммарный трафик при этом в кластере с 30 узлами можно оценить примерно в 30´8=240 Мб. При скорости сети 100 Мбит/с и с учетом служебных данных Ethernet и MPI такой объем информации передается за 25 секунд. В случае несбалансированной коллекции в выражении (3) возрастает вклад первого и третьего слагаемых из-за неравномерного распределения документов по узлам. Подбор параметров В описываемой системе предусмотрен подбор оптимальных параметров классификатора, которые можно разделить на четыре группы: 1) параметры предобработки и морфологического анализа; 2) параметры словаря; 3) параметры векторной модели; 4) параметры SVM. Подбор осуществляется на основе метода скользящего контроля по n блокам (n‑fold cross‑validation). В этом методе для каждого набора параметров классификатора обучающие данные разбиваются на n одинаковых блоков, обучение осуществляется на n–1 блоках, а на оставшемся блоке тестируется полученный классификатор и рассчитываются характеристики качества обучения. Такое обучение повторяется n раз, каждый блок один раз используется в качестве тестового. Затем характеристики качества обучения усредняются и считаются оценкой качества обучения для данного набора параметров. Весь процесс скользящего контроля повторяется для каждого набора из исследуемого диапазона параметров. Оптимальным считается набор параметров, при котором достигаются максимальные значения характеристик качества обучения. Условия проведения экспериментов Разработанные структура и алгоритм функционирования параллельной системы автоматической текстовой классификации были реализованы в среде Microsoft Visual Studio 2010 на языках C# и С/C++ на основе принципов объектно-ориентированного программирования. Для обучения SVM использовалась библиотека LIBSVM [4]. Целевой платформой приложения выбрана кластерная система, механизм передачи сообщений реализован с использованием библиотеки MPI.NET версии 1.0 [5]. Распараллеливание внутри блоков осуществлялось на основе технологии OpenMP (С/С++) и классов пространства имен System.Threading платформы Microsoft.Net.
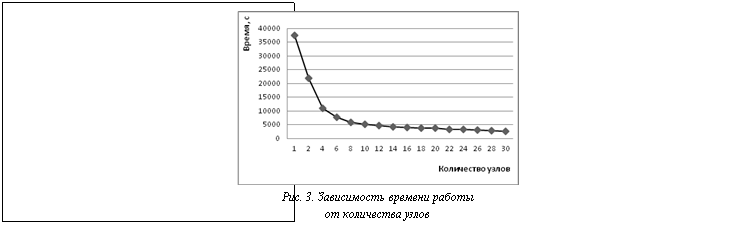
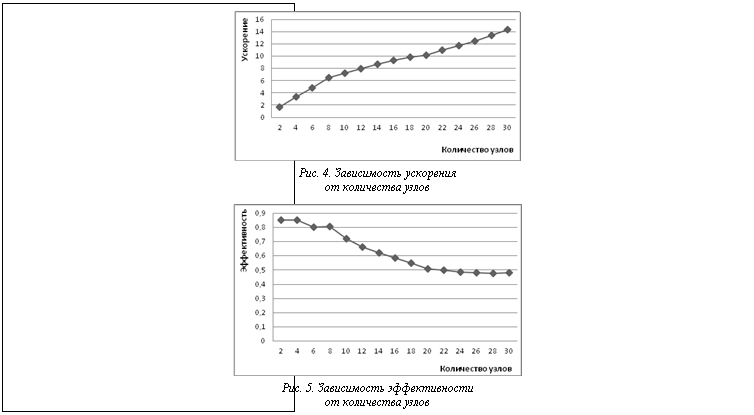
Для экспериментального исследования использовалась коллекция финансовых новостей агентства Reuters (Reuters-21578, Distribution 1.0) [6]. Обучающий набор документов был выделен в соответствии с общепринятым подходом, названным «ModApte split», при этом исключались документы, не помеченные ни одной рубрикой. Таким образом, обучающий набор в экспериментах был представлен 7 775 документами, тестовый – 3 019 документами, каждый из которых относится к одной или нескольким из 115 рубрик. Перед проведением экспериментов на все вычислительные узлы была скопирована текстовая коллекция Reuters-21578 объемом 9 Мб, суммарный трафик составил 9´30 = 270 Мб; процесс копирования занял менее 1 минуты. Результаты экспериментов Тестирование проводилось с целью измерения характеристик производительности параллельной системы – ускорения и эффективности. Ускорение вычисляется как отношение времени решения задачи на одном вычислительном узле ко времени решения на p вычислительных узлах. Эффективность вычисляется как отношение ускорения к количеству задействованных узлов и отражает долю времени выполнения алгоритма, в течение которой вычислительные узлы реально задействованы для решения задачи. Для измерения ускорения и эффективности была выбрана сложная вычислительная задача – подобраны параметры классификатора для коллекции Reuters-21578 методом скользящего контроля и проведен ряд запусков на разном количестве вычислительных узлов. Время выполнения на одном узле составило 37 466 с (примерно 10,5 часа). Зависимость времени выполнения на кластерной системе, ускорения и эффективности от разного количества задействованных узлов показана на рисунках 3–5. Из этих зависимостей видно, что, во-первых, при увеличении количества узлов время работы существенно снижается и происходит значительное ускорение, во-вторых, максимальная эффективность 80–85 % достигается при 2–8 вычислительных узлах, затем последовательно уменьшается до 50 %. Снижение эффективности объясняется особенностями коллекции Reuters-21578, имеющей крайне неравномерное распределение документов по рубрикам – 54 рубрики из 115 представлены менее чем 10 документами. Данное обстоятельство приводит к тому, что при увеличении количества узлов параллельной системы возрастает доля обмена сообщениями между узлами по сравнению с вычислениями на узлах. Для других текстовых коллекций, имеющих более равномерное распределение документов по рубрикам, снижение эффективности будет происходить при гораздо большем количестве задействованных узлов.
Таким образом, можно сделать вывод, что предложенная структура и алгоритм обучения параллельной системы автоматической текстовой классификации являются достаточно эффективными и позволяют существенно сократить время обработки больших тестовых коллекций. Так, для коллекций размером порядка 105 документов при использовании вычислительного кластера, состоящего из 20–30 обычных персональных компьютеров, время обработки сокращается с десятков часов до десятков минут. В дальнейшем планируется использовать другие, более крупные коллекции (RCV-1, РОМИП) для более детального исследования производительности системы, а также проанализировать влияние на ускорение параллельных реализаций отдельных блоков системы. Литература 1. Sebastiani F. Machine Learning in Automated Text Categorization. ACM Computing Surveys. Vol. 34. No. 1. March 2002, pp. 1–47. 2. Vapnik V. Statistical learning theory. Wiley, New York, 1998. 3. Котельников Е.В., Пескишева Т.А., Пестов О.А. Параллельный алгоритм обучения текстового классификатора для многопроцессорной системы с иерархической архитектурой // Вопросы современной науки и практики. Ун-т им. В.И. Вернадского. 2011. № 3 (34). С. 103–110. 4. LIBSVM – A Library for Support Vector Machines. URL: http://www.csie.ntu.edu.tw/~cjlin/libsvm/ (дата обращения: 01.10.2011). 5. Project MPI.NET // The Open Systems Lab, Indiana University. URL: http://www.osl.iu.edu/research/mpi.net (дата обращения: 01.10.2011). 6. Reuters-21578, Distribution 1.0. URL: http://www.daviddlewis.com/resources/testcollections/reuters21578 (дата обращения: 01.10.2011). |
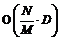 , поскольку каждый узел работает со своей порцией данных в среднем из N/M документов, а для построения каждого вектора требуется осуществлять поиск по глобальному словарю.
, поскольку каждый узел работает со своей порцией данных в среднем из N/M документов, а для построения каждого вектора требуется осуществлять поиск по глобальному словарю. =
=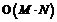 , (1)
, (1) . (2)
. (2)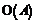 =
=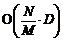 +
+
| Permanent link: http://swsys.ru/index.php?page=article&id=3008&lang=en |
Print version Full issue in PDF (5.33Mb) Download the cover in PDF (1.08Мб) |
| The article was published in issue no. № 1, 2012 [ pp. 31 - 36 ] |
Perhaps, you might be interested in the following articles of similar topics:
- Комбинированный метод автоматического определения тональности текста
- Прогнозирование на основе выделения границы реализаций динамических систем
- Метод автоматического формирования семантической сети из слабоструктурированных источников
- Сравнительный анализ методов построения математических моделей функционирования объекта с применением машинного обучения
- Определение весов оценочных слов на основе генетического алгоритма в задаче анализа тональности текстов
Back to the list of articles